
On this weblog publish I evaluate choices for real-time analytics on DynamoDB – Elasticsearch, Athena, and Spark – by way of ease of setup, upkeep, question functionality, latency. There may be restricted help for SQL analytics with a few of these choices. I additionally consider which use instances every of them are finest suited to.
Builders usually have a have to serve quick analytical queries over information in Amazon DynamoDB. Actual-time analytics use instances for DynamoDB embrace dashboards to allow stay views of the enterprise and progress to extra advanced utility options corresponding to personalization and real-time consumer suggestions. Nonetheless, as an operational database optimized for transaction processing, DynamoDB is just not well-suited to delivering real-time analytics. At Rockset, we lately added help for creating collections that pull information from Amazon DynamoDB – which principally means you possibly can run quick SQL on DynamoDB tables with none ETL. As a part of this effort, I spent a major period of time evaluating the strategies builders use to carry out analytics on DynamoDB information and understanding which technique is finest suited based mostly on the use case and located that Elasticsearch, Athena, and Spark every have their very own professionals and cons.
DynamoDB has been one of the vital widespread NoSQL databases within the cloud since its introduction in 2012. It’s central to many fashionable functions in advert tech, gaming, IoT, and monetary companies. Versus a conventional RDBMS like PostgreSQL, DynamoDB scales horizontally, obviating the necessity for cautious capability planning, resharding, and database upkeep. Whereas NoSQL databases like DynamoDB typically have glorious scaling traits, they help solely a restricted set of operations which might be targeted on on-line transaction processing. This makes it troublesome to develop analytics straight on them.
In an effort to help analytical queries, builders sometimes use a large number of various techniques along side DynamoDB. Within the following sections, we’ll discover just a few of those approaches and evaluate them alongside the axes of ease of setup, upkeep, question functionality, latency, and use instances they match properly.
If you wish to help analytical queries with out encountering prohibitive scan prices, you possibly can leverage secondary indexes in DynamoDB which helps a restricted kind of queries. Nonetheless for a majority of analytic use instances, it’s price efficient to export the information from DynamoDB into a distinct system like Elasticsearch, Athena, Spark, Rockset as described under, since they mean you can question with greater constancy.
DynamoDB + Glue + S3 + Athena
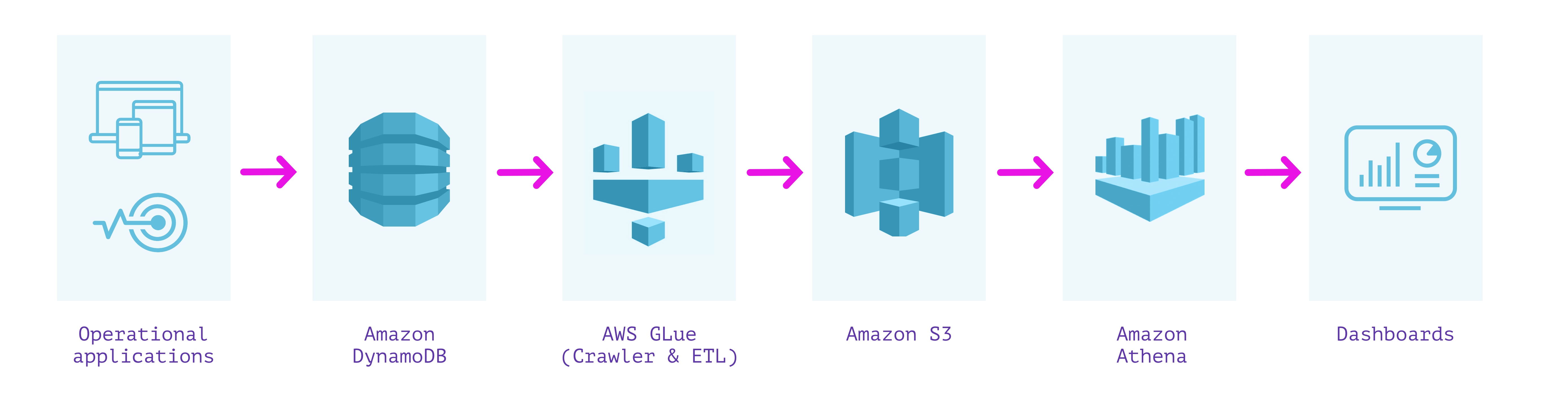
One method is to extract, rework, and cargo the information from DynamoDB into Amazon S3, after which use a service like Amazon Athena to run queries over it. We will use AWS Glue to carry out the ETL course of and create an entire copy of the DynamoDB desk in S3.
