

On this weblog, we are going to describe a brand new storage format that we adopted for our search index, one of many indexes in Rockset’s Converged Index. This new format diminished latencies for widespread queries by as a lot as 70% and the dimensions of the search index by about 20%.
As described in our Converged Index weblog, we retailer each column of each doc in a row-based retailer, column-based retailer, and a search index. We initially designed our search index to retailer particular person key-value pairs mapping a column worth to a doc id. We discovered that plenty of queries must retrieve numerous doc ids from the search index for a selected column worth. These queries had been spending as a lot as 70% of their time making rocksdb::DBIter::Subsequent() and rocksdb::DBIter::Search() calls.
As a part of our Star Schema Benchmark, we examined methods to cut back the variety of RocksDB calls that the search index was making. The targets of the initiative had been to:
- Cut back question latency
- Improve compute effectivity
- Cut back the storage footprint of indexes
With the assistance of our new storage format, the clustered search index, we had been in a position to obtain <1 second question latency for all 13 queries that make up the SSB. Learn the remainder of this weblog to see how we solved this technical problem.
Rockset’s Converged Index
With Rockset’s Converged Index, we retailer each column of each doc in three completely different indexes in order that our optimizer can choose the index that returns the very best latency for the question. For instance, if the question comprises slender selectivity predicates, the optimizer would resolve to make use of the search index and solely retrieve these paperwork from the gathering that fulfill the predicates. If the question comprises broad selectivity predicates, the optimizer would resolve to make use of the column retailer to retrieve all values for specified columns from all of the paperwork within the assortment.
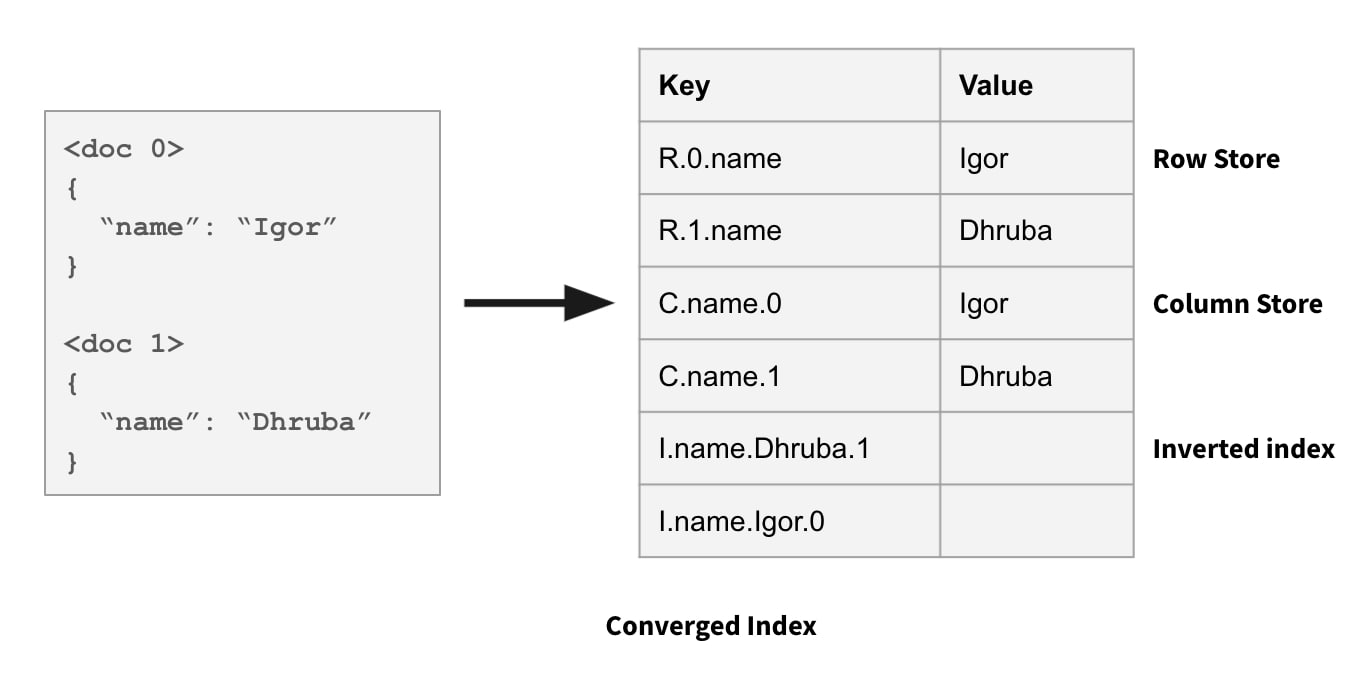
Within the row retailer, subject values in a doc are saved collectively. Within the column retailer, all values for a column throughout all paperwork are saved collectively. And within the search index, each <subject, worth> pair maps to the record of doc ids the place the sphere comprises that worth. See the picture beneath of Rockset’s Converged Index:
Block-Primarily based Storage Codecs
The columnar retailer in Rockset’s Converged Index is designed like every other columnar database: we write to and skim from the column retailer in blocks. Every block comprises a set of values which can be encoded after which compressed.
