

In AWS, a whole bunch of hundreds of consumers use AWS Glue, a serverless information integration service, to find, mix, and put together information for analytics and machine studying. When you have got advanced datasets and demanding Apache Spark workloads, chances are you’ll expertise efficiency bottlenecks or errors throughout Spark job runs. Troubleshooting these points may be tough and delay getting jobs working in manufacturing. Clients usually use Apache Spark Internet UI, a well-liked debugging device that’s a part of open supply Apache Spark, to assist repair issues and optimize job efficiency. AWS Glue helps Spark UI in two alternative ways, however you’ll want to set it up your self. This requires effort and time spent managing networking and EC2 situations, or by trial-and error with Docker containers.
At the moment, we’re happy to announce serverless Spark UI constructed into the AWS Glue console. Now you can use Spark UI simply because it’s a built-in element of the AWS Glue console, enabling you to entry it with a single click on when analyzing the main points of any given job run. There’s no infrastructure setup or teardown required. AWS Glue serverless Spark UI is a fully-managed serverless providing and customarily begins up in a matter of seconds. Serverless Spark UI makes it considerably quicker and simpler to get jobs working in manufacturing as a result of you have got prepared entry to low stage particulars on your job runs.
This put up describes how the AWS Glue serverless Spark UI lets you monitor and troubleshoot your AWS Glue job runs.
Getting began with serverless Spark UI
You may entry the serverless Spark UI for a given AWS Glue job run by navigating out of your Job’s web page in AWS Glue console.
- On the AWS Glue console, select ETL jobs.