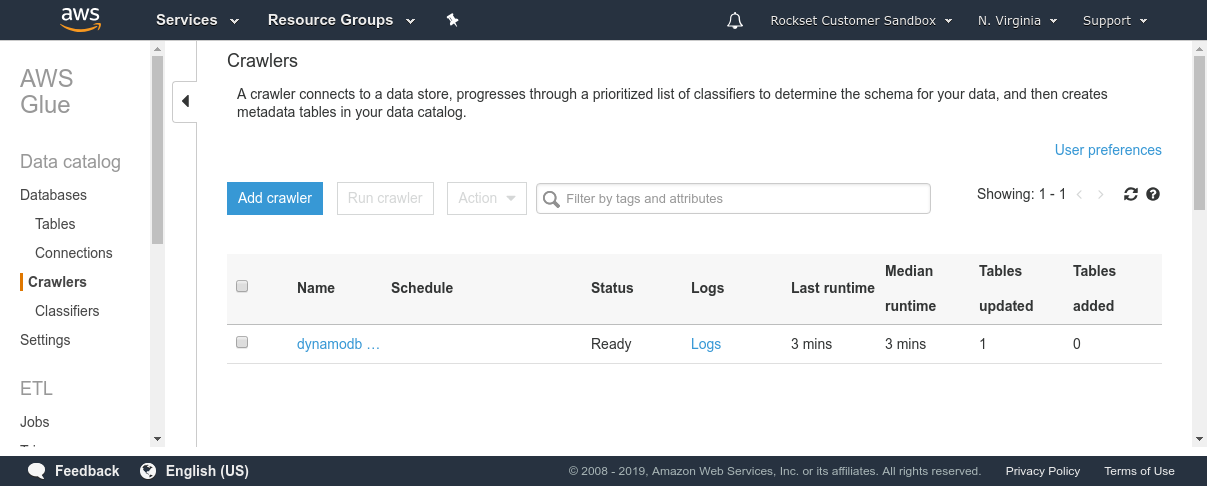
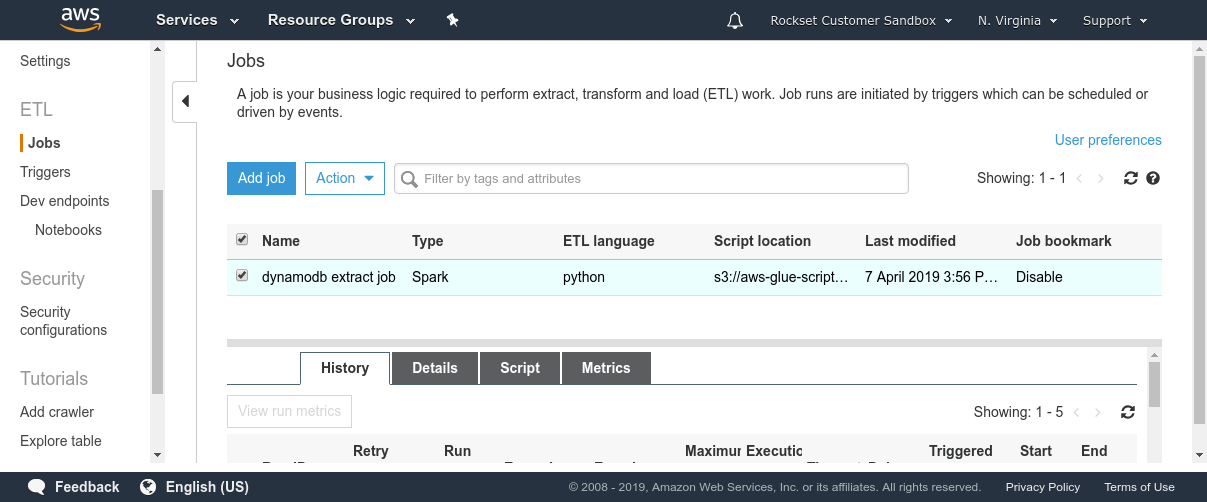
Amazon Athena expects to be offered with a schema so as to have the ability to run SQL queries on information in S3. DynamoDB, being a NoSQL retailer, imposes no mounted schema on the paperwork saved. Due to this fact, we have to extract the information and compute a schema based mostly on the information varieties noticed within the DynamoDB desk. AWS Glue is a totally managed ETL service that lets us do each. We will use two functionalities supplied by AWS Glue—Crawler and ETL jobs. Crawler is a service that connects to a datastore (corresponding to DynamoDB) and scans by way of the information to find out the schema. Individually, a Glue ETL Apache Spark job can scan and dump the contents of any DynamoDB desk into S3 in Parquet format. This ETL job can take minutes to hours to run relying on the scale of the DynamoDB desk and the learn bandwidth on the DynamoDB desk. As soon as each these processes have accomplished, we will fireplace up Amazon Athena and run queries on the information in DynamoDB.
