


(Picture supply: TileDB)
Being only one sort of database is simply too limiting today, so many databases have gone multi-modal. Why be only a key-value retailer once you could be KV plus graph? Doc databases are nice, however including a time-series information sort makes it higher! And all people shops vectors anymore. However the of us behind TileDB aren’t shopping for into the multi-modal development and as an alternative are looking for to invert the paradigm with a essentially totally different method.
It’s protected to say that TileDB founder and CEO Stavros Papadopoulos isn’t the most important fan of multi-modal databases.
“They’re committing to a single information sort–a desk or a doc or key-value–however nonetheless it’s a desk. It doesn’t change,” he says. “After which their force-fitting the opposite information sorts inside this.”
The results of the compromise a multi-modal database makes is a lower in efficiency, however that lower can’t be tolerated in a number of the largest analytic use instances in genomics, LiDAR imaging, and geospatial IoT information that TileDB clients are doing.
For instance, multi-modal database distributors say they’ll retailer massive picture information, or a binary massive objects (BLOBs), inside their database, however in accordance with Papadopulos, in reality they’re storing BLOB information in an exterior object retailer and even Dropbox, after which linking to the BLOB’s IP deal with from the database. “That’s not multi-modal, man,” he says. “It’s like storing a file inside your desk.”
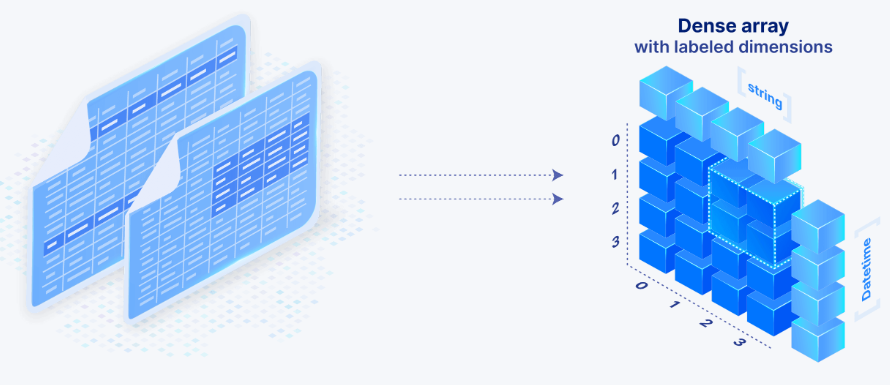
Together with his distributed, in-memory TileDB database, Papadopoulos is taking a essentially totally different method. As an alternative of making an attempt to suit totally different information sorts right into a database that’s essentially designed to deal with one information sort, he constructed TileDB with a extra versatile underlying information sort: the multi-dimensional array.
“TileDB adopts the multidimensional array as a first-class citizen, and this array has one attribute–it shapeshifts,” Papadopoulos says. “It morphs. It may well develop into a desk. It may well develop into a picture. It may well develop into doc. It may well develop into a key-value, as a result of it modifications. It has totally different dimensions. It’s dense or sparse. It has all this performance constructed into the mannequin that enables it take to take totally different shapes.
“So as an alternative of force-fitting information to a stiff information sort,” he continues, “we do the opposite manner round. We’re shifting the paradigm. We take the information that’s structured and we modify it and we apply completely to every of the information sorts, and that offers you efficiency.”
Papadopulos based TileDB after gaining his PhD in pc science and engineering from the Hong Kong College of Science and Expertise and spending time as a senior analysis scientist at Intel Labs and as a visiting scientist at each the Broad Institute and MIT.
At MIT, Papadopoulos labored beneath Turing Award winner Mike Stonebraker, and took an curiosity in considered one of his creations: SciDB, a column-oriented database designed to retailer multi-dimensional information in mathematical arrays for scientific purposes. Papadopulos took these learnings and created TileDB, which was spun out of MIT and Intel in 2017.
The potential to retailer information in multi-dimensional arrays offers TileDB the flexibleness and efficiency wanted by at present’s hardest analytic challenges, Papadopulos says. There are three core traits of TileDB that differentiate it from different databases, he says.
The TileDB database can assist dense and sparse arrays (Picture supply: TileDB)
“Primary, it handles all information,” he says. “Not simply tables. Not simply information. Not simply key-value. It handles all modalities. And that is extraordinarily necessary since you don’t have to purchase 10 totally different database programs in the event you have been coping with 10 totally different information modalities.
“The second factor is that we’re integrating the code within the database,” he says. “We don’t consider that the code ought to stay elsewhere. And if it lives in GitLab nonetheless, it must be managed alongside the information as a result of that’s how the builders use the code and the information within the group.
“And quantity three, our compute goes manner past SQL,” he continues. “SQL is only one API for us. Now we have a number of different APIs. Now we have a generic distribution, which we construct ourselves, and a distributed serverless engine, the place you’ll be able to spin up just about something. You’ll be able to spin up consumer outlined features. You’ll be able to spin up activity graphs for complicated workloads. You’ll be able to spin up Jupyter notebooks. You’ll be able to spin up any type of Net software inside the identical atmosphere.”

Stavros Papadopoulos is the CEO and founding father of TileDB
The open-source part of the TileDB database options APIs for Python, R, Java, Julia, Go, C, C#, and C++, enabling software builders to make use of the database with a variety of various purposes. The database integrates with Apache Arrow, offering compatibility with SQL engines like MariaDB, Trino, and Presto; computational frameworks like Dask and Spark; information science instruments like Pandas, Numpy, and Vaex; in addition to machine studying frameworks like PyTorch, TensorFlow, and scikit-learn.
TileDB, which was written in C++, integrates with object shops, together with S3, Azure BLOB Retailer, Google Cloud Storage, and Minio, primarily for persistence functions, Papadopoulos . Customers will pull in information they wish to analyze and retailer it in TileDB’s columnar format, which he calls “Parquet on steroids” as a result of it permits customers to choose two or three parameters to optimize the structure of the information on disk.
When Papadopoulos began the corporate, it was simply him. Now the Cambridge, Massachusetts primarily based firm has about 50 staff, together with a full crew of engineers working to construct and assist the database for enterprise use instances. Its clients use the database for high-end scientific evaluation of very massive information units in industries like prescribed drugs, oil and gasoline, autonomous autos, and others.
This week the corporate introduced that it’s raised $34 million in a Collection B spherical led by AlleyCorp, the enterprise capital agency led by Kevin Ryan, who’s the co-creator of MongoDB. Collaborating within the spherical have been Two Bear Capital, Nexus Enterprise Companions, Large Pi Ventures, Intel Capital, Uncorrelated, Lockheed Martin Ventures, Amgen Ventures, NTT Docomo Ventures, Verizon Ventures, S Ventures, LDV Companions, and Scale Asia Ventures.
The Collection B reveals that the corporate is for actual and that its database is prepared for manufacturing deployments, Papadopoulos says. “It’s not only a speculation anymore,” he says. “We simply raised our Collection b spherical, so now we will show that it really works extraordinarily nicely.”
Associated Objects:
TileDB Provides Vector Search Capabilities
Array Databases: The Subsequent Large Factor in Information Analytics?
Inside Pandata, the New Open-Supply Analytics Stack Backed by Anaconda

{kind=link}