
A key aspect in orchestrating multi-stage information and AI processes and pipelines is management circulate administration. That is why we proceed to put money into Databricks Workflows‘ management circulate capabilities which permit our prospects to achieve higher management over complicated workflows and implement superior orchestration situations. A couple of months in the past we launched the power to outline modular orchestration in workflows which permits our prospects to interrupt down complicated DAGs for higher workflow administration, reusability, and chaining pipelines throughout groups. At the moment we’re excited to announce the following innovation in Lakehouse orchestration – the power to implement conditional execution of duties and to outline job parameters.
Conditional execution of duties
Conditional execution might be divided into two capabilities, the “If/else situation activity kind” and “Run if dependencies” which collectively allow customers to create branching logic of their workflows, create extra subtle dependencies between duties in a pipeline, and subsequently introduce extra flexibility into their workflows.
New conditional activity kind
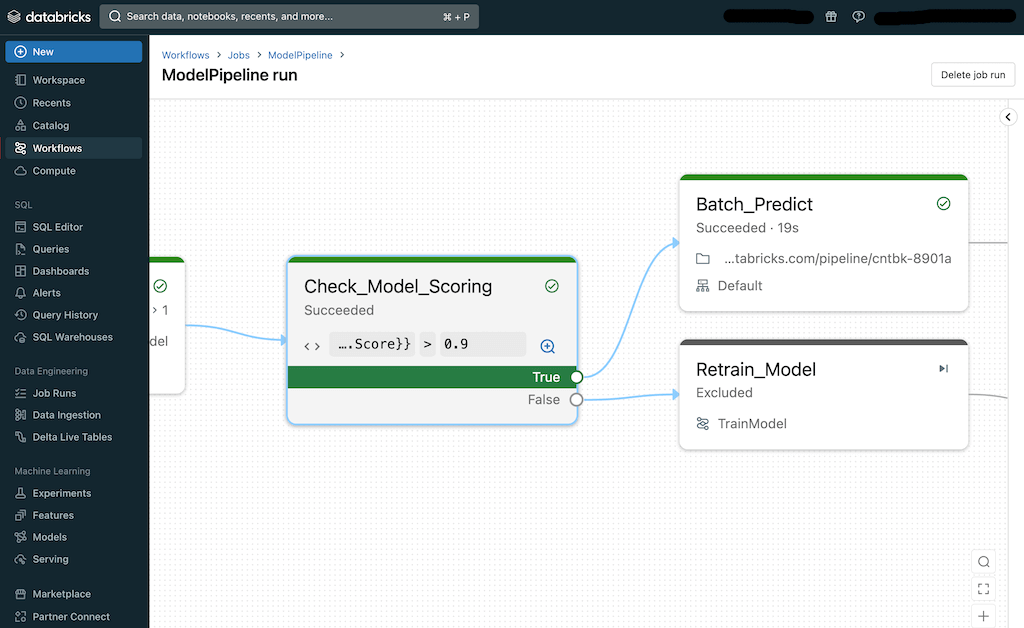
This functionality consists of the addition of a brand new activity kind named If/else situation. This activity kind permits customers to create a branching situation in a management circulate so a sure department is executed if the situation is true and one other department is executed if the situation is fake. Customers can outline quite a lot of circumstances and use dynamic values which might be set at runtime. Within the following instance, the scoring of a machine mannequin is checked earlier than continuing to prediction:
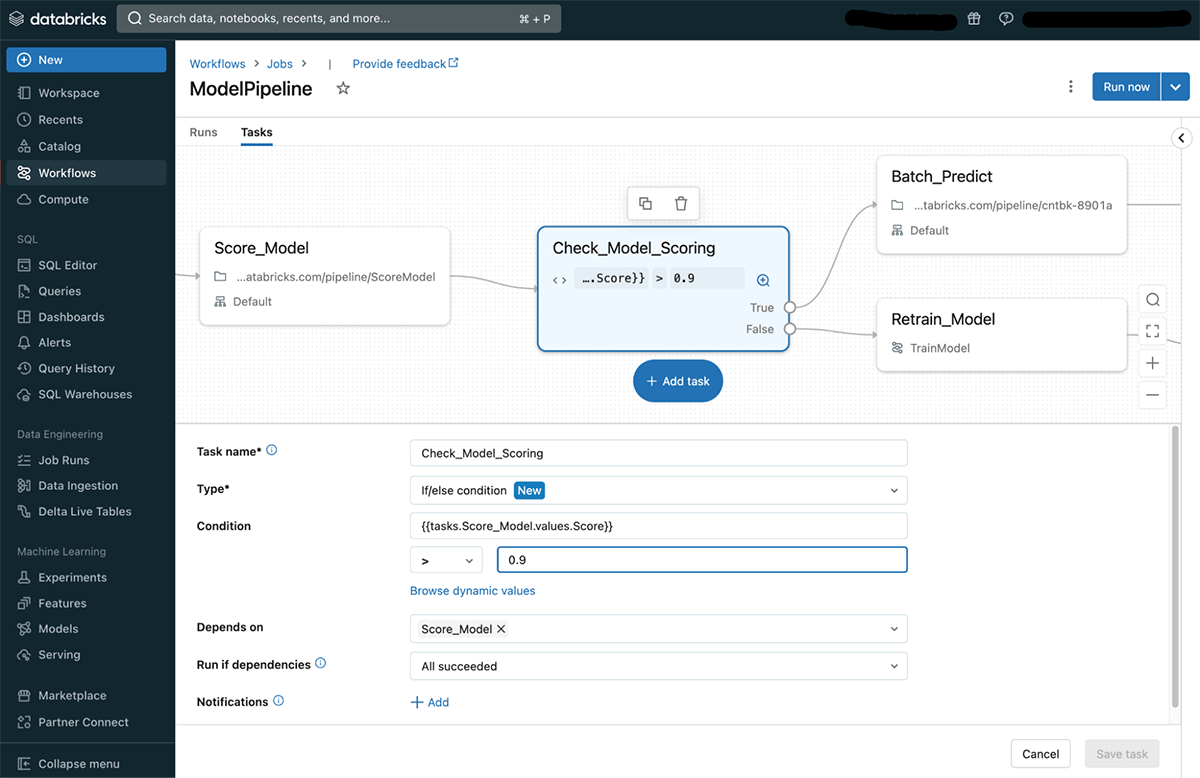
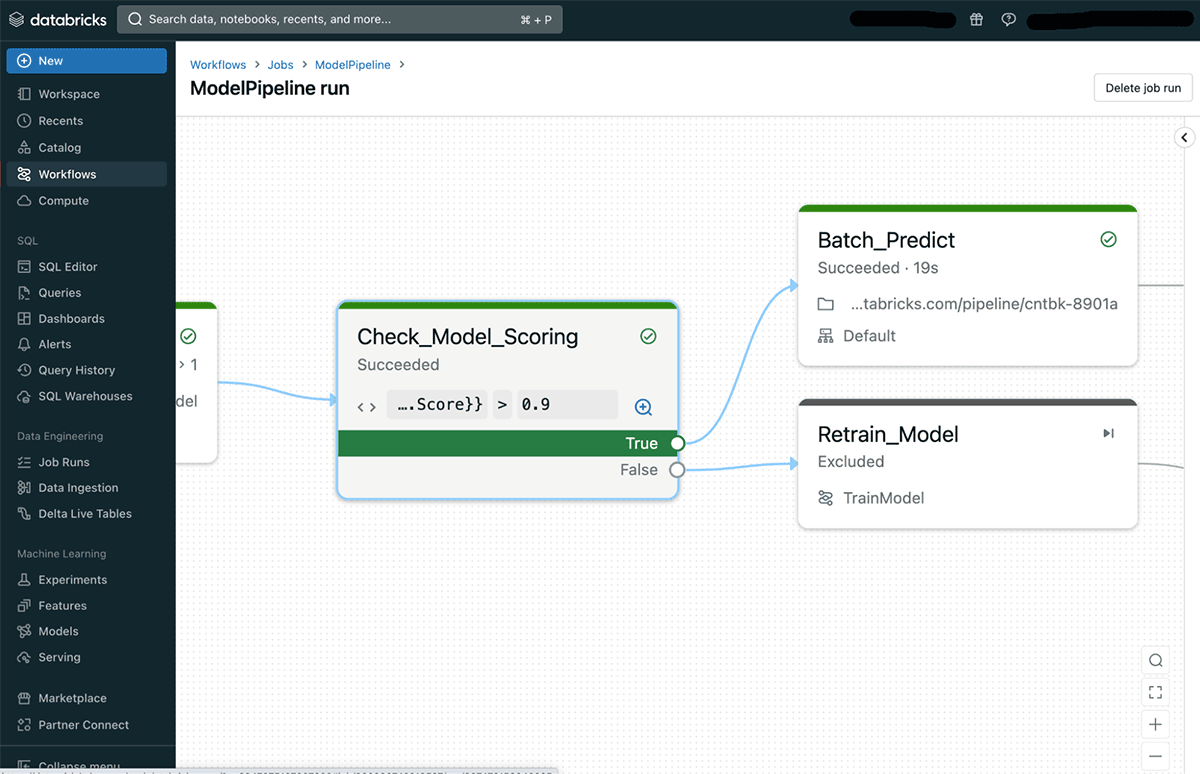
When reviewing a selected activity run, customers can simply see what was the situation outcome and which department was executed within the run.
