
Following the announcement we made yesterday round Retrieval Augmented Technology (RAG), at this time, we’re excited to announce the general public preview of Databricks Vector Search. We introduced the non-public preview to a restricted set of shoppers on the Knowledge + AI Summit in June, which is now accessible to all our clients. Databricks Vector Search permits builders to enhance the accuracy of their Retrieval Augmented Technology (RAG) and generative AI functions by similarity search over unstructured paperwork akin to PDFs, Workplace Paperwork, Wikis, and extra. Vector Search is a part of the Databricks Knowledge Intelligence Platform, making it straightforward in your RAG and Generative AI functions to make use of the proprietary knowledge saved in your Lakehouse in a quick and safe method and ship correct responses.
We designed Databricks Vector Search to be quick, safe and simple to make use of.
- Quick with low TCO – Vector Search is designed to ship excessive efficiency at decrease TCO, with as much as 5x decrease latency than different suppliers
- Easy, quick developer expertise – Vector Search makes it doable to synchronize any Delta Desk right into a vector index with 1-click – no want for advanced, customized constructed knowledge ingestion/sync pipelines.
- Unified Governance – Vector Search makes use of the identical Unity Catalog-based safety and knowledge governance instruments that already energy your Knowledge Intelligence Platform, which means you should not have to construct and preserve a separate set of knowledge governance insurance policies in your unstructured knowledge
- Serverless Scaling – Our serverless infrastructure mechanically scales to your workflows with out the necessity to configure situations and server varieties.
What’s vector search?
Vector search is a technique utilized in data retrieval and Retrieval Augmented Technology (RAG) functions to seek out paperwork or data primarily based on their similarity to a question. Vector search is why you may kind a plain language question akin to “blue sneakers which are good for friday evening” and get again related outcomes.
Tech giants have used vector seek for years to energy their product experiences – with the arrival of Generative AI, these capabilities are lastly democratized to all organizations.
Here is a breakdown of how Vector Search works:
Embeddings: In vector search, knowledge and queries are represented as vectors in a multi-dimensional area referred to as embeddings from a Generative AI mannequin.
Let’s take a easy instance the place we need to use vector search to seek out semantically related phrases in a big corpus of phrases. So, in case you question the corpus with the phrase ‘canine’, you need phrases like ‘pet’ to be returned. However, in case you seek for ‘automotive’, you need to retrieve phrases like ‘van’. In conventional search, you’ll have to preserve an inventory of synonyms or “related phrases” which is difficult to generate or scale. With a view to use vector search, you may as an alternative use a Generative AI mannequin to transform these phrases into vectors in a n-dimensional area referred to as embeddings. These vectors could have the property that semantically related phrases like ‘canine’ and ‘pet’ will probably be nearer to every within the n-dimensional area than the phrases ‘canine’ and ‘automotive’.
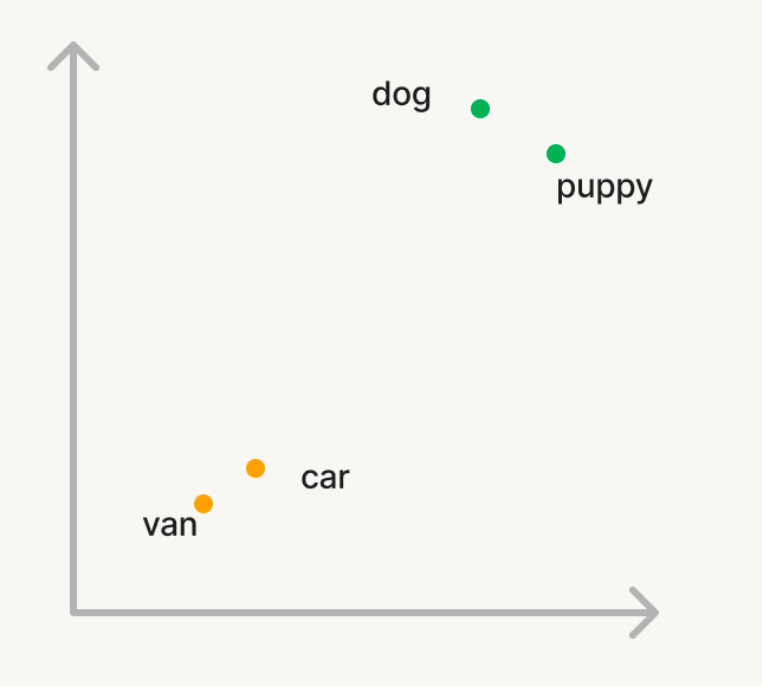
Similarity Calculation: To seek out related paperwork for a question, the similarity between the question vector and every doc vector is calculated to measure how shut they’re to one another within the n-dimensional area. That is sometimes carried out utilizing cosine similarity, which measures the cosine of the angle between the 2 vectors. There are a number of algorithms which are used to seek out related vectors in an environment friendly method, with HNSW primarily based algorithms persistently being greatest in efficiency
Functions: Vector search has many use circumstances:
- Suggestions – customized, context conscious suggestions to customers
- RAG – delivering related unstructured paperwork to assist a RAG utility reply person’s questions
- Semantic search – enabling plain language search queries that ship related outcomes
- Doc clustering – perceive similarities and variations between knowledge
Why do clients love Databricks Vector Search?
