

Word: for necessary background on vector search, see half 1 of our Introduction to Semantic Search: From Key phrases to Vectors.
When constructing a vector search app, you’re going to finish up managing plenty of vectors, also referred to as embeddings. And one of the vital frequent operations in these apps is discovering different close by vectors. A vector database not solely shops embeddings but in addition facilitates such frequent search operations over them.
The rationale why discovering close by vectors is helpful is that semantically comparable objects find yourself shut to one another within the embedding house. In different phrases, discovering the closest neighbors is the operation used to seek out comparable objects. With embedding schemes accessible for multilingual textual content, photos, sounds, knowledge, and plenty of different use instances, it is a compelling characteristic.
Producing Embeddings
A key choice level in growing a semantic search app that makes use of vectors is selecting which embedding service to make use of. Each merchandise you need to search on will must be processed to supply an embedding, as will each question. Relying in your workload, there could also be important overhead concerned in getting ready these embeddings. If the embedding supplier is within the cloud, then the supply of your system—even for queries—will rely upon the supply of the supplier.
It is a choice that needs to be given due consideration, since altering embeddings will usually entail repopulating the entire database, an costly proposition. Totally different fashions produce embeddings in a unique embedding house so embeddings are sometimes not comparable when generated with totally different fashions. Some vector databases, nonetheless, will permit a number of embeddings to be saved for a given merchandise.
One standard cloud-hosted embedding service for textual content is OpenAI’s Ada v2. It prices a few cents to course of 1,000,000 tokens and is broadly used throughout totally different industries. Google, Microsoft, HuggingFace, and others additionally present on-line choices.
In case your knowledge is just too delicate to ship exterior your partitions, or if system availability is of paramount concern, it’s attainable to regionally produce embeddings. Some standard libraries to do that embody SentenceTransformers, GenSim, and several other Pure Language Processing (NLP) frameworks.
For content material apart from textual content, there are all kinds of embedding fashions attainable. For instance, SentenceTransfomers permits photos and textual content to be in the identical embedding house, so an app might discover photos just like phrases, and vice versa. A number of various fashions can be found, and it is a quickly rising space of growth.
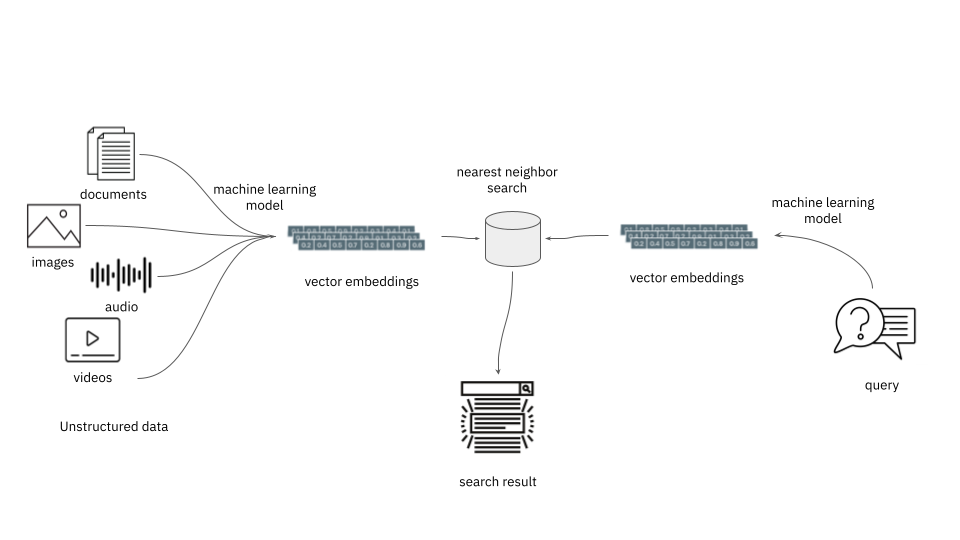
Nearest Neighbor Search
What exactly is supposed by “close by” vectors? To find out if vectors are semantically comparable (or totally different), you have to to compute distances, with a operate referred to as a distance measure. (You might even see this additionally known as a metric, which has a stricter definition; in observe, the phrases are sometimes used interchangeably.) Sometimes, a vector database can have optimized indexes primarily based on a set of obtainable measures. Right here’s a couple of of the frequent ones:
A direct, straight-line distance between two factors is known as a Euclidean distance metric, or typically L2, and is broadly supported. The calculation in two dimensions, utilizing x and y to signify the change alongside an axis, is sqrt(x^2 + y^2)—however take into account that precise vectors might have 1000’s of dimensions or extra, and all of these phrases must be computed over.
