

On this second submit of a multi-part sequence, we share finest practices for selecting the optimum Amazon Redshift cluster, information structure, changing saved procedures, appropriate features and queries broadly used for SQL conversions, and proposals for optimizing the size of information varieties for desk columns. You possibly can take a look at the first submit of this sequence for steering on planning, working, and validation of a large-scale information warehouse migration from Greenplum to Amazon Redshift utilizing AWS Schema Conversion Software (AWS SCT).
Select your optimum Amazon Redshift cluster
Amazon Redshift has two forms of clusters: provisioned and serverless. For provisioned clusters, you could arrange the identical with required compute assets. Amazon Redshift Serverless can run high-performance analytics within the cloud at any scale. For extra data, discuss with Introducing Amazon Redshift Serverless – Run Analytics At Any Scale With out Having to Handle Knowledge Warehouse Infrastructure.
An Amazon Redshift cluster consists of nodes. Every cluster has a pacesetter node and a number of compute nodes. The chief node receives queries from shopper functions, parses the queries, and develops question run plans. The chief node then coordinates the parallel run of those plans with the compute nodes and aggregates the intermediate outcomes from these nodes. It then returns the outcomes to the shopper functions.
When figuring out your sort of cluster, contemplate the next:
- Estimate the scale of the enter information compressed, vCPU, and efficiency. As of this writing, we advocate the Amazon Redshift RA3 occasion with managed storage, which scales compute and storage independently for quick question efficiency.
- Amazon Redshift gives an automatic “Assist me select” cluster primarily based on the scale of your information.
- A essential benefit of a cloud Amazon Redshift information warehouse is that you just’re now not caught with {hardware} and commodities like outdated guard information warehouses. For sooner innovation, you might have the choice to strive completely different cluster choices and select the optimized one when it comes to efficiency and value.
- On the time of growth or pilot, you’ll be able to often begin with a smaller variety of nodes. As you progress to manufacturing, you’ll be able to alter the variety of nodes primarily based in your utilization sample. When right-sizing your clusters, we advocate selecting the reserved occasion sort to chop down the fee even additional. The general public-facing utility Easy Replay may also help you identify efficiency in opposition to completely different cluster varieties and sizes by replaying the client workload. For provisioned clusters, if you happen to’re planning to make use of the beneficial RA3 occasion, you’ll be able to examine completely different node varieties to find out the appropriate occasion sort.
- Based mostly in your workload sample, Amazon Redshift helps resize, pause and cease, and concurrency scaling of the cluster. Amazon Redshift workload administration (WLM) allows efficient and versatile administration of reminiscence and question concurrency.
Create information extraction duties with AWS SCT
With AWS SCT extraction brokers, you’ll be able to migrate your supply tables in parallel. These extraction brokers authenticate utilizing a legitimate consumer on the information supply, permitting you to regulate the assets accessible for that consumer in the course of the extraction. AWS SCT brokers course of the information domestically and add it to Amazon Easy Storage Service (Amazon S3) via the community (through AWS Direct Join). We advocate having a constant community bandwidth between your Greenplum machine the place the AWS SCT agent is put in and your AWS Area.
In case you have tables round 20 million rows or 1 TB in dimension, you need to use the digital partitioning function on AWS SCT to extract information from these tables. This creates a number of sub-tasks and parallelizes the information extraction course of for this desk. Subsequently, we advocate creating two teams of duties for every schema that you just migrate: one for small tables and one for giant tables utilizing digital partitions.
For extra data, discuss with Creating, working, and monitoring an AWS SCT information extraction process.
Knowledge structure
To simplify and modernize your information structure, contemplate the next:
- Set up accountability and authority to implement enterprise information requirements and insurance policies.
- Formalize the information and analytics working mannequin between enterprise and enterprise items and features.
- Simplify the information expertise ecosystem via rationalization and modernization of information belongings and instruments or expertise.
- Develop organizational constructs that facilitate extra strong integration of the enterprise and supply groups, and construct data-oriented merchandise and options to handle the enterprise issues and alternatives all through the lifecycle.
- Again up the information periodically in order that if one thing is unsuitable, you might have the power to replay.
- Throughout planning, design, execution, and all through implementation and upkeep, guarantee information high quality administration is added to realize the specified end result.
- Easy is the important thing to a simple, quick, intuitive, and low-cost resolution. Easy scales significantly better than advanced. Easy makes it potential to suppose huge (Invent and Simplify is one other Amazon management precept). Simplify the legacy course of by migrating solely the required information utilized in tables and schemas. For instance, if you happen to’re performing truncate and cargo for incremental information, establish a watermark and solely course of incremental information.
- You’ll have use instances that requiring record-level inserts, updates, and deletes for privateness laws and simplified pipelines; simplified file administration and near-real-time information entry; or simplified change information seize (CDC) information pipeline growth. We advocate utilizing purposeful instruments primarily based in your use case. AWS affords the choices to make use of Apache HUDI with Amazon EMR and AWS Glue.
Migrate saved procedures
On this part, we share finest practices for saved process migration from Greenplum to Amazon Redshift. Knowledge processing pipelines with advanced enterprise logic typically use saved procedures to carry out the information transformation. We advise utilizing huge information processing like AWS Glue or Amazon EMR to modernize your extract, remodel, and cargo (ETL) jobs. For extra data, take a look at High 8 Finest Practices for Excessive-Efficiency ETL Processing Utilizing Amazon Redshift. For time-sensitive migration to cloud-native information warehouses like Amazon Redshift, redesigning and growing the complete pipeline in a cloud-native ETL device may be time-consuming. Subsequently, migrating the saved procedures from Greenplum to Amazon Redshift saved procedures might be the appropriate alternative.