- Select your job.
- Select the Runs tab.
- Choose the job run you wish to examine, then select Spark UI.
The Spark UI will show within the decrease pane, as proven within the following display seize:
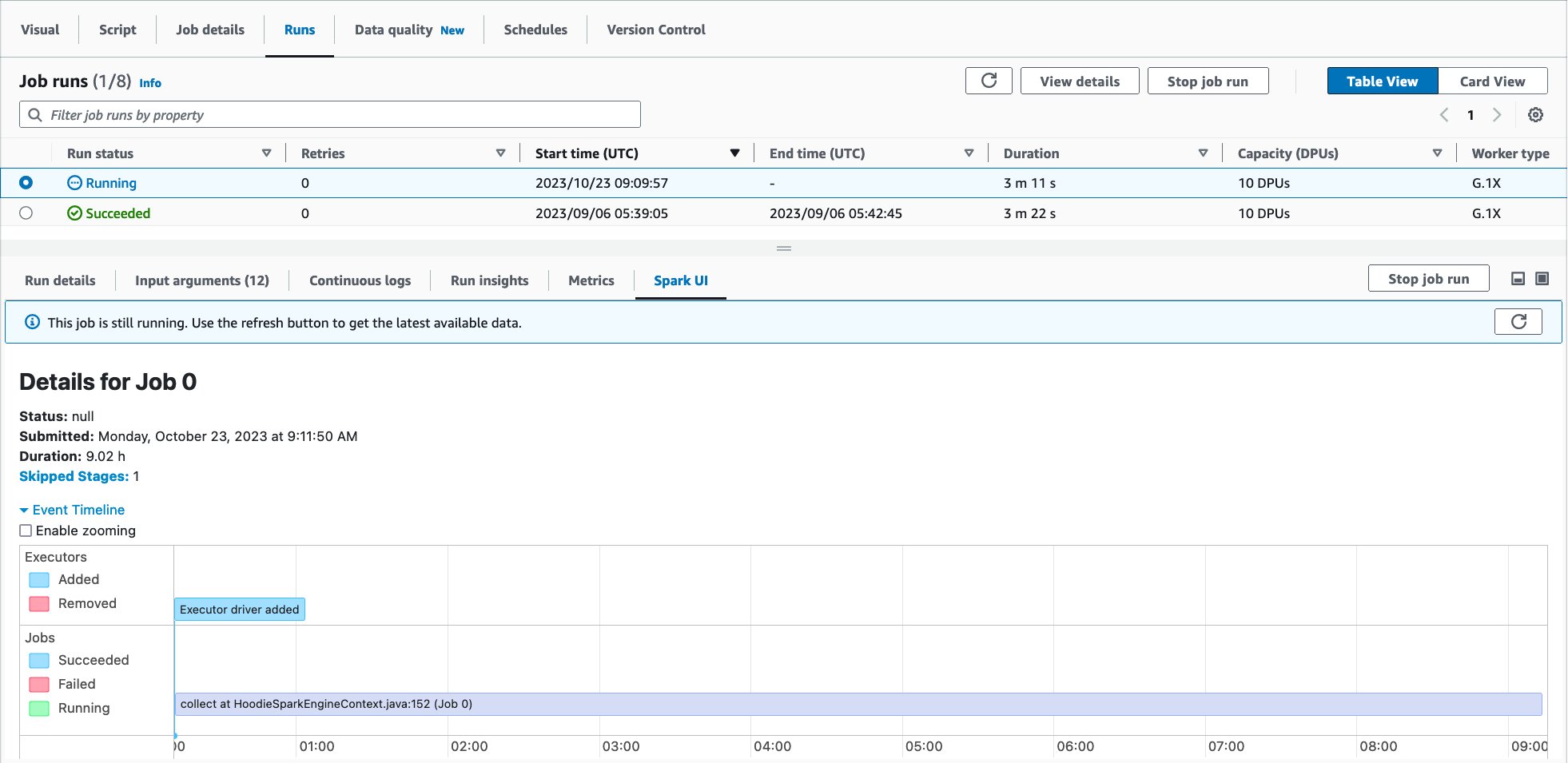
Alternatively, you will get to the serverless Spark UI for a selected job run by navigating from Job run monitoring in AWS Glue.
- On the AWS Glue console, select job run monitoring underneath ETL jobs.
- Choose your job run, and select View run particulars.
Scroll all the way down to the underside to view the Spark UI for the job run.
Conditions
Full the next prerequisite steps:
- Allow Spark UI occasion logs on your job runs. It’s enabled by default on Glue console and as soon as enabled, Spark occasion log recordsdata can be created in the course of the job run, and saved in your S3 bucket. The serverless Spark UI parses a Spark occasion log file generated in your S3 bucket to visualise detailed info for each working and accomplished job runs. A progress bar reveals the proportion to completion, with a typical parsing time of lower than a minute. As soon as logs are parsed, you’ll be able to
- When logs are parsed, you need to use the built-in Spark UI to debug, troubleshoot, and optimize your jobs.
For extra details about Apache Spark UI, discuss with Internet UI in Apache Spark.
Monitor and Troubleshoot with Serverless Spark UI
A typical workload for AWS Glue for Apache Spark jobs is loading information from relational databases to S3-based information lakes. This part demonstrates methods to monitor and troubleshoot an instance job run for the above workload with serverless Spark UI. The pattern job reads information from MySQL database and writes to S3 in Parquet format. The supply desk has roughly 70 million data.
