
Introduction to Operational Analytics
Operational analytics is a really particular time period for a kind of analytics which focuses on enhancing present operations. The sort of analytics, like others, includes using varied information mining and information aggregation instruments to get extra clear data for enterprise planning. The primary attribute that distinguishes operational analytics from different sorts of analytics is that it’s “analytics on the fly,” which implies that indicators emanating from the varied components of a enterprise are processed in real-time to feed again into instantaneous resolution making for the enterprise. Some individuals confer with this as “steady analytics,” which is one other option to emphasize the continual digital suggestions loop that may exist from one a part of the enterprise to others.
Operational analytics lets you course of varied sorts of data from totally different sources after which resolve what to do subsequent: what motion to take, whom to speak to, what instant plans to make. This type of analytics has turn into widespread with the digitization pattern in nearly all business verticals, as a result of it’s digitization that furnishes the info wanted for operational decision-making.
Examples of operational analytics
Let’s talk about some examples of operational analytics.
Software program recreation builders
For example that you’re a software program recreation developer and also you need your recreation to mechanically upsell a sure characteristic of your recreation relying on the gamer’s taking part in habits and the present state of all of the gamers within the present recreation. That is an operational analytics question as a result of it permits the sport developer to make instantaneous choices primarily based on evaluation of present occasions.
Product managers
Again within the day, product managers used to do quite a bit handbook work, speaking to clients, asking them how they use the product, what options within the product gradual them down, and so on. Within the age of operational analytics, a product supervisor can collect all these solutions by querying information that data utilization patterns from the product’s consumer base; and she or he can instantly feed that data again to make the product higher.
Advertising managers
Equally, within the case of promoting analytics, a advertising supervisor would use to prepare just a few focus teams, check out just a few experiments primarily based on their very own creativity after which implement them. Relying on the outcomes of experimentation, they’d then resolve what to do subsequent. An experiment could take weeks or months. We are actually seeing the rise of the “advertising engineer,” an individual who’s well-versed in utilizing information programs.
These advertising engineers can run a number of experiments without delay, collect outcomes from experiments within the type of information, terminate the ineffective experiments and nurture those that work, all via using data-based software program programs. The extra experiments they’ll run and the faster the turnaround instances of outcomes, the higher their effectiveness in advertising their product. That is one other type of operational analytics.
Definition of Operational Analytics Processing
An operational analytics system helps you make instantaneous choices from reams of real-time information. You gather new information out of your information sources and so they all stream into your operational information engine. Your user-facing interactive apps question the identical information engine to fetch insights out of your information set in actual time, and also you then use that intelligence to offer a greater consumer expertise to your customers.
Ah, you may say that you’ve got seen this “beast” earlier than. In truth, you is perhaps very, very accustomed to a system that…
- encompasses your information pipeline that sources information from varied sources
- deposits it into your information lake or information warehouse
- runs varied transformations to extract insights, after which…
- parks these nuggets of knowledge in a key-value retailer for quick retrieval by your interactive user-facing functions
And you’ll be completely proper in your evaluation: an equal engine that has your entire set of those above capabilities is an operational analytics processing system!