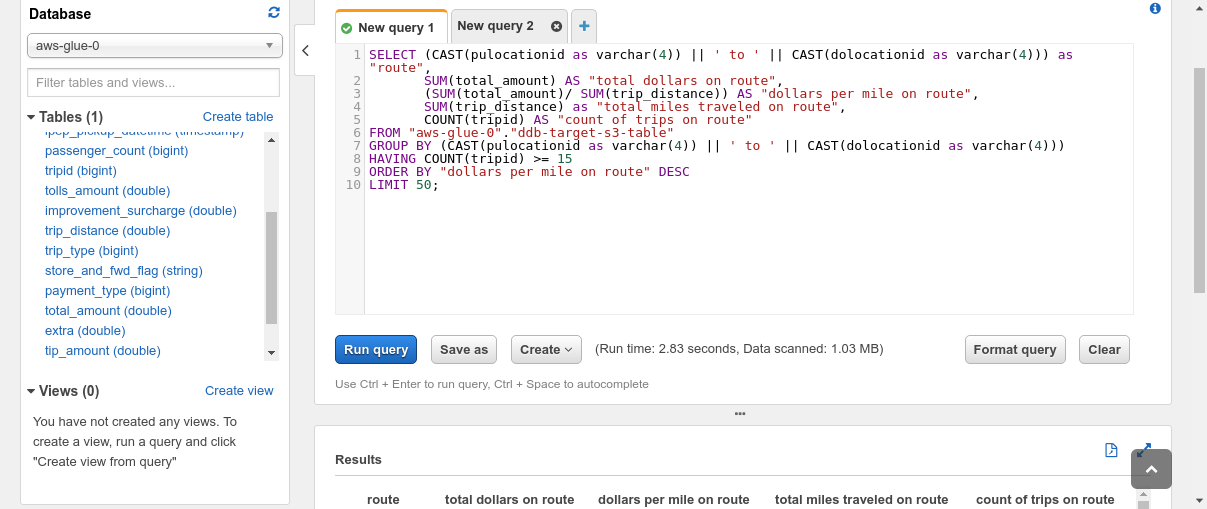
This whole course of doesn’t require provisioning any servers or capability, or managing infrastructure, which is advantageous. It may be automated pretty simply utilizing Glue Triggers to run on a schedule. Amazon Athena will be related to a dashboard corresponding to Amazon QuickSight that can be utilized for exploratory evaluation and reporting. Athena relies on Apache Presto which helps querying nested fields, objects and arrays inside JSON.
A significant drawback of this technique is that the information can’t be queried in actual time or close to actual time. Dumping all of DynamoDB’s contents can take minutes to hours earlier than it’s out there for working analytical queries. There isn’t a incremental computation that retains the 2 in sync—each load is a completely new sync. This additionally means the information that’s being operated on in Amazon Athena could possibly be a number of hours old-fashioned.
The ETL course of may also lose data if our DynamoDB information incorporates fields which have blended varieties throughout totally different gadgets. Area varieties are inferred when Glue crawls DynamoDB, and the dominant kind detected will likely be assigned as the kind of a column. Though there’s JSON help in Athena, it requires some DDL setup and administration to show the nested fields into columns for working queries over them successfully. There may also be some effort required for upkeep of the sync between DynamoDB, Glue, and Athena when the construction of knowledge in DynamoDB modifications.
Benefits
- All parts are “serverless” and require no provisioning of infrastructure
- Simple to automate ETL pipeline
Disadvantages
- Excessive end-to-end information latency of a number of hours, which suggests stale information
- Question latency varies between tens of seconds to minutes
- Schema enforcement can lose data with blended varieties
- ETL course of can require upkeep now and again if construction of knowledge in supply modifications
This method can work properly for these dashboards and analytics that don’t require querying the newest information, however as an alternative can use a barely older snapshot. Amazon Athena’s SQL question latencies of seconds to minutes, coupled with the big end-to-end latency of the ETL course of, makes this method unsuitable for constructing operational functions or real-time dashboards over DynamoDB.

DynamoDB + Hive/Spark

Another method to unloading all the DynamoDB desk into S3 is to run queries over it straight, utilizing DynamoDB’s Hive integration. The Hive integration permits querying the information in DynamoDB straight utilizing HiveQL, a SQL-like language that may specific analytical queries. We will do that by organising an Amazon EMR cluster with Hive put in.
As soon as our cluster is about up, we will log into our grasp node and specify an exterior desk in Hive pointing to the DynamoDB desk that we’re trying to question. It requires that we create this exterior desk with a specific schema definition for the information varieties. One caveat is that Hive is learn intensive, and the DynamoDB desk should be arrange with enough learn throughput to keep away from ravenous different functions which might be being served from it.
hive> CREATE EXTERNAL TABLE twitter(hashtags string, language string, textual content string)
> STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
> TBLPROPERTIES (
> "dynamodb.desk.identify" = "foxish-test-table",
> "dynamodb.column.mapping" = "hashtags:hashtags,language:language,textual content:textual content"
> );
WARNING: Configured write throughput of the dynamodb desk foxish-test-table is lower than the cluster map capability. ClusterMapCapacity: 10 WriteThroughput: 5
WARNING: Writes to this desk may lead to a write outage on the desk.
