

Knowledge lakes on Amazon Easy Storage Service (Amazon S3) have develop into the default repository for all enterprise knowledge and function a standard selection for numerous customers querying from quite a lot of analytics and machine studying (ML) instruments. Oftentimes you need to ingest knowledge repeatedly into the information lake from a number of sources and question towards the information lake from many analytics instruments concurrently with transactional capabilities. Options like supporting ACID transactions, schema enforcement, and time journey on an S3 knowledge lake have develop into an more and more well-liked requirement with the intention to construct a high-performance transactional knowledge lake operating analytics queries that return constant and up-to-date outcomes. AWS is designed to offer a number of choices so that you can implement transactional capabilities in your S3 knowledge lake, together with Apache Hudi, Apache Iceberg, AWS Lake Formation ruled tables, and open-source Delta Lake.
Amazon EMR is a cloud large knowledge platform for operating large-scale distributed knowledge processing jobs, interactive SQL queries, and ML purposes utilizing open-source analytics frameworks reminiscent of Apache Spark, Apache Hive, and Presto.
Delta Lake is an open-source challenge that helps implement fashionable knowledge lake architectures generally constructed on Amazon S3 or HDFS. Delta Lake affords the next functionalities:
- Ensures ACID transactions (atomic, constant, remoted, sturdy) on Spark in order that readers proceed to see a constant view of the desk throughout a Spark job
- Scalable metadata dealing with utilizing Spark’s distributed processing
- Combining streaming and batch makes use of instances utilizing the identical Delta desk
- Automated schema enforcements to keep away from unhealthy data throughout knowledge ingestion
- Time journey utilizing knowledge versioning
- Assist for merge, replace and delete operations to allow advanced use instances like change knowledge seize (CDC), slowly altering dimension (SCD) operations, streaming upserts, and extra
On this submit, we present how one can run open-source Delta Lake (model 2.0.0) on Amazon EMR. For demonstration functions, we use Amazon EMR Studio notebooks to stroll via its transactional capabilities:
- Learn
- Replace
- Delete
- Time journey
- Upsert
- Schema evolution
- Optimizations with file administration
- Z-ordering (multi-dimensional clustering)
- Knowledge skipping
- Multipart checkpointing
Transactional knowledge lake options on AWS
Amazon S3 is the most important and most performant object storage service for structured and unstructured knowledge and the storage service of option to construct a knowledge lake. With Amazon S3, you may cost-effectively construct and scale a knowledge lake of any measurement in a safe setting the place knowledge is protected by 99.999999999% (11 9s) of sturdiness.
Historically, clients have used Hive or Presto as a SQL engine on high of an S3 knowledge lake to question the information. Nonetheless, neither SQL engine comes with ACID compliance inherently, which is required to construct a transactional knowledge lake. A transactional knowledge lake requires properties like ACID transactions, concurrency controls, schema evolution, time journey, and concurrent upserts and inserts to construct quite a lot of use instances processing petabyte-scale knowledge. Amazon EMR is designed to offer a number of choices to construct a transactional knowledge lake:
- Apache Hudi – Apache Hudi is an open-source transactional knowledge lake framework that enormously simplifies incremental knowledge processing and knowledge pipeline growth. Beginning with launch model 5.28, Amazon EMR installs Hudi elements by default when Spark, Hive, or Presto are put in. Since then, a number of new capabilities and bug fixes have been added to Apache Hudi and integrated into Amazon EMR. Amazon EMR 6.7.0 accommodates Hudi model 0.11.0. For the model of elements put in with Hudi in numerous Amazon EMR releases, see the Amazon EMR Launch Information.
- Apache Iceberg – Apache Iceberg is an open desk format for enormous analytic datasets. Desk codecs sometimes point out the format and site of particular person desk recordsdata. Iceberg provides performance on high of that to assist handle petabyte-scale datasets in addition to newer knowledge lake necessities reminiscent of transactions, upsert or merge, time journey, and schema and partition evolution. Iceberg provides tables to compute engines together with Spark, Trino, PrestoDB, Flink, and Hive utilizing a high-performance desk format that works similar to a SQL desk. Beginning with Amazon EMR launch 6.5.0 (Amazon EMR model 6.7.0 helps Iceberg 0.13.1), you may reliably work with enormous tables with full help for ACID transactions in a extremely concurrent and performant method with out getting locked right into a single file format.
- Open-source Delta Lake – You too can construct your transactional knowledge lake by launching Delta Lake from Amazon EMR utilizing Amazon EMR Serverless, Amazon EMR on EKS, or Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) by including Delta JAR packages to the Spark classpath to run interactive and batch workloads.