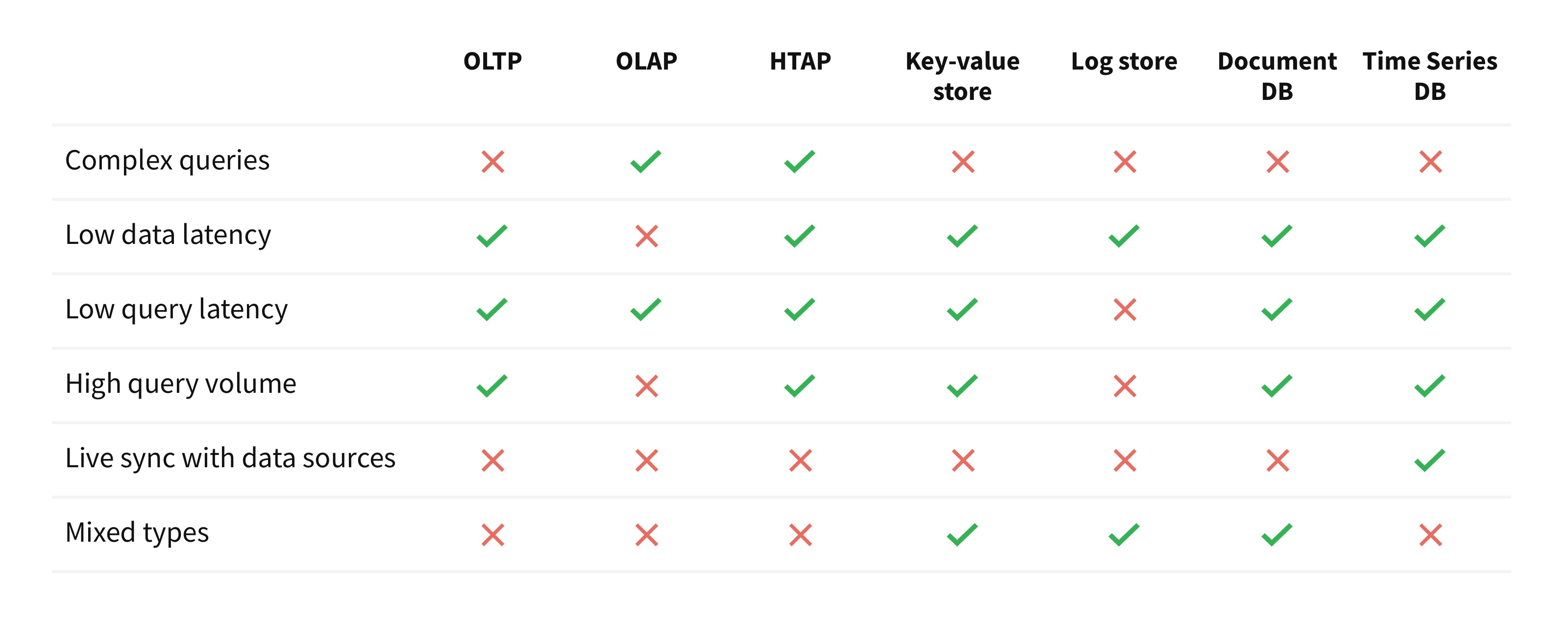
The definition of an operational analytics processing engine might be expressed within the type of the next six propositions:
- Advanced queries: Assist for queries like joins, aggregations, sorting, relevance, and so on.
- Low information latency: An replace to any information report is seen in question leads to underneath than just a few seconds.
- Low question latency: A easy search question returns in underneath just a few milliseconds.
- Excessive question quantity: Capable of serve a minimum of just a few hundred concurrent queries per second.
- Stay sync with information sources: Potential to maintain itself in sync with varied exterior sources with out having to write down exterior scripts. This may be accomplished through change-data-capture of an exterior database, or by tailing streaming information sources.
- Blended sorts: Permits values of various sorts in the identical column. That is wanted to have the ability to ingest new information while not having to wash them at write time.
Let’s talk about every of the above propositions in better element and talk about why every of the above options is critical for an operational analytics processing engine.
Proposition 1: Advanced queries
A database, in any conventional sense, permits the appliance to specific complicated information operations in a declarative approach. This permits the appliance developer to not must explicitly perceive information entry patterns, information optimizations, and so on. and frees him/her to give attention to the appliance logic. The database would assist filtering, sorting, aggregations, and so on. to empower the appliance to course of information effectively and rapidly. The database would assist joins throughout two or extra information units in order that an utility may mix the data from a number of sources to extract intelligence from them.
For instance, SQL, HiveQL, KSQL and so on. present declarative strategies to specific complicated information operations on information units. They’ve various expressive powers: SQL helps full joins whereas KSQL doesn’t.
Proposition 2: Low information latency
An operational analytics database, not like a transactional database, doesn’t have to assist transactions. The functions that use this sort of a database use it to retailer streams of incoming information; they don’t use the database to report transactions. The incoming information charge is bursty and unpredictable. The database is optimized for high-throughout writes and helps an eventual consistency mannequin the place newly written information turns into seen in a question inside just a few seconds at most.
Proposition 3: Low question latency
An operational analytics database is in a position to reply to queries rapidly. On this respect, it is rather just like transactional databases like Oracle, PostgreSQL, and so on. It’s optimized for low-latency queries somewhat than throughput. Easy queries end in just a few milliseconds whereas complicated queries scale out to complete rapidly as effectively. This is among the fundamental necessities to have the ability to energy any interactive utility.
