

Amazon Athena is a serverless, interactive analytics service constructed on open supply frameworks, supporting open desk file codecs. Athena offers a simplified, versatile option to analyze petabytes of knowledge the place it lives. You may analyze knowledge or construct purposes from an Amazon Easy Storage Service (Amazon S3) knowledge lake and 30 knowledge sources, together with on-premises knowledge sources or different cloud programs utilizing SQL or Python. Athena is constructed on open supply Trino and Presto engines and Apache Spark frameworks, with no provisioning or configuration effort required.
Beginning in the present day, the Athena SQL engine makes use of a cost-based optimizer (CBO), a brand new function that makes use of desk and column statistics saved within the AWS Glue Information Catalog as a part of the desk’s metadata. Through the use of these statistics, CBO improves question run plans and boosts the efficiency of queries run in Athena. Among the particular optimizations CBO can make use of embrace be a part of reordering and pushing aggregations down based mostly on the statistics out there for every desk and column.
TPC-DS benchmarks These benchmarks show the ability of the cost-based optimizer—queries run as much as 2x occasions quicker with CBO enabled in comparison with operating the identical TPC-DS queries with out CBO.
Efficiency and value comparability on TPC-DS benchmarks
We used the industry-standard TPC-DS 3 TB to symbolize totally different buyer use circumstances. These are consultant of workloads with 10 occasions the acknowledged benchmark measurement. This implies a 3 TB benchmark dataset precisely represents buyer workloads on 30–50 TB datasets.
In our testing, the dataset was saved in Amazon S3 in non-compressed Parquet format and the AWS Glue Information Catalog was used to retailer metadata for databases and tables. Reality tables have been partitioned on the date column used for be a part of operations, and every truth desk consisted of two,000 partitions. To assist illustrate the efficiency of CBO, we evaluate the habits of assorted queries and spotlight the efficiency variations between operating with CBO enabled vs. disabled.
The next graph illustrates the runtime of queries on the engine with and with out CBO.

The next graph presents the highest 10 queries from the TPC-DS benchmark with the best efficiency enchancment.

Let’s focus on a few of the cost-based optimization methods that contributed to improved question efficiency.
Price-based be a part of reordering
Be part of reordering, an optimization method utilized by cost-based SQL optimizers, analyzes totally different be a part of sequences to pick out the order that minimizes question runtime by decreasing intermediate knowledge processed at every step, reducing reminiscence and CPU necessities.
Let’s discuss question 82 of the TPC-DS 3TB dataset. The question performs inside joins on 4 tables: merchandise, stock, date_dim, and store_sales. The store_sales desk has 8.6 billion rows and is partitioned by date. The stock desk has 1 billion rows and can be partitioned by date. The merchandise desk incorporates 360,000 rows, and the date_dim desk holds 73,000 rows.
Question 82
With out CBO
With out utilizing CBO, the engine will decide the be a part of order based mostly on the sequence of tables outlined within the enter question with inside heuristics. The FROM clause of the enter question is "from merchandise, stock, date_dim, store_sales" (all inside joins). After passing by means of inside heuristics, Athena selected the be a part of order as ((merchandise ⋈ (stock ⋈ date_dim)) ⋈ store_sales). Regardless of store_sales being the biggest truth desk, it’s outlined final within the FROM clause and due to this fact will get joined final. This plan fails to scale back the intermediate be a part of sizes as early as potential, leading to an elevated question runtime. The next diagram exhibits the be a part of order with out CBO and the variety of rows flowing by means of totally different levels.

With CBO
When utilizing CBO, the optimizer determines one of the best be a part of order utilizing a wide range of knowledge, together with statistics in addition to be a part of measurement estimation, be a part of construct facet, and be a part of sort. On this occasion, Athena’s chosen be a part of order is ((store_sales ⋈ merchandise) ⋈ (stock ⋈ date_dim)). The most important truth desk, store_sales, with out being shuffled, is first joined with the merchandise dimension desk. The opposite partitioned desk, stock, can be first joined in-place with the date_dim dimension desk. The be a part of with the dimension desk acts as a filter on the very fact desk, which dramatically reduces the enter knowledge measurement of the be a part of that follows. Notice that which facet a desk resides for a be a part of is important in Athena, as a result of it’s the desk on the correct that will probably be constructed into reminiscence for the be a part of operation. Due to this fact, we at all times wish to preserve the bigger desk on the left and the smaller desk on the correct. CBO selected a plan that the left facet was 8.6 billion earlier than, and now it’s 13.6 million.
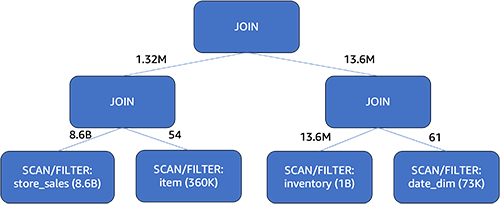
With CBO, the question runtime improved by 25% (from 15 seconds right down to 11 seconds) by selecting the optimum be a part of order.
Subsequent, let’s focus on one other CBO method.
Price-based aggregation pushdown
Aggregation pushdown is an optimization method utilized by question optimizers to enhance efficiency. It includes pushing aggregation operations like SUM, COUNT, and AVG into an earlier stage within the question plan, whereas sustaining the identical question semantics. This reduces the quantity of knowledge transferred between the levels. By minimizing knowledge processing, aggregation pushdown decreases reminiscence utilization, I/O prices, and community visitors.
Nevertheless, pushing down aggregation shouldn’t be at all times useful. It will depend on the information distribution. For instance, grouping on a column with many rows however few distinct values (like gender) earlier than joins works higher. Grouping first means aggregating a lot of information into fewer information (simply male, feminine, for instance). Grouping after becoming a member of means a lot of information must take part the be a part of earlier than being aggregated. However, grouping on a excessive cardinality column is healthier accomplished after joins. Doing it earlier than dangers pointless aggregation overhead as a result of every worth is probably going distinctive anyway and that step is not going to lead to an earlier discount within the quantity of knowledge transferred between intermediate levels.
Due to this fact, whether or not to push down aggregation ought to be a cost-based determination. Let’s take instance of the question 2 run on a 3TB TPC-DS dataset, displaying how the aggregation pushdown’s worth will depend on knowledge distribution. The web_sales desk has 2.1 billion rows and the catalog_sales desk has 4.23 billion rows. Each tables are partitioned on the date column.
Question 2
With out CBO
Athena first joins the results of the union all operation on the web_sales desk and the catalog_sales desk with one other desk. Solely then does it carry out aggregation on the joined outcomes. On this instance, the quantity of knowledge that wanted to be joined was large, leading to an extended question runtime.