- Lake Formation ruled tables – We introduced the overall availability of Lake Formation transactions, row-level safety, and acceleration at AWS re:Invent 2021. These capabilities can be found by way of new replace and entry APIs that stretch the governance capabilities of Lake Formation with row-level safety, and supply transactions over knowledge lakes. For extra data, confer with Efficient knowledge lakes utilizing AWS Lake Formation, Half 3: Utilizing ACID transactions on ruled tables.
Though all these choices have their very own deserves, this submit focuses on Delta Lake to offer extra flexibility to our clients to construct your transactional knowledge lake platform utilizing your software of selection. Delta Lake supplies many capabilities, together with snapshot isolation and environment friendly DML and rollback. It supplies improved efficiency via options like Z-order partitioning and file optimizations via compaction.
Answer overview
Navigate via the steps supplied on this submit to implement Delta Lake on Amazon EMR. You may entry the pattern pocket book from the GitHub repo. You too can discover this pocket book in your EMR Studio workspace below Pocket book Examples.
Conditions
To stroll via this submit, we use Delta Lake model 2.0.0, which is supported in Apache Spark 3.2.x. Select the Delta Lake model appropriate together with your Spark model by visiting the Delta Lake releases web page. We create an EMR cluster utilizing the AWS Command Line Interface (AWS CLI). We use Amazon EMR 6.7.0, which helps Spark model 3.2.1.
Arrange Amazon EMR and Delta Lake
We use the bootstrap motion to put in Delta Lake on the EMR cluster. Create the next script and retailer it into your S3 bucket (for instance, s3://<your bucket>/bootstrap/deltajarinstall.sh) for use for bootstrap motion:
Use the next AWS CLI command to create an EMR cluster with the next purposes put in: Hadoop, Spark, Livy, and Jupyter Enterprise Gateway. You too can use the Amazon EMR console to create an EMR cluster with the bootstrap motion. Substitute <your subnet> with one of many subnets through which your EMR Studio is operating. On this instance, we use a public subnet as a result of we want web connectivity to obtain the required JAR recordsdata for the bootstrap motion. Should you use a non-public subnet, chances are you’ll have to configure community tackle translation (NAT) and VPN gateways to entry companies or sources situated exterior of the VPC. Replace <your-bucket> together with your S3 bucket.
Arrange Amazon EMR Studio
We use EMR Studio to launch our pocket book setting to check Delta Lake PySpark codes on our EMR cluster. EMR Studio is an built-in growth setting (IDE) that makes it simple for knowledge scientists and knowledge engineers to develop, visualize, and debug knowledge engineering and knowledge science purposes written in R, Python, Scala, and PySpark. For setup directions, confer with Arrange an Amazon EMR Studio. Alternatively, you can too arrange EMR Notebooks as a substitute of EMR Studio.
- To arrange Apache Spark with Delta Lake, use the next configuration within the PySpark pocket book cell:
- Import the packages wanted for this instance:
- Arrange a desk location setting variable deltaPath:
- Create Delta tables.
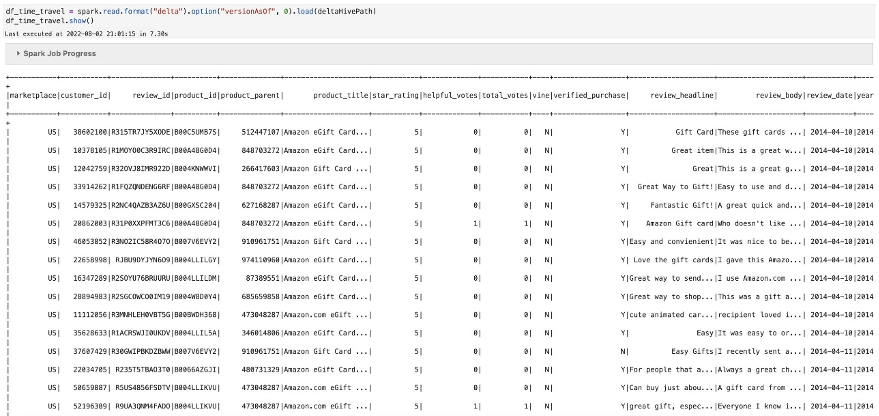
Now you can begin operating some Spark assessments on recordsdata transformed to Delta format. To do this, we learn a public dataset (Amazon Product Opinions Dataset) and write the information in Delta Lake format to the S3 bucket that we created within the earlier step. - Learn the Amazon Product Opinions Parquet file within the DataFrame (we’re loading one partition for the sake of simplicity):
- Test the DataFrame schema:

- Convert the Parquet file and write the information to Amazon S3 in Delta desk format:
Test the Amazon S3 location that you simply laid out in
deltaPathfor brand new objects created within the bucket. Discover the_delta_logfolder that obtained created within the S3 bucket. That is the metadata listing for the transaction log of a Delta desk. This listing accommodates transaction logs or change logs of all of the adjustments to the state of a Delta desk.
