

For any fashionable data-driven firm, having clean knowledge integration pipelines is essential. These pipelines pull knowledge from varied sources, rework it, and cargo it into vacation spot techniques for analytics and reporting. When operating correctly, it gives well timed and reliable data. Nevertheless, with out vigilance, the various knowledge volumes, traits, and utility conduct may cause knowledge pipelines to grow to be inefficient and problematic. Efficiency can decelerate or pipelines can grow to be unreliable. Undetected errors lead to dangerous knowledge and influence downstream evaluation. That’s why sturdy monitoring and troubleshooting for knowledge pipelines is crucial throughout the next 4 areas:
- Reliability
- Efficiency
- Throughput
- Useful resource utilization
Collectively, these 4 elements of monitoring present end-to-end visibility and management over a knowledge pipeline and its operations.
In the present day we’re happy to announce a brand new class of Amazon CloudWatch metrics reported together with your pipelines constructed on prime of AWS Glue for Apache Spark jobs. The brand new metrics present combination and fine-grained insights into the well being and operations of your job runs and the information being processed. Along with offering insightful dashboards, the metrics present classification of errors, which helps with root trigger evaluation of efficiency bottlenecks and error prognosis. With this evaluation, you’ll be able to consider and apply the really helpful fixes and finest practices for architecting your jobs and pipelines. Because of this, you acquire the advantage of greater availability, higher efficiency, and decrease price to your AWS Glue for Apache Spark workload.
This put up demonstrates how the brand new enhanced metrics show you how to monitor and debug AWS Glue jobs.
Allow the brand new metrics
The brand new metrics might be configured by the job parameter enable-observability-metrics.
The brand new metrics are enabled by default on the AWS Glue Studio console. To configure the metrics on the AWS Glue Studio console, full the next steps:
- On the AWS Glue console, select ETL jobs within the navigation pane.
- Below Your jobs, select your job.
- On the Job particulars tab, develop Superior properties.
- Below Job observability metrics, choose Allow the creation of extra observability CloudWatch metrics when this job runs.

To allow the brand new metrics within the AWS Glue CreateJob and StartJobRun APIs, set the next parameters within the DefaultArguments property:
- Key –
--enable-observability-metrics - Worth –
true
To allow the brand new metrics within the AWS Command Line Interface (AWS CLI), set the identical job parameters within the --default-arguments argument.
Use case
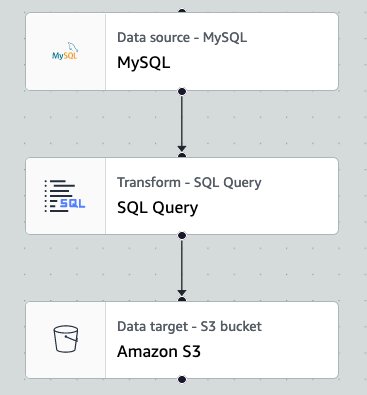
A typical workload for AWS Glue for Apache Spark jobs is to load knowledge from a relational database to a knowledge lake with SQL-based transformations. The next is a visible illustration of an instance job the place the variety of employees is 10.
When the instance job ran, the workerUtilization metrics confirmed the next development.
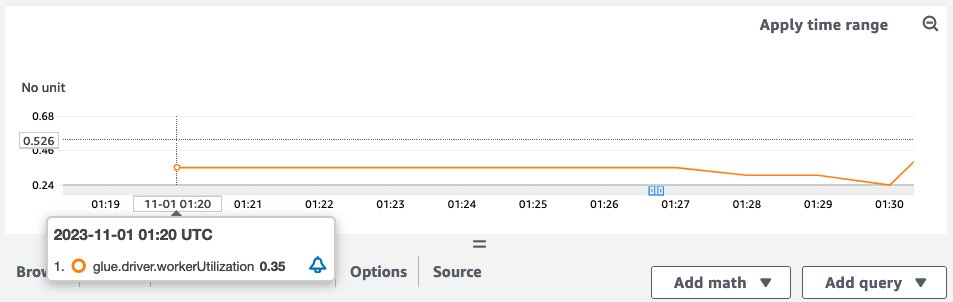
Be aware that workerUtilization confirmed values between 0.20 (20%) and 0.40 (40%) for all the period. This usually occurs when the job capability is over-provisioned and plenty of Spark executors have been idle, leading to pointless price. To enhance useful resource utilization effectivity, it’s a good suggestion to allow AWS Glue Auto Scaling. The next screenshot reveals the identical workerUtilization metrics graph when AWS Glue Auto Scaling is enabled for a similar job.