If/else circumstances can be utilized in quite a lot of methods to allow extra subtle use circumstances. Some examples embrace:
- Run extra duties on weekends in a pipeline that’s scheduled for day by day runs.
- Exclude duties if no new information was processed in an earlier step of a pipeline.
Run if dependencies
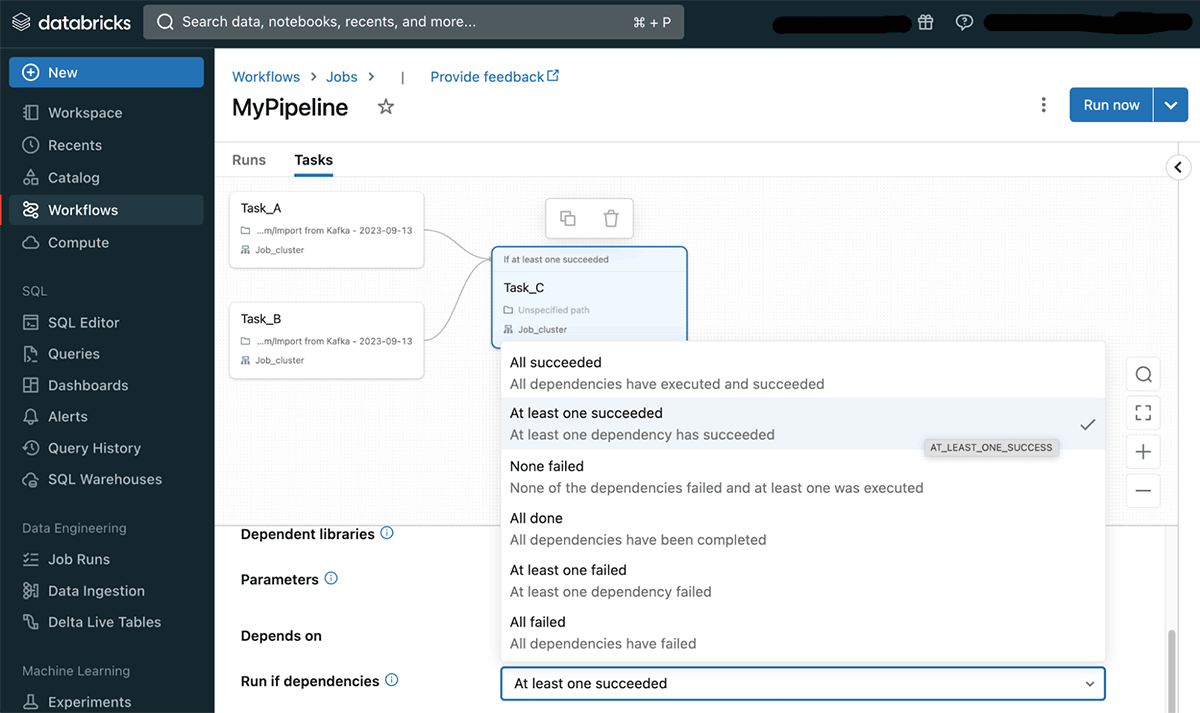
Run if dependencies are a brand new task-level configuration that gives customers with extra flexibility in defining activity dependency. When a activity has a number of dependencies over a number of duties, customers can now outline what are the circumstances that may decide the execution of the dependent activity. These circumstances are known as “Run if dependencies” and might outline {that a} activity will run if all dependencies succeded, no less than one succeeded, all completed no matter standing and many others. (see the documentation for a whole listing and extra particulars on every possibility).