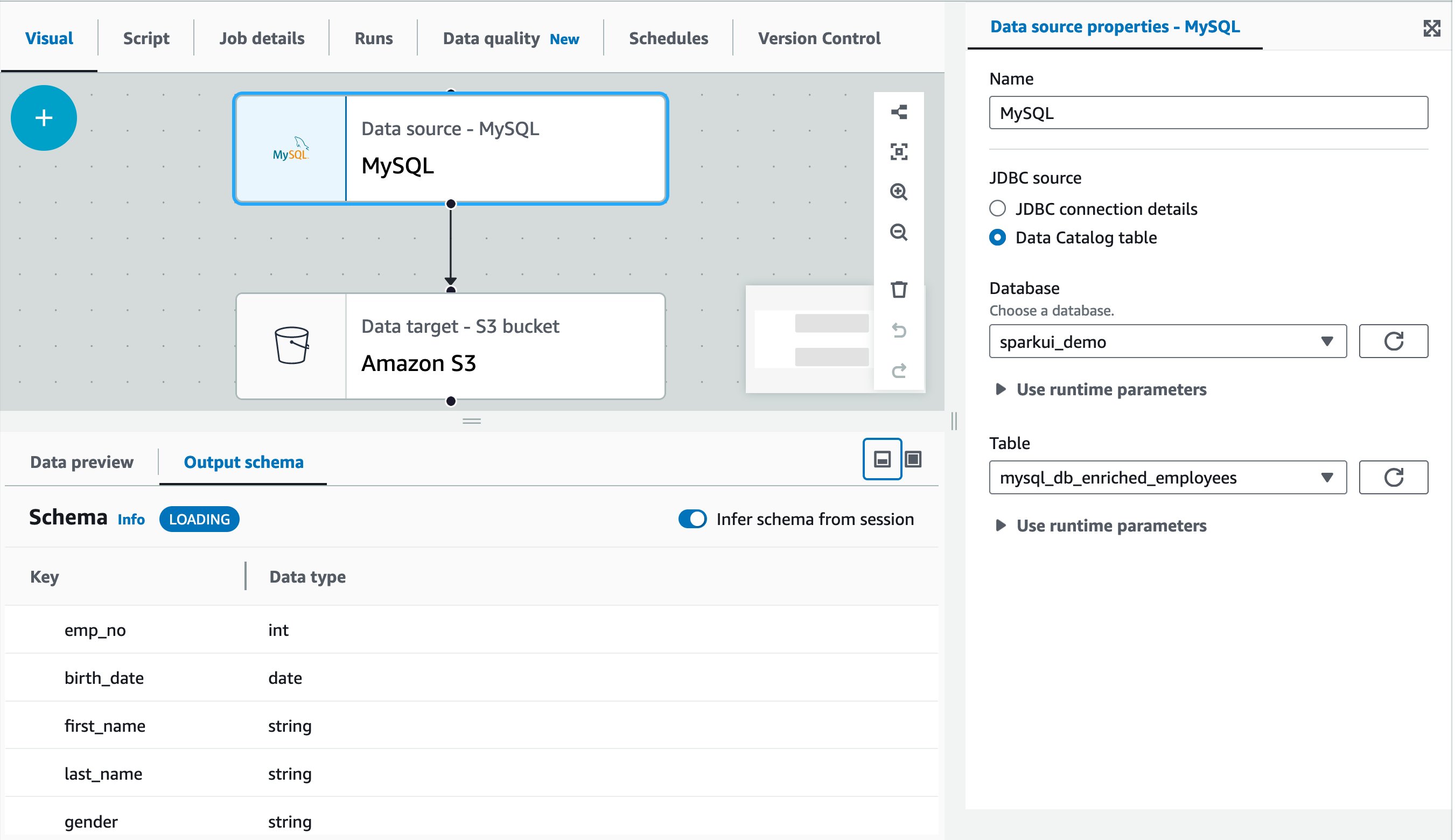
The next display seize reveals a pattern visible job authored in AWS Glue Studio visible editor. On this instance, the supply MySQL desk has already been registered within the AWS Glue Information Catalog upfront. It may be registered by AWS Glue crawler or AWS Glue catalog API. For extra info, discuss with Information Catalog and crawlers in AWS Glue.