“We’re thrilled to leverage Databricks’ highly effective options to rework our buyer assist operations at Lippert. Managing a dynamic name middle setting for a corporation our dimension, the problem of bringing new brokers in control amidst the everyday agent churn is critical. Databricks gives the important thing to our answer – by establishing an agent-assist expertise powered by Vector Search, we will empower our brokers to swiftly discover solutions to buyer inquiries. By ingesting content material from product manuals, YouTube movies, and assist circumstances into our Vector Search, Databricks ensures our brokers have the data they want at their fingertips. This progressive strategy is a game-changer for Lippert, enhancing effectivity and elevating the client assist expertise.”
-Chris Nishnick, Synthetic Intelligence, Lippert
Automated Knowledge Ingestion
Earlier than a vector database can retailer data, it requires an information ingestion pipeline the place uncooked, unprocessed knowledge from numerous sources should be cleaned, processed (parsed/chunked), and embedded with an AI mannequin earlier than it’s saved as vectors within the database. This course of to construct and preserve one other set of knowledge ingestion pipelines is pricey and time-consuming, taking time from worthwhile engineering assets. Databricks Vector Search is totally built-in with the Databricks Knowledge Intelligence Platform, enabling it to mechanically pull knowledge and embed that knowledge with no need to construct and preserve new knowledge pipelines.
