
Amazon Easy Storage Service (Amazon S3) is without doubt one of the main cloud object storage providers obtainable. It makes use of an HTTP interface, making it simple for utility builders to combine S3 into their purposes.
Athena is a serverless question service supplied by Amazon to question the information saved in Amazon S3 utilizing commonplace SQL. As a result of it integrates simply with S3, is serverless, and makes use of a well-known language, Athena has develop into the default service for many enterprise intelligence (BI) choice makers to question the massive quantities of (often streaming) knowledge coming into their object shops.
Although it’s highly effective sufficient to assist huge batch analytics, Athena falls quick in terms of real-time analytics purposes.
Limitations of Utilizing S3 and Athena for Actual-Time Analytics
The way in which Athena is constructed makes it clear that it’s not supposed for use for real-time analytics.
For instance, once you run an Athena question, the question is submitted to a queue quite than being run instantly. When it’s time to run that question, the information is fetched from S3. As soon as the result’s obtainable, it’s uploaded again to S3, within the designated path, the place the appliance can lastly entry the outcome.
Moreover, when querying S3 knowledge from Athena, it has to question the whole dataset each time a question is run. You can create partitions when organising the S3 bucket and the information path to restrict the quantity of information being queried, however when you arrange the listing construction and the information is saved in that path, you may’t change it until you’re able to populate the information once more. Moreover, the partition is restricted solely to timestamps, so you may’t have a customized partition, reminiscent of buyer ID or zip code.
One other downside is that there’s no option to index the information being populated in S3, which means there’s no option to optimize question efficiency. You simply should hope that the dataset being queried is sufficiently small that it doesn’t take too lengthy to return with the outcomes. You possibly can construct an efficient analytics or reporting dashboard utilizing the S3 and Athena combo, however in case you attempt to construct a real-time utility you’ll discover the latency is just too excessive for it to be performant. Moreover, you may’t have various concurrent connections to Athena. This may shortly develop into a bottleneck.
As a result of Athena is restricted to operating solely 5 queries in parallel at any time by default, there’s no assure that your question might be executed instantly. It would work in case you’re a small group or a person. But when Athena is already built-in into an utility with actual customers, they might have to attend minutes to get a response. That is undoubtedly not a very good person expertise.
Athena is greatest for batch processing and purposes the place the latency of the outcome will not be essential. Athena additionally works nicely for knowledge and enterprise intelligence engineers who run loads of advert hoc queries on the information throughout growth. When you’re able to implement an utility with low latency and excessive concurrency necessities although, it’s best to begin in search of alternate options.
Constructing Actual-Time Analytics on S3 Utilizing Rockset
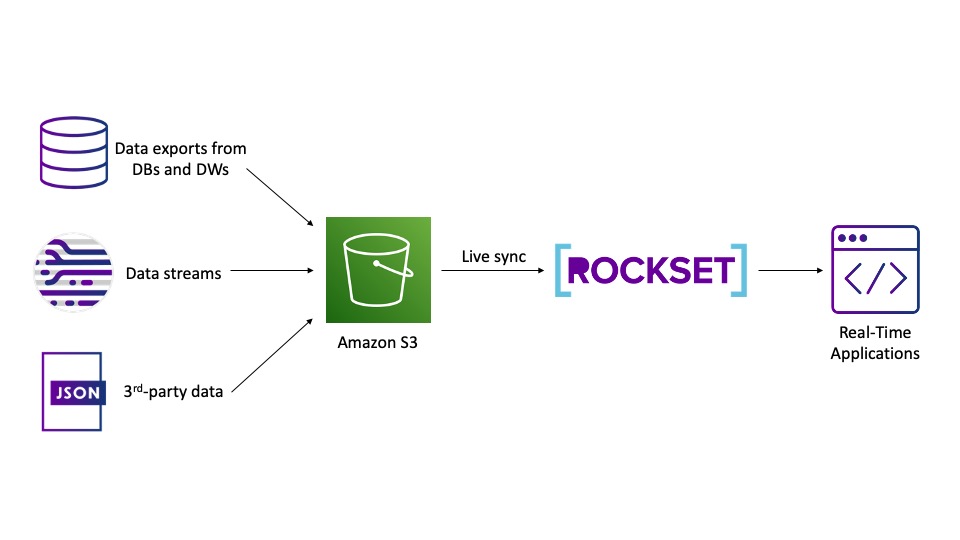
Rockset was constructed with real-time analytics in thoughts. Rockset’s superior indexes make it attainable to serve outcomes as much as 125x sooner than Athena, whereas making knowledge able to be queried in below a second of being ingested. As an illustration, you would have one utility writing knowledge to S3 whereas one other utility is querying for a similar knowledge in near-real time.
Athena will not be a datastore by itself, it’s only a question engine for the datastore in S3. In case you have JSON or CSV recordsdata in S3, they’re going to be columnar in nature, and there’s solely a lot you are able to do with that type of knowledge. Rockset, nonetheless, takes that knowledge and creates several types of indexes on it, thereby making queries as environment friendly as attainable.