Studying column values as blocks is way more environment friendly than studying particular person values. This isn’t solely as a result of every block is effectively encoded for sooner reads, but in addition as a result of we make a lot fewer rocksdb::DBIter::Subsequent() calls. For each rocksdb::DBIter::Subsequent() name, RocksDB wants to take a look at its index of the LSM tree and use a min-heap to carry out a collection of key comparisons with a view to discover the following key. The important thing comparisons are costly. When the info is saved in blocks we solely must make this costly rocksdb::DBIter::Subsequent() name as soon as per block as a substitute of as soon as per particular person worth.
Whereas the advantages of utilizing block-based storage format for the column retailer had been very clear, it was not clear at first how and whether or not we should always use a block-based storage format for the search index.
We initially designed our search index to retailer particular person key-value pairs mapping a column worth to a doc id. We noticed that the repetitive rocksdb::DBIter::Subsequent() and rocksdb::DBIter::Search() calls brought about the throughput of the search index to be a lot worse than the throughput of the column retailer. Queries that wanted to learn numerous doc ids from the search index had been very sluggish.
So, we designed a block-based storage format for our search index. To one of the best of our information, that is the primary time a block-based storage format has been used for a search index in a storage system that helps real-time updates. What made this drawback attention-grabbing was that the brand new format wanted to fulfill the next necessities:
- Help real-time updates, can’t apply updates in batch.
- Updates mustn’t make queries sluggish.
- Every block would nonetheless be saved in RocksDB as a key-value pair, so a block shouldn’t be greater than 10s of MBs in measurement.
How Does It Work?
The essential concept right here is that for each <subject, worth> pair (e.g. <title, Dhruba>) within the search index, we need to retailer the corresponding record of doc ids in blocks as a substitute of as particular person entries. We name every of those blocks a “cluster”. The minimal and most doc id numbers that could possibly be saved in a cluster decide the boundaries of the cluster.
That will help you perceive the trade-offs we made within the remaining design, let me first describe a easy design that we thought-about at first and the issues with that design.
Preliminary Design
Within the preliminary design, for each <subject, worth> pair we accumulate doc ids in a cluster till we attain a sure threshold Ok, and retailer these doc ids in a single key-value pair in RocksDB. Word that we don’t want to carry a cluster in-memory till it’s full.
As an alternative, we constantly write incremental updates to RocksDB as updates are available after which merge all of the partial RocksDB values throughout question processing and compaction utilizing RocksDB’s merge operator. After the present cluster for a <subject, worth> pair fills as much as Ok entries, we create the following cluster for this <subject, worth> pair to carry the following Ok entries and so forth. We monitor cluster boundaries for each <subject, worth> pair and use these boundaries to appropriately apply updates. In different phrases, the boundaries decide clusters from which the doc id of up to date subject must be faraway from and added to.
We found the next issues with this method:
- We wanted to trace cluster boundaries individually for every
<subject, worth>pair which difficult the learn/write paths. - Doc updates might trigger older clusters to get larger later. These clusters would must be break up to restrict the dimensions to Ok entries. Splitting clusters requires us to amass a world lock to make sure that all author threads use the identical cluster boundaries. International locks negatively influence the latency and throughput of writes when cluster splits occur. This additionally makes our write path very difficult.