For a profitable migration, make certain to observe Amazon Redshift saved process finest practices:
- Specify the schema title whereas making a saved process. This helps facilitate schema-level safety and you may implement grants or revoke entry management.
- To forestall naming conflicts, we advocate naming procedures utilizing the prefix
sp_. Amazon Redshift reserves thesp_prefix solely for saved procedures. By prefixing your process names withsp_, you make sure that your process title gained’t battle with any present or future Amazon Redshift process names. - Qualify your database objects with the schema title within the saved process.
- Observe the minimal required entry rule and revoke undesirable entry. For related implementation, make certain the saved process run permission will not be open to ALL.
- The SECURITY attribute controls a process’s privileges to entry database objects. Whenever you create a saved process, you’ll be able to set the SECURITY attribute to both DEFINER or INVOKER. Should you specify SECURITY INVOKER, the process makes use of the privileges of the consumer invoking the process. Should you specify SECURITY DEFINER, the process makes use of the privileges of the proprietor of the process. INVOKER is the default. For extra data, discuss with Safety and privileges for saved procedures.
- Managing transactions in terms of saved procedures are vital. For extra data, discuss with Managing transactions.
- TRUNCATE points a commit implicitly inside a saved process. It interferes with the transaction block by committing the present transaction and creating a brand new one. Train warning whereas utilizing TRUNCATE to make sure it by no means breaks the atomicity of the transaction. This additionally applies for COMMIT and ROLLBACK.
- Adhere to cursor constraints and perceive efficiency concerns whereas utilizing cursor. You must use set-based SQL logic and non permanent tables whereas processing giant datasets.
- Keep away from hardcoding in saved procedures. Use dynamic SQL to assemble SQL queries dynamically at runtime. Guarantee acceptable logging and error dealing with of the dynamic SQL.
- For exception dealing with, you’ll be able to write RAISE statements as a part of the saved process code. For instance, you’ll be able to elevate an exception with a customized message or insert a document right into a logging desk. For unhandled exceptions like WHEN OTHERS, use built-in features like SQLERRM or SQLSTATE to cross it on to the calling software or program. As of this writing, Amazon Redshift limits calling a saved process from the exception block.
Sequences
You need to use IDENTITY columns, system timestamps, or epoch time as an choice to make sure uniqueness. The IDENTITY column or a timestamp-based resolution might need sparse values, so if you happen to want a steady quantity sequence, you could use devoted quantity tables. You may as well use of the RANK() or ROW_NUMBER() window operate over the complete set. Alternatively, get the high-water mark from the prevailing ID column from the desk and increment the values whereas inserting information.
Character datatype size
Greenplum char and varchar information sort size is specified when it comes to character size, together with multi-byte ones. Amazon Redshift character varieties are outlined when it comes to bytes. For desk columns utilizing multi-byte character units in Greenplum, the transformed desk column in Amazon Redshift ought to allocate satisfactory storage to the precise byte dimension of the supply information.
A simple workaround is to set the Amazon Redshift character column size to 4 instances bigger than the corresponding Greenplum column size.
A finest apply is to make use of the smallest potential column dimension. Amazon Redshift doesn’t allocate cupboard space in line with the size of the attribute; it allocates storage in line with the true size of the saved string. Nevertheless, at runtime, whereas processing queries, Amazon Redshift allocates reminiscence in line with the size of the attribute. Subsequently, not setting a default dimension of 4 instances better helps from a efficiency perspective.
An environment friendly resolution is to investigate manufacturing datasets and decide the utmost byte dimension size of the Greenplum character columns. Add a 20% buffer to help future incremental development on the desk.
To reach on the precise byte dimension size of an present column, run the Greenplum information construction character utility from the AWS Samples GitHub repo.
Numeric precision and scale
The Amazon Redshift numeric information sort has a restrict to retailer as much as most precision of 38, whereas in a Greenplum database, you’ll be able to outline a numeric column with none outlined size.
Analyze your manufacturing datasets and decide numeric overflow candidates utilizing the Greenplum information construction numeric utility from the AWS Samples GitHub repo. For numeric information, you might have choices to sort out this primarily based in your use case. For numbers with a decimal half, you might have the choice to spherical the information primarily based on the information sort with none information loss in the entire quantity half. For future reference, you’ll be able to a preserve copy of the column in VARCHAR or retailer in an S3 information lake. Should you see an especially small proportion of an outlier of overflow information, clear up the supply information for high quality information migration.
SQL queries and features
Whereas changing SQL scripts or saved procedures to Amazon Redshift, if you happen to encounter unsupported features, database objects, or code blocks for which you might need to rewrite the question, create user-defined features (UDFs), or redesign. You possibly can create a customized scalar UDF utilizing both a SQL SELECT clause or a Python program. The brand new operate is saved within the database and is out there for any consumer with ample privileges to run. You run a customized scalar UDF in a lot the identical approach as you run present Amazon Redshift features to match any performance of legacy databases. The next are some examples of alternate question statements and methods to realize particular aggregations that may be required throughout a code rewrite.
AGE
The Greenplum operate AGE () returns an interval subtracting from the present date. You might accomplish the identical utilizing a subset of MONTHS_BETWEEN(), ADD_MONTH(), DATEDIFF(), and TRUNC() features primarily based in your use case.
The next instance Amazon Redshift question calculates the hole between the date 2001-04-10 and 1957-06-13 when it comes to 12 months, month, and days. You possibly can apply this to any date column in a desk.

