
As companies develop, information volumes scale from GBs to TBs (or extra), and latency calls for go from hours to minutes (or much less), making it more and more costlier to offer contemporary insights again to the enterprise. Traditionally, Python and Scala information engineers have turned to streaming to fulfill these calls for, effectively processing new information in real-time, however analytics engineers who wanted to scale SQL-based dbt pipelines did not have this selection.
Now not! This weblog seeks as an instance how we will use the brand new Streaming Tables and Materialized Views on Databricks to ship contemporary, real-time insights to companies with the simplicity of SQL and dbt.
Background
On the 2023 Knowledge + AI Summit, we launched Streaming Tables and Materialized Views into Databricks SQL. This superior functionality gave Databricks SQL customers quick access to highly effective new desk materializations first launched inside Delta Stay Tables, permitting them to incrementalize giant queries, stream straight from occasion information sources and extra.
Along with natively utilizing Streaming Tables and Materialized Views inside a Databricks setting, in addition they work for dbt customers on Databricks. dbt-databricks has turn out to be one of the crucial standard methods to construct information fashions on Databricks, leveraging all the highly effective capabilities of Databricks SQL, together with the Photon compute engine, immediately scaling Serverless SQL Warehouses and the Unity Catalog governance mannequin, with the ubiquity of dbt’s transformation framework.
What’s modified in dbt-databricks?
As of dbt v1.6+, dbt-databricks has developed in three key sides:
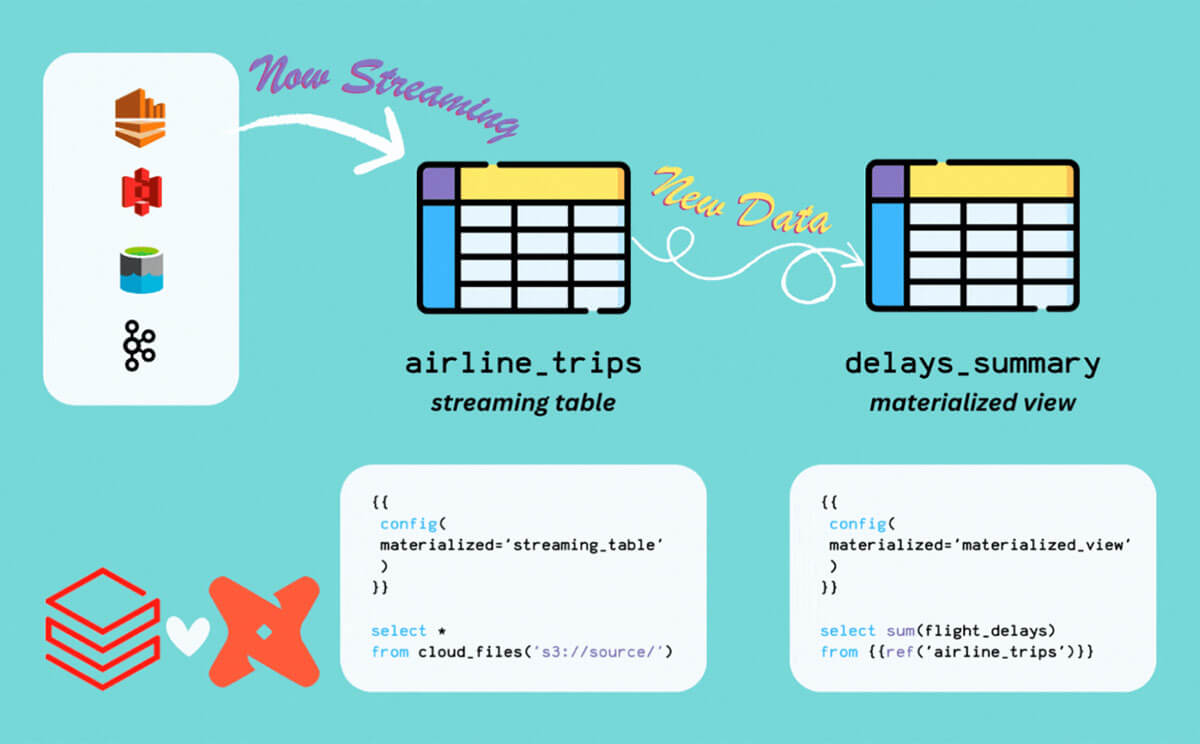
- New materializations: “streaming_table” and “materialized_view”
- New syntax to learn straight from cloud information storage with out staging your sources as a desk
- Entry to superior streaming ideas corresponding to window aggregations, watermarking and stream-stream joins
Notice: Preserve a watch out for the upcoming dbt v1.7.3 launch which is able to additional refine the above capabilities!
Let’s check out how we will use these new options with the Airline Journeys demo.
The Airline Journeys demo
The Airline Journeys demo was created to reveal the right way to incrementally ingest and remodel reside occasion information for up-to-date enterprise insights on Databricks, be it a dashboard or an AI mannequin. The dataset represents all airline journeys being taken in the US over time, capturing the delays to departures and arrivals for every journey.
An included helper pocket book establishes a simulated stream from this dataset whereas the dbt mission showcases a knowledge mannequin that takes these uncooked json occasions and transforms them through streaming ETL right into a layer of Materialized Views, characteristic tables and extra.
The repository is publicly obtainable right here, and leverages pattern information packaged in all Databricks workspaces out-of-the-box. Be happy to comply with alongside!