Our Delta Sync APIs mechanically synchronize supply knowledge with vector indexes. As supply knowledge is added, up to date, or deleted, we mechanically replace the corresponding vector index to match. Underneath the hood, Vector Search manages failures, handles retries, and optimizes batch sizes to offer you one of the best efficiency and throughput with none work or enter. These optimizations scale back your whole price of possession because of elevated utilization of your embedding mannequin endpoint.
Let’s check out an instance the place we create a vector index in three easy steps. All Vector Search capabilities can be found by REST APIs, our Python SDK, or throughout the Databricks UI.
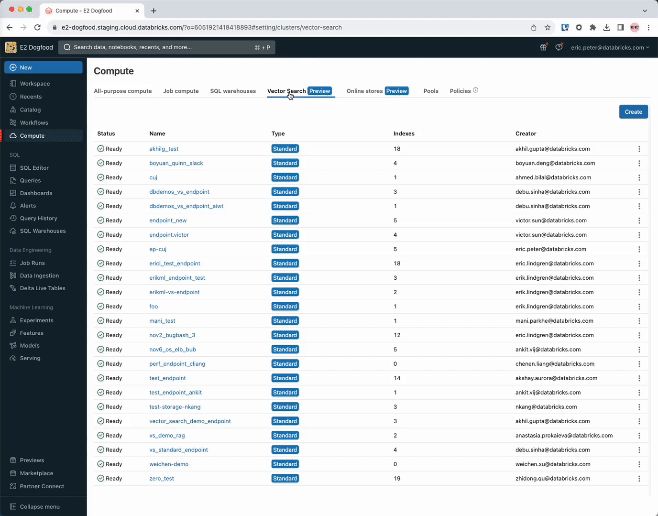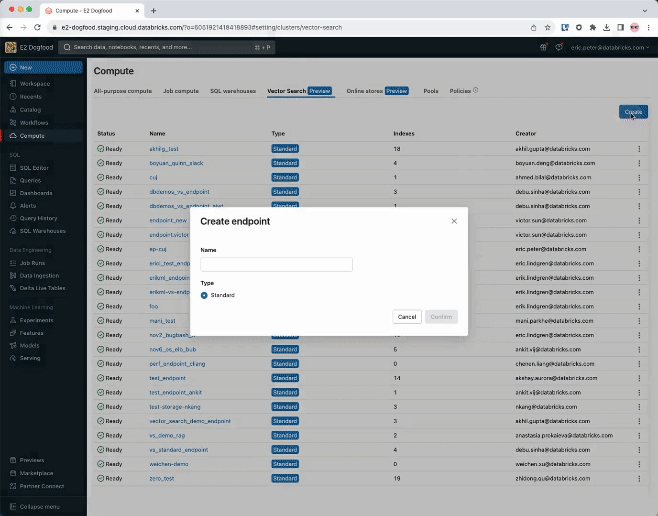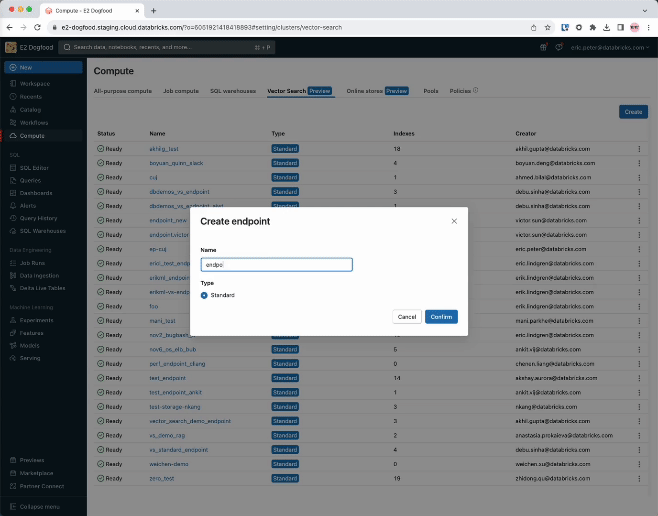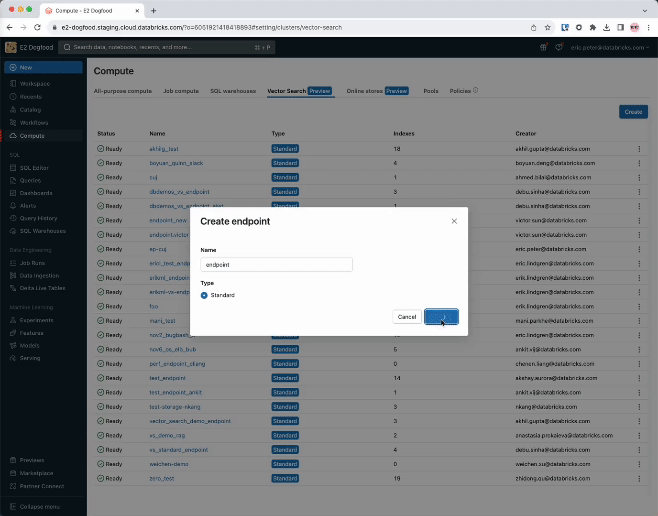
Step 1. Create a vector search endpoint that will probably be used to create and question a vector index utilizing the UI or our REST API/SDK.
from databricks.vector_search.shopper import VectorSearchClient
vsc = VectorSearchClient()
vsc.create_endpoint(title="endpoint", endpoint_type="STANDARD")Step 2. After making a Delta Desk together with your supply knowledge, you choose a column within the Delta Desk to embed after which choose a Mannequin Serving endpoint that’s used to generate embeddings for the information.