COUNT
In case you have a use case to get distinct aggregation within the Depend() window operate, you could possibly accomplish the identical utilizing a mix of the Dense_Rank () and Max() window features.
The next instance Amazon Redshift question calculates the distinct merchandise rely for a given date of sale:
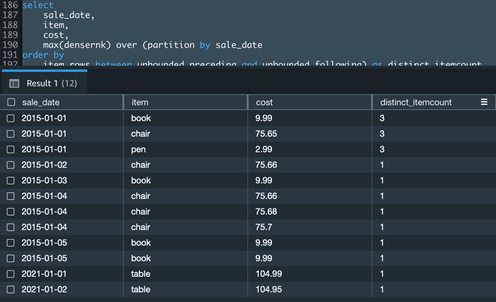
ORDER BY
Amazon Redshift combination window features with an ORDER BY clause require a compulsory body.
The next instance Amazon Redshift question creates a cumulative sum of value by sale date and orders the outcomes by merchandise throughout the partition:

STRING_AGG
In Greenplum, STRING_AGG() is an combination operate, which is used to concatenate an inventory of strings. In Amazon Redshift, use the LISTAGG() operate.
The next instance Amazon Redshift question returns a semicolon-separated checklist of e-mail addresses for every division:

ARRAY_AGG
In Greenplum, ARRAY_AGG() is an combination operate that takes a set of values as enter and returns an array. In Amazon Redshift, use a mix of the LISTAGG() and SPLIT_TO_ARRAY() features. The SPLIT_TO_ARRAY() operate returns a SUPER datatype.
The next instance Amazon Redshift question returns an array of e-mail addresses for every division:

To retrieve array parts from a SUPER expression, you need to use the SUBARRAY() operate:

UNNEST
In Greenplum, you need to use the UNNEST operate to separate an array and convert the array parts right into a set of rows. In Amazon Redshift, you need to use PartiQL syntax to iterate over SUPER arrays. For extra data, discuss with Querying semistructured information.

