
Rockset is a schemaless SQL knowledge platform. It’s designed to help SQL on uncooked knowledge. Whereas most SQL databases are strongly and statically typed, knowledge inside Rockset is strongly however dynamically typed. Dynamic typing makes it troublesome for us to undertake off-the-shelf SQL question optimizers since they’re designed for statically typed knowledge the place the sorts of the columns are recognized forward of time. Most of Rockset’s operational analytics use instances execute a whole bunch of concurrent queries, and every question wants to finish inside just a few milliseconds. Given our distinctive challenges and efficiency necessities, constructing our personal SQL question engine from scratch appeared like the appropriate selection.
This weblog submit provides you a sneak peek at what occurs beneath the hood of our SQL question engine while you problem a SQL question to Rockset.
Broadly talking, a SQL question goes by 3 predominant levels as proven in Determine 1:
- Planning
- Optimization
- Execution

Within the starting stage, a set of steps that should be executed to finish the question is produced. This set of steps known as a question plan.
A question plan is additional categorized into the next varieties:
- Logical Question Plan: It’s an algebraic illustration of the question.
- Bodily Question Plan: It consists of operators that execute components of the question. For instance, the logical question plan might include a “Assortment” node that signifies that knowledge should be retrieved from a particular assortment, whereas the bodily plan incorporates a “ColumnScan” or “IndexFilter” operator that really retrieves the info utilizing a particular entry methodology from the index.
A number of question plans may be produced for a similar question from which the question optimizer then chooses probably the most environment friendly question plan for execution. The ultimate question plan chosen for execution known as the execution plan.
With a purpose to inspire our design selections for the question planner we first want to know the question optimization stage. Particularly, we have to perceive how an optimizer chooses an execution plan. Within the subsequent part, we have a look at the two predominant classes of question optimization strategies.
Rule Based mostly Optimization vs. Price Based mostly Optimization
A question optimizer is entrusted with the job of choosing probably the most environment friendly execution plan for a selected question.
The Rule Based mostly Optimizer (RBO) makes use of a set of predetermined guidelines primarily based on a heuristic to infer probably the most environment friendly execution plan. For instance, you can have a rule that chooses a special entry methodology to fetch the info from the index primarily based on the character of the filter clause within the question. We index all fields, so predicates that evaluate a discipline worth with a continuing (corresponding to “a < 10”) may be pushed into the index. However predicates that evaluate a discipline with one other discipline (corresponding to “a < b”) can’t be pushed into the index. You might select the entry methodology that scans the inverted index for under these paperwork that fulfill the predicate (IndexFilter) for queries which have predicates that may be pushed down into the index, versus a full columnar scan adopted by a filter within the case the place the predicates can’t be pushed down. That is illustrated in Determine 2.