- You too can set the desk location in Spark config, which lets you learn the information utilizing SQL format:
Question Delta tables with DML operations
Now that we’ve efficiently written knowledge in Amazon S3 in Delta Lake 2.0.0 desk format, let’s question the Delta Lake and discover Delta desk options.
Learn
We begin with the next question:
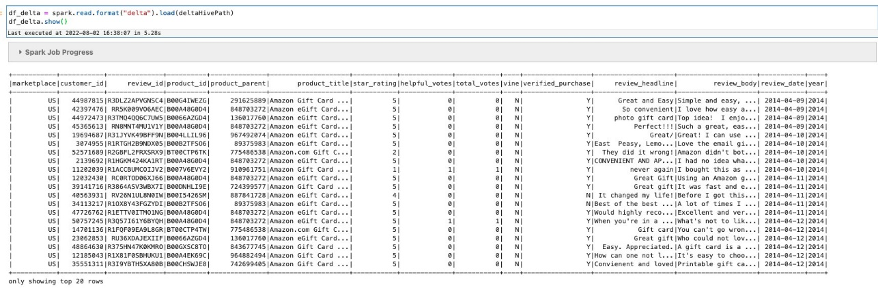
You too can use normal SQL statements, despite the fact that the desk has not but been created or registered inside a knowledge catalog (reminiscent of a Hive metastore or the AWS Glue Knowledge Catalog). On this case, Delta permits using a particular notation delta.TABLE_PATH to deduce the desk metadata straight from a selected location. For tables which can be registered in a metastore, the LOCATION path parameter is non-compulsory. If you create a desk with a LOCATION parameter, the desk is taken into account unmanaged by the metastore. If you difficulty a DROP assertion on a managed desk with out the trail possibility, the corresponding knowledge recordsdata are deleted, however for unmanaged tables, the DROP operation doesn’t delete the information recordsdata beneath.
Replace
Firstly, run the next step to outline the Delta desk:
Now let’s replace a column and observe how the Delta desk reacts. We replace {the marketplace} column and exchange the worth US with USA. There are completely different syntaxes accessible to carry out the replace.
You need to use the next code:
Alternatively, use the next code:
The next is a 3rd technique:
Take a look at if the replace was profitable:
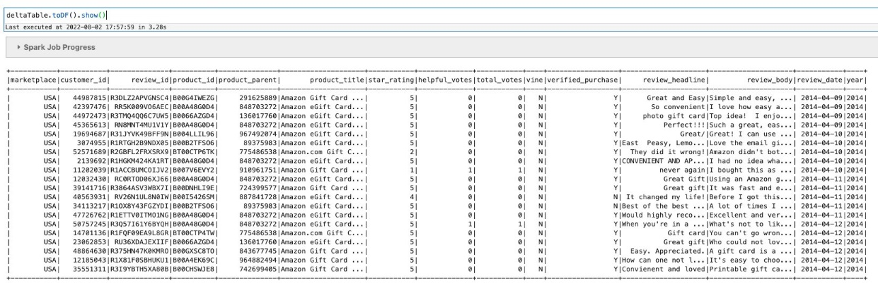
You may see that the market worth modified from US to USA.
Delete
GDPR and CCPA rules mandate the well timed removing of particular person buyer knowledge and different data from datasets. Let’s delete a document from our Delta desk.
Test the existence of data within the file with verified_purchase="N":
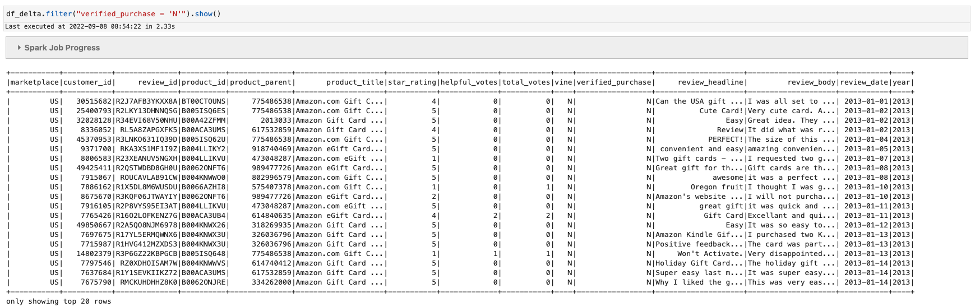
Then delete all data from the desk for verified_purchase="N":
If you run the identical command once more to verify the existence of data within the file with verified_purchase="N", no rows can be found.