Now it’s time to run the job! The primary job run completed in half-hour and 10 seconds as proven:
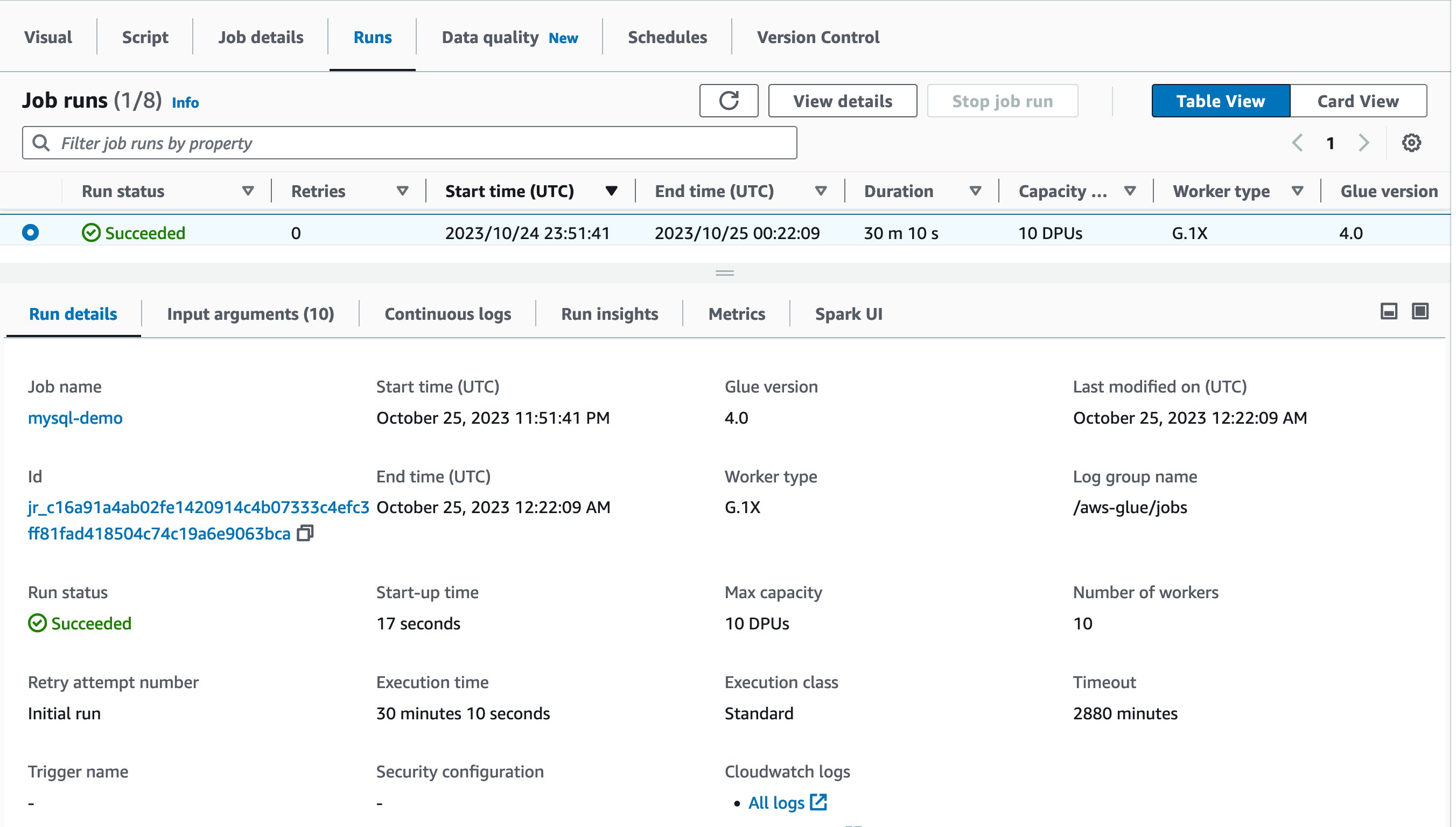
Let’s use Spark UI to optimize the efficiency of this job run. Open Spark UI tab within the Job runs web page. Whenever you drill all the way down to Phases and consider the Period column, you’ll discover that Stage Id=0 spent 27.41 minutes to run the job, and the stage had just one Spark process within the Duties:Succeeded/Whole column. Which means there was no parallelism to load information from the supply MySQL database.