Or you will have a rule that chooses a special be a part of technique relying on whether or not the be a part of is an equijoin or not. An RBO doesn’t at all times produce probably the most environment friendly execution plan, however in most conditions it’s adequate.
However, a Price Based mostly Optimizer (CBO) begins with all attainable question plans in its search area. It evaluates them by assigning a rating to each plan. This rating is a perform of the compute, reminiscence, and time required to execute that plan. The ultimate value of the plan is memoized by breaking the question plan into less complicated sub-plans and scoring every of them as you go alongside. The fee mannequin may be designed primarily based on the necessities of the system. It additionally makes use of different details about the info corresponding to row selectivity and distribution of values to infer probably the most environment friendly execution plan extra precisely. On condition that the search area of plan options can develop exponentially, a great CBO must steadiness exploration (which grows the search area) with exploitation (scoring the already-explored plans and pruning those that won’t be optimum).
The primary question optimizer for Rockset was rule primarily based. Whereas it labored properly for easier queries with fewer knobs to show, for extra complicated queries it quickly developed right into a slightly gnarly mesh of specialised guidelines providing little or no flexibility to seize different subtleties. Particular care needed to be taken to make sure that these guidelines didn’t step on one another. Additional, it was virtually inconceivable to exhaustively cowl all of the optimizations, usually leading to clunky tweaks to present guidelines after a helpful heuristic was found as an afterthought. Our rule primarily based optimizer quickly developed into a large home of playing cards with guidelines precariously balanced collectively.
On condition that the first use case for Rockset is operational analytics queries with low latency and excessive concurrency necessities, there was an rising emphasis on question efficiency. The RBO supplied a slightly brittle method in direction of question optimization and we quickly realized that we wanted one thing that was extensible, steady, and dependable. After surveying some analysis literature, we got here throughout Orca, which is a state-of-the-art value primarily based question optimizer particularly designed for heavy operational workloads. We determined to maneuver in direction of a value primarily based optimizer that may assist us higher meet our necessities. Within the course of, we determined to rewrite our question planner to help value primarily based optimization. Our question planning structure is closely impressed by Orca[1] in addition to CockroachLabs[2].
Now that we perceive at a excessive stage how a question optimizer operates, allow us to transfer onto how queries are deliberate in Rockset.
Question Planning
Step one earlier than the planning part is question parsing. The parser checks the SQL question string for syntactic correctness after which converts it to an summary syntax tree (AST). This AST is the enter to the question planner.
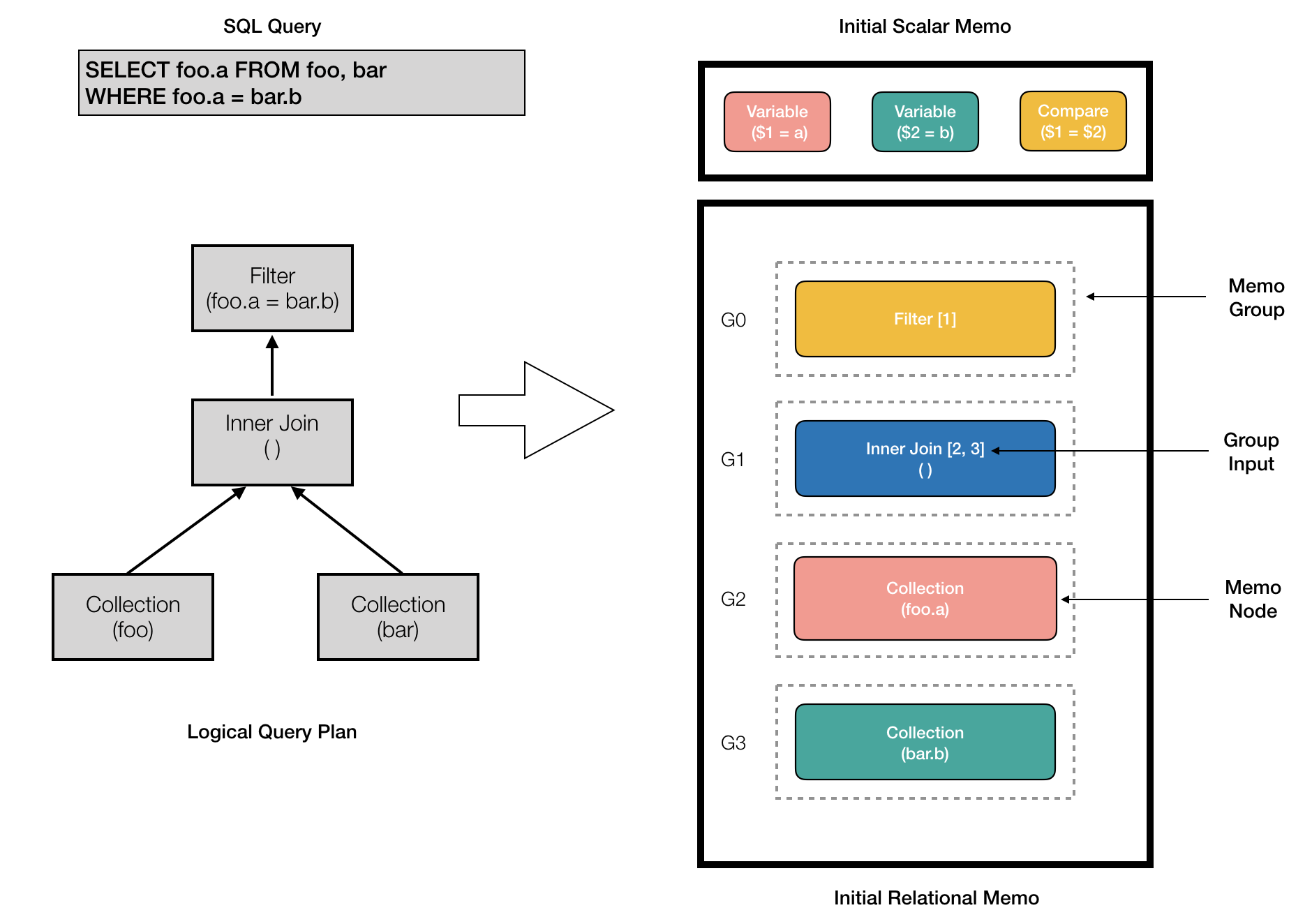
Allow us to use the next instance question as we stroll by the completely different steps of question planning.
SELECT foo.a FROM foo, bar
WHERE foo.a = bar.b
The AST for this question is proven in Determine 3.