Notice that the delete technique removes the information solely from the most recent model of a desk. These data are nonetheless current in older snapshots of the information.
To view the earlier desk snapshots for the deleted data, run the next command:
Time journey
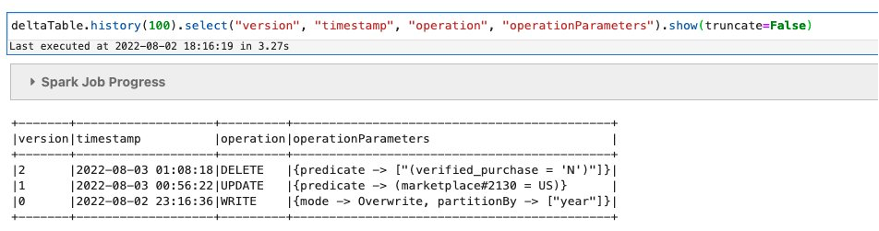
To view the Delta desk historical past, run the next command. This command retrieves data on the model, timestamp, operation, and operation parameters for every write to a Delta desk.
You may see the historical past within the output, with the latest replace to the desk showing on the high. You’ll find the variety of variations of this desk by checking the model column.
Within the earlier instance, you checked the variety of variations accessible for this desk. Now let’s verify the oldest model of the desk (model 0) to see the earlier market worth (US) earlier than the replace and the data which were deleted:
market is displaying as US, and you can too see the verified_purchase = ‘N’ data.
To erase knowledge historical past from the bodily storage, it is advisable explicitly vacuum older variations.
Upsert
You may upsert knowledge from an Apache Spark DataFrame right into a Delta desk utilizing the merge operation. This operation is just like the SQL MERGE command however has extra help for deletes and additional situations in updates, inserts, and deletes. For extra data, confer with Upsert right into a desk utilizing merge.
Create some data to organize for the upsert operation we carry out in a later stage. We create a dataset that we use to replace the document in the principle desk for "review_id":'R315TR7JY5XODE' and add a brand new document for "review_id":'R315TR7JY5XOA1':
Create a Spark DataFrame for data_upsert:
Now let’s carry out the upsert with the Delta Lake merge operation. On this instance, we replace the document in the principle desk for "review_id":'R315TR7JY5XODE' and add a brand new document for "review_id":'R315TR7JY5XOA1' utilizing the data_upsert DataFrame we created:
(deltaTable.alias('t').merge(df_data_upsert.alias('u'), 't.review_id = u.review_id').whenMatchedUpdateAll().whenNotMatchedInsertAll().execute())
Question the merged desk:

Now examine the earlier output with the oldest model of the desk by utilizing the time journey DataFrame:

Discover that for "review_id":'R315TR7JY5XODE', many column values like product_id, product_parent, helpful_votes, review_headline, and review_body obtained up to date.
Schema evolution
By default, updateAll and insertAll assign all of the columns within the goal Delta desk with columns of the identical title from the supply dataset. Any columns within the supply dataset that don’t match columns within the goal desk are ignored.
Nonetheless, in some use instances, it’s fascinating to routinely add supply columns to the goal Delta desk. To routinely replace the desk schema throughout a merge operation with updateAll and insertAll (at the least certainly one of them), you may set the Spark session configuration spark.databricks.delta.schema.autoMerge.enabled to true earlier than operating the merge operation.
Schema evolution happens solely when there’s both an updateAll (UPDATE SET *) or an insertAll (INSERT *) motion, or each.
Optimization with file administration
Delta Lake supplies a number of optimization choices to speed up the efficiency of your knowledge lake operations. On this submit, we present how one can implement Delta Lake optimization with file administration.
