
We lately introduced our AI-generated documentation characteristic, which makes use of giant language fashions (LLMs) to robotically generate documentation for tables and columns in Unity Catalog. We’ve got been humbled by the reception of this characteristic amongst our clients. At this time, greater than 80% of the desk metadata updates on Databricks are AI-assisted.
On this weblog publish, we share our expertise growing this characteristic – from prototyping as a hackathon undertaking utilizing off-the-shelf SaaS-based LLMs to making a bespoke LLM that’s higher, sooner, and cheaper. The brand new mannequin took 2 engineers, 1 month and fewer than $1,000 in compute value to develop. We hope you’ll discover the learnings helpful, as we imagine they apply to a large class of GenAI use instances. Extra importantly, it has allowed us to reap the benefits of speedy advances being made in open-source LLMs.
What’s AI-generated documentation?
On the middle of every knowledge platform lies a (probably monumental) assortment of datasets (typically within the type of tables). In nearly each group we have now labored with, the overwhelming majority of tables usually are not documented. The absence of documentation gives a lot of challenges, together with making it tough for people to find the information wanted for answering a enterprise query, or extra lately, for AI brokers to robotically discover datasets to make use of in response to questions (a key functionality in our platform that we’re calling Knowledge Intelligence).
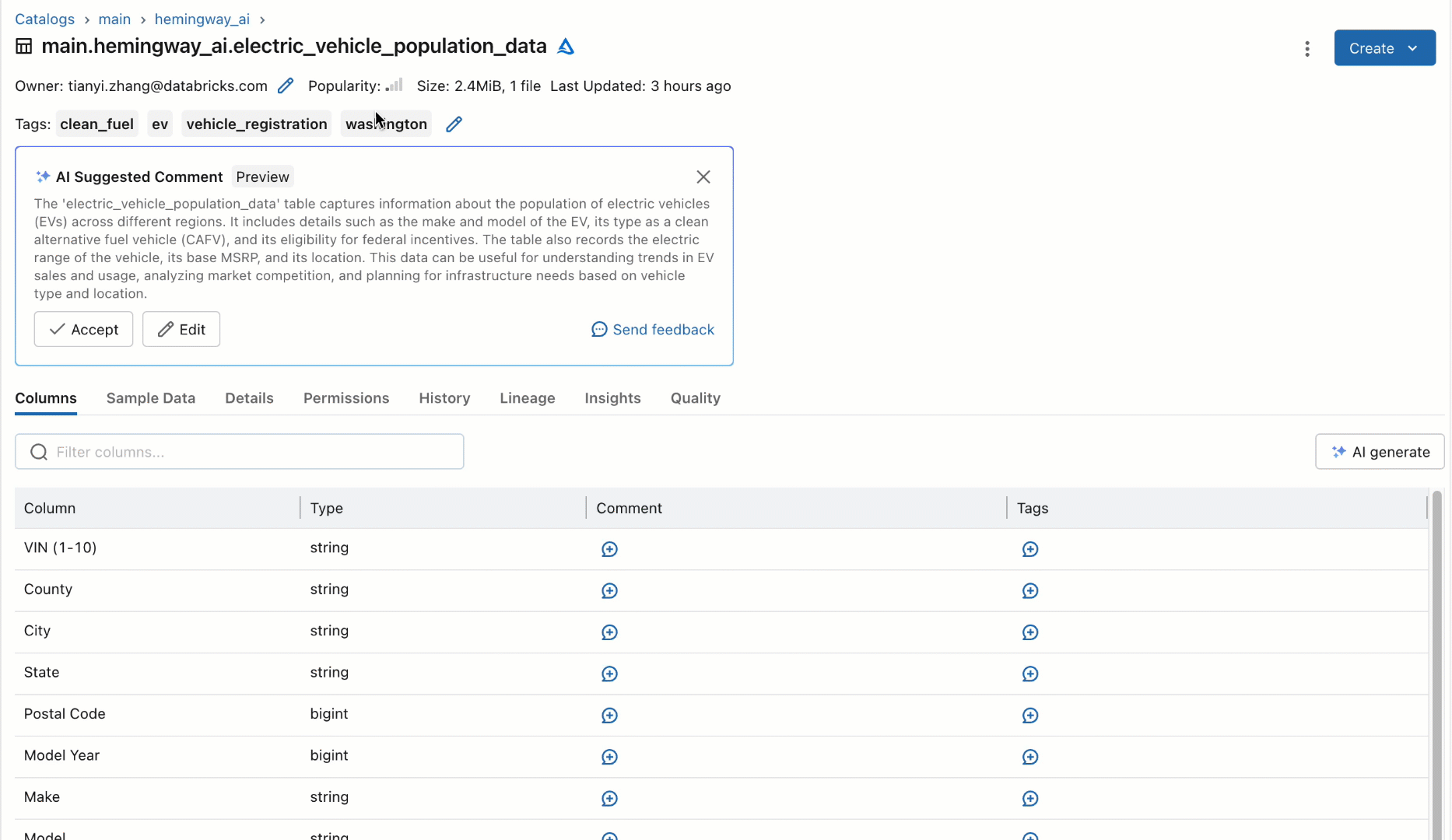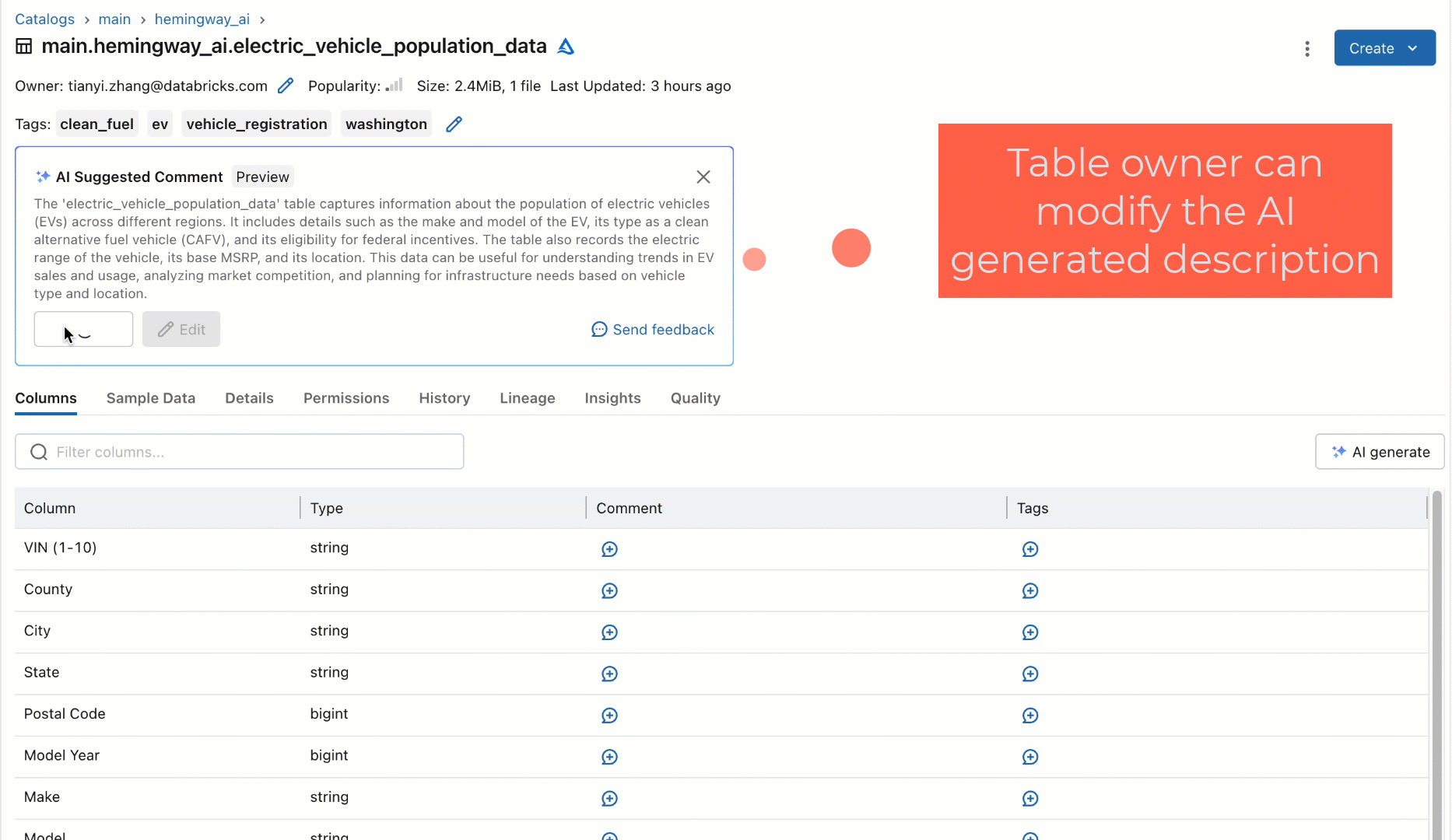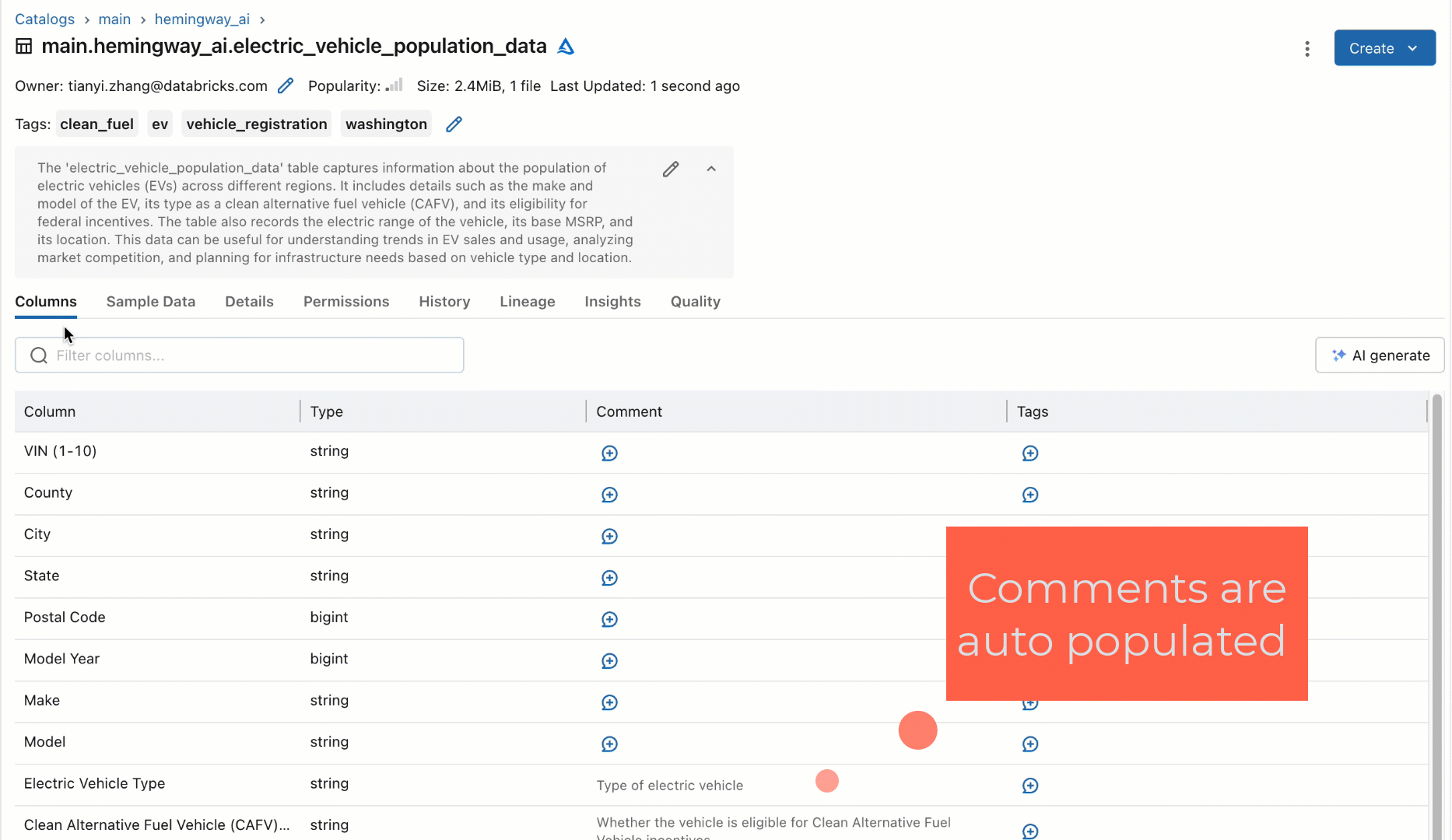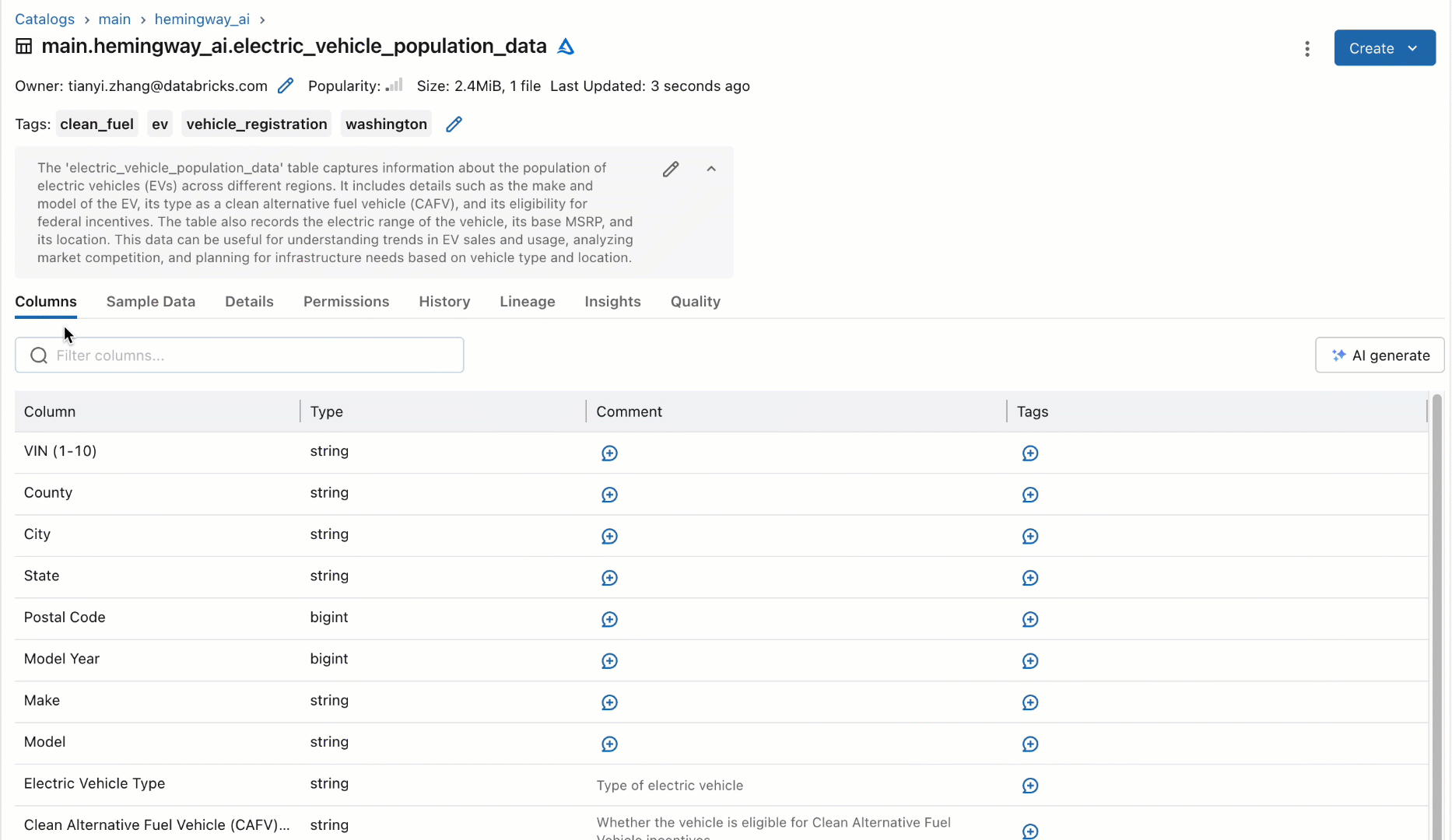
Fairly than counting on people to doc these datasets, we prototyped as a part of our quarterly hackathon a brand new workflow utilizing an off-the-shelf SaaS-based LLM to robotically generate documentation for tables and their columns based mostly on their schema. This new workflow would robotically recommend descriptions for the tables and columns and permit customers to both individually settle for, bulk settle for, or modify the options for greater constancy, as proven under. Once we confirmed this prototype to some customers, their rapid query was universally, “When can I’ve it?!”
Challenges with LLMs
As we moved in direction of launching this characteristic to all our clients, we bumped into three challenges with the mannequin:
- High quality: The last word success of this characteristic depends upon the standard of the generated documentation. Though we may measure the standard (by way of how typically they’re accepted), we had restricted knobs at our disposal to enhance it, other than primary prompting. Through the non-public preview interval, we additionally generally observed the standard of the options degrading, with none change to our codebase. Our hypothesis is that the SaaS LLM controller rolled out updates to the mannequin that generally affected efficiency on particular duties.