One other is the Manhattan distance metric, typically known as L1. That is like Euclidean in case you skip all of the multiplications and sq. root, in different phrases, in the identical notation as earlier than, merely abs(x) + abs(y). Consider it like the gap you’d have to stroll, following solely right-angle paths on a grid.
In some instances, the angle between two vectors can be utilized as a measure. A dot product, or internal product, is the mathematical instrument used on this case, and a few {hardware} is specifically optimized for these calculations. It incorporates the angle between vectors in addition to their lengths. In distinction, a cosine measure or cosine similarity accounts for angles alone, producing a worth between 1.0 (vectors pointing the identical route) to 0 (vectors orthogonal) to -1.0 (vectors 180 levels aside).
There are fairly a couple of specialised distance metrics, however these are much less generally carried out “out of the field.” Many vector databases permit for customized distance metrics to be plugged into the system.
Which distance measure must you select? Typically, the documentation for an embedding mannequin will say what to make use of—it’s best to comply with such recommendation. In any other case, Euclidean is an effective place to begin, except you might have particular causes to suppose in any other case. It might be price experimenting with totally different distance measures to see which one works greatest in your software.
With out some intelligent methods, to seek out the closest level in embedding house, within the worst case, the database would wish to calculate the gap measure between a goal vector and each different vector within the system, then kind the ensuing checklist. This shortly will get out of hand as the dimensions of the database grows. Consequently, all production-level databases embody approximate nearest neighbor (ANN) algorithms. These commerce off a tiny little bit of accuracy for a lot better efficiency. Analysis into ANN algorithms stays a scorching subject, and a powerful implementation of 1 is usually a key issue within the alternative of a vector database.
Choosing a Vector Database
Now that we’ve mentioned among the key parts that vector databases help–storing embeddings and computing vector similarity–how must you go about deciding on a database to your app?
Search efficiency, measured by the point wanted to resolve queries towards vector indexes, is a main consideration right here. It’s price understanding how a database implements approximate nearest neighbor indexing and matching, since this may have an effect on the efficiency and scale of your software. But additionally examine replace efficiency, the latency between including new vectors and having them seem within the outcomes. Querying and ingesting vector knowledge on the similar time might have efficiency implications as nicely, so be sure you take a look at this in case you count on to do each concurrently.
Have a good suggestion of the dimensions of your venture and how briskly you count on your customers and vector knowledge to develop. What number of embeddings are you going to want to retailer? Billion-scale vector search is definitely possible immediately. Can your vector database scale to deal with the QPS necessities of your software? Does efficiency degrade as the dimensions of the vector knowledge will increase? Whereas it issues much less what database is used for prototyping, it would be best to give deeper consideration to what it will take to get your vector search app into manufacturing.
Vector search functions usually want metadata filtering as nicely, so it’s a good suggestion to grasp how that filtering is carried out, and the way environment friendly it’s, when researching vector databases. Does the database pre-filter, post-filter or search and filter in a single step to be able to filter vector search outcomes utilizing metadata? Totally different approaches can have totally different implications for the effectivity of your vector search.
One factor usually neglected about vector databases is that additionally they must be good databases! Those who do a superb job dealing with content material and metadata on the required scale needs to be on the high of your checklist. Your evaluation wants to incorporate issues frequent to all databases, akin to entry controls, ease of administration, reliability and availability, and working prices.
Conclusion
In all probability the most typical use case immediately for vector databases is complementing Giant Language Fashions (LLMs) as a part of an AI-driven workflow. These are highly effective instruments, for which the business is simply scratching the floor of what’s attainable. Be warned: This superb know-how is prone to encourage you with recent concepts about new functions and potentialities to your search stack and what you are promoting.

{kind=link}