The question planner has the next key elements:
Memo
A Memo is a recursive in-memory knowledge construction used to effectively retailer the forest of question plan options generated throughout question planning.
It consists of the next elements:
Memo Group:
A Memo consists of a set of containers referred to as teams. Every group incorporates logically equal expressions that every obtain the identical group aim in numerous logical methods.
Memo Node:
Every group expression in a memo group known as a memo node. Every memo node is an operator that has different memo teams as kids.
The memo nodes are subdivided into 2 varieties:
- Relational (e.g. Assortment, Be part of Relation)
- Scalar (e.g. Expressions)
We’ve got 2 completely different Memo buildings to carry the relational and scalar memo nodes individually. A Relational Memo construction is used to retailer the relational memo nodes whereas a Scalar Memo construction shops the scalar memo nodes. Every memo node has a fingerprint that uniquely identifies it. Each the relational and scalar Memos retailer a novel set of the relational and scalar memo nodes, respectively.
The scalar memo doesn’t have teams for the reason that most simplified model of a scalar memo node is saved within the scalar memo.
Determine 4 exhibits the preliminary contents of the Relational and Scalar Memos for our instance question. The logical question plan interprets to 4 memo teams, 2 for every Assortment, 1 for the InnerJoin with empty predicates, and 1 for the Filter. Group 0 (G0) can be referred to as the foundation memo group because it corresponds to the foundation of the logical question plan.

Normalization:
Throughout this step, plan options are generated by making use of a set of normalization guidelines to the plan nodes. Normalization is used primarily to simplify expressions, remodel equal expressions to a canonical kind, and apply optimizations which might be believed to at all times be helpful with a purpose to save the CBO some work. These guidelines specify a sequence of transformations to be utilized to a plan node when a selected match situation is glad. It’s anticipated that these normalization guidelines don’t result in cyclic dependencies. The ensuing memo nodes are saved within the Memo, which can lead to creating new memo teams and/or including new memo nodes to present teams. Memo nodes ensuing from the normalization of scalars (e.g., fixed folding) are thought-about remaining. We ignore the price of computing scalar expressions; we assume that equal scalar expressions (corresponding to a + 2 and 2 + a) have the identical value (zero). It is just the relational memo nodes which might be explored.
We’ve got carried out our personal rule specification language (RSL) to precise these normalization guidelines. We convert these RSL guidelines to C++ code snippets utilizing our personal RSL compiler.
For example, we will specific fixed folding in RSL as follows.
[Normalize, Name="evaluateConstantCall"]
FunctionCall(
func: *,
args: * if (allConstant($args))
)
=>
Fixed(worth: evalFunction($func, $args))
This rule implies that in the event you encounter a FunctionCall scalar memo node that has all constants for its arguments, substitute it with a Fixed scalar memo node with its worth equal to that of the evaluated perform.
That is illustrated in Determine 5.

Going again to our instance question, we will specify a normalization rule that produces another plan by pushing down the predicate foo.a = bar.b into the Inside Be part of operation, versus making use of it as a submit be a part of predicate.
[Normalize, Name="pushAfterJoinPredicatesIntoInnerJoin"]
Filter(
enter: $j=Be part of(kind: kInner, predicates: $join_pred=*),
predicates: $pred=*)
=>
substitute($j, predicates: intersectPredicates($join_pred, $pred))
With this normalization,
SELECT foo.a FROM foo, bar
WHERE foo.a = bar.b
successfully converts to
SELECT foo.a FROM foo INNER JOIN bar
ON foo.a = bar.b
Determine 6 exhibits what the brand new Memo would seem like after normalization. It solely exhibits the memo teams that will likely be walked throughout exploration.

Exploration
Exploration occurs as a part of the question optimization stage. Throughout this part, the varied plan options are costed by scoring dependent memo teams recursively, beginning at a Memo’s root group.
It’s throughout this part that probably the most environment friendly be a part of technique, be a part of ordering, and entry path could be picked to execute our instance question.
That is nonetheless work in progress and continues to be an energetic space of improvement for our workforce. We are going to speak about it at size in a future weblog submit.
Execution
The execution plan obtained on account of exploration is forwarded to the execution engine, which distributes the duties throughout machines to allow distributed question execution. The ultimate outcomes are then relayed again to the top consumer. We are going to cowl the small print about question execution in one in every of our future weblog posts.
Quite a lot of this continues to be actively developed, actually as I write this weblog. If engaged on such thrilling issues is your factor, we’re hiring!
References:
[1] Soliman, Mohamed A., et al. “Orca: a modular question optimizer structure for giant knowledge.” Proceedings of the 2014 ACM SIGMOD worldwide convention on Administration of information. ACM, 2014.
[2] CockroachDB: https://github.com/cockroachdb/cockroach/blob/release-19.1/pkg/sql/decide/doc.go

{kind=link}