
Introduction
Databricks Lakehouse Monitoring means that you can monitor all of your knowledge pipelines – from knowledge to options to ML fashions – with out extra instruments and complexity. Constructed into Unity Catalog, you possibly can monitor high quality alongside governance and get deep perception into the efficiency of your knowledge and AI belongings. Lakehouse Monitoring is absolutely serverless so that you by no means have to fret about infrastructure or tuning compute configuration.
Our single, unified strategy to monitoring makes it easy to trace high quality, diagnose errors, and discover options straight within the Databricks Intelligence Platform. Maintain studying to find the way you and your crew can get probably the most out of Lakehouse Monitoring.
Why Lakehouse Monitoring?
Right here’s a state of affairs: your knowledge pipeline seems to be working easily, solely to find that the standard of the information has silently degraded over time. It’s a standard drawback amongst knowledge engineers – every part appears wonderful till somebody complains that the information is unusable.
For these of you coaching ML fashions, monitoring manufacturing mannequin performances and evaluating completely different variations is an ongoing problem. Consequently, groups are confronted with fashions going stale in manufacturing and tasked with rolling them again.
The phantasm of practical pipelines that masks crumbling knowledge high quality makes it difficult for knowledge and AI groups to fulfill supply and high quality SLAs. Lakehouse Monitoring may also help you proactively uncover high quality points earlier than downstream processes are impacted. You possibly can keep forward of potential points, making certain that pipelines run easily, and machine studying fashions stay efficient over time. No extra weeks spent on debugging and rolling again adjustments!
The way it works

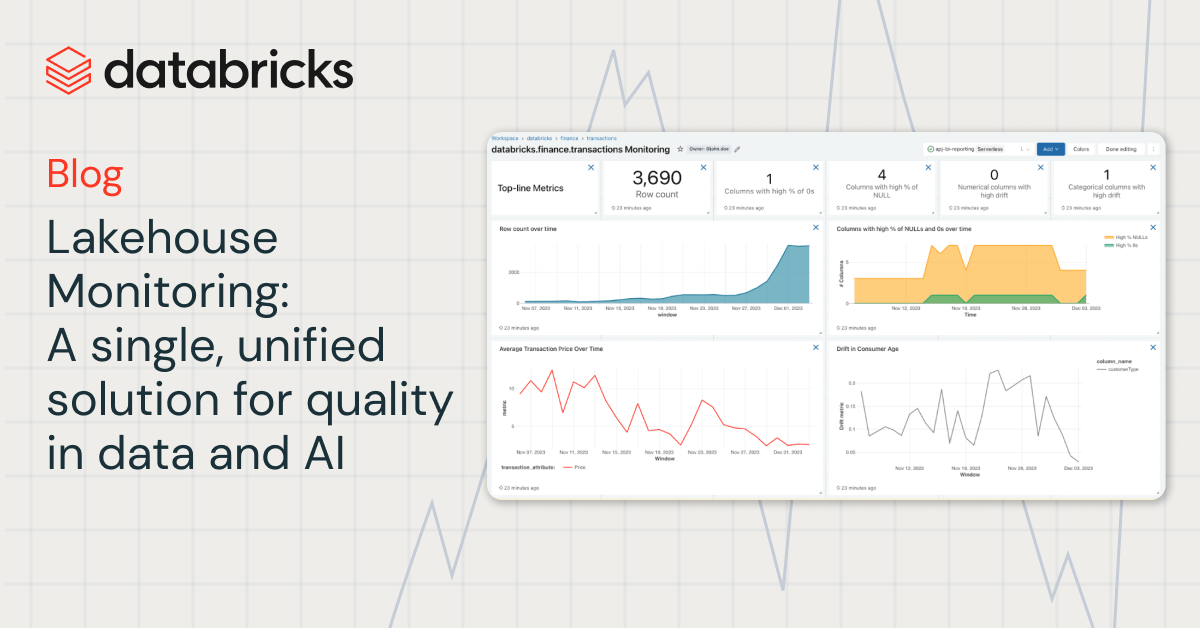
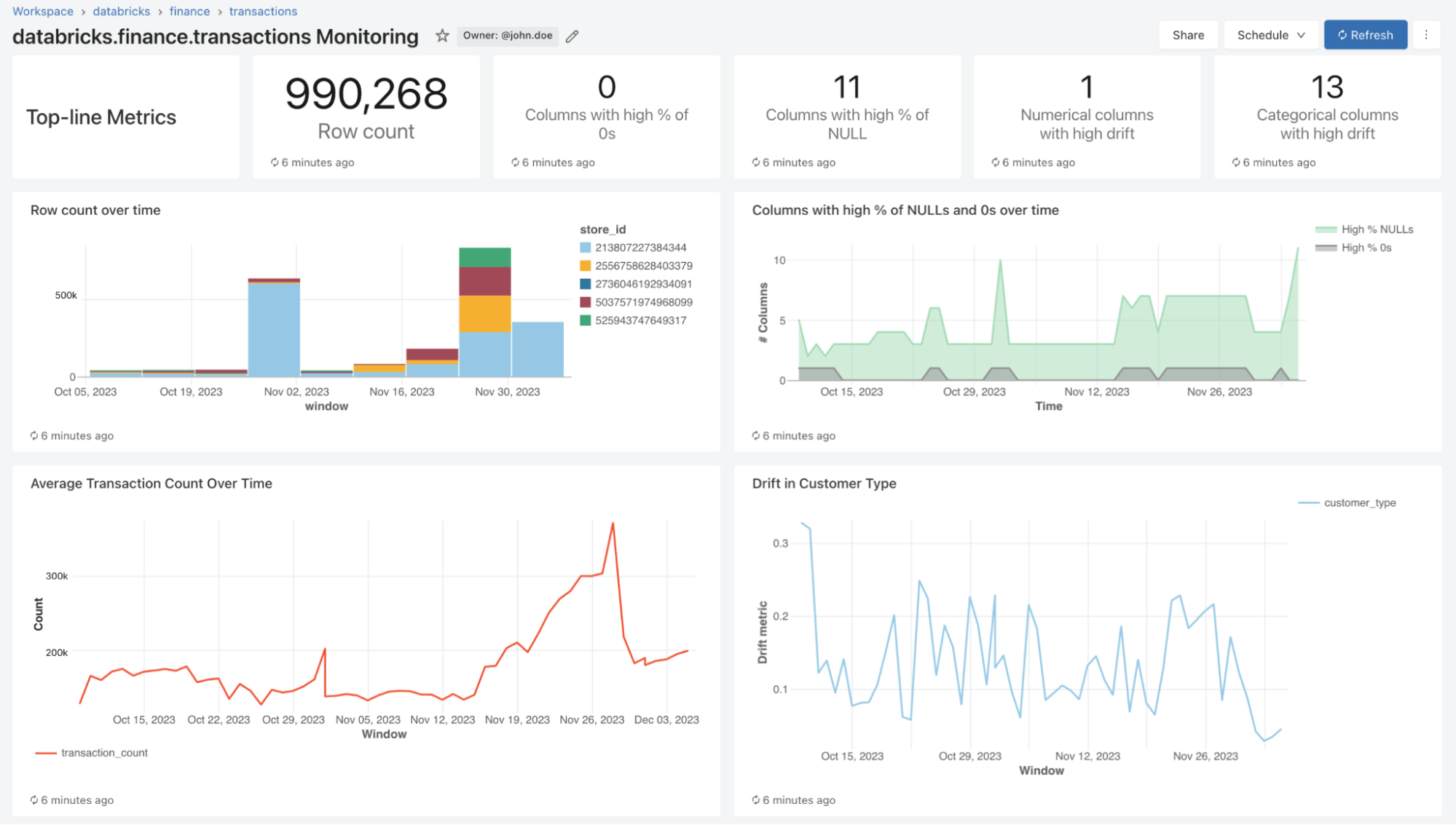
With Lakehouse Monitoring, you possibly can monitor the statistical properties and high quality of all of your tables in simply one-click. We robotically generate a dashboard that visualizes knowledge high quality for any Delta desk in Unity Catalog. Our product computes a wealthy set of metrics out of the field. For example, for those who’re monitoring an inference desk, we offer mannequin efficiency metrics, as an illustration, R-squared, accuracy, and so forth.. Alternatively, for these monitoring knowledge engineering tables, we offer distributional metrics together with imply, min/max, and so forth.. Along with the built-in metrics, you can even configure customized (business-specific) metrics that you really want us to calculate. Lakehouse Monitoring refreshes metrics and retains the dashboard up-to-date in line with your specified schedule. All metrics are saved in Delta tables to allow ad-hoc analyses, customized visualizations, and alerts.