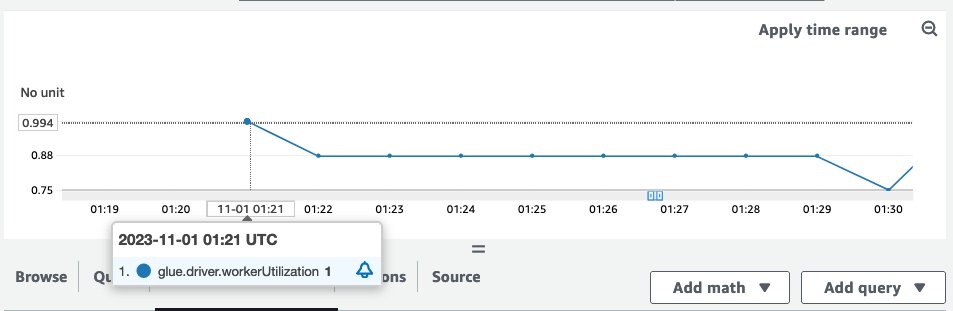
workerUtilization confirmed 1.0 at first due to AWS Glue Auto Scaling and it trended between 0.75 (75%) and 1.0 (100%) primarily based on the workload necessities.
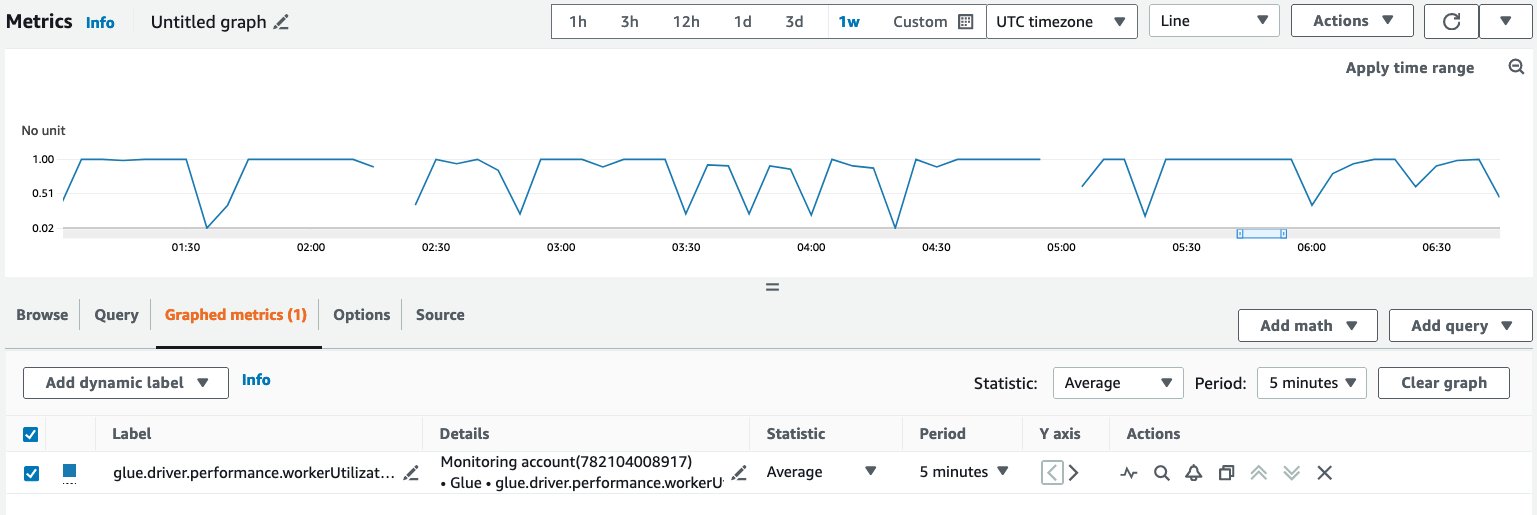
Question and visualize metrics in CloudWatch
Full the next steps to question and visualize metrics on the CloudWatch console:
- On the CloudWatch console, select All metrics within the navigation pane.
- Below Customized namespaces, select Glue.