Proposition 4: Excessive question quantity
A user-facing utility usually makes many queries in parallel, particularly when a number of customers are utilizing the appliance concurrently. For instance, a gaming utility may need many customers taking part in the identical recreation on the identical time. A fraud detection utility is perhaps processing a number of transactions from totally different customers concurrently and may have to fetch insights about every of those customers in parallel. An operational analytics database is able to supporting a excessive question charge, starting from tens of queries per second (e.g. dwell dashboard) to hundreds of queries per second (e.g. a web based cell app).
Proposition 5: Stay sync with information sources
A web-based analytics database lets you mechanically and repeatedly sync information from a number of exterior information sources. With out this characteristic, you’ll create yet one more information silo that’s tough to take care of and babysit.
You have got your personal system-of-truth databases, which could possibly be Oracle or DynamoDB, the place you do your transactions, and you’ve got occasion logs in Kafka; however you want a single place the place you need to herald all these information units and mix them to generate insights. The operational analytics database has built-in mechanisms to ingest information from quite a lot of information sources and mechanically sync them into the database. It might use change-data-capture to repeatedly replace itself from upstream information sources.
Proposition 6: Blended sorts
An analytics system is tremendous helpful when it is ready to retailer two or extra various kinds of objects in the identical column. With out this characteristic, you would need to clear up the occasion stream earlier than you possibly can write it to the database. An analytics system can present low information latency provided that cleansing necessities when new information arrives is diminished to a minimal. Thus, an operational analytics database has the potential to retailer objects of blended sorts throughout the identical column.
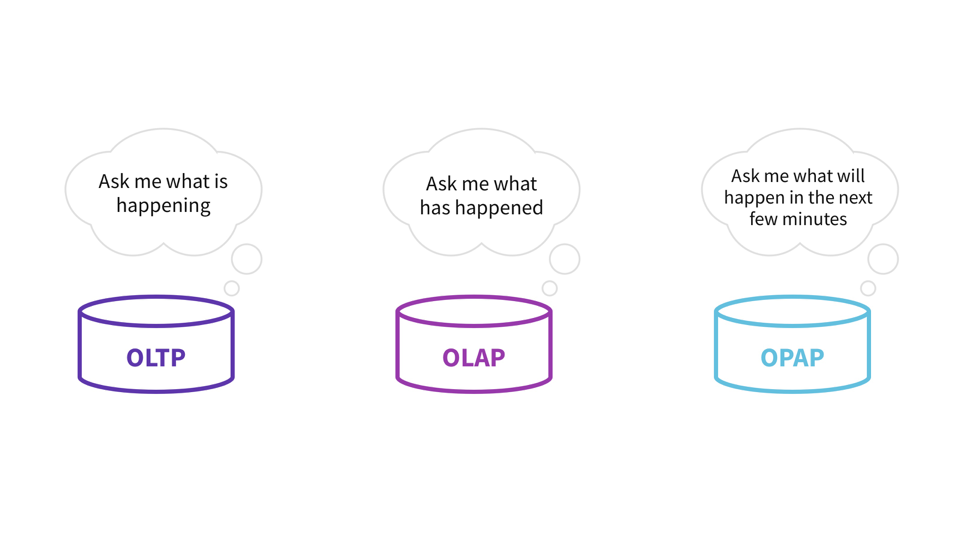
The six above traits are distinctive to an OPerational Analytics Processing (OPAP) system.

Architectural Uniqueness of an OPAP System
The Database LOG
The Database is the LOG; it durably shops information. It’s the “D” in ACID programs. Let’s analyze the three sorts of information processing programs so far as their LOG is anxious.
