
)
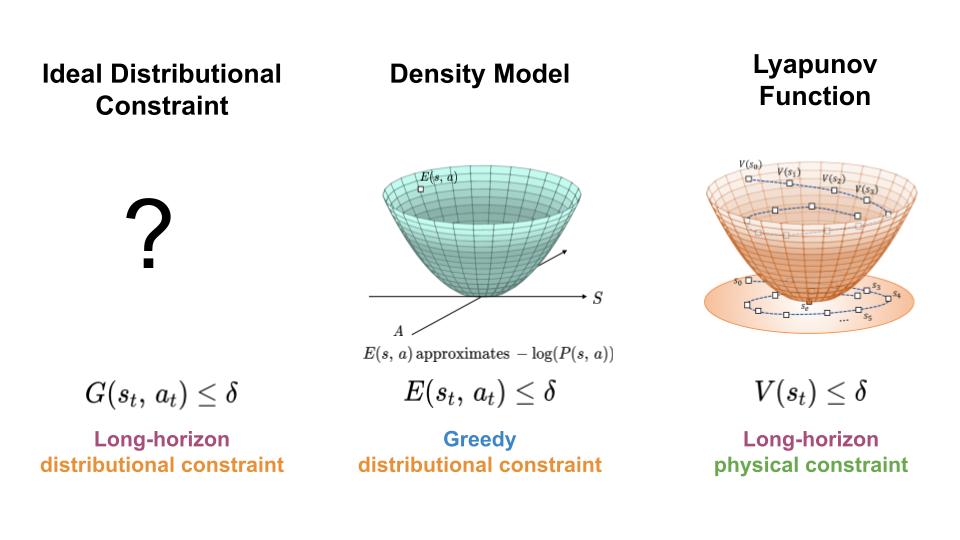
To manage the distribution shift expertise by learning-based controllers, we search a mechanism for constraining the agent to areas of excessive information density all through its trajectory (left). Right here, we current an strategy which achieves this aim by combining options of density fashions (center) and Lyapunov features (proper).
With a view to make use of machine studying and reinforcement studying in controlling actual world programs, we should design algorithms which not solely obtain good efficiency, but in addition work together with the system in a secure and dependable method. Most prior work on safety-critical management focuses on sustaining the security of the bodily system, e.g. avoiding falling over for legged robots, or colliding into obstacles for autonomous automobiles. Nonetheless, for learning-based controllers, there may be one other supply of security concern: as a result of machine studying fashions are solely optimized to output appropriate predictions on the coaching information, they’re vulnerable to outputting faulty predictions when evaluated on out-of-distribution inputs. Thus, if an agent visits a state or takes an motion that could be very totally different from these within the coaching information, a learning-enabled controller might “exploit” the inaccuracies in its discovered element and output actions which can be suboptimal and even harmful.
To forestall these potential “exploitations” of mannequin inaccuracies, we suggest a brand new framework to cause concerning the security of a learning-based controller with respect to its coaching distribution. The central thought behind our work is to view the coaching information distribution as a security constraint, and to attract on instruments from management concept to manage the distributional shift skilled by the agent throughout closed-loop management. Extra particularly, we’ll focus on how Lyapunov stability will be unified with density estimation to supply Lyapunov density fashions, a brand new form of security “barrier” perform which can be utilized to synthesize controllers with ensures of conserving the agent in areas of excessive information density. Earlier than we introduce our new framework, we’ll first give an outline of present methods for guaranteeing bodily security by way of barrier perform.
In management concept, a central subject of examine is: given recognized system dynamics, $s_{t+1}=f(s_t, a_t)$, and recognized system constraints, $s in C$, how can we design a controller that’s assured to maintain the system inside the specified constraints? Right here, $C$ denotes the set of states which can be deemed secure for the agent to go to. This drawback is difficult as a result of the desired constraints should be glad over the agent’s complete trajectory horizon ($s_t in C$ $forall 0leq t leq T$). If the controller makes use of a easy “grasping” technique of avoiding constraint violations within the subsequent time step (not taking $a_t$ for which $f(s_t, a_t) notin C$), the system should still find yourself in an “irrecoverable” state, which itself is taken into account secure, however will inevitably result in an unsafe state sooner or later whatever the agent’s future actions. With a view to keep away from visiting these “irrecoverable” states, the controller should make use of a extra “long-horizon” technique which includes predicting the agent’s complete future trajectory to keep away from security violations at any level sooner or later (keep away from $a_t$ for which all attainable ${ a_{hat{t}} }_{hat{t}=t+1}^H$ result in some $bar{t}$ the place $s_{bar{t}} notin C$ and $t<bar{t} leq T$). Nonetheless, predicting the agent’s full trajectory at each step is extraordinarily computationally intensive, and sometimes infeasible to carry out on-line throughout run-time.