- All of the
<subject, worth>cluster boundaries must be held in reminiscence to have the ability to apply incoming writes. This metadata might change into very massive in measurement and devour a major quantity of reminiscence in our knowledge servers.
Closing Design
Finally, we got here up with a design that’s easy and helped us obtain vital efficiency enhancements.
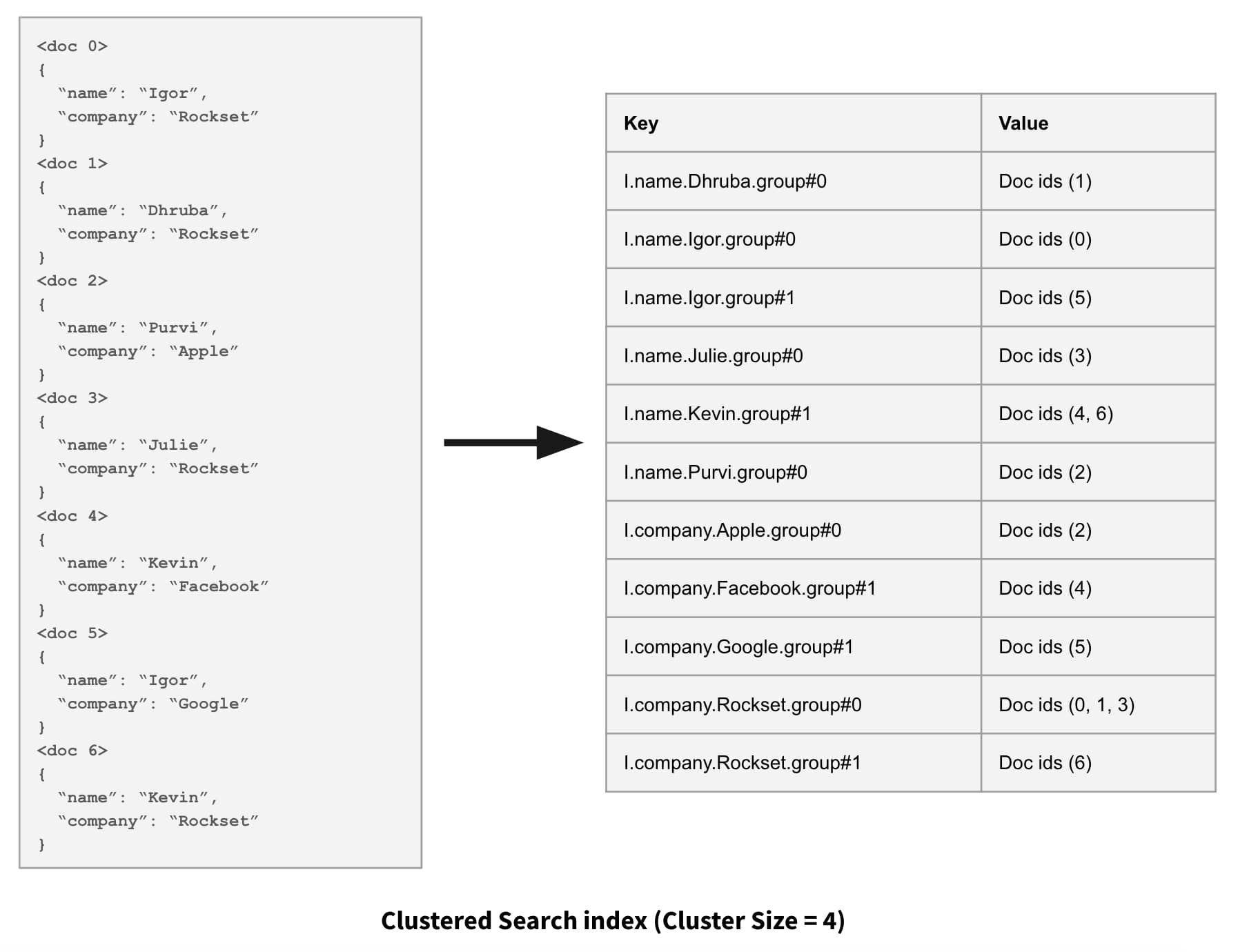
On this design, the cluster boundaries are predetermined. Parameter Ok specifies the utmost measurement of a cluster aka cluster measurement, and document_id / Ok operate determines the cluster id. Thus, the primary Ok paperwork with doc ids [0, 1K) fall in the first cluster, next K documents with document ids [1K, 2K) fall in the second cluster and so on. For every <field, value> pair in an incoming document, we add the document id to the cluster determined by the above function. This means that depending on how many times a particular <field, value> pair repeats in a consecutive set of K documents, clusters could contain much fewer entries than the cluster size of K.