The embedding mannequin may be:
- A mannequin that you just fine-tuned
- An off-the-shelf open supply mannequin (akin to E5, BGE, InstructorXL, and many others)
- A proprietary embedding mannequin accessible through API (akin to OpenAI, Cohere, Anthropic, and many others)
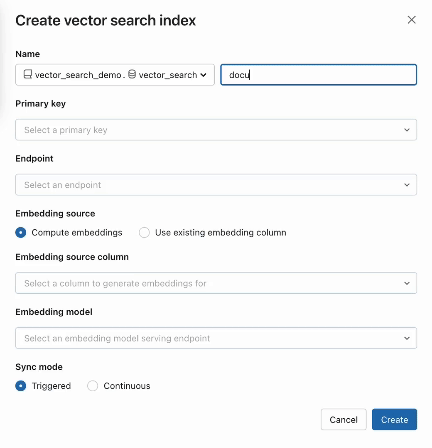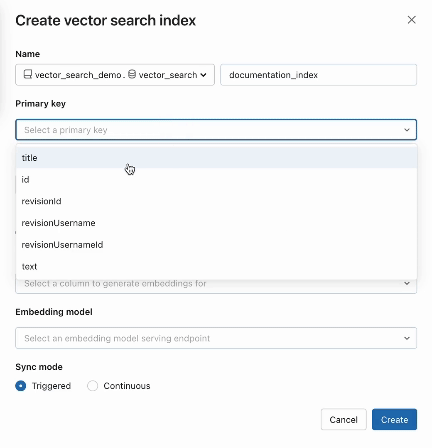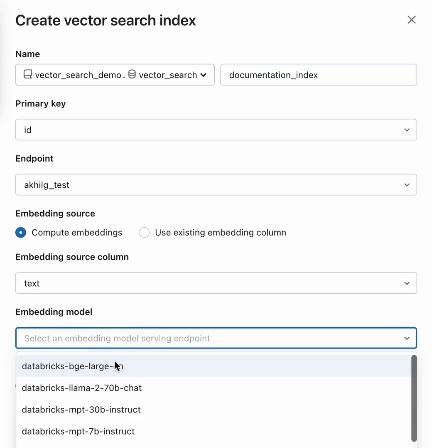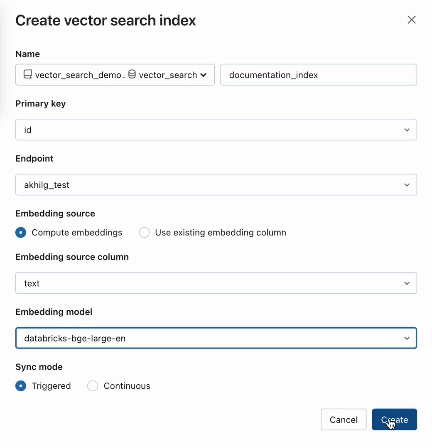
#The desk we would wish to index
source_table_fullname = "acme.product.documentation"
#Title of the vector index
vs_index_fullname = "acme.product.documentation_vs_index"
#Title of the embedding distant endpoint
embedding_model_endpoint_name="embeddings_endpoint"
index=vsc.create_delta_sync_index(
endpoint_name=vs_endpoint_name,
index_name=vs_index_fullname,
source_table_name=source_table_fullname,
pipeline_type="CONTINUOUS",
primary_key="id",
embedding_model_endpoint_name=proxy_endpoint_name,
embedding_source_column="content material"
)Vector Search additionally presents superior modes for purchasers that choose to handle their embeddings in a Delta Desk or create knowledge ingestion pipelines utilizing REST APIs. For examples, please see the Vector Search documentation.
Step 3. As soon as the index is prepared, you may make queries to seek out related vectors in your question. These outcomes can then be despatched to your Retrieval Augmented Technology (RAG) utility.
query = "How can I observe billing utilization on my workspaces?"
outcomes = index.similarity_search(
query_text=query,
columns=["url", "content"],
num_results=1)“This product is simple to make use of, and we have been up and operating in a matter of hours. All of our knowledge is in Delta already, so the built-in managed expertise of Vector Search with delta sync is superior.”
—- Alex Dalla Piazza (EQT Company)“
Constructed-In Governance
Enterprise organizations require stringent safety and entry controls over their knowledge so customers can not use Generative AI fashions to offer them confidential knowledge they shouldn’t have entry to. Nonetheless, present Vector databases both should not have sturdy safety and entry controls or require organizations to construct and preserve a separate set of safety insurance policies separate from their knowledge platform. Having a number of units of safety and governance provides price and complexity and is error-prone to take care of reliably.
Databricks Vector Search leverages the identical safety controls and knowledge governance that already protects the remainder of the Knowledge Intelligence Platform enabled by integration with Unity Catalog. The vector indexes are saved as entities inside your Unity catalog and leverage the identical unified interface to outline insurance policies on knowledge, with fine-grained management on embeddings.