With CBO
Athena makes use of one of many statistics values, the distinct worth rely, to guage the fee implications of pushing down the aggregation vs. not doing so. When a column has many rows however few distinct values, CBO is extra more likely to push aggregation down. This shrank the certified rows from web_sales and catalog_sales tables to 2,590 and three,590 rows, respectively. These aggregated information have been then unioned and used to affix with the tables. Evaluating to the plan with out CBO, the information collaborating within the be a part of from the 2 giant tables dropped from 6.33 billion rows (2.1 billion + 4.23 billion) to only 6,180 rows (2,590 + 3,590). This considerably decreased question runtime.
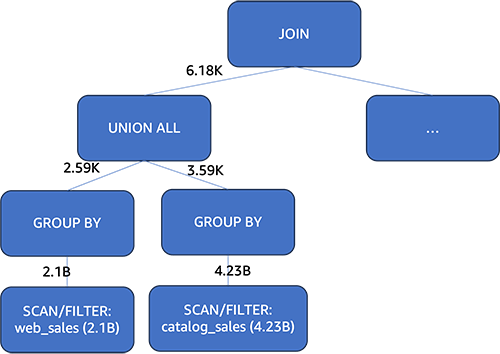
With CBO, the question runtime improved by 50% (from 37 seconds right down to 18 seconds). In abstract, CBO helped Athena select an optimum aggregation pushdown plan, reducing the question time in half in comparison with not utilizing cost-based optimization.
Conclusion
On this put up, we mentioned how Athena makes use of a cost-based optimizer (CBO) in its engine v3 to make use of desk statistics for producing extra environment friendly question run plans. Testing on the TPC-DS benchmark confirmed an 11% enchancment in total question efficiency when utilizing CBO in comparison with with out it.
Two key optimization employed by CBO are be a part of reordering and combination pushdown. Be part of reordering reduces intermediate knowledge by intelligently choosing the order to affix tables based mostly on statistics. Combination pushdown decreases intermediate knowledge by pushing aggregations earlier within the plan when useful.
In abstract, Athena’s new cost-based optimizer considerably hurries up queries by selecting superior run plans. CBO optimizes based mostly on desk statistics saved within the AWS Glue Information Catalog. This automated optimization improves productiveness for Athena customers by means of extra responsive question efficiency. To reap the benefits of optimization methods of CBO, consult with working with column statistics to generate statistics on the tables and columns within the AWS Glue Information Catalog.
Concerning the Authors
 Darshit Thakkar is a Technical Product Supervisor with AWS and works with the Amazon Athena staff based mostly out of Boston, Massachusetts.
Darshit Thakkar is a Technical Product Supervisor with AWS and works with the Amazon Athena staff based mostly out of Boston, Massachusetts.
 Wei Zheng is a Sr. Software program Improvement Engineer with Amazon Athena. He joined AWS in 2021 and has been engaged on a number of efficiency enhancements on Athena.
Wei Zheng is a Sr. Software program Improvement Engineer with Amazon Athena. He joined AWS in 2021 and has been engaged on a number of efficiency enhancements on Athena.
 Chuho Chang is a Software program Improvement Engineer with Amazon Athena. He has been engaged on question optimizers for over a decade.
Chuho Chang is a Software program Improvement Engineer with Amazon Athena. He has been engaged on question optimizers for over a decade.
 Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the massive knowledge analytics area since then, serving to clients construct scalable and strong options utilizing AWS analytics providers.
Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the massive knowledge analytics area since then, serving to clients construct scalable and strong options utilizing AWS analytics providers.

{kind=link}