
In line with over 40,000 builders, MongoDB is the hottest NOSQL database in use proper now. The instrument’s meteoric rise is probably going resulting from its JSON construction which makes it simple for Javascript builders to make use of. From a developer perspective, MongoDB is a superb answer for supporting trendy knowledge purposes. However, builders generally want to drag particular workflows out of MongoDB and combine them right into a secondary system whereas persevering with to trace any modifications to the underlying MongoDB knowledge.
Monitoring knowledge modifications, additionally known as “change knowledge seize” (CDC), may also help present helpful insights into enterprise workflows and assist different real-time purposes. There are a selection of strategies your crew can make use of to assist observe knowledge modifications. This weblog publish will take a look at three of them: tailing MongoDB with an oplog, utilizing MongoDB change streams, and utilizing a Kafka connector.
Tailing the MongoDB Oplog

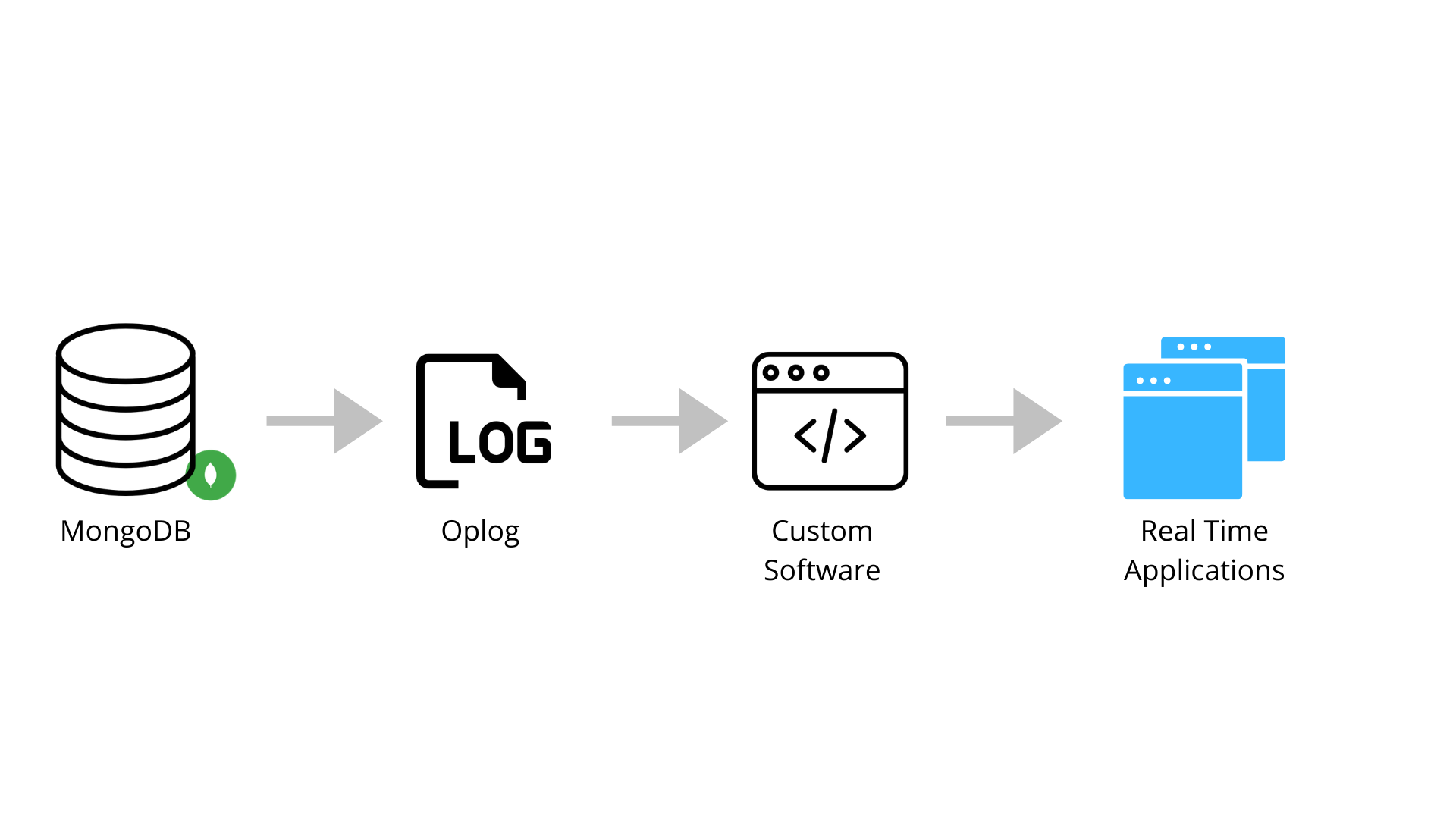
Determine 1: Tailing MongoDB’s oplog to an software
An oplog is a log that tracks all the operations occurring in a database. In case you’ve replicated MongoDB throughout a number of areas, you’ll want a dad or mum oplog to maintain all of them in sync. Tail this oplog with a tailable cursor that may comply with the oplog to the latest change. A tailable cursor can be utilized like a publish-subscribe paradigm. Which means that, as new modifications are available in, the cursor will publish them to some exterior subscriber that may be related to another dwell database occasion.
You possibly can arrange a tailable cursor utilizing a library like PyMongo in Python and code related to what’s offered within the instance under. What you’ll discover is there’s a clause that states whereas cursor.alive:. This whereas assertion permits your code to maintain checking to see in case your cursor remains to be alive and doc references the completely different paperwork that captured the change within the oplog.
import time
import pymongo
import redis
redis_uri=”redis://:hostname.redislabs.com@mypassword:12345/0”
r = redis.StrictRedis(url=redis_uri)
consumer = pymongo.MongoClient()
oplog = consumer.native.oplog.rs
first = oplog.discover().type('$pure', pymongo.DESCENDING).restrict(-1).subsequent()
row_ts = first['ts']
whereas True:
cursor = oplog.discover({'ts': {'$gt': ts}}, tailable=True, await_data=True)
cursor.add_option(8)
whereas cursor.alive:
for doc in cursor:
row_ts = doc['ts']
r.set(doc['h'], doc)
time.sleep(1)
MongoDB shops its knowledge, together with the information in MongoDB’s oplog, in what it references as paperwork.
Within the code above, the paperwork are referenced within the for loop for doc in cursor:. This loop will can help you entry the person modifications on a doc by doc foundation.
The ts is the important thing that represents a brand new row. You possibly can see the ts key instance doc under, in JSON format:
{ "ts" : Timestamp(1422998574, 1), "h" : NumberLong("-6781014703318499311"), "v" : 2, "op" : "i", "ns" : "take a look at.mycollection", "o" : { "_id" : 1, "knowledge" : "hi there" } }
Tailing the oplog does pose a number of challenges which floor after you have a scaled software requiring secondary and first situations of MongoDB. On this case, the first occasion acts because the dad or mum database that all the different databases use as a supply of fact.
Issues come up in case your main database wasn’t correctly replicated and a community outage happens. If a brand new main database is elected and that main database hasn’t correctly replicated, your tailing cursor will begin in a brand new location, and the secondaries will roll again any unsynced operations. Which means that your database will drop these operations. It’s attainable to seize knowledge modifications when the first database fails; nonetheless, to take action, your crew must develop a system to handle failovers.
Utilizing MongoDB Change Streams
Tailing the oplog is each code-heavy and extremely dependent upon the MongoDB infrastructure’s stability. As a result of tailing the oplog creates plenty of danger and might result in your knowledge turning into disjointed, utilizing MongoDB change streams is usually a greater possibility for syncing your knowledge.

