
What’s the quickest we will load knowledge into RocksDB? We had been confronted with this problem as a result of we wished to allow our prospects to shortly check out Rockset on their huge datasets. Despite the fact that the majority load of information in LSM timber is a crucial subject, not a lot has been written about it. On this put up, we’ll describe the optimizations that elevated RocksDB’s bulk load efficiency by 20x. Whereas we needed to resolve fascinating distributed challenges as nicely, on this put up we’ll give attention to single node optimizations. We assume some familiarity with RocksDB and the LSM tree knowledge construction.
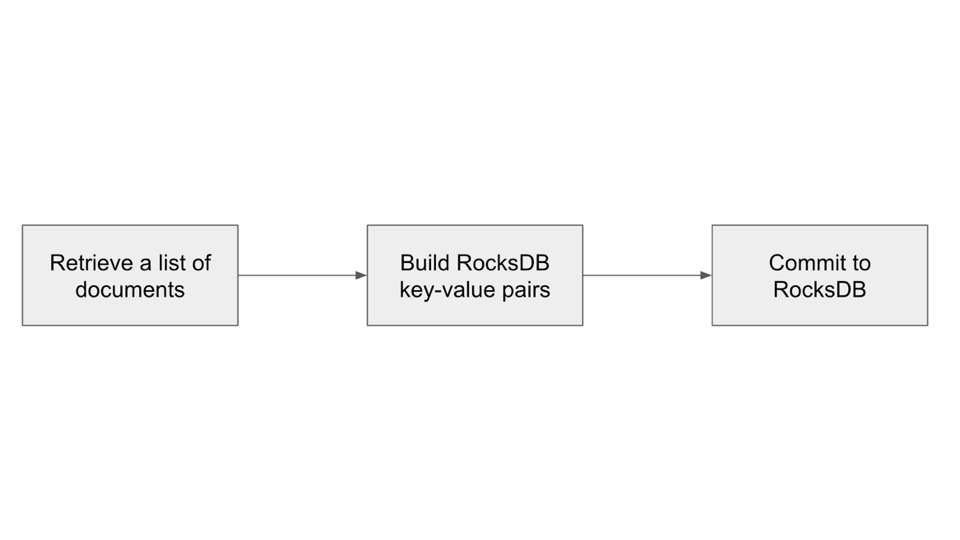
Rockset’s write course of comprises a few steps:
- In step one, we retrieve paperwork from the distributed log retailer. One doc symbolize one JSON doc encoded in a binary format.
- For each doc, we have to insert many key-value pairs into RocksDB. The subsequent step converts the checklist of paperwork into an inventory of RocksDB key-value pairs. Crucially, on this step, we additionally must learn from RocksDB to find out if the doc already exists within the retailer. If it does we have to replace secondary index entries.
- Lastly, we commit the checklist of key-value pairs to RocksDB.

We optimized this course of for a machine with many CPU cores and the place an affordable chunk of the dataset (however not all) matches in the principle reminiscence. Totally different approaches would possibly work higher with small variety of cores or when the entire dataset matches into major reminiscence.
Buying and selling off Latency for Throughput
Rockset is designed for real-time writes. As quickly because the buyer writes a doc to Rockset, now we have to use it to our index in RocksDB. We don’t have time to construct an enormous batch of paperwork. It is a disgrace as a result of rising the dimensions of the batch minimizes the substantial overhead of per-batch operations. There is no such thing as a must optimize the person write latency in bulk load, although. Throughout bulk load we improve the dimensions of our write batch to tons of of MB, naturally resulting in the next write throughput.
Parallelizing Writes
In a daily operation, we solely use a single thread to execute the write course of. That is sufficient as a result of RocksDB defers a lot of the write processing to background threads by compactions. A few cores additionally must be out there for the question workload. Through the preliminary bulk load, question workload is just not vital. All cores needs to be busy writing. Thus, we parallelized the write course of — as soon as we construct a batch of paperwork we distribute the batch to employee threads, the place every thread independently inserts knowledge into RocksDB. The vital design consideration right here is to reduce unique entry to shared knowledge constructions, in any other case, the write threads can be ready, not writing.
Avoiding Memtable
RocksDB provides a function the place you’ll be able to construct SST information by yourself and add them to RocksDB, with out going by the memtable, known as IngestExternalFile(). This function is nice for bulk load as a result of write threads don’t need to synchronize their writes to the memtable. Write threads all independently type their key-value pairs, construct SST information and add them to RocksDB. Including information to RocksDB is an affordable operation because it entails solely a metadata replace.
Within the present model, every write thread builds one SST file. Nevertheless, with many small information, our compaction is slower than if we had a smaller variety of larger information. We’re exploring an strategy the place we’d type key-value pairs from all write threads in parallel and produce one huge SST file for every write batch.
Challenges with Turning off Compactions
The commonest recommendation for bulk loading knowledge into RocksDB is to show off compactions and execute one huge compaction in the long run. This setup can be talked about within the official RocksDB Efficiency Benchmarks. In any case, the one purpose RocksDB executes compactions is to optimize reads on the expense of write overhead. Nevertheless, this recommendation comes with two crucial caveats.