- Efficiency (throughput): We had restricted API quota provisioned with the SaaS LLM supplier. We work with tens of 1000’s of organizations, and it isn’t unusual {that a} single group would have hundreds of thousands of tables. It will take too lengthy to generate documentation for all of the tables based mostly on the throughput quota.
- Value: Associated to the above, it was not cost-effective until we began charging clients for utilizing this particular characteristic.
We’ve got heard comparable considerations from quite a lot of clients as they attempt to transfer their LLM-based purposes from a proof-of-concept to manufacturing and noticed this as a superb alternative for us to discover options for a company like ours.
We experimented with completely different variations of the SaaS LLMs, however all of them had the identical challenges. This isn’t stunning in hindsight. The SaaS LLMs are an engineering marvel, however they’re very common fashions that want to handle all of the use instances from desk technology to conversing in regards to the that means of life. The generality means it must have a particularly giant variety of parameters, which limits how briskly and the way low cost it will probably return solutions. Because it continues to evolve to optimize for various use instances, it may additionally regress the narrower use case we have now.
Constructing a bespoke mannequin
To handle the aforementioned challenges, we began constructing a bespoke mannequin. It took a crew of two engineers one month to construct a personalized, smaller LLM that was higher, sooner, and cheaper:
- High quality: Primarily based on our analysis (see under), the mannequin is considerably higher than the cheaper model of the SaaS mannequin, and roughly equal to the costlier model.
- Efficiency (throughput): As a result of the bespoke mannequin is loads smaller, it will probably slot in A10 GPUs, and we will enhance the inference throughput with horizontal scaling. The smaller GPUs are additionally extra out there, which permits us to generate the descriptions for all tables sooner.
- Value: Every fine-tuning run of the mannequin solely prices just a few {dollars}, and in mixture, it value lower than $1000 to develop as a result of we did a variety of experiments. It additionally resulted in a ten fold discount in inference value.
Step one was to deal with this as an utilized machine studying downside. “Utilized machine studying” sounds daunting and complex, however all it meant was that we wanted to:
- Discover coaching datasets so we will bootstrap an preliminary mannequin
- Determine an analysis mechanism so we will measure the standard, earlier than rolling it out to manufacturing
- Practice and choose fashions
- Acquire real-world utilization metrics, so we will monitor how properly a monitor does in manufacturing
- Iterate and roll out new fashions to constantly enhance the three dimensions: high quality, efficiency, value
Coaching knowledge
We created the preliminary coaching dataset for this fine-tuning activity, utilizing two completely different sources of information:
- North American Trade Classification System (NAICS) codes. It is a public dataset utilized by Federal statistical companies in classifying enterprise institutions for the aim of gathering, analyzing, and publishing statistical knowledge associated to the U.S. enterprise financial system.
- Databricks’ inside use case taxonomy curation datasets. It is a sequence of inside datasets created by our resolution architects to indicate clients greatest apply architectures.
Then we synthesized CREATE TABLE statements utilizing the above use instances to yield a various set of tables and generated pattern responses together with desk descriptions and column feedback utilizing one other LLM. In whole, we generated ~3600 coaching examples.
Notably, we didn’t use any buyer knowledge for coaching this highly effective characteristic that each one of our clients can profit from.
Bootstrapping mannequin analysis
After the characteristic launch, we may measure a mannequin’s high quality by means of manufacturing metrics akin to the speed of customers accepting the options. However earlier than we made it to the launch, we wanted a solution to consider the mannequin’s high quality towards that of the SaaS LLM.
To do this in an unbiased vogue, we arrange a easy double-blind analysis framework wherein we requested 4 workers to fee desk descriptions generated from the 2 fashions we needed to check utilizing a set of 62 unseen tables. Our framework then generated a sheet the place every row confirmed the enter and confirmed each outputs in a randomized order. The evaluator would vote on the higher pattern (or give a tie). The framework then processed the votes from completely different evaluators to generate a report; it additionally summarizes the diploma to which every of the evaluators agreed.
Primarily based on our experiences up to now, having an analysis dataset of tens to lots of of information factors is a enough preliminary milestone and will be generalized to different use instances as properly.
Mannequin choice and fine-tuning
We thought of the next standards for mannequin choice:
- Whether or not the license helps industrial use
- Efficiency (high quality) of the mannequin for textual content technology
- Velocity of the mannequin
Primarily based on these standards, MPT-7B and Llama2-7B had been the main candidates, as proven in our LLM information. We thought of bigger fashions akin to MPT-30B and Llama-2-13B. Ultimately we selected MPT-7B, because it has one of the best mixture of high quality and inference efficiency:
- There was no discernable distinction within the high quality between the MPT-7B and Llama-2-7B fine-tuned fashions for this activity.
