

Think about you had a giant e book, and also you had been searching for the part that talks about dinosaurs. Would you learn via each web page or use the index? The index will prevent a number of time and power. Now think about that it’s a giant e book with a number of phrases in actually tiny print, and you might want to discover all of the sections that speak about animals. Utilizing the index will prevent a LOT of time and power. Extending this analogy to the world of knowledge analytics: “time” is question latency and “power” is compute value.
What has this bought to do with Snowflake? I’m personally an enormous fan of Snowflake – it’s massively scalable, it’s simple to make use of and for those who’re making the suitable space-time tradeoff it’s very inexpensive. Nonetheless for those who make the incorrect space-time tradeoff, you’ll end up throwing increasingly compute at it whereas your staff continues to complain about latency. However when you perceive the way it actually works, you possibly can cut back your Snowflake compute value and get higher question efficiency for sure use instances. I focus on Snowflake right here, however you possibly can generalize this to most warehouses.
Understanding the space-time tradeoff in information analytics
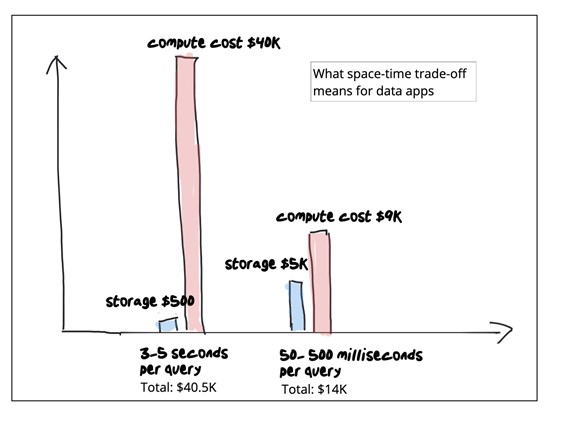
In laptop science, a space-time tradeoff is a means of fixing an issue or calculation in much less time by utilizing extra cupboard space, or by fixing an issue in little or no area by spending a very long time.
How Snowflake handles space-time tradeoff
When information is loaded into Snowflake, it reorganizes that information into its compressed, columnar format and shops it in cloud storage – this implies it’s extremely optimized for area which straight interprets to minimizing your storage footprint. The column design retains information nearer collectively, however requires computationally intensive scans to fulfill the question. That is an appropriate trade-off for a system closely optimized for storage. It’s budget-friendly for analysts operating occasional queries, however compute turns into prohibitively costly as question quantity will increase as a consequence of programmatic entry by excessive concurrency purposes.
How Rockset handles space-time tradeoff
However, Rockset is constructed for real-time analytics. It’s a real-time indexing database designed for millisecond-latency search, aggregations and joins so it indexes each area in a Converged Index™ which mixes a row index, column index and search index – this implies it’s extremely optimized for time which straight interprets to doing much less work and lowering compute value. This interprets to a much bigger storage footprint in trade for quicker queries and lesser compute. Rockset will not be the most effective car parking zone for those who’re doing occasional queries on a PB-scale dataset. However it’s best fitted to serving excessive concurrency purposes within the sub-100TB vary as a result of it makes a wholly completely different space-time tradeoff, leading to quicker efficiency at considerably decrease compute prices.

Attaining decrease question latency at decrease compute value
Snowflake makes use of columnar codecs and cloud storage to optimize for storage value. Nonetheless for every question it must scan your information. To speed up efficiency, question execution is break up amongst a number of processors that scan massive parts of your dataset in parallel. To execute queries quicker, you possibly can exploit locality utilizing micropartitioning and clustering. Use parallelism so as to add extra compute till in some unspecified time in the future you hit the higher sure for efficiency. When every question is computationally intensive, and also you begin operating many queries per second, the full compute value monthly explodes on you.
In stark distinction, Rockset indexes all fields, together with nested fields, in a Converged Index™ which mixes an inverted index, a columnar index and a row index. Given that every area is listed, you possibly can count on area amplification which is optimized utilizing superior storage structure and compaction methods. And information is served from scorching storage ie NVMe SSD so your storage value is larger. It is a good trade-off, as a result of purposes are much more compute-intensive. As of as we speak, Rockset doesn’t scan any quicker than Snowflake. It merely tries actually laborious to keep away from full scans. Our distributed SQL question engine makes use of a number of indexes in parallel, exploiting selective question patterns and accelerating aggregations over massive numbers of information, to realize millisecond latencies at considerably decrease compute prices. The needle-in-a-haystack kind queries go straight to the inverted index and fully keep away from scans. With every WHERE clause in your question, Rockset is ready to use the inverted index to execute quicker and use lesser compute (which is the precise reverse of a warehouse).
One instance of the kind of optimizations required to realize sub-second latencies: question parsing, optimizing, planning, scheduling takes about 1.2 ms on Rockset — in most warehouses the question startup value runs in 100s of milliseconds.
Attaining decrease information latency at decrease compute value
A cloud information warehouse is extremely optimized for batch inserts. Updates to an present file sometimes end in a copy-on-write on massive swaths of knowledge. New writes are amassed and when the batch is full, that batch have to be compressed and printed earlier than it’s queryable.
Steady Information Ingestion in Minutes vs. Milliseconds
Snowpipe is Snowflake’s steady information ingestion service. Snowpipe masses information inside minutes after recordsdata are added to a stage and submitted for ingestion. Briefly, Snowpipe gives a “pipeline” for loading recent information in micro-batches, however it sometimes takes many minutes and incurs very excessive compute value. For instance at 4K writes per second, this method ends in lots of of {dollars} of compute per hour.
In distinction, Rockset is a totally mutable index which makes use of RocksDB LSM bushes and a lockless protocol to make writes seen to present queries as quickly as they occur. Distant compaction accelerates the indexing of knowledge even when coping with bursty writes. The LSM index compresses information whereas permitting for inserts, updates and deletes of particular person information in order that new information is queryable inside a second of it being generated. This mutability implies that it’s simple to remain in sync with OLTP databases or information streams. It means new information is queryable inside a second of it being generated. This method reduces each information latency and compute value for real-time updates. For instance, at 4K writes per second, new information is queryable in 350 milliseconds, and makes use of roughly 1/tenth of the compute in comparison with Snowpipe.
Associates don’t let pals construct apps on warehouses
Embedded content material: https://youtu.be/-vaE0uB6eqc
Cloud information warehouses like Snowflake are purpose-built for enormous scale batch analytics ie massive scale aggregations and joins on PBs of historic information. Rockset is constructed for serving purposes with milisecond-latency search, aggregations and joins. Snowflake is optimized for storage effectivity whereas Rockset is optimized for compute effectivity. One is nice for batch analytics. The opposite is nice for real-time analytics. Information apps have selective queries. They’ve low latency, excessive concurrency necessities. They’re at all times on. In case your warehouse compute value is exploding, ask your self for those who’re making the suitable space-time tradeoff in your specific use case.


{kind=link}