To optimize the information load, introduce parameters referred to as hashfield and hashpartitions to the supply desk definition. For extra info, discuss with Studying from JDBC tables in parallel. Persevering with to the Glue Catalog desk, add two properties: hashfield=emp_no, and hashpartitions=18 in Desk properties.
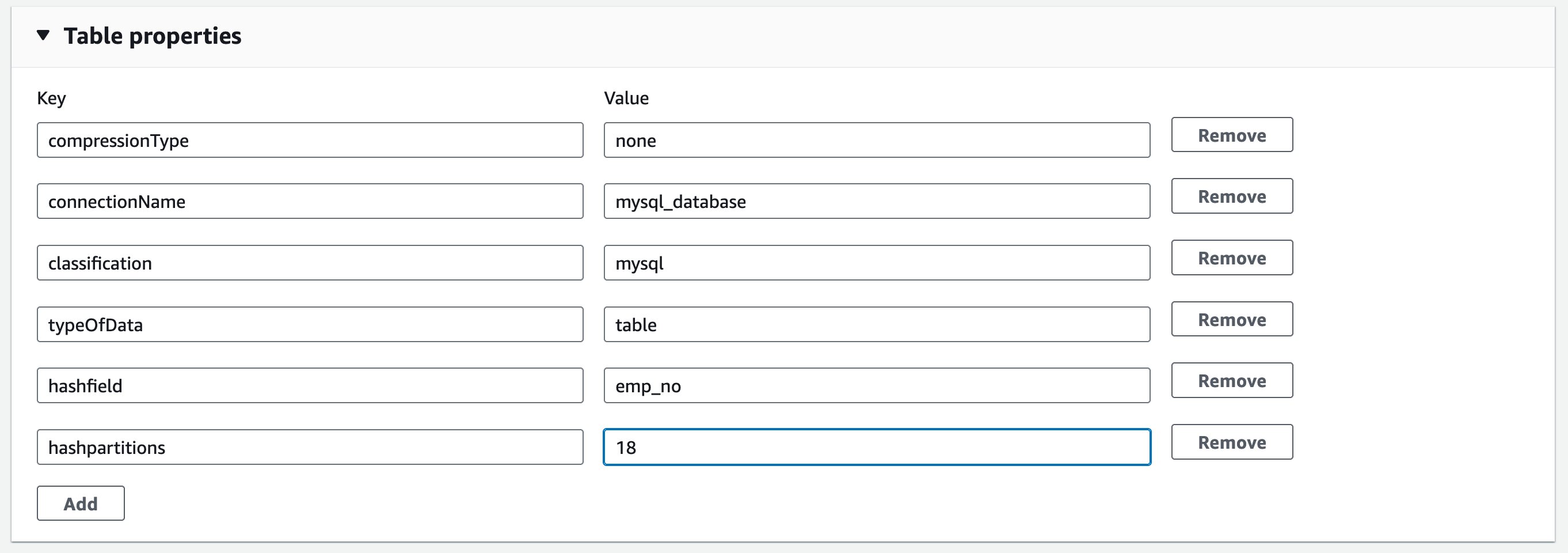
This implies the brand new job runs studying parallelize information load from the supply MySQL desk.
Let’s strive working the identical job once more! This time, the job run completed in 9 minutes and 9 seconds. It saved 21 minutes from the earlier job run.