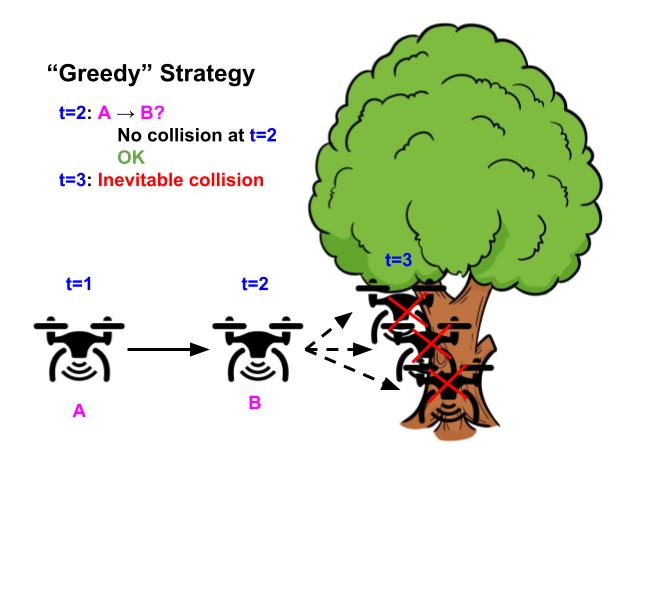
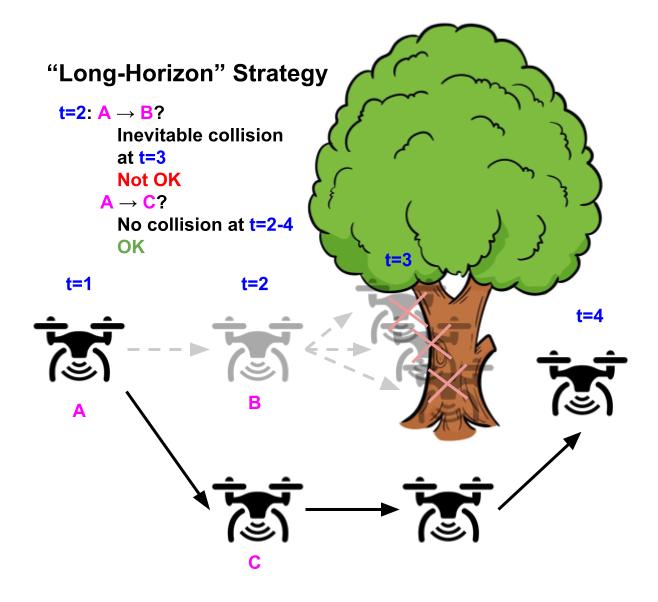
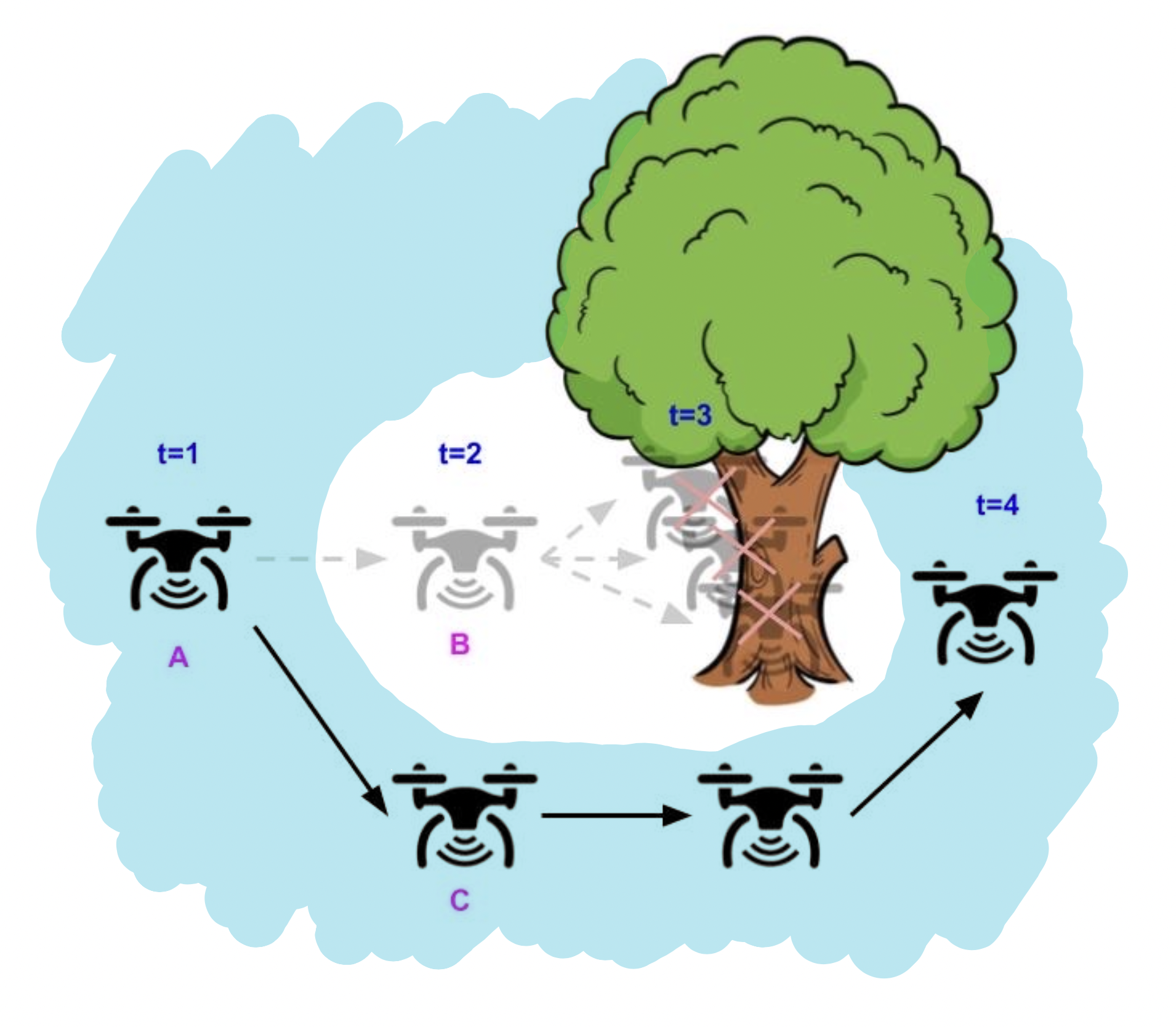
Illustrative instance of a drone whose aim is to fly as straight as attainable whereas avoiding obstacles. Utilizing the “grasping” technique of avoiding security violations (left), the drone flies straight as a result of there’s no impediment within the subsequent timestep, however inevitably crashes sooner or later as a result of it may possibly’t flip in time. In distinction, utilizing the “long-horizon” technique (proper), the drone turns early and efficiently avoids the tree, by contemplating the whole future horizon way forward for its trajectory.
Management theorists deal with this problem by designing “barrier” features, $v(s)$, to constrain the controller at every step (solely enable $a_t$ which fulfill $v(f(s_t, a_t)) leq 0$). With a view to make sure the agent stays secure all through its complete trajectory, the constraint induced by barrier features ($v(f(s_t, a_t))leq 0$) prevents the agent from visiting each unsafe states and irrecoverable states which inevitably result in unsafe states sooner or later. This technique basically amortizes the computation of trying into the longer term for inevitable failures when designing the security barrier perform, which solely must be accomplished as soon as and will be computed offline. This fashion, at runtime, the coverage solely must make use of the grasping constraint satisfaction technique on the barrier perform $v(s)$ to be able to guarantee security for all future timesteps.
The blue area denotes the of states allowed by the barrier perform constraint, $ v(s) leq 0$. Utilizing a “long-horizon” barrier perform, the drone solely must greedily be certain that the barrier perform constraint $v(s) leq 0$ is glad for the following state, to be able to keep away from security violations for all future timesteps.