OK
Time taken: 2.567 seconds
hive> present tables;
OK
twitter
Time taken: 0.135 seconds, Fetched: 1 row(s)
hive> choose hashtags, language from twitter restrict 10;
OK
music km
music in
music th
music ja
music es
music en
music en
music en
music en
music ja
music en
Time taken: 0.197 seconds, Fetched: 10 row(s)
This method provides us extra up-to-date outcomes and operates on the DynamoDB desk straight reasonably than constructing a separate snapshot. The identical mechanism we noticed within the earlier part applies in that we have to present a schema that we compute utilizing a service like AWS Glue Crawler. As soon as the exterior desk is about up with the right schema, we will run interactive queries on the DynamoDB desk written in HiveQL. In a really comparable method, one may also join Apache Spark to a DynamoDB desk utilizing a connector for working Spark SQL queries. The benefit of those approaches is that they’re able to working on up-to-date DynamoDB information.
A drawback of the method is that it may well take a number of seconds to minutes to compute outcomes, which makes it lower than superb for real-time use instances. Incorporating new updates as they happen to the underlying information sometimes requires one other full scan. The scan operations on DynamoDB will be costly. Working these analytical queries powered by desk scans ceaselessly may also adversely impression the manufacturing workload that’s utilizing DynamoDB. Due to this fact, it’s troublesome to energy operational functions constructed straight on these queries.
In an effort to serve functions, we could have to retailer the outcomes from queries run utilizing Hive/Spark right into a relational database like PostgreSQL, which provides one other part to take care of, administer, and handle. This method additionally departs from the “serverless” paradigm that we utilized in earlier approaches because it requires managing some infrastructure, i.e. EC2 situations for EMR and probably an set up of PostgreSQL as properly.
Benefits
- Queries over newest information in DynamoDB
- Requires no ETL/pre-processing aside from specifying a schema
Disadvantages
- Schema enforcement can lose data when fields have blended varieties
- EMR cluster requires some administration and infrastructure administration
- Queries over the newest information includes scans and are costly
- Question latency varies between tens of seconds to minutes straight on Hive/Spark
- Safety and efficiency implications of working analytical queries on an operational database
This method can work properly for some sorts of dashboards and analytics that should not have tight latency necessities and the place it is not price prohibitive to scan over all the DynamoDB desk for advert hoc interactive queries. Nonetheless, for real-time analytics, we’d like a option to run a variety of analytical queries with out costly full desk scans or snapshots that shortly fall old-fashioned.
DynamoDB + AWS Lambda + Elasticsearch
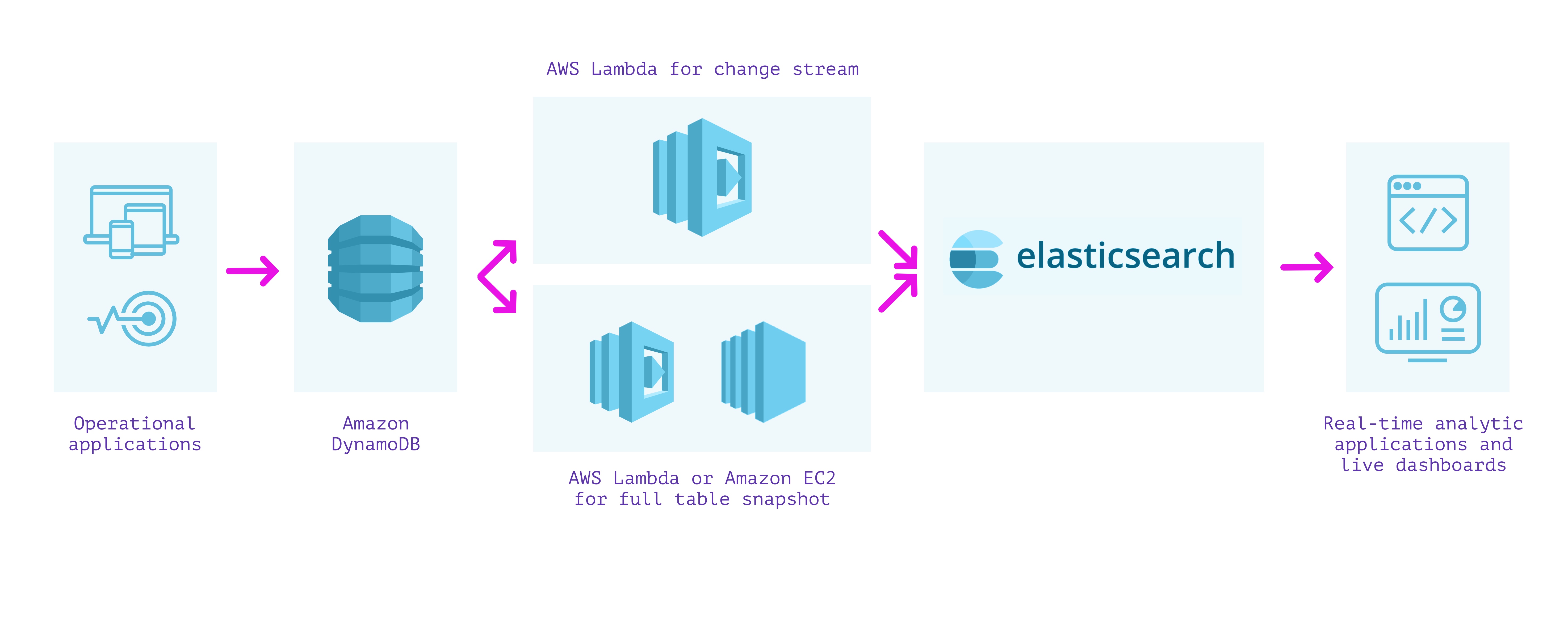
One other method to constructing a secondary index over our information is to make use of DynamoDB with Elasticsearch. Elasticsearch will be arrange on AWS utilizing Amazon Elasticsearch Service, which we will use to provision and configure nodes in response to the scale of our indexes, replication, and different necessities. A managed cluster requires some operations to improve, safe, and hold performant, however much less so than working it fully by oneself on EC2 situations.