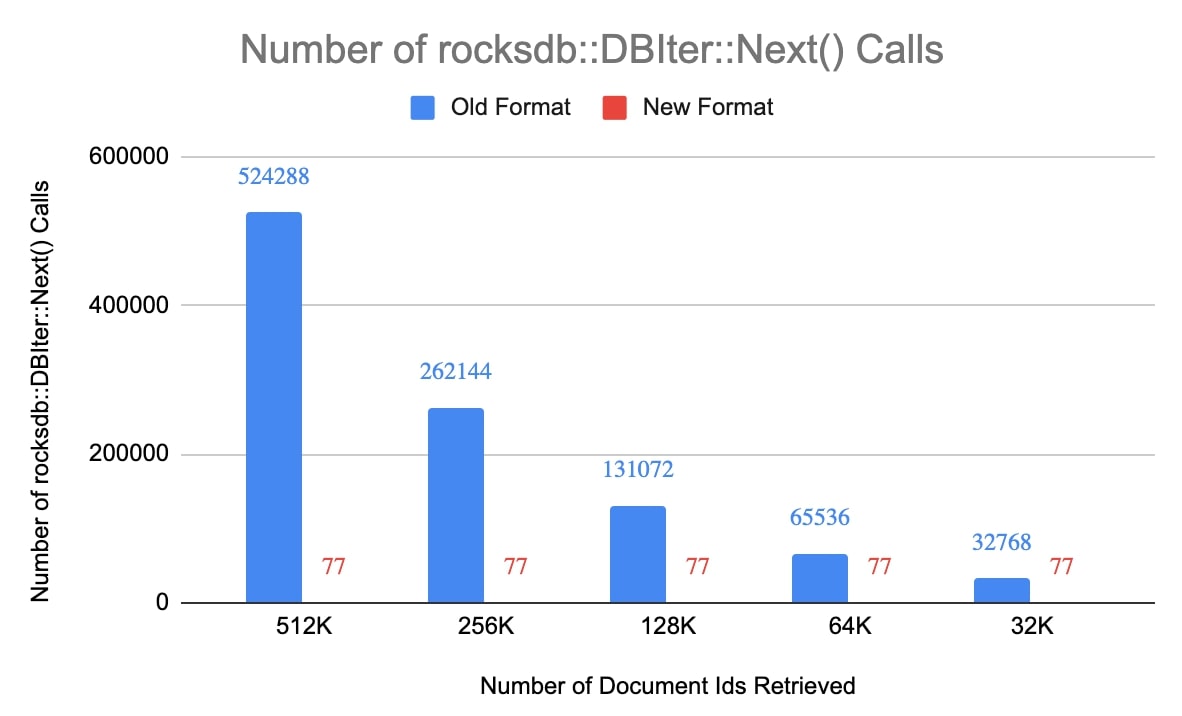
We were fine with clusters containing fewer entries than the cluster size of K. As we described earlier, our queries were slow when we needed to read a lot of document ids from the search index. In these cases, there would still be thousands to tens of thousands of entries per cluster and these clusters would help avoid the rocksdb::DBIter::Next() calls thousands of times.
We experimented with different values for parameter K, and picked 2^16 as it gives a good trade-off between performance and the worst-case RocksDB value size.
The following figure shows what the clustered search index looks like using a very small cluster size of 4.
