

Motivation
Accessing, understanding, and retrieving data from paperwork are central to numerous processes throughout numerous industries. Whether or not working in finance, healthcare, at a mother and pop carpet retailer, or as a pupil in a College, there are conditions the place you see an enormous doc that it’s essential learn via to reply questions. Enter JITR, a game-changing software that ingests PDF recordsdata and leverages LLMs (Language Language Fashions) to reply person queries concerning the content material. Let’s discover the magic behind JITR.
What Is JITR?
JITR, which stands for Simply In Time Retrieval, is likely one of the latest instruments in DataRobot’s GenAI Accelerator suite designed to course of PDF paperwork, extract their content material, and ship correct solutions to person questions and queries. Think about having a private assistant that may learn and perceive any PDF doc after which present solutions to your questions on it immediately. That’s JITR for you.
How Does JITR Work?
Ingesting PDFs: The preliminary stage includes ingesting a PDF into the JITR system. Right here, the software converts the static content material of the PDF right into a digital format ingestible by the embedding mannequin. The embedding mannequin converts every sentence within the PDF file right into a vector. This course of creates a vector database of the enter PDF file.
Making use of your LLM: As soon as the content material is ingested, the software calls the LLM. LLMs are state-of-the-art AI fashions educated on huge quantities of textual content knowledge. They excel at understanding context, discerning that means, and producing human-like textual content. JITR employs these fashions to grasp and index the content material of the PDF.
Interactive Querying: Customers can then pose questions concerning the PDF’s content material. The LLM fetches the related data and presents the solutions in a concise and coherent method.
Advantages of Utilizing JITR
Each group produces quite a lot of paperwork which are generated in a single division and consumed by one other. Typically, retrieval of knowledge for workers and groups might be time consuming. Utilization of JITR improves worker effectivity by lowering the assessment time of prolonged PDFs and offering immediate and correct solutions to their questions. As well as, JITR can deal with any kind of PDF content material which allows organizations to embed and put it to use in several workflows with out concern for the enter doc.
Many organizations might not have sources and experience in software program growth to develop instruments that make the most of LLMs of their workflow. JITR allows groups and departments that aren’t fluent in Python to transform a PDF file right into a vector database as context for an LLM. By merely having an endpoint to ship PDF recordsdata to, JITR might be built-in into any internet software corresponding to Slack (or different messaging instruments), or exterior portals for purchasers. No information of LLMs, Pure Language Processing (NLP), or vector databases is required.
Actual-World Functions
Given its versatility, JITR might be built-in into virtually any workflow. Beneath are a few of the functions.
Enterprise Report: Professionals can swiftly get insights from prolonged reviews, contracts, and whitepapers. Equally, this software might be built-in into inner processes, enabling workers and groups to work together with inner paperwork.
Buyer Service: From understanding technical manuals to diving deep into tutorials, JITR can allow clients to work together with manuals and paperwork associated to the merchandise and instruments. This could improve buyer satisfaction and cut back the variety of help tickets and escalations.
Analysis and Growth: R&D groups can shortly extract related and digestible data from advanced analysis papers to implement the State-of-the-art know-how within the product or inner processes.
Alignment with Pointers: Many organizations have tips that ought to be adopted by workers and groups. JITR allows workers to retrieve related data from the rules effectively.
Authorized: JITR can ingest authorized paperwork and contracts and reply questions primarily based on the data offered within the enter paperwork.
Easy methods to Construct the JITR Bot with DataRobot
The workflow for constructing a JITR Bot is just like the workflow for deploying any LLM pipeline utilizing DataRobot. The 2 fundamental variations are:
- Your vector database is outlined at runtime
- You want logic to deal with an encoded PDF
For the latter we will outline a easy operate that takes an encoding and writes it again to a brief PDF file inside our deployment.
```python
def base_64_to_file(b64_string, filename: str="temp.PDF", directory_path: str = "./storage/knowledge") -> str:
"""Decode a base64 string right into a PDF file"""
import os
if not os.path.exists(directory_path):
os.makedirs(directory_path)
file_path = os.path.be part of(directory_path, filename)
with open(file_path, "wb") as f:
f.write(codecs.decode(b64_string, "base64"))
return file_path
```
With this helper operate outlined we will undergo and make our hooks. Hooks are only a fancy phrase for features with a selected title. In our case, we simply must outline a hook known as `load_model` and one other hook known as `score_unstructured`. In `load_model`, we’ll set the embedding mannequin we wish to use to search out essentially the most related chunks of textual content in addition to the LLM we’ll ping with our context conscious immediate.