Because the method utilizing the Logstash Plugin for Amazon DynamoDB is unsupported and reasonably troublesome to arrange, we will as an alternative stream writes from DynamoDB into Elasticsearch utilizing DynamoDB Streams and an AWS Lambda perform. This method requires us to carry out two separate steps:
- We first create a lambda perform that’s invoked on the DynamoDB stream to publish every replace because it happens in DynamoDB into Elasticsearch.
- We then create a lambda perform (or EC2 occasion working a script if it can take longer than the lambda execution timeout) to publish all the prevailing contents of DynamoDB into Elasticsearch.
We should write and wire up each of those lambda features with the right permissions with the intention to be certain that we don’t miss any writes into our tables. When they’re arrange together with required monitoring, we will obtain paperwork in Elasticsearch from DynamoDB and may use Elasticsearch to run analytical queries on the information.
The benefit of this method is that Elasticsearch helps full-text indexing and several other kinds of analytical queries. Elasticsearch helps shoppers in numerous languages and instruments like Kibana for visualization that may assist shortly construct dashboards. When a cluster is configured accurately, question latencies will be tuned for quick analytical queries over information flowing into Elasticsearch.
Disadvantages embrace that the setup and upkeep price of the answer will be excessive. As a result of lambdas fireplace once they see an replace within the DynamoDB stream, they’ll have have latency spikes attributable to chilly begins. The setup requires metrics and monitoring to make sure that it’s accurately processing occasions from the DynamoDB stream and in a position to write into Elasticsearch. It’s also not “serverless” in that we pay for provisioned assets versus the assets that we truly use. Even managed Elasticsearch requires coping with replication, resharding, index development, and efficiency tuning of the underlying situations. Functionally, by way of analytical queries, it lacks help for joins, that are helpful for advanced analytical queries that contain multiple index.
Benefits
- Full-text search help
- Assist for a number of kinds of analytical queries
- Can work over the newest information in DynamoDB
Disadvantages
- Requires administration and monitoring of infrastructure for ingesting, indexing, replication, and sharding
- Requires separate system to make sure information integrity and consistency between DynamoDB and Elasticsearch
- Scaling is guide and requires provisioning further infrastructure and operations
- No help for joins between totally different indexes
This method can work properly when implementing full-text search over the information in DynamoDB and dashboards utilizing Kibana. Nonetheless, the operations required to tune and preserve an Elasticsearch cluster in manufacturing, with tight necessities round latency and information integrity for real-time dashboards and functions, will be difficult.