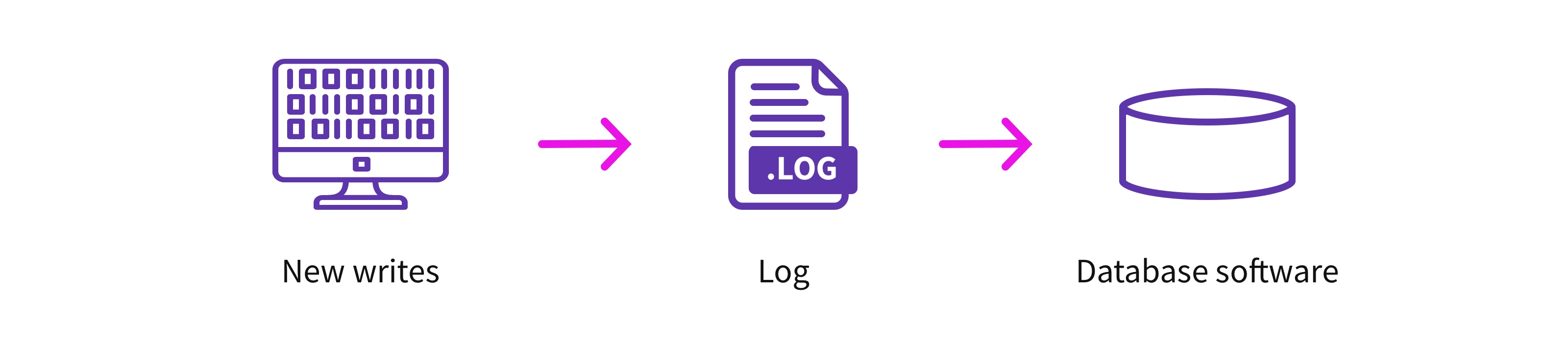
The first use of an OLTP system is to ensure some types of sturdy consistency between updates and reads. In these instances the LOG is behind the database server(s) that serves queries. For instance, an OLTP system like PostgreSQL has a database server; updates arrive on the database server, which then writes it to the LOG. Equally, Amazon Aurora‘s database server(s) receives new writes, appends transactional data (like sequence quantity, transaction quantity, and so on.) to the write after which persists it within the LOG. On each of those instances, the LOG is hidden behind the transaction engine as a result of the LOG must retailer metadata concerning the transaction.

Equally, many OLAP programs assist some fundamental type of transactions as effectively. For instance, the OLAP Snowflake Knowledge Warehouse explicitly states that it’s designed for bulk updates and trickle inserts (see Part 3.3.2 titled Concurrency Management). They use a copy-on-write strategy for complete datafiles and a world key-value retailer because the LOG. The database servers fronting the LOG implies that streaming write charges are solely as quick because the database servers can deal with.
However, an OPAP system’s main aim is to assist a excessive replace charge and low question latency. An OPAP system doesn’t have the idea of a transaction. As such, an OPAP system has the LOG in entrance of the database servers, the reason is that the log is required just for sturdiness. Making the database be fronted by the log is advantageous: the log can function a buffer for giant write volumes within the face of sudden bursty write storms. A log can assist a a lot larger write charge as a result of it’s optimized for writes and never for random reads.
Sort binding at question time and never at write time
OLAP databases affiliate a set kind for each column within the database. Which means each worth saved in that column conforms to the given kind. The database checks for conformity when a brand new report is written to the database. If a subject of a brand new report doesn’t adhere to the desired kind of the column, the report is both discarded or a failure is signaled. To keep away from most of these errors, OLAP database are fronted by an information pipeline that cleans and validates each new report earlier than it’s inserted to the database.
Instance
Let’s say {that a} database has a column known as ‘zipcode’. We all know that zip code are integers within the US whereas zipcodes within the UK can have each letters and digits. In an OLAP database, now we have to transform each of those to the ‘string’ kind earlier than we are able to retailer them in the identical column. However as soon as we retailer them as strings within the database, we lose the power to make integer comparisons as a part of the question on this column. For instance, a question of the kind choose rely(*) from desk the place zipcode > 1000 will throw an error as a result of we’re doing an integral vary examine however the column kind is a string.
However an OPAP database doesn’t have a set kind for each column within the database. As an alternative, the kind is related to each particular person worth saved within the column. The ‘zipcode’ subject in an OPAP database is able to storing each most of these data in the identical column with out dropping the kind data of each subject.
Going additional, for the above question choose rely(*) from desk the place zipcode > 1000, the database may examine and match solely these values within the column which can be integers and return a legitimate end result set. Equally, a question choose rely(*) from desk the place zipcode=’NW89EU’ may match solely these data which have a price of kind ‘string’ and return a legitimate end result set.
Thus, an OPAP database can assist a powerful schema, however implement the schema binding at question time somewhat than at information insertion time. That is what’s termed sturdy dynamic typing.