```python
def load_model(input_dir):
"""Customized mannequin hook for loading our information base."""
import os
import datarobot_drum as drum
from langchain.chat_models import AzureChatOpenAI
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
strive:
# Pull credentials from deployment
key = drum.RuntimeParameters.get("OPENAI_API_KEY")["apiToken"]
besides ValueError:
# Pull credentials from atmosphere (when working domestically)
key = os.environ.get('OPENAI_API_KEY', '')
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2",
cache_folder=os.path.be part of(input_dir, 'storage/deploy/sentencetransformers')
)
llm = AzureChatOpenAI(
deployment_name=OPENAI_DEPLOYMENT_NAME,
openai_api_type=OPENAI_API_TYPE,
openai_api_base=OPENAI_API_BASE,
openai_api_version=OPENAI_API_VERSION,
openai_api_key=OPENAI_API_KEY,
openai_organization=OPENAI_ORGANIZATION,
model_name=OPENAI_DEPLOYMENT_NAME,
temperature=0,
verbose=True
)
return llm, embedding_function
```Okay, so we’ve our embedding operate and our LLM. We even have a technique to take an encoding and get again to a PDF. So now we get to the meat of the JITR Bot, the place we’ll construct our vector retailer at run time and use it to question the LLM.
```python
def score_unstructured(mannequin, knowledge, question, **kwargs) -> str:
"""Customized mannequin hook for making completions with our information base.
When requesting predictions from the deployment, move a dictionary
with the next keys:
- 'query' the query to be handed to the retrieval chain
- 'doc' a base64 encoded doc to be loaded into the vector database
datarobot-user-models (DRUM) handles loading the mannequin and calling
this operate with the suitable parameters.
Returns:
--------
rv : str
Json dictionary with keys:
- 'query' person's authentic query
- 'reply' the generated reply to the query
"""
import json
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores.base import VectorStoreRetriever
from langchain.vectorstores.faiss import FAISS
llm, embedding_function = mannequin
DIRECTORY = "./storage/knowledge"
temp_file_name = "temp.PDF"
data_dict = json.masses(knowledge)
# Write encoding to file
base_64_to_file(data_dict['document'].encode(), filename=temp_file_name, directory_path=DIRECTORY)
# Load up the file
loader = PyPDFLoader(os.path.be part of(DIRECTORY, temp_file_name))
docs = loader.load_and_split()
# Take away file when performed
os.take away(os.path.be part of(DIRECTORY, temp_file_name))
# Create our vector database
texts = [doc.page_content for doc in docs]
metadatas = [doc.metadata for doc in docs]
db = FAISS.from_texts(texts, embedding_function, metadatas=metadatas)
# Outline our chain
retriever = VectorStoreRetriever(vectorstore=db)
chain = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever
)
# Run it
response = chain(inputs={'query': data_dict['question'], 'chat_history': []})
return json.dumps({"outcome": response})
```With our hooks outlined, all that’s left to do is deploy our pipeline in order that we’ve an endpoint folks can work together with. To some, the method of making a safe, monitored and queryable endpoint out of arbitrary Python code might sound intimidating or not less than time consuming to arrange. Utilizing the drx package deal, we will deploy our JITR Bot in a single operate name.
```python
import datarobotx as drx
deployment = drx.deploy(
"./storage/deploy/", # Path with embedding mannequin
title=f"JITR Bot {now}",
hooks={
"score_unstructured": score_unstructured,
"load_model": load_model
},
extra_requirements=["pyPDF"], # Add a package deal for parsing PDF recordsdata
environment_id="64c964448dd3f0c07f47d040", # GenAI Dropin Python atmosphere
)
```Easy methods to Use JITR
Okay, the onerous work is over. Now we get to take pleasure in interacting with our newfound deployment. By way of Python, we will once more benefit from the drx package deal to reply our most urgent questions.