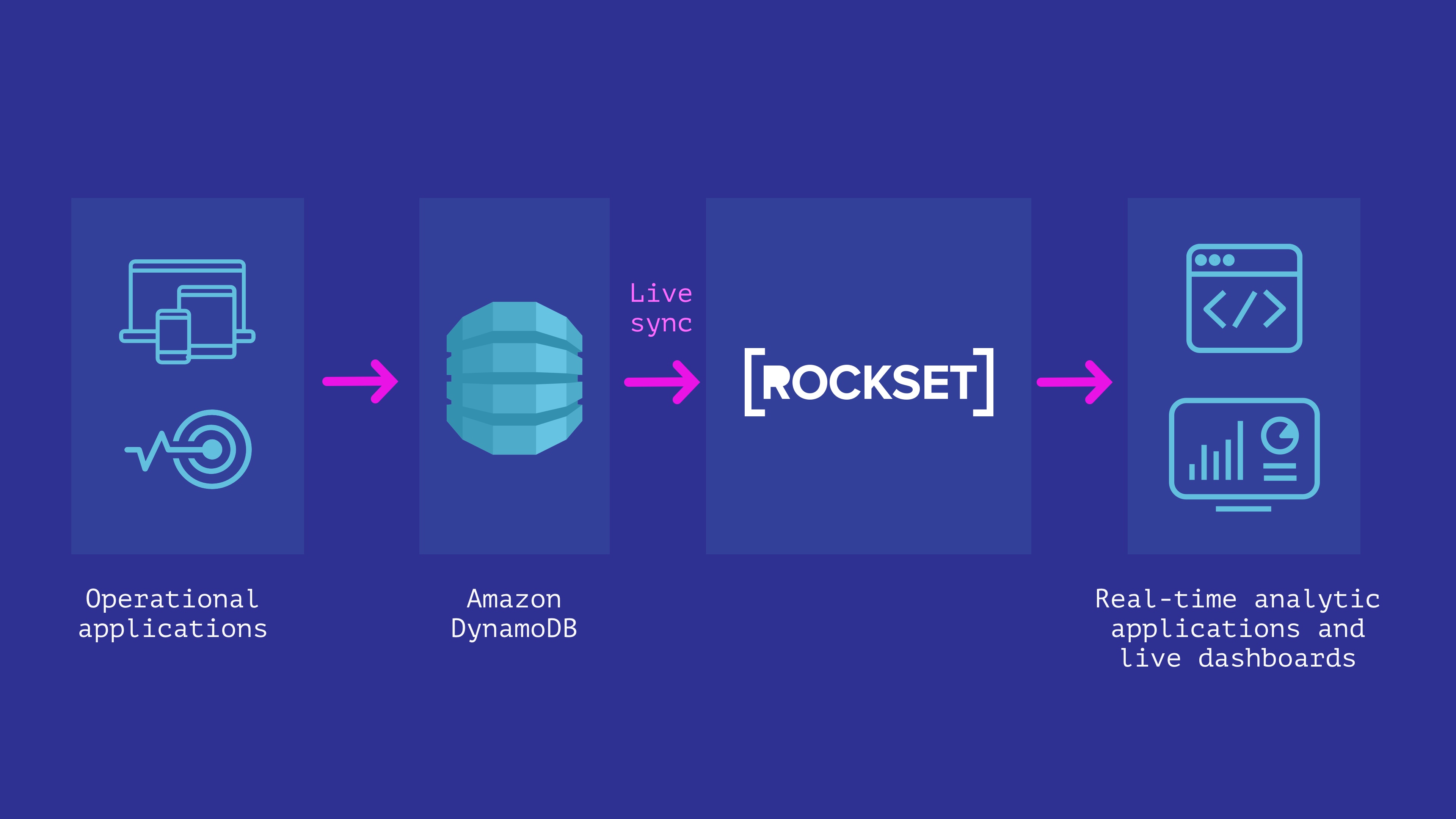
DynamoDB + Rockset
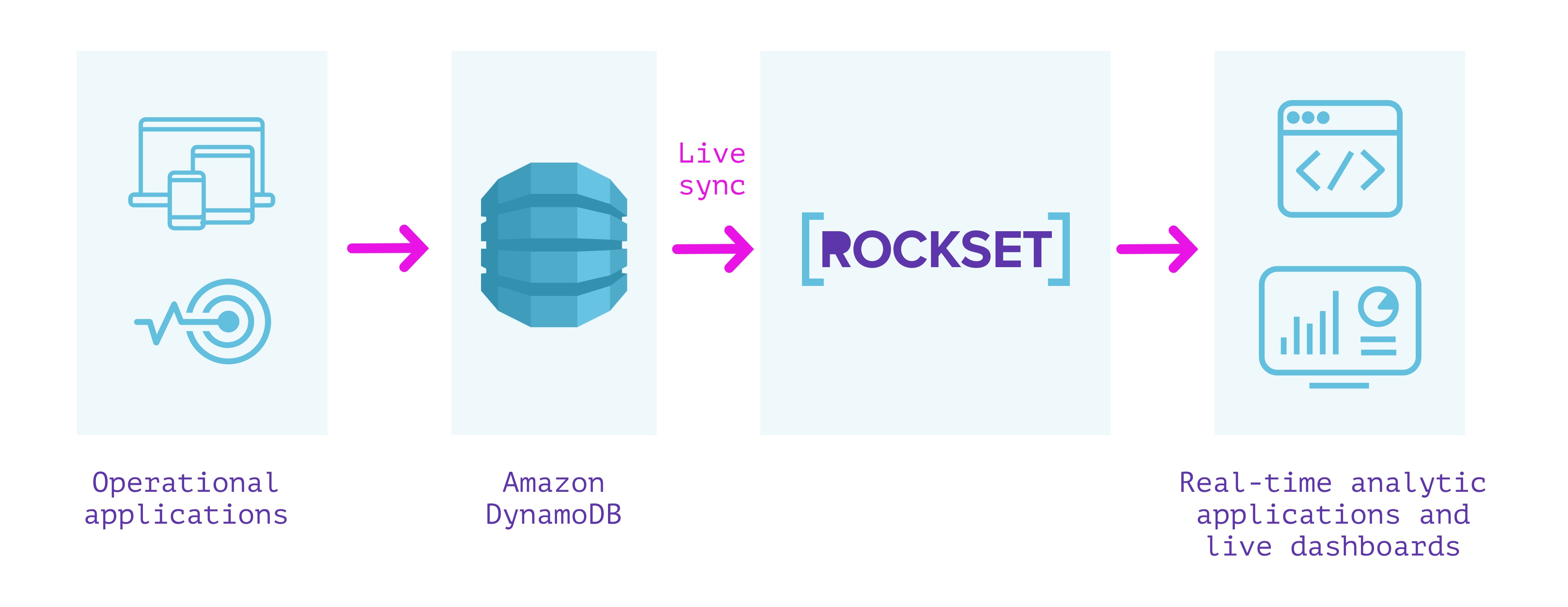
Rockset is a very managed service for real-time indexing constructed primarily to help real-time functions with excessive QPS necessities.
Rockset has a stay integration with DynamoDB that can be utilized to maintain information in sync between DynamoDB and Rockset. We will specify the DynamoDB desk we wish to sync contents from and a Rockset assortment that indexes the desk. Rockset indexes the contents