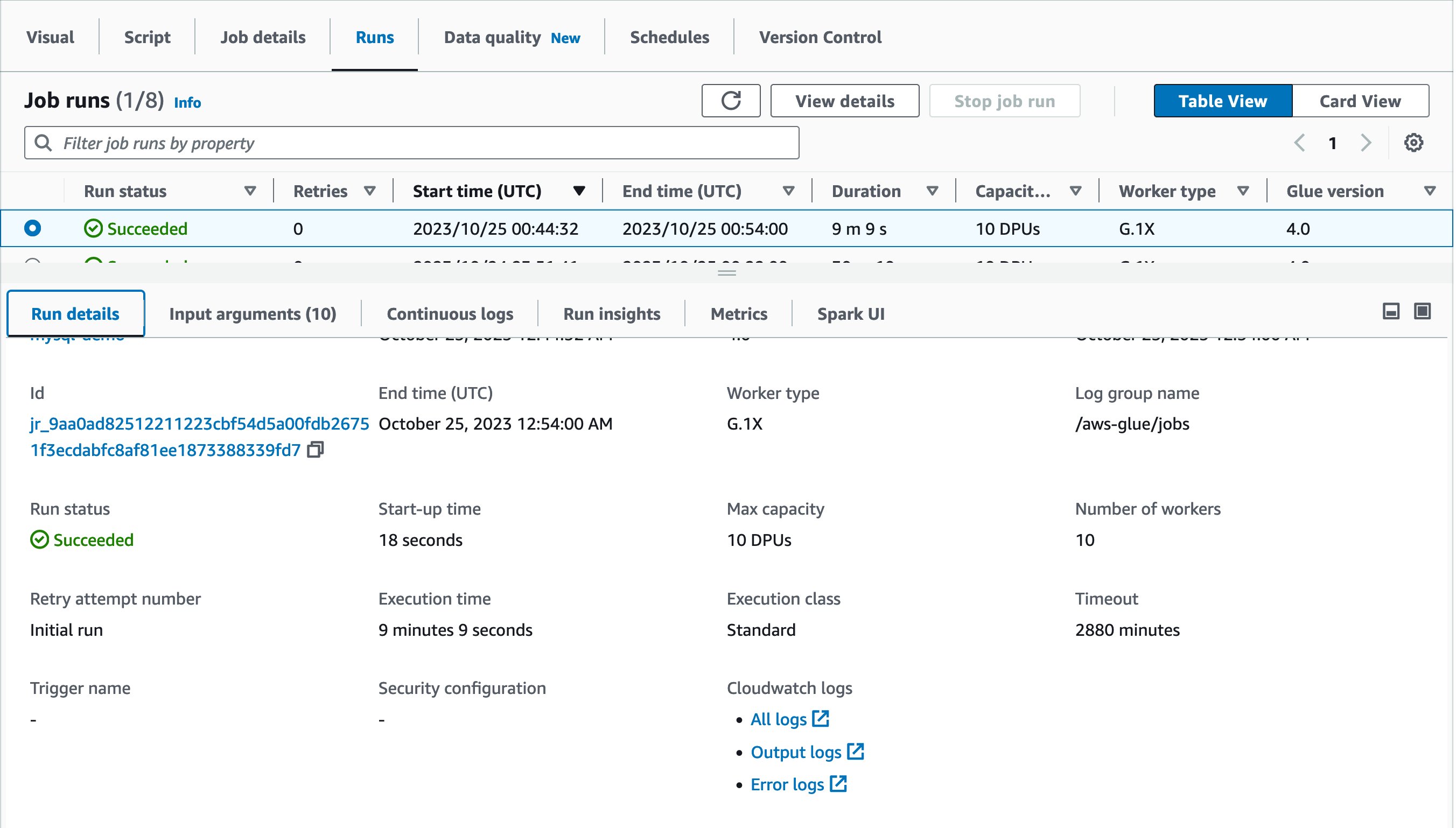
As a finest apply, view the Spark UI and evaluate them earlier than and after the optimization. Drilling all the way down to Accomplished levels, you’ll discover that there was one stage and 18 duties as an alternative of 1 process.