Configuring Monitoring
You possibly can arrange monitoring on any desk you personal utilizing the Databricks UI (AWS | Azure) or API (AWS | Azure). Choose the kind of monitoring profile you need in your knowledge pipelines or fashions:
- Snapshot Profile: If you wish to monitor the total desk over time or evaluate present knowledge to earlier variations or a identified baseline, a Snapshot Profile will work finest. We’ll then calculate metrics over all the information within the desk and replace metrics each time the monitor is refreshed.
- Time Sequence Profile: In case your desk incorporates occasion timestamps and also you wish to evaluate knowledge distributions over home windows of time (hourly, every day, weekly, …), then a Time Sequence profile will work finest. We suggest that you simply activate Change Knowledge Feed (AWS | Azure) so you will get incremental processing each time the monitor is refreshed. Be aware: you’ll need a timestamp column with a view to configure this profile.
- Inference Log Profile: If you wish to evaluate mannequin efficiency over time or monitor how mannequin inputs and predictions are shifting over time, an inference profile will work finest. You will have an inference desk (AWS | Azure) which incorporates inputs and outputs from a ML classification or regression mannequin. You too can optionally embody floor fact labels to calculate drift and different metadata akin to demographic data to get equity and bias metrics.
You possibly can select how typically you need our monitoring service to run. Many purchasers select a every day or hourly schedule to make sure the freshness and relevance of their knowledge. If you would like monitoring to robotically run on the finish of knowledge pipeline execution, you can even name the API to refresh monitoring straight in your Workflow.
To additional customise monitoring, you possibly can set slicing expressions to watch characteristic subsets of the desk along with the desk as a complete. You possibly can slice any particular column, e.g. ethnicity, gender, to generate equity and bias metrics. You too can outline customized metrics based mostly on columns in your major desk or on prime of out-of-the-box metrics. See how one can use customized metrics (AWS | Azure) for extra particulars.
Visualize High quality
As a part of a refresh, we’ll scan your tables and fashions to generate metrics that monitor high quality over time. We calculate two varieties of metrics that we retailer in Delta tables for you:
- Profile Metrics: They supply abstract statistics of your knowledge. For instance, you possibly can monitor the variety of nulls and zeros in your desk or accuracy metrics to your mannequin. See the profile metrics desk schema (AWS | Azure) for extra data.
- Drift Metrics: They supply statistical drift metrics that assist you to evaluate towards your baseline tables. See the drift metrics desk schema (AWS | Azure) for extra data.
To visualise all these metrics, Lakehouse Monitoring supplies an out-of-the-box dashboard that’s absolutely customizable. You too can create Databricks SQL alerts (AWS | Azure) to get notified on threshold violations, adjustments to knowledge distribution, and drift out of your baseline desk.