Determine 2: Utilizing MongoDB change streams to load knowledge into an software
The change streams instrument was developed to supply easy-to-track dwell streams of MongoDB modifications, together with updates, inserts, and deletes. This instrument is far more sturdy throughout community outages, when it makes use of resume tokens that assist hold observe of the place your change stream was final pulled from. Change streams don’t require the usage of a pub-sub (publish-subscribe) mannequin like Kafka and RabbitMQ do. MongoDB change streams will observe your knowledge modifications for you and push them to your goal database or software.
You possibly can nonetheless use the PyMongo library to interface with MongoDB. On this case, you’ll create a change_stream that acts like a client in Kafka and serves because the entity that watches for modifications in MongoDB. This course of is proven under:
import os
import pymongo
from bson.json_util import dumps
consumer = pymongo.MongoClient(os.environ['CHANGE_STREAM_DB'])
change_stream = consumer.changestream.assortment.watch()
for change in change_stream:
print(dumps(change))
print('') # for readability solely
Utilizing change streams is an effective way to keep away from the problems encountered when tailing the oplog. Moreover, change streams is a superb selection for capturing knowledge modifications, since that’s what it was developed to do.
That stated, basing your real-time software on MongoDB change streams has one large downside: You’ll must design and develop knowledge units which can be doubtless listed with the intention to assist your exterior purposes. In consequence, your crew might want to tackle extra advanced technical work that may decelerate growth. Relying on how heavy your software is, this problem would possibly create an issue. Regardless of this downside, utilizing change streams does pose much less danger general than tailing the oplog does.
Utilizing Kafka Connector
As a 3rd possibility, you need to use Kafka to connect with your dad or mum MongoDB occasion and observe modifications as they arrive. Kafka is an open-source knowledge streaming answer that enables builders to create real-time knowledge feeds. MongoDB has a Kafka connector that may sync knowledge in each instructions. It may possibly each present MongoDB with updates from different programs and publish modifications to exterior programs.