Right here, we used the notion of a “barrier” perform as an umbrella time period to explain a lot of totally different sorts of features whose functionalities are to constrain the controller to be able to make long-horizon ensures. Some particular examples embrace management Lyapunov features for guaranteeing stability, management barrier features for guaranteeing basic security constraints, and the worth perform in Hamilton-Jacobi reachability for guaranteeing basic security constraints beneath exterior disturbances. Extra just lately, there has additionally been some work on studying barrier features, for settings the place the system is unknown or the place barrier features are troublesome to design. Nonetheless, prior works in each conventional and learning-based barrier features are primarily targeted on making ensures of bodily security. Within the subsequent part, we’ll focus on how we will lengthen these concepts to control the distribution shift skilled by the agent when utilizing a learning-based controller.
To forestall mannequin exploitation as a result of distribution shift, many learning-based management algorithms constrain or regularize the controller to forestall the agent from taking low-likelihood actions or visiting low probability states, as an illustration in offline RL, model-based RL, and imitation studying. Nonetheless, most of those strategies solely constrain the controller with a single-step estimate of the information distribution, akin to the “grasping” technique of conserving an autonomous drone secure by stopping actions which causes it to crash within the subsequent timestep. As we noticed within the illustrative figures above, this technique just isn’t sufficient to ensure that the drone won’t crash (or go out-of-distribution) in one other future timestep.
How can we design a controller for which the agent is assured to remain in-distribution for its complete trajectory? Recall that barrier features can be utilized to ensure constraint satisfaction for all future timesteps, which is precisely the form of assure we hope to make with reference to the information distribution. Based mostly on this commentary, we suggest a brand new form of barrier perform: the Lyapunov density mannequin (LDM), which merges the dynamics-aware facet of a Lyapunov perform with the data-aware facet of a density mannequin (it’s in truth a generalization of each sorts of perform). Analogous to how Lyapunov features retains the system from turning into bodily unsafe, our Lyapunov density mannequin retains the system from going out-of-distribution.
An LDM ($G(s, a)$) maps state and motion pairs to destructive log densities, the place the values of $G(s, a)$ signify one of the best information density the agent is ready to keep above all through its trajectory. It may be intuitively considered a “dynamics-aware, long-horizon” transformation on a single-step density mannequin ($E(s, a)$), the place $E(s, a)$ approximates the destructive log probability of the information distribution. Since a single-step density mannequin constraint ($E(s, a) leq -log(c)$ the place $c$ is a cutoff density) may nonetheless enable the agent to go to “irrecoverable” states which inevitably causes the agent to go out-of-distribution, the LDM transformation will increase the worth of these “irrecoverable” states till they change into “recoverable” with respect to their up to date worth. In consequence, the LDM constraint ($G(s, a) leq -log(c)$) restricts the agent to a smaller set of states and actions which excludes the “irrecoverable” states, thereby guaranteeing the agent is ready to stay in excessive data-density areas all through its complete trajectory.
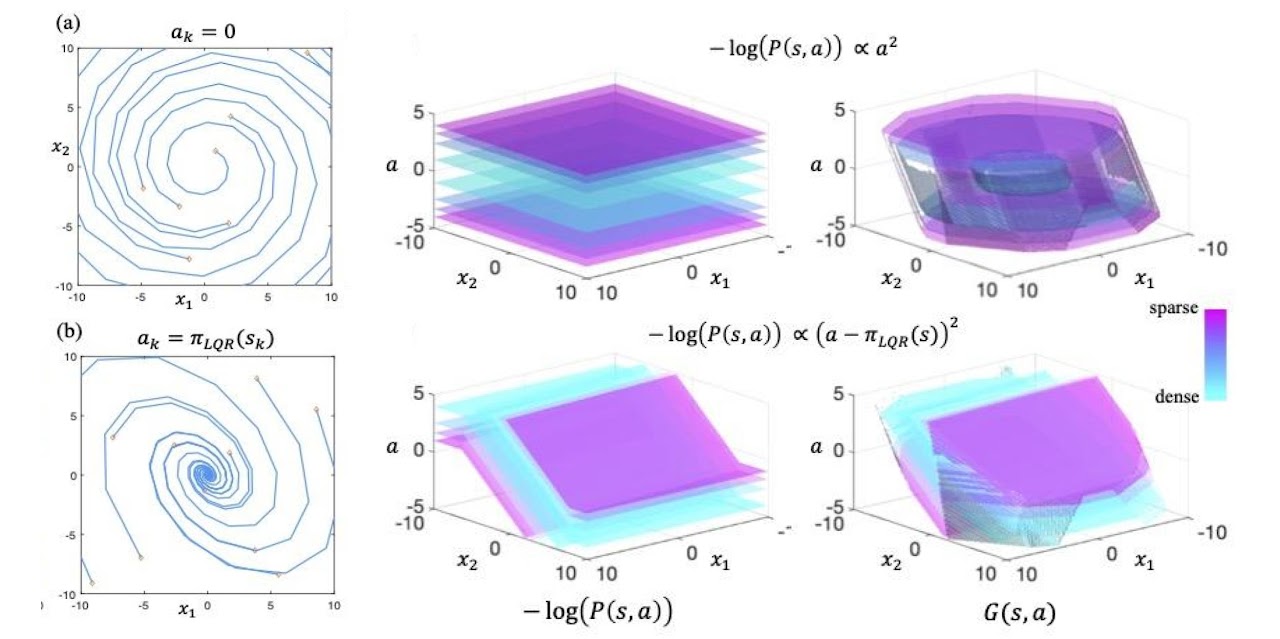
Instance of information distributions (center) and their related LDMs (proper) for a 2D linear system (left). LDMs will be considered as “dynamics-aware, long-horizon” transformations on density fashions.