- The smaller 7B fashions, after fine-tuning, had been already assembly the standard bar. It was considerably higher than the cheaper model of the SaaS mannequin, and roughly equal to the costlier model.
- We didn’t but observe a measurable good thing about utilizing bigger fashions for this activity that may justify the elevated serving prices.
- The latency for the smaller fashions was considerably higher than the bigger fashions whereas providing comparable high quality so we may ship a a lot snappier product expertise.
- The smaller mannequin may match comfortably and be served utilizing A10 GPUs, which had been extra available. Their abundance would imply greater inference throughput for the duty.
The overall time it took to finetune the mannequin on the ~3600 examples was solely round quarter-hour!
Whereas we selected MPT-7B for our mannequin, we imagine the LLM panorama is altering quickly and one of the best mannequin at the moment gained’t be one of the best mannequin tomorrow. That’s why we think about this to be an iterative and steady course of and are centered on utilizing instruments that make our analysis environment friendly and quick.
Key architectural elements of our manufacturing pipeline
We had been in a position to construct this rapidly by counting on the next key elements of the Databricks Knowledge Intelligence Platform:
- Databricks LLM finetuning. It gives a quite simple infrastructure for fine-tuning the fashions for our activity. We ready the coaching knowledge in JSON format, and with a one-line CLI command, we had been in a position to fine-tune the LLMs.
- Unity Catalog: The fashions that we use in manufacturing are registered in Unity Catalog (UC), offering the governance we have to not only for the information, but additionally the fashions. With its end-to-end lineage characteristic, UC additionally offers us traceability from the fashions again to the datasets they’re educated on.
- Delta Sharing: We used Delta Sharing to distribute the mannequin to all manufacturing areas we have now all over the world for sooner serving.
- Databricks optimized LLM serving: As soon as the fashions are registered in UC, they are often served utilizing the brand new optimized LLM serving, which gives important efficiency enchancment by way of throughput and latency enchancment in comparison with conventional serving for LLM serving.
Value
The fine-tuning compute value for the entire undertaking was lower than $1000 (every fine-tuning run value just a few {dollars}). And the ultimate result’s a greater than 10-fold discount in value. Why is the cost-saving so important? It isn’t stunning if we think about the next:
- As talked about earlier, the SaaS LLMs want to handle all of the use instances, together with performing as a common chatbot. The generality requires a particularly giant variety of parameters, which incurs important compute prices in inference.
- Once we fine-tune for a extra particular activity, we will use a a lot smaller immediate. Bigger, general-purpose fashions require longer prompts that embody detailed directions on what the enter is and what kind the output ought to take. Wonderful-tuned fashions can bake directions and anticipated construction into the mannequin itself. We discovered we had been in a position to scale back the variety of enter tokens with no impression on efficiency by greater than half.
- Inference prices scale with the variety of enter and output tokens, and prices scale linearly for SaaS companies which might be charged per token. With Databricks’ LLM Serving providing, we provide provisioned throughput charged per hour, which gives constant latencies, uptime SLAs, and autoscaling. As a result of smaller LLMs can slot in smaller GPUs which might be less expensive and extra out there and since we provide a extremely optimized runtime, we will aggressively drive down prices. Additionally, smaller LLMs scale up and down sooner, that means we will rapidly scale as much as meet peaks of demand and aggressively scale down when utilization is lighter, creating substantial value effectivity in manufacturing.
Conclusion
Having well-documented knowledge is crucial to all knowledge customers, and rising extra necessary day-by-day to energy AI-based knowledge platforms (what we’re calling Knowledge Intelligence). We began with SaaS LLMs for prototyping this new GenAI characteristic however bumped into challenges with high quality, efficiency, and price. We constructed a bespoke mannequin to do the identical activity at higher high quality, and but leading to greater throughput with scale-out and 10x value discount. To recap what it took:
- 2 engineers
- 1 month
- Lower than $1000 in compute for coaching and experimentation
- MPT-7B finetuned on 3600 synthetically generated examples, in underneath quarter-hour
- 4 human evaluators, with 62 preliminary analysis examples
This expertise demonstrates how simple it’s to develop and deploy bespoke LLMs for particular duties. This mannequin is now stay on Databricks in Amazon Internet Companies and Google Cloud and is getting used to energy most knowledge annotations on the platform.

{kind=link}