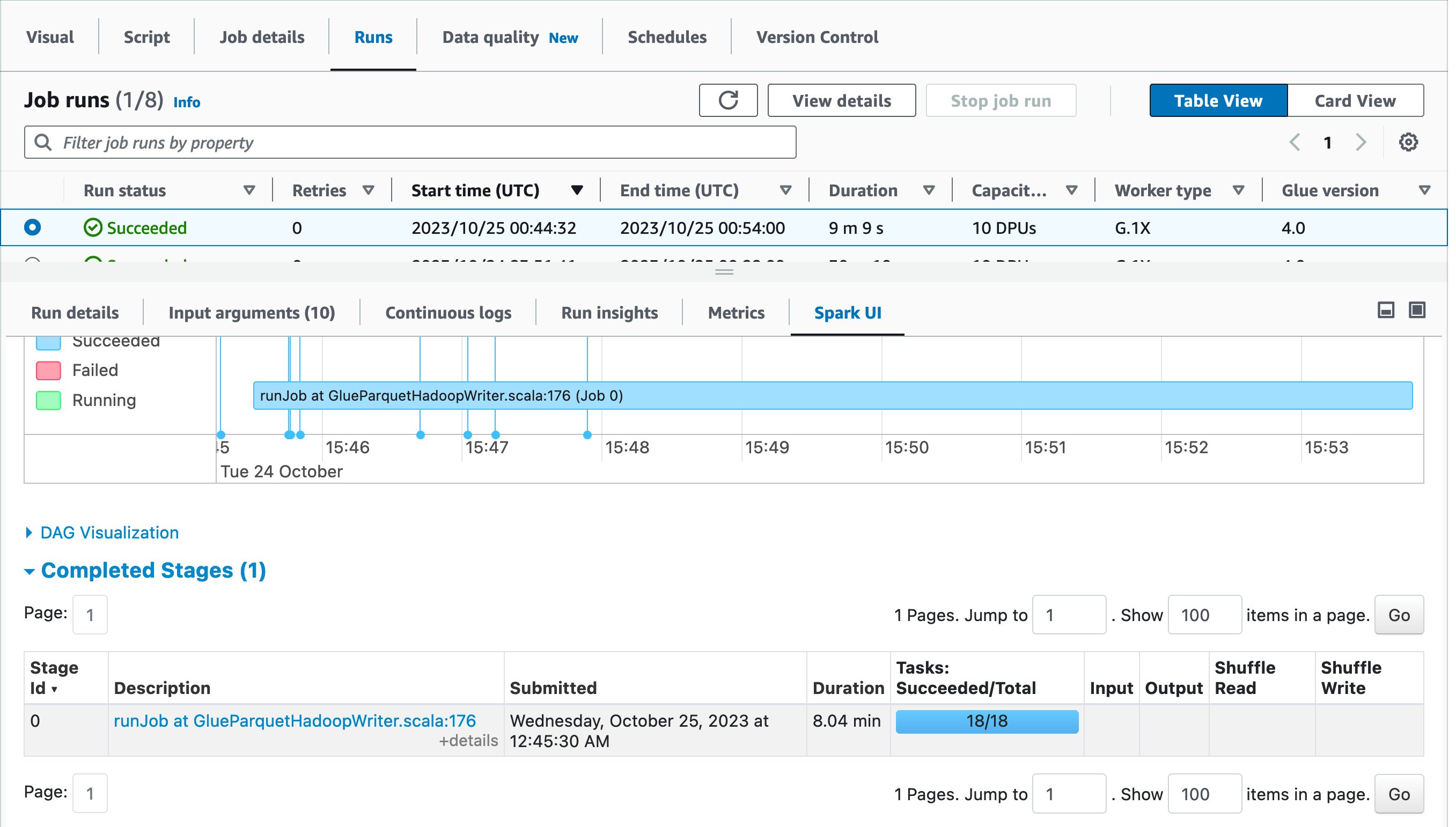
Within the first job run, AWS Glue routinely shuffled information throughout a number of executors earlier than writing to vacation spot as a result of there have been too few duties. Then again, within the second job run, there was just one stage as a result of there was no must do further shuffling, and there have been 18 duties for loading information in parallel from supply MySQL database.