WHERE
You possibly can’t use a window operate within the WHERE clause of a question in Amazon Redshift. As a substitute, assemble the question utilizing the WITH clause after which refer the calculated column within the WHERE clause.
The next instance Amazon Redshift question returns the sale date, merchandise, and value from a desk for the gross sales dates the place the full sale is greater than 100:

Discuss with the next desk for added Greenplum date/time features together with the Amazon Redshift equal to speed up you code migration.
| . | Description | Greenplum | Amazon Redshift |
| 1 | The now() operate return the beginning time of the present transaction |
now () |
sysdate |
| 2 | clock_timestamp() returns the beginning timestamp of the present assertion inside a transaction block |
clock_timestamp () |
to_date(getdate(),'yyyy-mm-dd') + substring(timeofday(),12,15)::timetz |
| 3 | transaction_timestamp () returns the beginning timestamp of the present transaction |
transaction_timestamp () |
to_date(getdate(),'yyyy-mm-dd') + substring(timeofday(),12,15)::timetz |
| 4 | Interval – This operate provides x years and y months to the date_time_column and returns a timestamp sort |
date_time_column + interval ‘ x years y months’ |
add_months(date_time_column, x*12 + y) |
| 5 | Get whole variety of seconds between two-time stamp fields | date_part('day', end_ts - start_ts) * 24 * 60 * 60+ date_part('hours', end_ts - start_ts) * 60 * 60+ date_part('minutes', end_ts - start_ts) * 60+ date_part('seconds', end_ts - start_ts) |
datediff('seconds', start_ts, end_ts) |
| 6 | Get whole variety of minutes between two-time stamp fields | date_part('day', end_ts - start_ts) * 24 * 60 + date_part('hours', end_ts - start_ts) * 60 + date_part('minutes', end_ts - start_ts) |
datediff('minutes', start_ts, end_ts) |
| 7 | Extract date half literal from distinction of two-time stamp fields | date_part('hour', end_ts - start_ts) |
extract(hour from (date_time_column_2 - date_time_column_1)) |
| 8 | Operate to return the ISO day of the week | date_part('isodow', date_time_column) |
TO_CHAR(date_time_column, 'ID') |
| 9 | Operate to return ISO 12 months from date time area | extract (isoyear from date_time_column) |
TO_CHAR(date_time_column, ‘IYYY’) |
| 10 | Convert epoch seconds to equal datetime | to_timestamp(epoch seconds) |
TIMESTAMP 'epoch' + Number_of_seconds * interval '1 second' |
Amazon Redshift utility for troubleshooting or working diagnostics for the cluster
The Amazon Redshift Utilities GitHub repo incorporates a set of utilities to speed up troubleshooting or evaluation on Amazon Redshift. Such utilities encompass queries, views, and scripts. They aren’t deployed by default onto Amazon Redshift clusters. The most effective apply is to deploy the wanted views into the admin schema.
Conclusion
On this submit, we coated prescriptive steering round information varieties, features, and saved procedures to speed up the migration course of from Greenplum to Amazon Redshift. Though this submit describes modernizing and transferring to a cloud warehouse, try to be augmenting this transformation course of in the direction of a full-fledged trendy information structure. The AWS Cloud lets you be extra data-driven by supporting a number of use instances. For a contemporary information structure, it is best to use purposeful information shops like Amazon S3, Amazon Redshift, Amazon Timestream, and others primarily based in your use case.
In regards to the Authors
 Suresh Patnam is a Principal Options Architect at AWS. He’s obsessed with serving to companies of all sizes reworking into fast-moving digital organizations specializing in huge information, information lakes, and AI/ML. Suresh holds a MBA diploma from Duke College- Fuqua College of Enterprise and MS in CIS from Missouri State College. In his spare time, Suresh enjoys enjoying tennis and spending time together with his household.
Suresh Patnam is a Principal Options Architect at AWS. He’s obsessed with serving to companies of all sizes reworking into fast-moving digital organizations specializing in huge information, information lakes, and AI/ML. Suresh holds a MBA diploma from Duke College- Fuqua College of Enterprise and MS in CIS from Missouri State College. In his spare time, Suresh enjoys enjoying tennis and spending time together with his household.
 Arunabha Datta is a Sr. Knowledge Architect at AWS Skilled Providers. He collaborates with clients and companions to architect and implement trendy information structure utilizing AWS Analytics providers. In his spare time, Arunabha enjoys pictures and spending time together with his household.
Arunabha Datta is a Sr. Knowledge Architect at AWS Skilled Providers. He collaborates with clients and companions to architect and implement trendy information structure utilizing AWS Analytics providers. In his spare time, Arunabha enjoys pictures and spending time together with his household.

{kind=link}