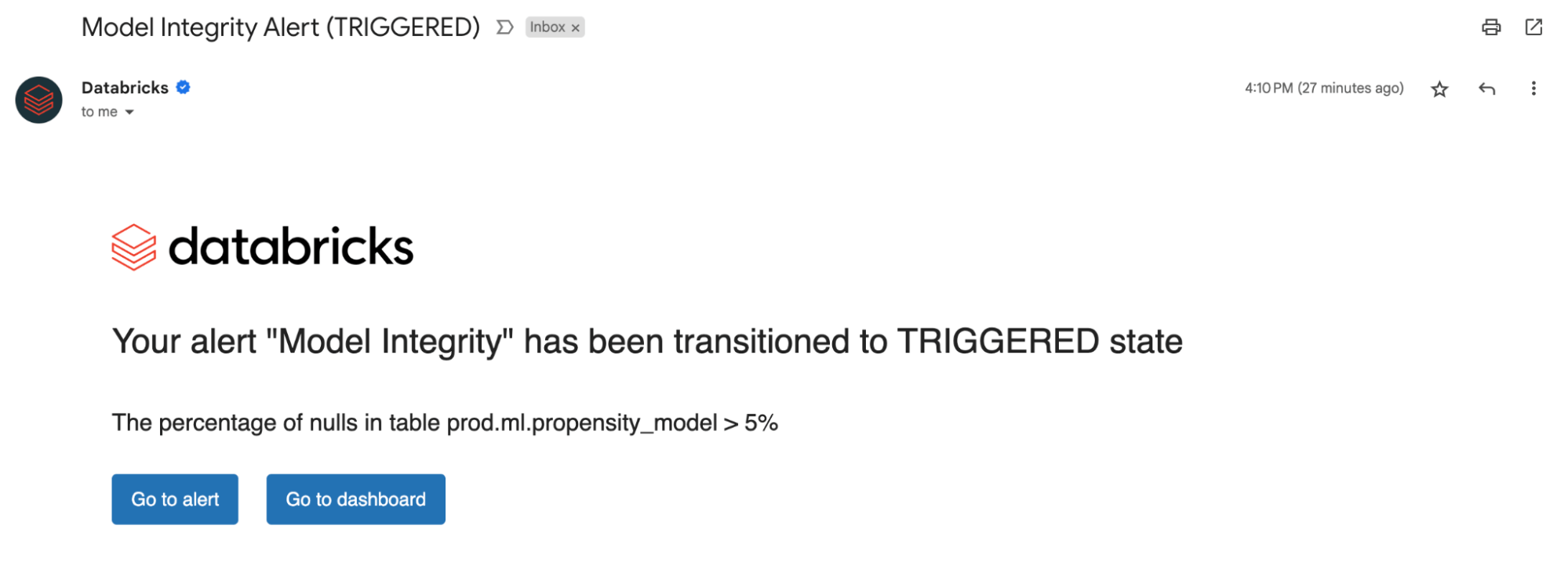
Establishing Alerts
Whether or not you are monitoring knowledge tables or fashions, organising alerts on our computed metrics notifies you of potential errors and helps forestall downstream dangers.
You may get alerted if the % of nulls and zeros exceed a sure threshold or endure adjustments over time. If you’re monitoring fashions, you will get alerted if mannequin efficiency metrics like toxicity or drift fall beneath sure high quality thresholds.
Now, with insights derived from our alerts, you possibly can establish whether or not a mannequin wants retraining or if there are potential points together with your supply knowledge. After you’ve addressed points, you possibly can manually name the refresh API to get the most recent metrics to your up to date pipeline. Lakehouse Monitoring helps you proactively take actions to keep up the general well being and reliability of your knowledge and fashions.
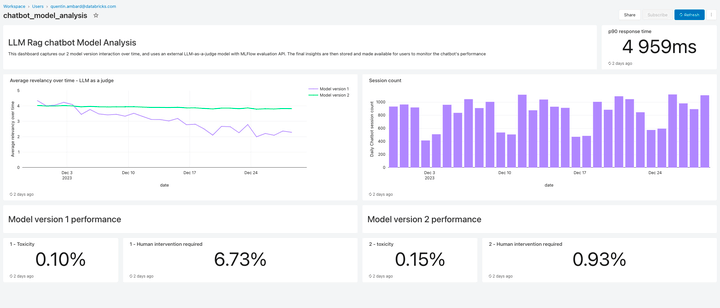
Monitor LLM High quality
Lakehouse Monitoring presents a totally managed high quality resolution for Retrieval Augmented Technology (RAG) functions. It scans your utility outputs for poisonous or in any other case unsafe content material. You possibly can shortly diagnose errors associated to e.g. stale knowledge pipelines or sudden mannequin conduct. Lakehouse Monitoring absolutely manages monitoring pipelines, liberating builders to deal with their functions.
What’s coming subsequent?
We’re excited for the way forward for Lakehouse Monitoring and looking out ahead to help:
- Knowledge classification/ PII Detection – Join our Personal Preview right here!
- Expectations to robotically implement knowledge high quality guidelines and orchestrate your pipelines
- A holistic view of your screens to summarize the standard and well being throughout your tables
To be taught extra about Lakehouse monitoring and get began in the present day, go to our product documentation (AWS | Azure). Moreover, make amends for the current bulletins about creating top quality RAG functions, and be a part of us for our GenAI webinar.

{kind=link}