of the DynamoDB desk in a full snapshot after which syncs new modifications as they happen. The contents of the Rockset assortment are at all times in sync with the DynamoDB supply; no quite a lot of seconds aside in regular state.
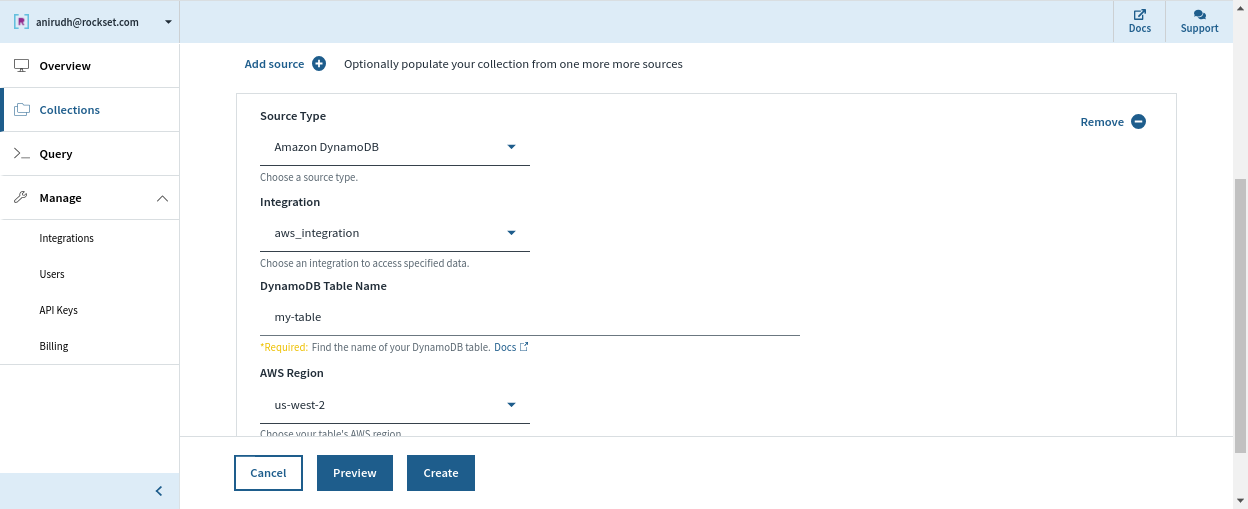
Rockset manages the information integrity and consistency between the DynamoDB desk and the Rockset assortment robotically by monitoring the state of the stream and offering visibility into the streaming modifications from DynamoDB.