At Rockset now we have to execute one learn for every doc write – we have to do one major key lookup to examine if the brand new doc already exists within the database. With compactions turned off we shortly find yourself with hundreds of SST information and the first key lookup turns into the largest bottleneck. To keep away from this we constructed a bloom filter on all major keys within the database. Since we often don’t have duplicate paperwork within the bulk load, the bloom filter permits us to keep away from costly major key lookups. A cautious reader will discover that RocksDB additionally builds bloom filters, but it surely does so per file. Checking hundreds of bloom filters continues to be costly.
The second downside is that the ultimate compaction is single-threaded by default. There’s a function in RocksDB that allows multi-threaded compaction with choice max_subcompactions. Nevertheless, rising the variety of subcompactions for our remaining compaction doesn’t do something. With all information in stage 0, the compaction algorithm can not discover good boundaries for every subcompaction and decides to make use of a single thread as an alternative. We fastened this by first executing a priming compaction — we first compact a small variety of information with CompactFiles(). Now that RocksDB has some information in non-0 stage, that are partitioned by vary, it will probably decide good subcompaction boundaries and the multi-threaded compaction works like a attraction with all cores busy.
Our information in stage 0 usually are not compressed — we don’t wish to decelerate our write threads and there’s a restricted profit of getting them compressed. Ultimate compaction compresses the output information.
Conclusion
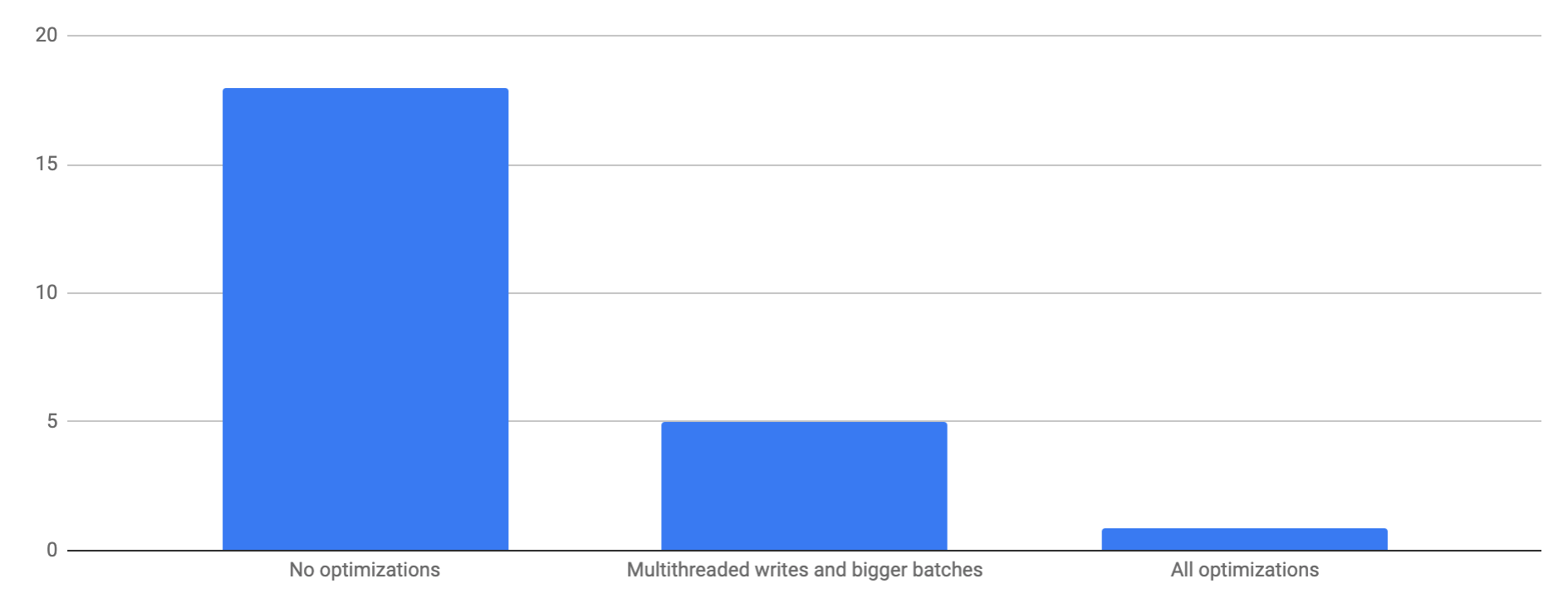
With these optimizations, we will load a dataset of 200GB uncompressed bodily bytes (80GB with LZ4 compression) in 52 minutes (70 MB/s) whereas utilizing 18 cores. The preliminary load took 35min, adopted by 17min of ultimate compaction. With not one of the optimizations the load takes 18 hours. By solely rising the batch dimension and parallelizing the write threads, with no modifications to RocksDB, the load takes 5 hours. Observe that each one of those numbers are measured on a single node RocksDB occasion. Rockset parallelizes writes on a number of nodes and might obtain a lot increased write throughput.
Bulk loading of information into RocksDB could be modeled as a big parallel type the place the dataset doesn’t match into reminiscence, with an extra constraint that we additionally must learn some a part of the info whereas sorting. There’s plenty of fascinating work on parallel type on the market and we hope to survey some strategies and check out making use of them in our setting. We additionally invite different RocksDB customers to share their bulk load methods.
I’m very grateful to everyone who helped with this undertaking — our superior interns Jacob Klegar and Aditi Srinivasan; and Dhruba Borthakur, Ari Ekmekji and Kshitij Wadhwa.
Study extra about how Rockset makes use of RocksDB:

{kind=link}