
The consequences of local weather change and inequality are threatening societies internationally, however there’s nonetheless an annual funding hole of US$2.5 trillion to attain the UN Sustainable Growth Objectives by 2030. A considerable quantity of that cash is anticipated to return from non-public sources like pension funds, however institutional buyers usually battle to effectively incorporate sustainability into their funding choices.
Matter is a Danish fintech on a mission to make capital work for folks and the planet. The corporate helps buyers perceive how firms and governments align with sustainable practices, throughout local weather, environmental, social and governance-related themes. Matter has partnered with main monetary corporations, akin to Nasdaq and Nordea, on offering sustainability knowledge to buyers.

Matter collects knowledge from a whole bunch of unbiased sources with the intention to join buyers to insights from specialists in NGOs and academia, in addition to to indicators from trusted media. We make the most of state-of-the-art machine studying algorithms to investigate advanced knowledge and extract priceless key factors related to the analysis of the sustainability of investments. Matter units itself aside by counting on a wisdom-of-the-crowd strategy, and by permitting our shoppers to entry all insights by way of a custom-made reporting system, APIs or built-in internet parts that empower skilled managers, in addition to retail buyers, to take a position extra sustainably.
NoSQL Knowledge Makes Analytics Difficult
Matter’s providers vary from end-user-facing dashboards and portfolio summarization to stylish knowledge pipelines and APIs that observe sustainability metrics on investable corporations and organizations everywhere in the world.
In a number of of those situations, each NoSQL databases and knowledge lakes have been very helpful due to their schemaless nature, variable value profiles and scalability traits. Nevertheless, such options additionally make arbitrary analytical queries exhausting to construct for and, as soon as carried out, sometimes fairly sluggish, negating a few of their authentic upsides. Whereas we examined and carried out completely different rematerialization methods for various components of our pipelines, such options sometimes take a considerable quantity of effort and time to construct and keep.
Decoupling Queries from Schema and Index Design
We use Rockset in a number of components of our knowledge pipeline due to how simple it’s to arrange and work together with; it supplies us with a easy “freebie” on prime of our current knowledge shops that enables us to question them with out frontloading choices on indexes and schema designs, which is a extremely fascinating resolution for a small firm with an increasing product and idea portfolio.
Our preliminary use case for Rockset, nevertheless, was not only a good addition to an current pipeline, however as an integral a part of our NLP (Pure Language Processing)/AI product structure that permits brief growth cycles in addition to a reliable service.
Implementing Our NLP Structure with Rockset
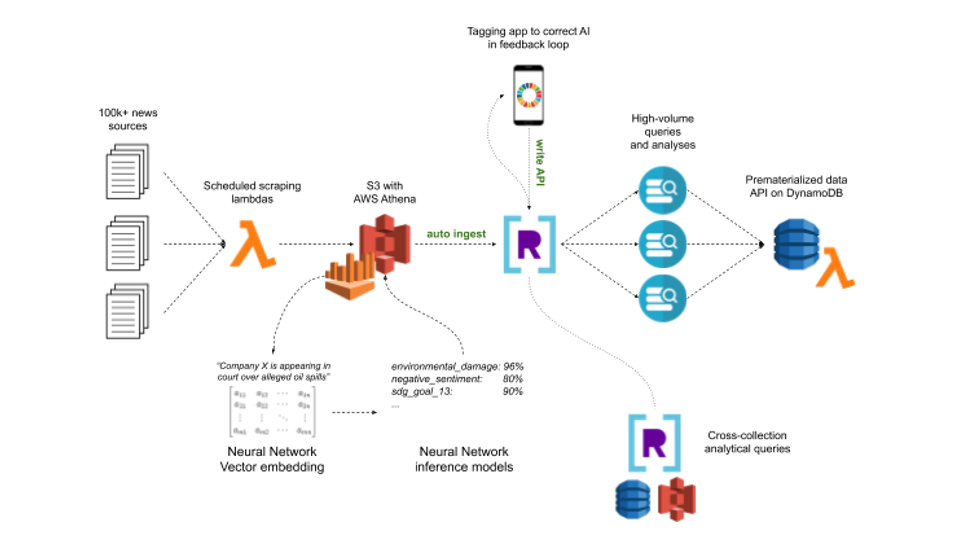
Massive components of what make up accountable investments aren’t doable to attain utilizing conventional numerical evaluation, as there are numerous qualitative intricacies in company accountability and sustainability. To measure and gauge a few of these particulars, Matter has constructed an NLP pipeline that actively ingests and analyzes information feeds to report on sustainability- and responsibility-oriented information for about 20,000+ corporations. Bringing in knowledge from our distributors, we repeatedly course of tens of millions of stories articles from 1000’s of sources with sentence splitting, named entity recognition, sentiment scoring and subject extraction utilizing a mixture of proprietary and open-source neural networks. This shortly yields many million rows of knowledge with a number of metrics which can be helpful on each a person and combination stage.
To retain as a lot knowledge as doable and make sure the transparency wanted in our line of enterprise, we retailer all our knowledge after every step in our terabyte-scale, S3-backed knowledge lake. Whereas Amazon Athena supplies immense worth for a number of components of our circulation, it falls wanting helpful analytical queries on the velocity, scale and complexity with which we want them. To resolve this challenge, we merely join Rockset to our S3 lake and auto-ingest that knowledge, letting us use rather more performant and cost-effective ad-hoc queries than these provided by Athena.
With our NLP-processed information knowledge at hand, we will dive in to uncover many fascinating insights:
- How are information sources reporting on a given firm’s carbon emissions, labor remedy, lobbying conduct, and so on.?
- How has this advanced over time?
- Are there any ongoing scandals?
Precisely which pulls are fascinating are uncovered in tight collaboration with our early companions, that means that we want the querying flexibility supplied by SQL options, whereas additionally benefiting from an simply expandable knowledge mannequin.
Consumer requests sometimes encompass queries for a number of thousand asset positions of their portfolios, together with advanced analyses akin to development forecasting and lower- and upper-bound estimates for sentence metric predictions. We ship this excessive quantity of queries to Rockset and use the question outcomes to pre-materialize all of the completely different pulls in a DynamoDB database with easy indices. This structure yields a quick, scalable, versatile and simply maintainable end-user expertise. We’re able to delivering ~10,000 years of every day sentiment knowledge each second with sub-second latencies.
We’re completely happy to have Rockset as a part of our stack due to how simple it now’s for us to increase our knowledge mannequin, auto-ingest many knowledge sources and introduce fully new question logic with out having to rethink main components of our structure.
Flexibility to Add New Knowledge and Analyses with Minimal Effort
We initially checked out implementing a delta structure for our NLP pipeline, that means that we’d calculate adjustments to related knowledge views given a brand new row of knowledge and replace the state of those views. This may yield very excessive efficiency at a comparatively low infrastructure and repair value. Such an answer would, nevertheless, restrict us to queries which can be doable to formulate in such a approach up entrance, and would incur important construct value and time for each delta operation we’d be curious about. This may have been a untimely optimization that was overly slender in scope.