Within the Databricks Workflows UI, customers can select a dependency kind within the task-level area Run if dependencies as proven beneath.
Run if dependencies are helpful in implementing a number of use circumstances. For instance, think about you might be implementing a pipeline that ingests world gross sales information by processing the information for every nation in a separate activity with country-specific enterprise logic after which aggregates all of the totally different nation datasets right into a single desk. On this case, if a single nation processing activity fails, you would possibly nonetheless need to go forward with aggregation so an output desk is created even when it solely incorporates partial information so it’s nonetheless usable for downstream customers till the problem is addressed. Databricks Workflows gives the power to do a restore run which is able to enable getting all the information as meant after fixing the problem that prompted one of many nations to fail. If a restore run is initiated on this state of affairs, solely the failed nation activity and the aggregation activity will likely be rerun.
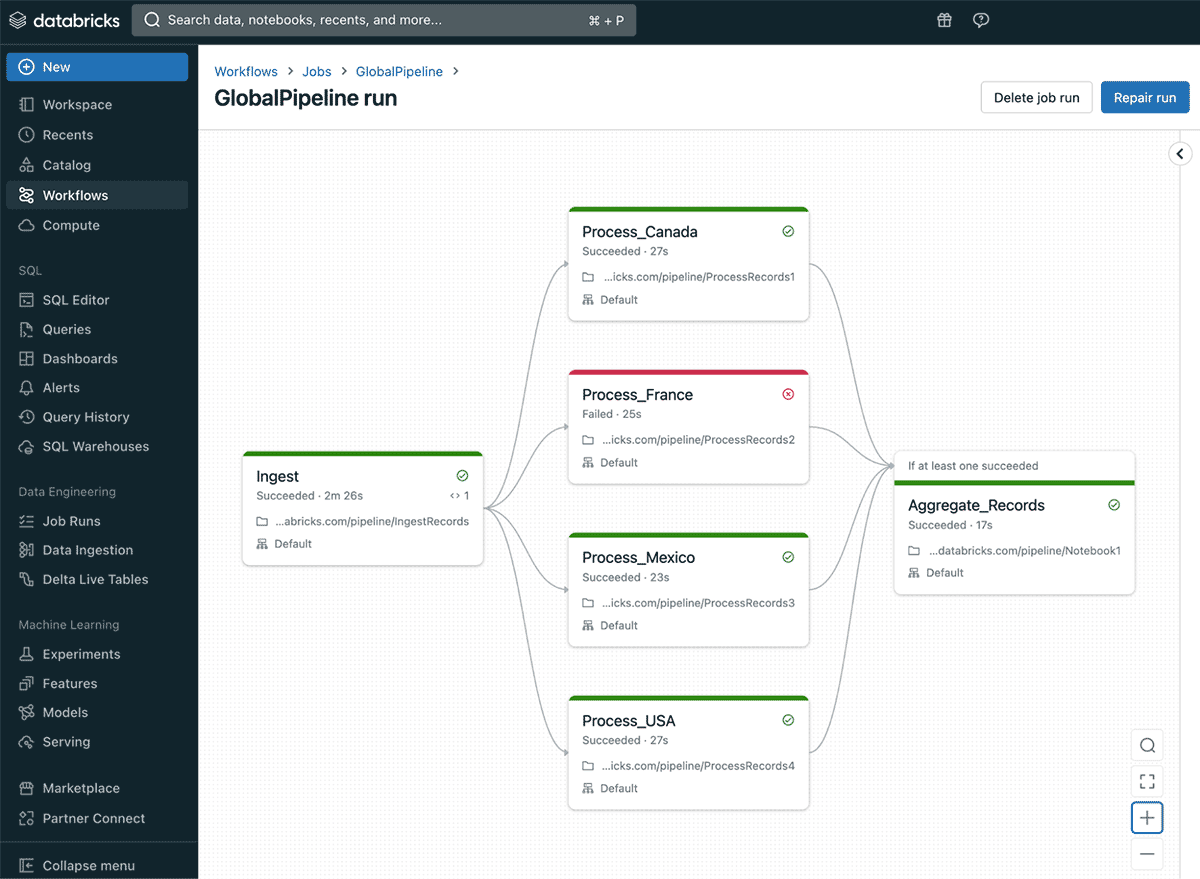
Each the “If/else situation” activity varieties and “Run if dependencies” at the moment are usually accessible for all customers. To be taught extra about these options see this documentation.
Job parameters
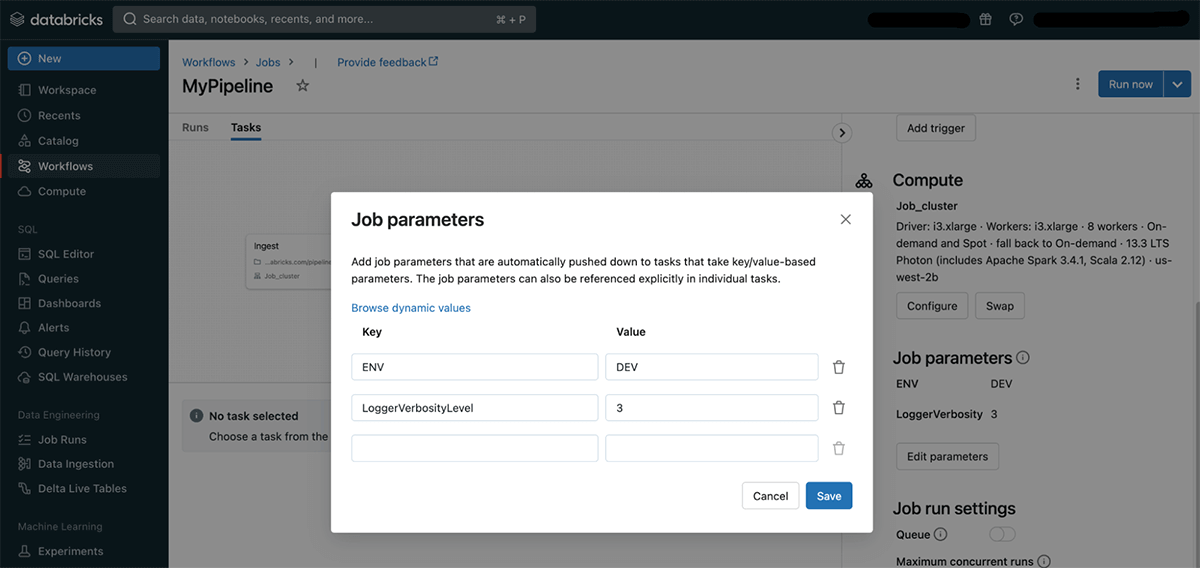
One other approach we’re including extra flexibility and management for workflows is thru the introduction of job parameters. These are key/worth pairs which might be accessible to all duties in a job at runtime. Job parameters present a simple approach so as to add granular configurations to a pipeline which is beneficial for reusing jobs for various use circumstances, a special set of inputs or working the identical job in several environments (e.g. improvement and staging environments).