```python
# Discover a PDF
url = "https://s3.amazonaws.com/datarobot_public_datasets/drx/Instantnoodles.PDF"
resp = requests.get(url).content material
encoding = base64.b64encode(io.BytesIO(resp).learn()) # encode it
# Work together
response = deployment.predict_unstructured(
{
"query": "What does this say about noodle rehydration?",
"doc": encoding.decode(),
}
)['result']
— – – –
{'query': 'What does this say about noodle rehydration?',
'chat_history': [],
'reply': 'The article mentions that in the course of the frying course of, many tiny holes are created resulting from mass switch, and so they function channels for water penetration upon rehydration in scorching water. The porous construction created throughout frying facilitates rehydration.'}
```However extra importantly, we will hit our deployment in any language we wish because it’s simply an endpoint. Beneath, I present a screenshot of me interacting with the deployment proper via Postman. This implies we will combine our JITR Bot into basically any software we wish by simply having the applying make an API name.
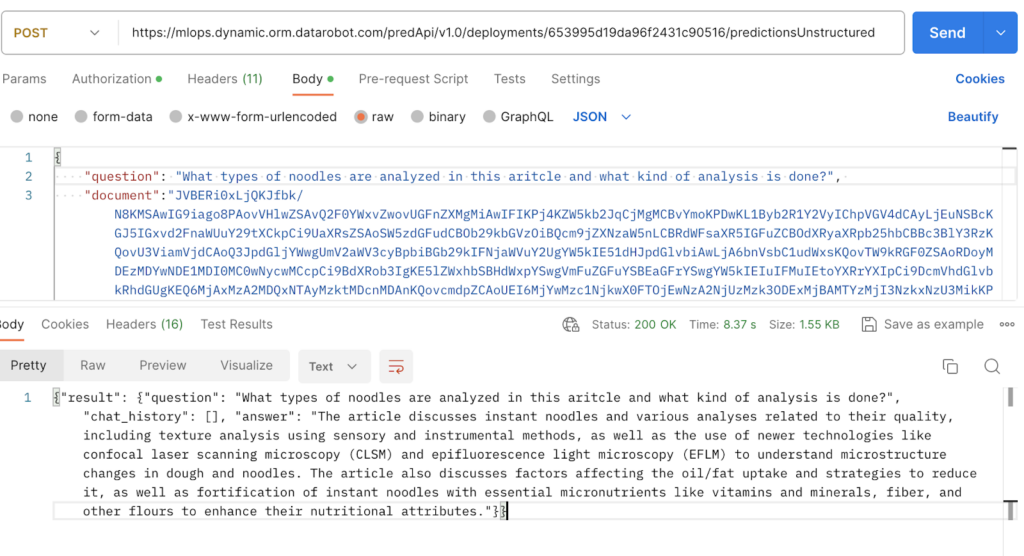
As soon as embedded in an software, utilizing JITR could be very simple. For instance, within the Slackbot software used at DataRobot internally, customers merely add a PDF with a query to start out a dialog associated to the doc.
JITR makes it simple for anybody in a company to start out driving real-world worth from generative AI, throughout numerous touchpoints in workers’ day-to-day workflows. Take a look at this video to be taught extra about JITR.
Issues You Can Do to Make the JITR Bot Extra Highly effective
Within the code I confirmed, we ran via a simple implementation of the JITRBot which takes an encoded PDF and makes a vector retailer at runtime with a view to reply questions. Since they weren’t related to the core idea, I opted to go away out quite a lot of bells and whistles we applied internally with the JITRBot corresponding to:
- Returning context conscious immediate and completion tokens
- Answering questions primarily based on a number of paperwork
- Answering a number of questions directly
- Letting customers present dialog historical past
- Utilizing different chains for various kinds of questions
- Reporting customized metrics again to the deployment
There’s additionally no motive why the JITRBot has to solely work with PDF recordsdata! As long as a doc might be encoded and transformed again right into a string of textual content, we might construct extra logic into our `score_unstructured` hook to deal with any file kind a person offers.
Begin Leveraging JITR in Your Workflow
JITR makes it simple to work together with arbitrary PDFs. Should you’d like to offer it a strive, you’ll be able to observe together with the pocket book right here.

{kind=link}