Ingesting information from cloud information storage
One of many easiest methods to start out leveraging Streaming Tables is for information ingestion from cloud information storage, like S3 for AWS or ADLS for Azure. You’ll have an upstream information supply producing occasion information at a excessive quantity, and a course of to land these as uncooked recordsdata right into a storage location, usually json, csv, parquet or avro.
In our demo, think about we obtain a reside feed of each airline journey taken in the US from an exterior social gathering, and we wish to ingest this incrementally because it comes.
As a substitute of staging the recordsdata as an exterior desk, or utilizing a third social gathering instrument to materialize a Delta Desk for the information supply, we will merely use Streaming Tables to resolve this. Take the mannequin under for our bronze airline journeys feed:
{{
config(
materialized='streaming_table'
)
}}
choose
*
,_metadata.file_modification_time as file_modification_time
from stream read_files('{{var("input_path")}}/airways', format=>'json')The 2 key factors to notice are:
- The materialization technique is about to ‘streaming_table’
- This can run a CREATE OR REFRESH STREAMING TABLE command in Databricks
- The syntax to learn from cloud storage leverages Auto Loader below the hood
- read_files() will record out new json recordsdata within the specified folder and begin processing them. Since we’re utilizing dbt, we have taken benefit of the var() operate in dbt to move an s3 folder path dynamically (of the shape “s3://…”)
- The STREAM key phrase signifies to stream from this location. Alternatively, with out it we will nonetheless use read_files() with materialized=’desk’ to do a batch learn straight from the desired folder
As an apart, whereas Auto Loader requires the least setup, you can too stream straight from an occasion streaming platform like Kafka, Kinesis or Occasion Hubs for even decrease latency utilizing very comparable syntax. See right here for extra particulars.
Incrementally enriching information for the silver layer
Streaming doesn’t must cease on the ingestion step. If we wish to carry out some joins downstream or add a surrogate key, however wish to limit it to new information solely to save lots of on compute, we will proceed to make use of the Streaming Desk materialization. For instance, take the snippet from our subsequent mannequin for the silver, enriched airways journeys feed, the place we be a part of mapping tables for airport codes into the uncooked information set:
{{
config(
materialized='streaming_table'
)
}}
...
SELECT
{{ dbt_utils.generate_surrogate_key([
'ArrTimestamp'
])
}} as delay_id
,...
FROM STREAM({{ref("airline_trips_bronze")}}) uncooked
INNER JOIN {{ref("airport_codes")}} ac
ON uncooked.Origin = ac.iata_code
...As soon as once more, we have made use of the Streaming Desk materialization, and have been in a position to leverage customary dbt performance for all of our logic. This consists of:
- Leveraging the dbt_utils package deal for useful shortcuts like producing a surrogate key
- Utilizing the ref() assertion to take care of full lineage
The one actual change to our SQL was the addition of the STREAM() key phrase across the ref() assertion for airline_trips_bronze, to point that this desk is being learn incrementally, whereas the airport_codes desk being joined is a mapping desk that’s learn in full. That is referred to as a stream-static be a part of.
Crafting a compute-efficient gold layer with Materialized Views
With our enriched silver tables prepared, we will now take into consideration how we wish to serve up aggregated insights to our finish enterprise shoppers. Sometimes if we use a desk materialization, we must recompute all historic outcomes each time.
To make the most of the Streaming Tables upstream that solely course of new information in every run, we flip as an alternative to Materialized Views for the duty!
The excellent news in Databricks is {that a} mannequin that builds a Materialized View appears to be like no completely different than a mannequin that builds a desk! Take our instance for a gold layer Materialized View to calculate the proportion of delayed flights every day:
{{
config(
materialized='materialized_view'
)
}}
SELECT
airline_name
,ArrDate
,COUNT(*) AS no_flights
,SUM(IF(IsArrDelayed = TRUE,1,0)) AS tot_delayed
,ROUND(tot_delayed*100/no_flights,2) AS perc_delayed
FROM {{ ref('airline_trips_silver') }}
WHERE airline_name IS NOT NULL
GROUP BY 1,2All we modified was the materialization config!
Keep in mind, Materialized Views could be incrementally refreshed when there are modifications to the bottom tables. Within the above state of affairs, as we stream new information, the Materialized View determines which teams require re-calculation and solely computes these, leaving unchanged aggregations as-is and decreasing total compute prices. That is simpler to visualise within the instance as we mixture over ArrDate, the arrival date of flights, that means new days of information will naturally fall into new teams and present teams will stay unchanged.
Analyzing the occasion logs of the Materialized View (pictured under) after a number of runs of the mannequin, we will see the incrementalization at work. The primary run is a full computation like several desk, however a second run to replace the aggregations with new information leverages a row-wise incremental refresh. A last run of the mannequin recognised that no new information had been ingested upstream and easily did nothing.

What else can I count on within the demo repository?
We have coated the fundamentals of getting information straight from the occasion supply all the best way to a BI-ready Materialized View, however the demo repository accommodates a lot extra.
Included within the repository are examples of the right way to monitor logs for Streaming Tables and Materialized Views to know how information is being processed, in addition to a complicated instance not coated on this weblog of the right way to be a part of two streams collectively in a stream-stream be a part of simply with SQL!
Clone within the repo to your Databricks setting to get began, or join up dbt Cloud to Databricks at no extra price with accomplice join. You can too be taught extra with the documentation for Materialized Views and Streaming Tables.

{kind=link}