Job parameters might be outlined by the job settings button Edit parameters. You’ll be able to outline a number of parameters for a single job and leverage dynamic values which might be offered by the system. You’ll be able to be taught extra about job parameters in this documentation.
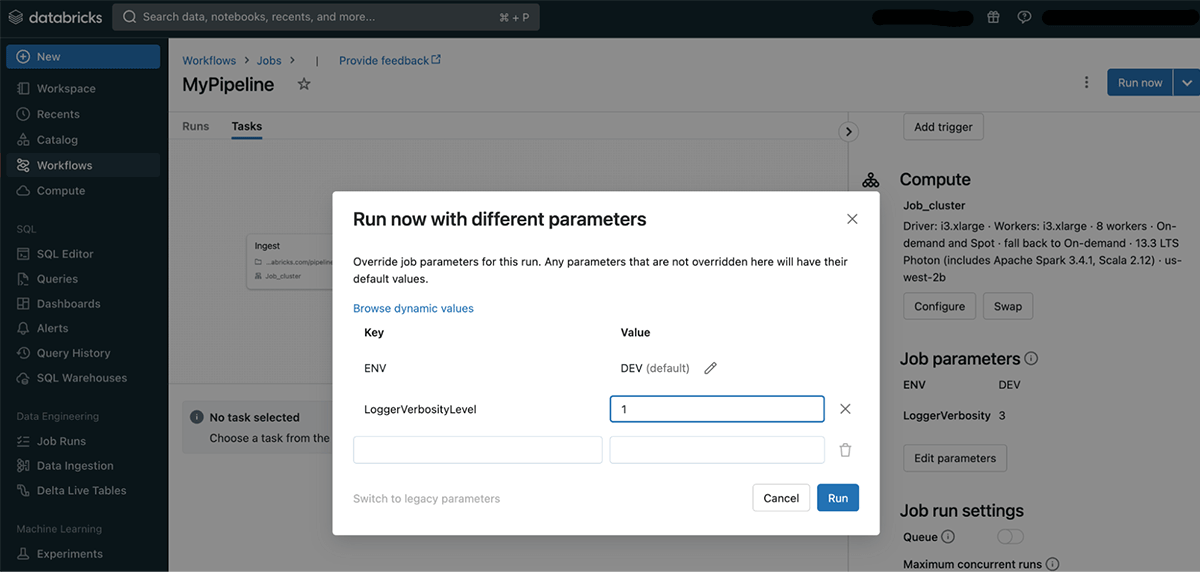
When instantiating a job run manually, you may present totally different parameters by selecting “Run now with totally different parameters” Within the “Run now” dropdown. This may be helpful for fixing a problem, working the identical workflow over a special desk or processing a selected entity.
Job parameters can be utilized as enter for an “If/else situation” activity to manage the circulate of a job. This permits customers to writer workflows with a number of branches that solely execute in particular runs in line with user-provided values. This fashion a consumer seeking to run a pipeline in a selected state of affairs can simply management the circulate of that pipeline, presumably skipping duties or enabling particular processing steps.
Get began
We’re very excited to see how you employ these new capabilities so as to add extra management to your workflows and deal with new use circumstances!

{kind=link}