How precisely does this “dynamics-aware, long-horizon” transformation work? Given a knowledge distribution $P(s, a)$ and dynamical system $s_{t+1} = f(s_t, a_t)$, we outline the next because the LDM operator: $mathcal{T}G(s, a) = max{-log P(s, a), min_{a’} G(f(s, a), a’)}$. Suppose we initialize $G(s, a)$ to be $-log P(s, a)$. Underneath one iteration of the LDM operator, the worth of a state motion pair, $G(s, a)$, can both stay at $-log P(s, a)$ or enhance in worth, relying on whether or not the worth at one of the best state motion pair within the subsequent timestep, $min_{a’} G(f(s, a), a’)$, is bigger than $-log P(s, a)$. Intuitively, if the worth at one of the best subsequent state motion pair is bigger than the present $G(s, a)$ worth, because of this the agent is unable to stay on the present density degree no matter its future actions, making the present state “irrecoverable” with respect to the present density degree. By rising the present the worth of $G(s, a)$, we’re “correcting” the LDM such that its constraints wouldn’t embrace “irrecoverable” states. Right here, one LDM operator replace captures the impact of trying into the longer term for one timestep. If we repeatedly apply the LDM operator on $G(s, a)$ till convergence, the ultimate LDM shall be freed from “irrecoverable” states within the agent’s complete future trajectory.