Improvement in the Number of RocksDB Next Calls
We discovered the following benefits of the clustered search index approach:
In addition to the benefits listed above, the final design also met our initial set of requirements including allowing for mutability and low data and query latency. Here’s how we met those requirements:
- We can apply updates in real-time as they come in. We do not need to wait until a cluster fills up before we can persist it and make it available for queries.
- The multiple partial updates to the same cluster get compacted into the full value during background compaction. This helps avoid performing these merges during query execution. We also use a technique that we call lazy merging during query execution to perform live merges efficiently. Basically, when the merges happen from a read-only path like query execution, we avoid the serialization/deserialization step of the merged value which is otherwise enforced by the rocksdb::MergeOperator interface.
- The cluster size configuration parameter lets us keep the worst-case RocksDB value size under 10s of MBs.
The following charts show the improvement in the number of rocksdb::DBIter::Next() calls made and also the processing time to retrieve a bunch of document ids from the search index in the new format. For this experiment, we used a small collection with 5 million documents in it. Cluster size of 2^16 was used for the new format, which means there can only be up to 77 clusters (5,000,000 / 2^16) for a <field, value> pair.
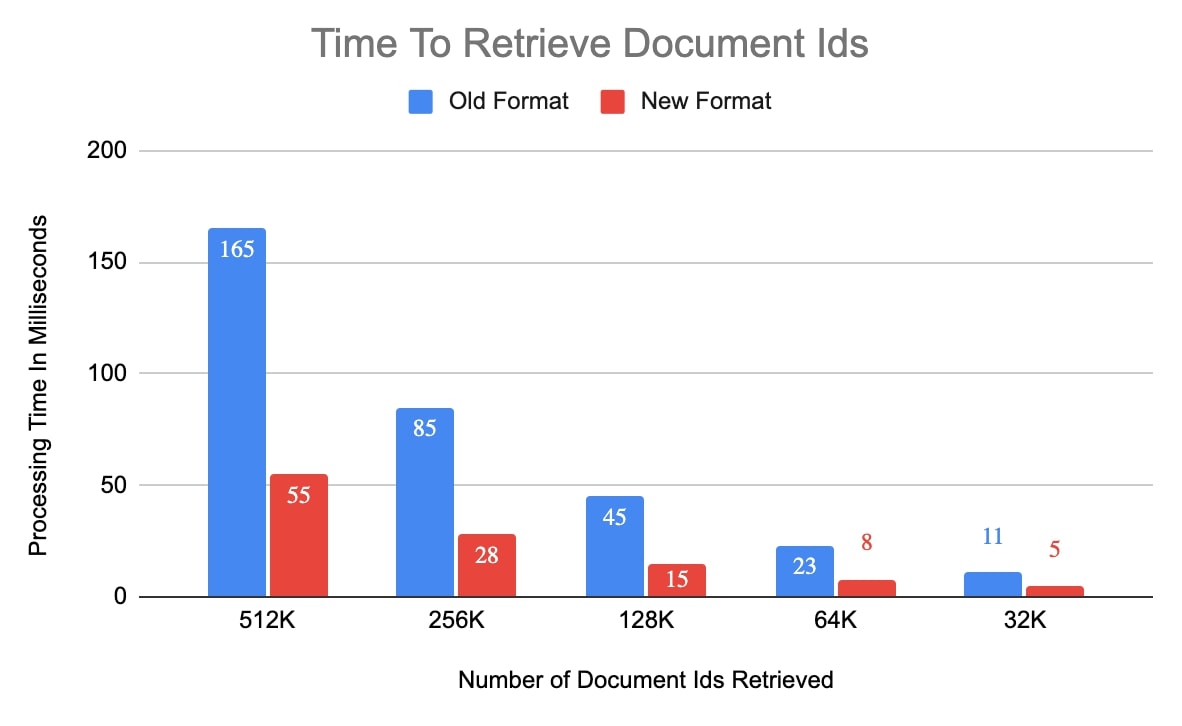
The clustered search index storage format reduced latency for queries that read a lot of document ids from the search index by as much as 70%. It has also helped reduce the size of the search index for some of our production customers by about 20%.

{kind=link}