An alternate delta structure that requires queries to be formulated up entrance
Due to this, we actually noticed the necessity for an addition to our pipeline that will permit us to shortly take a look at and add advanced queries to assist ever-evolving knowledge and perception necessities. Whereas we may have carried out an ETL set off on prime of our S3 knowledge lake ourselves to feed into our personal managed database, we’d have needed to deal with suboptimal indexing, denormalization and errors in ingestion, and resolve them ourselves. We estimate that it could have taken us 3 months to get to a rudimentary implementation, whereas we have been up and operating utilizing Rockset in our stack inside a few days.
The schemaless, easy-to-manage, pay-as-you-go nature of Rockset makes it a no brainer to us. We will introduce new AI fashions and knowledge fields with out having to rebuild the encircling infrastructure. We will merely increase the prevailing mannequin and question our knowledge whichever approach we like with minimal engineering, infrastructure and upkeep.
As a result of Rockset permits us to ingest from many alternative sources in our cloud, we additionally discover question synergies between completely different collections in Rockset. “Present me the typical environmental sentiment for corporations within the oil extraction business with income above $100 billion” is one kind of question that will have been exhausting to carry out previous to the introduction of Rockset, as a result of the info factors within the question originate from separate knowledge pipelines.
One other synergy comes from the power to jot down to Rockset collections by way of the Rockset Write API. This enables us to right dangerous predictions made by the AI by way of our customized tagging app, tapping into the newest knowledge ingested in our pipeline. In another structure, we must arrange one other synchronization job between our tagging utility and NLP database which might, once more, incur construct value and time.

Utilizing Rockset within the structure leads to larger flexibility and shorter construct time
Excessive-Efficiency Analytics on NoSQL Knowledge When Time to Market Issues
In case you are something like Matter and have knowledge shops that will be helpful to question, however you might be struggling to make NoSQL and/or Presto-based options akin to Amazon Athena totally assist the queries you want, I like to recommend Rockset as a extremely priceless service. Whilst you can construct or purchase options to the issues I’ve outlined on this submit individually that may present extra ingest choices, higher absolute efficiency, decrease marginal prices or increased scalability potential, I’ve but to seek out something that comes remotely near Rockset on all of those areas on the identical time, in a setting the place time to market is a extremely priceless metric.
Authors:
Alexander Harrington is CTO at Matter, coming from a business-engineering background with a selected emphasis on using rising applied sciences in current areas of enterprise.
Dines Selvig is Lead on the AI growth at Matter, constructing an end-to-end AI system to assist buyers perceive the sustainability profile of the businesses they spend money on.

{kind=link}