To make use of an LDM in management, we will prepare an LDM and learning-based controller on the identical coaching dataset and constrain the controller’s motion outputs with an LDM constraint ($G(s, a)) leq -log(c)$). As a result of the LDM constraint prevents each states with low density and “irrecoverable” states, the learning-based controller will be capable to keep away from out-of-distribution inputs all through the agent’s complete trajectory. Moreover, by selecting the cutoff density of the LDM constraint, $c$, the consumer is ready to management the tradeoff between defending towards mannequin error vs. flexibility for performing the specified activity.
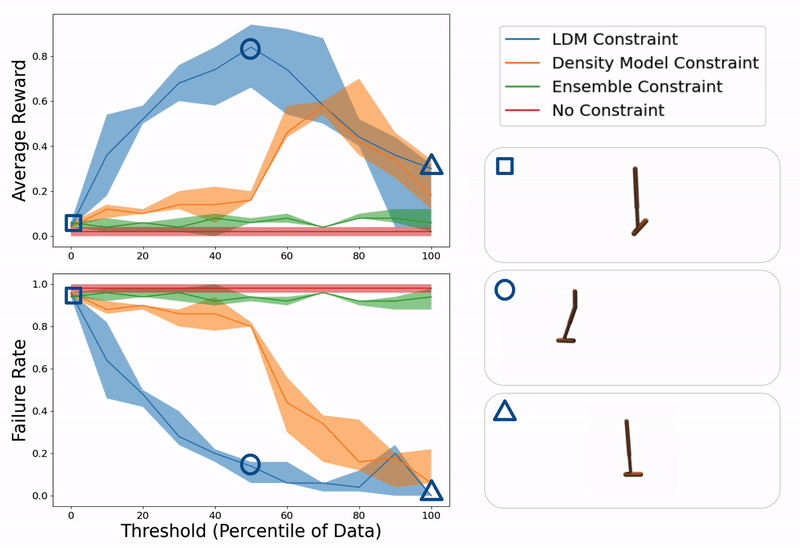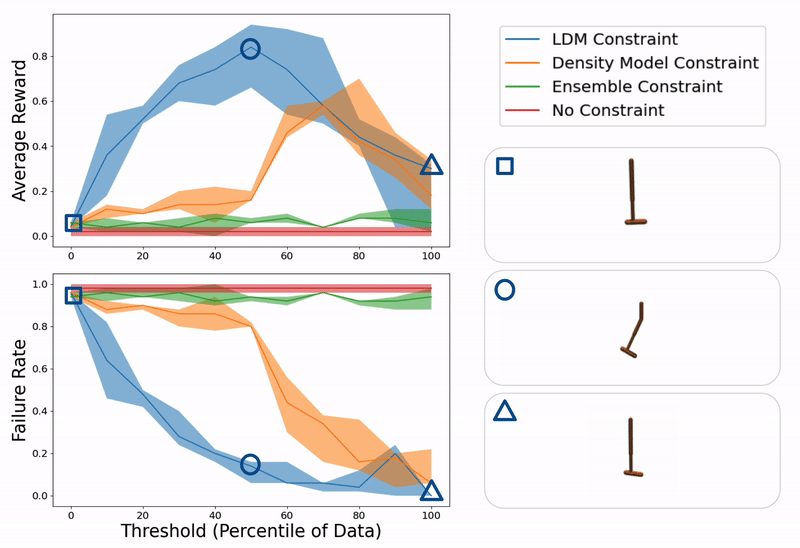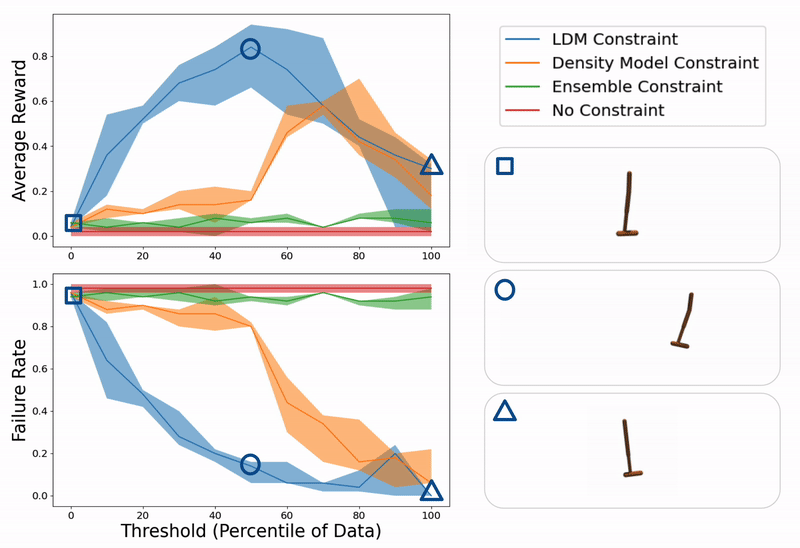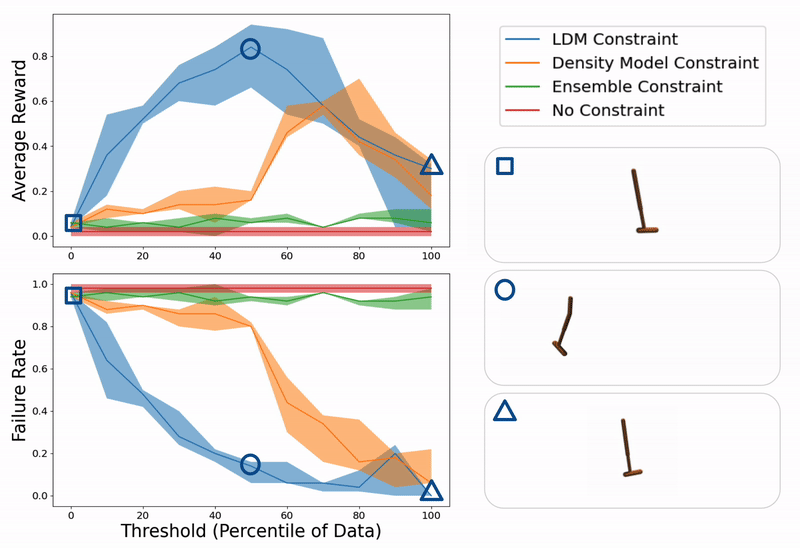
Instance analysis of ours and baseline strategies on a hopper management activity for various values of constraint thresholds (x- axis). On the best, we present instance trajectories from when the brink is just too low (hopper falling over as a result of extreme mannequin exploitation), good (hopper efficiently hopping in direction of goal location), or too excessive (hopper standing nonetheless as a result of over conservatism).