Issues
Bear in mind the next issues:
- Serverless Spark UI is supported in AWS Glue 3.0 and later
- Serverless Spark UI can be accessible for jobs that ran after November 20, 2023, as a consequence of a change in how AWS Glue emits and shops Spark logs
- Serverless Spark UI can visualize Spark occasion logs which is as much as 1 GB in measurement
- There is no such thing as a restrict in retention as a result of serverless Spark UI scans the Spark occasion log recordsdata in your S3 bucket
- Serverless Spark UI just isn’t accessible for Spark occasion logs saved in S3 bucket that may solely be accessed by your VPC
- Spark UI within the AWS Glue console doesn’t assist rolling logs, corresponding to these generated by default in streaming jobs. You may flip off rolling logs for a streaming job by passing in extra configuration. Remember that very massive log recordsdata could value quite a bit to keep up. To show off rolling logs, present the next two job parameters:
- Key –
--spark-ui-event-logs-path, Worth –true - Key –
--conf, Worth –spark.eventLog.rolling.enabled=false
- Key –
Conclusion
This put up described how the AWS Glue serverless Spark UI helps you monitor and troubleshoot your AWS Glue jobs. By offering immediate entry to the Spark UI immediately inside the AWS Administration Console, now you can examine the low-level particulars of job runs to determine and resolve points. With the serverless Spark UI, there isn’t any infrastructure to handle—the UI spins up routinely for every job run and tears down when now not wanted. This streamlined expertise saves you effort and time in comparison with manually launching Spark UIs your self.
Give the serverless Spark UI a strive at the moment. We predict you’ll discover it invaluable for optimizing efficiency and shortly troubleshooting errors. We sit up for listening to your suggestions as we proceed bettering the AWS Glue console expertise.
Concerning the authors
 Noritaka Sekiyama is a Principal Large Information Architect on the AWS Glue group. He works based mostly in Tokyo, Japan. He’s liable for constructing software program artifacts to assist prospects. In his spare time, he enjoys biking on his highway bike.
Noritaka Sekiyama is a Principal Large Information Architect on the AWS Glue group. He works based mostly in Tokyo, Japan. He’s liable for constructing software program artifacts to assist prospects. In his spare time, he enjoys biking on his highway bike.
 Alexandra Tello is a Senior Entrance Finish Engineer with the AWS Glue group in New York Metropolis. She is a passionate advocate for usability and accessibility. In her free time, she’s an espresso fanatic and enjoys constructing mechanical keyboards.
Alexandra Tello is a Senior Entrance Finish Engineer with the AWS Glue group in New York Metropolis. She is a passionate advocate for usability and accessibility. In her free time, she’s an espresso fanatic and enjoys constructing mechanical keyboards.
 Matt Sampson is a Software program Growth Supervisor on the AWS Glue group. He loves working along with his different Glue group members to make providers that our prospects profit from. Outdoors of labor, he may be discovered fishing and possibly singing karaoke.
Matt Sampson is a Software program Growth Supervisor on the AWS Glue group. He loves working along with his different Glue group members to make providers that our prospects profit from. Outdoors of labor, he may be discovered fishing and possibly singing karaoke.
 Matt Su is a Senior Product Supervisor on the AWS Glue group. He enjoys serving to prospects uncover insights and make higher selections utilizing their information with AWS Analytic providers. In his spare time, he enjoys snowboarding and gardening.
Matt Su is a Senior Product Supervisor on the AWS Glue group. He enjoys serving to prospects uncover insights and make higher selections utilizing their information with AWS Analytic providers. In his spare time, he enjoys snowboarding and gardening.

{kind=link}