- Select Observability Metrics (or Observability Metrics Per Supply, or Observability Metrics Per Sink).
- Seek for and choose the particular metric title, job title, job run ID, and observability group.
- On the Graphed metrics tab, configure your most popular statistic, interval, and so forth.
Question metrics utilizing the AWS CLI
Full the next steps for querying utilizing the AWS CLI (for this instance, we question the employee utilization metric):
- Create a metric definition JSON file (present your AWS Glue job title and job run ID):
- Run the
get-metric-datacommand:
Create a CloudWatch alarm
You may create static threshold-based alarms for the completely different metrics. For directions, consult with Create a CloudWatch alarm primarily based on a static threshold.
For instance, for skewness, you’ll be able to set an alarm for skewness.stage with a threshold of 1.0, and skewness.job with a threshold of 0.5. This threshold is only a suggestion; you’ll be able to modify the brink primarily based in your particular use case (for instance, some jobs are anticipated to be skewed and it’s not a problem to be alarmed for). Our suggestion is to judge the metric values of your job runs for a while earlier than qualifying the anomalous values and configuring the thresholds to alarm.
Different enhanced metrics
For a full record of different enhanced metrics out there with AWS Glue jobs, consult with Monitoring with AWS Glue Observability metrics. These metrics can help you seize the operational insights of your jobs, equivalent to useful resource utilization (reminiscence and disk), normalized error courses equivalent to compilation and syntax, person or service errors, and throughput for every supply or sink (information, recordsdata, partitions, and bytes learn or written).
Job observability dashboards
You may additional simplify observability to your AWS Glue jobs utilizing dashboards for the perception metrics that allow real-time monitoring utilizing Amazon Managed Grafana, and allow visualization and evaluation of traits with Amazon QuickSight.
Conclusion
This put up demonstrated how the brand new enhanced CloudWatch metrics show you how to monitor and debug AWS Glue jobs. With these enhanced metrics, you’ll be able to extra simply establish and troubleshoot points in actual time. This ends in AWS Glue jobs that have greater uptime, quicker processing, and lowered expenditures. The top profit for you is simpler and optimized AWS Glue for Apache Spark workloads. The metrics can be found in all AWS Glue supported Areas. Test it out!
Concerning the Authors
 Noritaka Sekiyama is a Principal Large Knowledge Architect on the AWS Glue staff. He’s chargeable for constructing software program artifacts to assist prospects. In his spare time, he enjoys biking along with his new street bike.
Noritaka Sekiyama is a Principal Large Knowledge Architect on the AWS Glue staff. He’s chargeable for constructing software program artifacts to assist prospects. In his spare time, he enjoys biking along with his new street bike.
 Shenoda Guirguis is a Senior Software program Improvement Engineer on the AWS Glue staff. His ardour is in constructing scalable and distributed Knowledge Infrastructure/Processing Programs. When he will get an opportunity, Shenoda enjoys studying and enjoying soccer.
Shenoda Guirguis is a Senior Software program Improvement Engineer on the AWS Glue staff. His ardour is in constructing scalable and distributed Knowledge Infrastructure/Processing Programs. When he will get an opportunity, Shenoda enjoys studying and enjoying soccer.
 Sean Ma is a Principal Product Supervisor on the AWS Glue staff. He has an 18+ yr observe file of innovating and delivering enterprise merchandise that unlock the ability of information for customers. Exterior of labor, Sean enjoys scuba diving and faculty soccer.
Sean Ma is a Principal Product Supervisor on the AWS Glue staff. He has an 18+ yr observe file of innovating and delivering enterprise merchandise that unlock the ability of information for customers. Exterior of labor, Sean enjoys scuba diving and faculty soccer.
 Mohit Saxena is a Senior Software program Improvement Supervisor on the AWS Glue staff. His staff focuses on constructing distributed techniques to allow prospects with interactive and easy to make use of interfaces to effectively handle and rework petabytes of information seamlessly throughout knowledge lakes on Amazon S3, databases and data-warehouses on cloud.
Mohit Saxena is a Senior Software program Improvement Supervisor on the AWS Glue staff. His staff focuses on constructing distributed techniques to allow prospects with interactive and easy to make use of interfaces to effectively handle and rework petabytes of information seamlessly throughout knowledge lakes on Amazon S3, databases and data-warehouses on cloud.

{kind=link}