To this point, we’ve solely mentioned the properties of a “good” LDM, which will be discovered if we had oracle entry to the information distribution and dynamical system. In observe, although, we approximate the LDM utilizing solely information samples from the system. This causes an issue to come up: regardless that the function of the LDM is to forestall distribution shift, the LDM itself may undergo from the destructive results of distribution shift, which degrades its effectiveness for stopping distribution shift. To grasp the diploma to which the degradation occurs, we analyze this drawback from each a theoretical and empirical perspective. Theoretically, we present even when there are errors within the LDM studying process, an LDM constrained controller remains to be capable of preserve ensures of conserving the agent in-distribution. Albeit, this assure is a bit weaker than the unique assure offered by an ideal LDM, the place the quantity of degradation depends upon the dimensions of the errors within the studying process. Empirically, we approximate the LDM utilizing deep neural networks, and present that utilizing a discovered LDM to constrain the learning-based controller nonetheless gives efficiency enhancements in comparison with utilizing single-step density fashions on a number of domains.
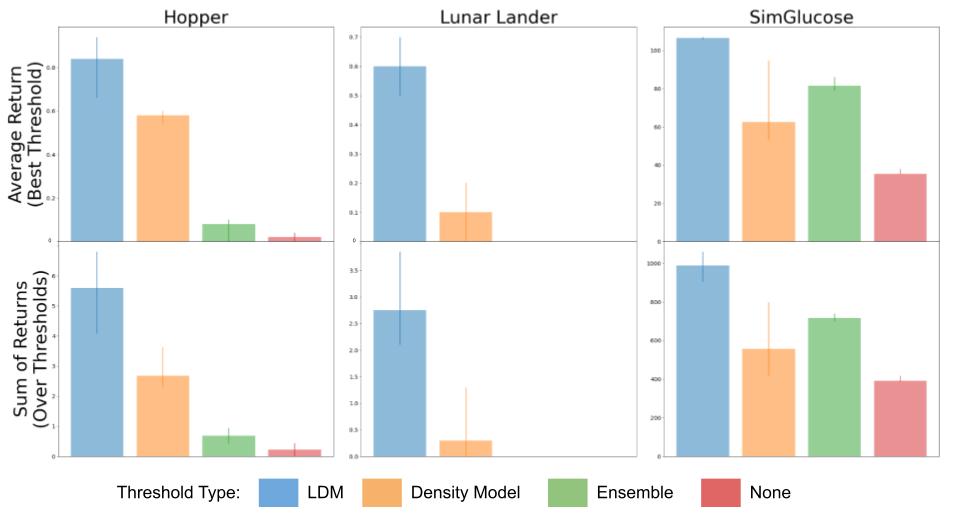
Analysis of our methodology (LDM) in comparison with constraining a learning-based controller with a density mannequin, the variance over an ensemble of fashions, and no constraint in any respect on a number of domains together with hopper, lunar lander, and glucose management.
At present, one of many greatest challenges in deploying learning-based controllers on actual world programs is their potential brittleness to out-of-distribution inputs, and lack of ensures on efficiency. Conveniently, there exists a big physique of labor in management concept targeted on making ensures about how programs evolve. Nonetheless, these works normally concentrate on making ensures with respect to bodily security necessities, and assume entry to an correct dynamics mannequin of the system in addition to bodily security constraints. The central thought behind our work is to as a substitute view the coaching information distribution as a security constraint. This permits us to make use of those concepts in controls in our design of learning-based management algorithms, thereby inheriting each the scalability of machine studying and the rigorous ensures of management concept.
This publish relies on the paper “Lyapunov Density Fashions: Constraining Distribution Shift in Studying-Based mostly Management”, offered at ICML 2022. You
discover extra particulars in our paper and on our web site. We thank Sergey Levine, Claire Tomlin, Dibya Ghosh, Jason Choi, Colin Li, and Homer Walke for his or her worthwhile suggestions on this weblog publish.

&description=Preserving+Studying-Based+mostly+Management+Secure+by+Regulating+Distributional+Shift+%E2%80%93+The+Berkeley+Synthetic+Intelligence+Analysis+Weblog){kind=link}