Comparisons with Different Knowledge Programs
Now that we perceive the necessities of an OPAP database, let’s evaluate and distinction different present information options. Particularly, let’s evaluate its options with an OLTP database, an OLAP information warehouse, an HTAP database, a key-value database, a distributed logging system, a doc database and a time-series database. These are a few of the widespread programs which can be in use at the moment.
Examine with an OLTP database
An OLTP system is used to course of transactions. Typical examples of transactional programs are Oracle, Spanner, PostgreSQL, and so on. The programs are designed for low-latency updates and inserts, and these writes are throughout failure domains in order that the writes are sturdy. The first design focus of those programs is to not lose a single replace and to make it sturdy. A single question usually processes just a few kilobytes of knowledge at most. They’ll maintain a excessive question quantity, however not like an OPAP system, a single question isn’t anticipated to course of megabytes or gigabytes of knowledge in milliseconds.
Examine with an OLAP information warehouse
- An OLAP information warehouse can course of very complicated queries on massive datasets and is just like an OPAP system on this regard. Examples of OLAP information warehouses are Amazon Redshift and Snowflake. However that is the place the similarity ends.
- An OLAP system is designed for total system throughput whereas OPAP is designed for the bottom of question latencies.
- An OLAP information warehouse can have an total excessive write charge, however not like a OPAP system, writes are batched and inserted into the database periodically.
- An OLAP database requires a strict schema at information insertion time, which primarily implies that schema binding occurs at information write time. However, an OPAP database natively understands semi-structured schema (JSON, XML, and so on.) and the strict schema binding happens at question time.
- An OLAP warehouse helps a low variety of concurrent queries (e.g. Amazon Redshift helps as much as 50 concurrent queries), whereas a OPAP system can scale to assist massive numbers of concurrent queries.
Examine with an HTAP database
An HTAP database is a mixture of each OLTP and OLAP programs. Which means the variations talked about within the above two paragraphs apply to HTAP programs as effectively. Typical HTAP programs embody SAP HANA and MemSQL.
Examine with a key-value retailer
Key-Worth (KV) shops are recognized for pace. Typical examples of KV shops are Cassandra and HBase. They supply low latency and excessive concurrency however that is the place the similarity with OPAP ends. KV shops don’t assist complicated queries like joins, sorting, aggregations, and so on. Additionally, they’re information silos as a result of they don’t assist the auto-sync of knowledge from exterior sources and thus violate Proposition 5.
Examine with a logging system
A log retailer is designed for prime write volumes. It’s appropriate for writing a excessive quantity of updates. Apache Kafka and Apache Samza are examples of logging programs. The updates reside in a log, which isn’t optimized for random reads. A logging system is sweet at windowing capabilities however doesn’t assist arbitrary complicated queries throughout your entire information set.
Examine with a doc database
A doc database natively helps a number of information codecs, usually JSON. Examples of a doc database are MongoDB, Couchbase and Elasticsearch. Queries are low latency and might have excessive concurrency however they don’t assist complicated queries like joins, sorting and aggregations. These databases don’t assist automated methods to sync new information from exterior sources, thus violating Proposition 5.
Examine with a time-series database
A time-series database is a specialised operational analytics database. Queries are low latency and it will possibly assist excessive concurrency of queries. Examples of time-series databases are Druid, InfluxDB and TimescaleDB. It will probably assist a fancy aggregations on one dimension and that dimension is ‘time’. However, an OPAP system can assist complicated aggregations on any data-dimension and never simply on the ‘time’ dimension. Time sequence database aren’t designed to hitch two or extra information units whereas OPAP programs can be a part of two or extra datasets as a part of a single question.
References
- Techopedia: https://www.techopedia.com/definition/29495/operational-analytics
- Andreessen Horowitz: https://a16z.com/2019/05/16/everyone-is-an-analyst-opportunities-in-operational-analytics/
- Forbes: https://www.forbes.com/websites/forbestechcouncil/2019/06/11/from-good-to-great-how-operational-analytics-can-give-businesses-a-real-time-edge/
- Gartner: https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo
- Tech Republic: https://www.techrepublic.com/article/how-data-scientists-can-help-operational-analytics-succeed/
- Quora: https://www.quora.com/What-is-Operations-Analytics
 !
!
{kind=link}