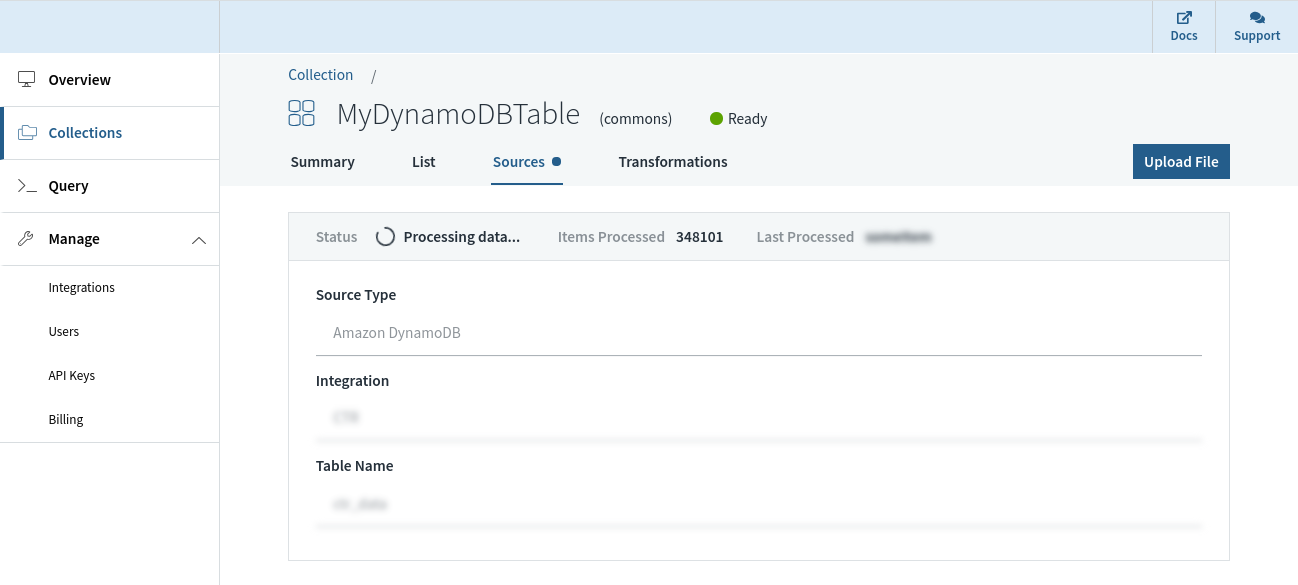
With no schema definition, a Rockset assortment can robotically adapt when fields are added/eliminated, or when the construction/kind of the information itself modifications in DynamoDB. That is made attainable by sturdy dynamic typing and good schemas that obviate the necessity for any further ETL.
The Rockset assortment we sourced from DynamoDB helps SQL for querying and will be simply used to construct real-time dashboards utilizing integrations with Tableau, Superset, Redash, and so forth. It may also be used to serve queries to functions over a REST API or utilizing consumer libraries in a number of programming languages. The superset of ANSI SQL that Rockset helps can work natively on deeply nested JSON arrays and objects, and leverage indexes which might be robotically constructed over all fields, to get millisecond latencies on even advanced analytical queries.
As well as, Rockset takes care of safety, encryption of knowledge, and role-based entry management for managing entry to it. We will keep away from the necessity for ETL by leveraging mappings we will arrange in Rockset to change the information because it arrives into a set. We will additionally optionally handle the lifecycle of the information by organising retention insurance policies to robotically purge older information. Each information ingestion and question serving are robotically managed, which lets us deal with constructing and deploying stay dashboards and functions whereas eradicating the necessity for infrastructure administration and operations.
Rockset is an effective match for real-time analytics on prime of operational information shops like DynamoDB for the next causes.
Abstract
- Constructed to ship excessive QPS and serve real-time functions
- Utterly serverless. No operations or provisioning of infrastructure or database required
- Dwell sync between DynamoDB and the Rockset assortment, in order that they’re by no means quite a lot of seconds aside
- Monitoring to make sure consistency between DynamoDB and Rockset
- Automated indexes constructed over the information enabling low-latency queries
- SQL question serving that may scale to excessive QPS
- Joins with information from different sources corresponding to Amazon Kinesis, Apache Kafka, Amazon S3, and so forth.
- Integrations with instruments like Tableau, Redash, Superset, and SQL API over REST and utilizing consumer libraries.
- Options together with full-text search, ingest transformations, retention, encryption, and fine-grained entry management
We will use Rockset for implementing real-time analytics over the information in DynamoDB with none operational, scaling, or upkeep issues. This could considerably pace up the event of stay dashboards and functions.
If you would like to construct your utility on DynamoDB information utilizing Rockset, you may get began at no cost on right here. For a extra detailed instance of how one can run SQL queries on a DynamoDB desk synced into Rockset, try our weblog on working quick SQL on DynamoDB tables.
Different DynamoDB assets:

{kind=link}