Determine 1: Utilizing Rockset to index knowledge in Amazon S3 for real-time analytics
Converged Index
Rockset creates greater than only one index for a chunk of information coming into the database. For instance, suppose you’ve got JSON knowledge coming into S3 with a discipline known as “title” in it. Rockset sees this discipline and creates several types of key-value shops on this discipline. This characteristic is named converged indexing, and it comes with the next indexes:
- Row retailer
- Columnar retailer
- Search index

Determine 2: Instance of converged indexing
As you may see from Determine 3 under, these indexes are used for completely different functions primarily based on the question you’re operating. For instance, in case you run a question to search out the typical worth or to sum the values of a specific discipline, Rockset will optimize for this request and robotically use the columnar retailer to fetch the outcomes. Equally, in case you are attempting to filter your knowledge primarily based on the worth of a specific discipline, Rockset will once more optimize for that request and robotically use the search index.

Determine 3: Totally different indexes are used for several types of queries
Having several types of indexes and letting Rockset resolve which is greatest for a given question means you may cease worrying about optimizing your question and concentrate on constructing your characteristic.
Question Latency
As a result of Rockset robotically maintains these in depth indexes, much less knowledge needs to be scanned to get the outcomes of a question. This drastically reduces latency in order that Rockset can be utilized in real-time purposes.
That is attainable as a result of Rockset decides which index must be used on the fly primarily based on the question. If required, Rockset can use a number of indexes for a single question.
Concurrent Queries
When many customers are utilizing your utility and often querying the database, it’s worthwhile to have a lot of concurrent queries operating. For this reason Athena’s default limitation of 5 queries operating in parallel could cause a bottleneck, and it’s not simple learn how to enhance that quantity.
Conversely, Rockset helps 1000s of QPS (queries per second) by making the most of cloud elasticity and autoscaling compute as wanted to deal with massive question volumes.
Mutability of Information and Schema
In Athena, if you wish to change the schema, say so as to add or take away a discipline, it’s important to go to Hive or Glue to make that change. It’s very specific and entails handbook intervention. However with Rockset, it’s all dynamic.
As a result of Rockset creates indexes primarily based on the information coming in, it robotically adjusts to the schema of the incoming knowledge. This could be a large timesaver when you’ve got a wide range of knowledge coming in from many sources. With Rockset, the information turns into obtainable for queries as quickly as it’s obtained, with out the necessity for a predetermined schema.
Developer Productiveness
Rockset gives a saved procedure-like characteristic known as Question Lambdas. It’s a named, parameterized SQL question saved on Rockset.
Question Lambdas are serverless saved queries in Rockset that use RESTful APIs for interfacing. They take parameters within the API request for use within the question that can finally be run. The question outcome then comes again within the response of that API request.
The benefit of utilizing Question Lambdas is you could hold your utility code freed from hard-coded SQL queries. Primarily based in your wants, you may simply change the question independently of the appliance and replace the Question Lambda within the backend. This doesn’t require any app updates on the person’s finish, and they’ll proceed to get the up to date outcomes.
As a result of the interface to Question Lambdas is RESTful APIs, it’s handy for builders to get began. This additionally signifies that a backend group could be writing and updating queries on the Rockset finish whereas frontend builders can merely devour the APIs and concentrate on bettering the appliance, with out having to jot down advanced SQL queries.
Making Actual-Time Analytics Potential on Information Lakes
Whereas the S3 and Athena mixture is sufficient for asynchronous querying use instances, it’s much less nicely suited to real-time analytics. Athena was, in spite of everything, designed primarily for rare queries that would tolerate excessive variability in latency.
Actual-time purposes, then again, demand a distinct kind of structure that optimizes for pace, concurrency, and schema flexibility. In case you have a requirement to construct extra demanding purposes on knowledge in S3, Rockset gives a purpose-built answer for real-time analytics.
To study extra, view the Rockset Actual-Time Analytics on Information Lakes tech discuss with CTO, Dhruba Borthakur, for a extra in-depth dialogue of key concerns when constructing purposes on S3 knowledge.
To study extra, view the Rockset tech discuss under with CTO, Dhruba Borthakur, for a extra in-depth dialogue of key concerns when constructing purposes on S3 knowledge.

{kind=link}