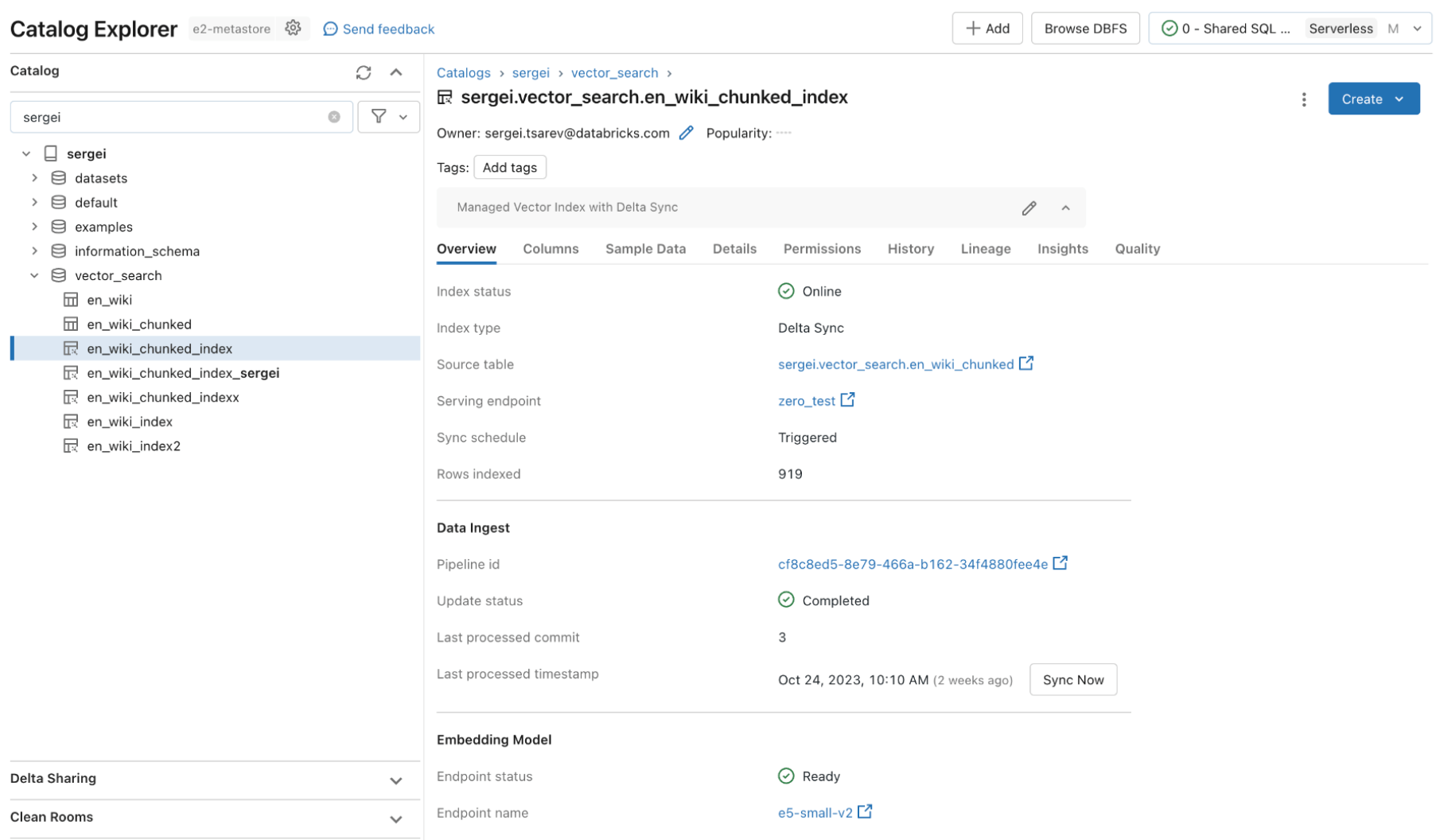
Quick Question Efficiency
As a result of maturity of the market, many vector databases present good leads to Proof-of-Ideas (POCs) with small quantities of knowledge. Nonetheless, they typically fall quick in efficiency or scalability for manufacturing deployments. With poor out-of-the-box efficiency, customers must work out the way to tune and scale search indexes which is time-consuming and tough to do effectively. They’re compelled to grasp their workload and make tough decisions on what compute situations to choose, and what configuration to make use of.