Determine 3: Streaming knowledge with Kafka from MongoDB to an software
For this feature, you’ll must replace the configuration of each your Kafka occasion and your MongoDB occasion to arrange the CDC. The Kafka connector will publish the doc modifications to Kafka’s REST API interface. Technically, the information is captured with MongoDB change streams within the MongoDB cluster itself after which revealed to the Kafka subjects. This course of is completely different from utilizing Debezium’s MongoDB connector, which makes use of MongoDB’s replication mechanism. The necessity to use MongoDB’s replication mechanism could make the Kafka connector a better choice to combine.
You possibly can set the Kafka connector to trace on the assortment stage, the database stage, and even the deployment stage. From there, your crew can use the dwell knowledge feed as wanted.
Utilizing a Kafka connector is a superb possibility if your organization is already utilizing Kafka for different use circumstances. With that in thoughts, utilizing a Kafka connector is arguably one of many extra technically advanced strategies for capturing knowledge modifications. You will need to handle and keep a Kafka occasion that’s operating exterior to all the things else, in addition to another system and database that sits on high of Kafka and pulls from it. This requires technical assist and introduces a brand new level of failure. Not like MongoDB change streams, which have been created to straight assist MongoDB, this technique is extra like a patch on the system, making it a riskier and extra advanced possibility.
Managing CDC with Rockset and MongoDB Change Streams
MongoDB change streams presents builders another choice for capturing knowledge modifications. Nevertheless, this feature nonetheless requires your purposes to straight learn the change streams, and the instrument doesn’t index your knowledge. That is the place Rockset is available in. Rockset offers real-time indexing that may assist velocity up purposes that depend on MongoDB knowledge.

Determine 4: Utilizing change streams and Rockset to index your knowledge
By pushing knowledge to Rockset, you offload your purposes’ reads whereas benefiting from Rocket’s search, columnar, and row-based indexes, making your purposes’ reads sooner. Rockset layers these advantages on high of MongoDB’s change streams, rising the velocity and ease of entry to MongoDB’s knowledge modifications.
Abstract
MongoDB is a highly regarded possibility for software databases. Its JSON-based construction makes it simple for frontend builders to make use of. Nevertheless, it’s usually helpful to dump read-heavy analytics to a different system for efficiency causes or to mix knowledge units. This weblog offered three of those strategies: tailing the oplog, utilizing MongoDB change streams, and utilizing the Kafka connector. Every of those methods has its advantages and disadvantages.
In case you’re attempting to construct sooner real-time purposes, Rockset is an exterior indexing answer you need to think about. Along with having a built-in connector to seize knowledge modifications from MongoDB, it offers real-time indexing and is straightforward to question. Rockset ensures that your purposes have up-to-date data, and it permits you to run advanced queries throughout a number of knowledge programs—not simply MongoDB.
Different MongoDB sources:
Ben has spent his profession centered on all types of knowledge. He has centered on growing algorithms to detect fraud, cut back affected person readmission and redesign insurance coverage supplier coverage to assist cut back the general price of healthcare. He has additionally helped develop analytics for advertising and IT operations with the intention to optimize restricted sources similar to workers and funds. Ben privately consults on knowledge science and engineering issues. He has expertise each working hands-on with technical issues in addition to serving to management groups develop methods to maximise their knowledge.

{kind=link}