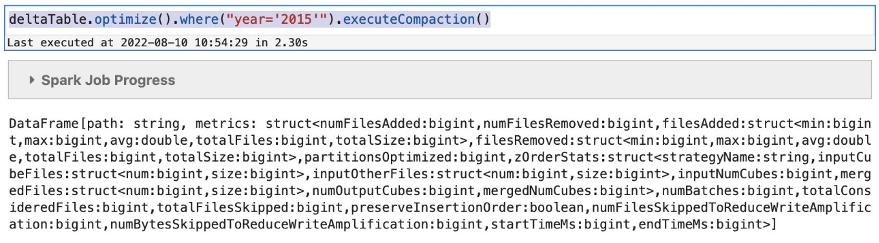
With Delta Lake, you may optimize the format of information storage to enhance question efficiency. You need to use the next command to optimize the storage format of the entire desk:
To cut back the scope of optimization for very giant tables, you may embrace a the place clause situation:
Z-ordering
Delta Lake makes use of Z-ordering to scale back the quantity of information scanned by Spark jobs. To carry out the Z-order of information, you specify the columns to order within the ZORDER BY clause. Within the following instance, we’re Z-ordering the desk primarily based on a low cardinality column verified_purchase:
Knowledge skipping
Delta Lake routinely collects knowledge skipping data in the course of the Delta Lake write operations. Delta Lake refers back to the minimal and most values for every column at runtime to speed up the question efficiency. This characteristic is routinely activated and there’s no have to make any adjustments within the utility.
Multipart checkpointing
Delta Lake routinely compacts all of the incremental updates to the Delta logs right into a Parquet file. This checkpointing permits quicker reconstruction of the present state. With the SQL configuration spark.databricks.delta.checkpoint.partSize=<n>, (the place n is the restrict of variety of actions, reminiscent of AddFile), Delta Lake can parallelize the checkpoint operation and write every checkpoint in a single Parquet file.
Clear up
To keep away from ongoing prices, delete the S3 buckets and EMR Studio, and cease the EMR cluster used for experimentation of this submit.
Conclusion
On this submit, we mentioned the way to configure open-source Delta Lake with Amazon EMR, which helps you create a transactional knowledge lake platform to help a number of analytical use instances. We demonstrated how you should use completely different sorts of DML operations on a Delta desk. Take a look at the pattern Jupyter pocket book used within the walkthrough. We additionally shared some new options provided by Delta Lake, reminiscent of file compaction and Z-ordering. You may implement these new options to optimize the efficiency of the large-scale knowledge scan on a knowledge lake setting. As a result of Amazon EMR helps two ACID file codecs (Apache Hudi and Apache Iceberg) out of the field, you may simply construct a transactional knowledge lake to boost your analytics capabilities. With the pliability supplied by Amazon EMR, you may set up the open-source Delta Lake framework on Amazon EMR with the intention to help a wider vary of transactional knowledge lake wants primarily based on numerous use instances.
Now, you should use the most recent open-source model of Delta Lake utilizing the bootstrap actions proven on this submit to run on Amazon EMR to construct your transactional knowledge lake.
Concerning the Authors
 Avijit Goswami is a Principal Options Architect at AWS specialised in knowledge and analytics. He helps AWS strategic clients in constructing high-performing, safe, and scalable knowledge lake options on AWS utilizing AWS managed companies and open-source options. Exterior of his work, Avijit likes to journey, hike within the San Francisco Bay Space trails, watch sports activities, and take heed to music.
Avijit Goswami is a Principal Options Architect at AWS specialised in knowledge and analytics. He helps AWS strategic clients in constructing high-performing, safe, and scalable knowledge lake options on AWS utilizing AWS managed companies and open-source options. Exterior of his work, Avijit likes to journey, hike within the San Francisco Bay Space trails, watch sports activities, and take heed to music.
 Ajit Tandale is a Huge Knowledge Options Architect at Amazon Internet Companies. He helps AWS strategic clients speed up their enterprise outcomes by offering experience in large knowledge utilizing AWS managed companies and open-source options. Exterior of labor, he enjoys studying, biking, and watching sci-fi films.
Ajit Tandale is a Huge Knowledge Options Architect at Amazon Internet Companies. He helps AWS strategic clients speed up their enterprise outcomes by offering experience in large knowledge utilizing AWS managed companies and open-source options. Exterior of labor, he enjoys studying, biking, and watching sci-fi films.
 Thippana Vamsi Kalyan is a Software program Growth Engineer at AWS. He’s keen about studying and constructing extremely scalable and dependable knowledge analytics companies and options on AWS. In his free time, he enjoys studying, being outdoor along with his spouse and child, strolling, and watching sports activities and flicks.
Thippana Vamsi Kalyan is a Software program Growth Engineer at AWS. He’s keen about studying and constructing extremely scalable and dependable knowledge analytics companies and options on AWS. In his free time, he enjoys studying, being outdoor along with his spouse and child, strolling, and watching sports activities and flicks.

{kind=link}