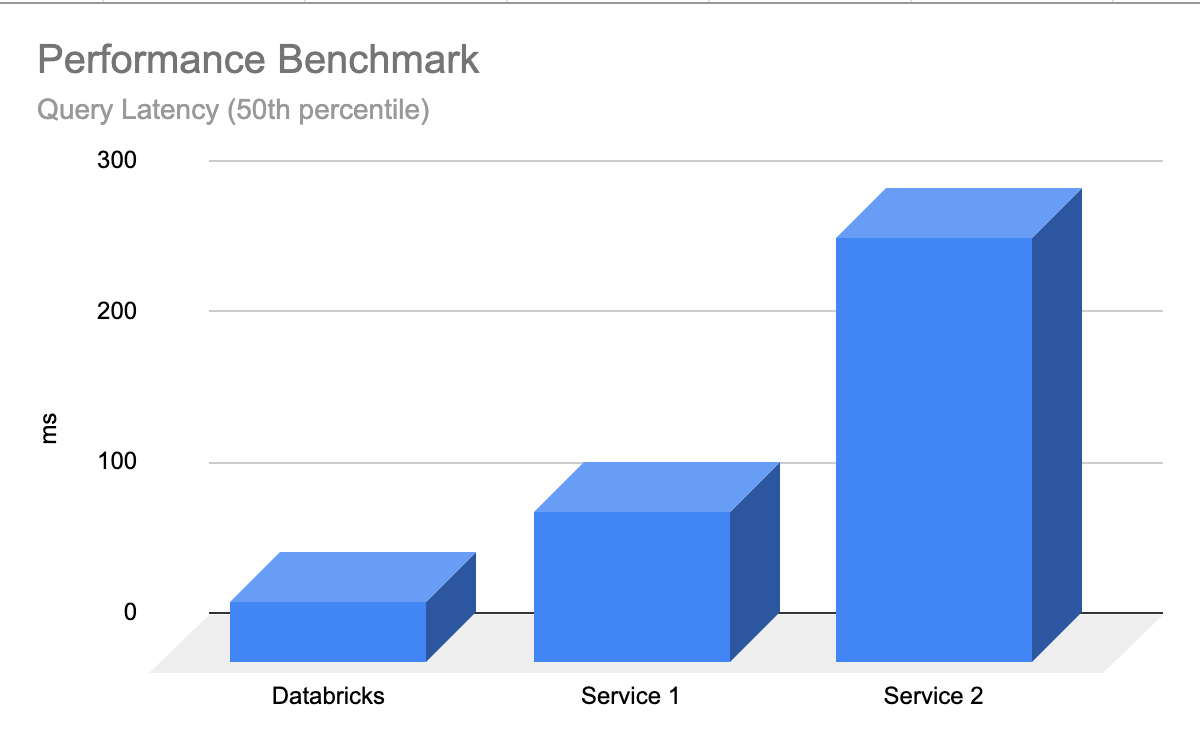
Databricks Vector Search is performant out-of-the-box the place the LLMs return related outcomes shortly with minimal latency and nil work wanted to tune and scale the database. Vector Search is designed to be extraordinarily quick for queries with or with out filtering. It reveals efficiency as much as 5x higher than among the different main vector databases. It’s straightforward to configure – you merely inform us your anticipated workload dimension (e.g., queries per second), required latency, and anticipated variety of embeddings – we care for the remainder. You don’t want to fret about occasion varieties, RAM/CPU, or understanding the internal workings of how vector databases function.
We spent quite a lot of effort customizing Databricks Vector Search to assist AI workloads that 1000’s of our clients are already operating on Databricks. The optimizations included benchmarking and figuring out one of the best {hardware} appropriate for semantic search, optimizing the underlying search algorithm and the community overhead to offer one of the best efficiency at scale.
Subsequent Steps
Get began by studying our documentation and particularly making a Vector Search index
Learn extra about Vector Search pricing
Beginning deploying your individual RAG utility (demo)
Signal–up for a Databricks Generative AI Webinar
Learn the abstract bulletins made earlier this week

{kind=link}