
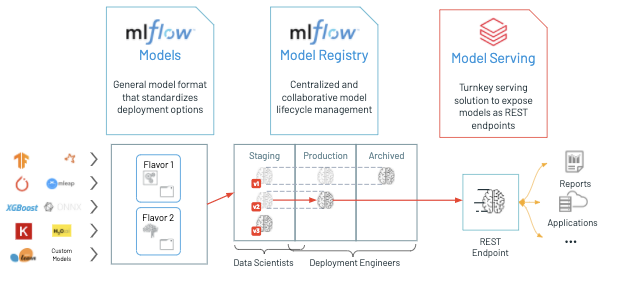
Databricks launched a public preview of GPU and LLM optimization assist for Databricks Mannequin Serving. This new function allows the deployment of varied AI fashions, together with LLMs and Imaginative and prescient fashions, on the Lakehouse Platform.
Databricks Mannequin Serving gives computerized optimization for LLM Serving, delivering high-performance outcomes with out the necessity for handbook configuration. In response to Databricks, it’s the primary serverless GPU serving product constructed on a unified information and AI platform, permitting customers to create and deploy GenAI purposes seamlessly inside a single platform, masking every little thing from information ingestion to mannequin deployment and monitoring.
Databricks Mannequin Serving simplifies the deployment of AI fashions, making it simple even for customers with out deep infrastructure information. Customers can deploy a variety of fashions, together with pure language, imaginative and prescient, audio, tabular, or customized fashions, no matter how they had been educated (from scratch, open-source, or fine-tuned with proprietary information).
Simply log your mannequin with MLflow, and Databricks Mannequin Serving will routinely put together a production-ready container with GPU libraries like CUDA and deploy it to serverless GPUs. This absolutely managed service handles every little thing from managing situations, sustaining model compatibility, to patching variations. It additionally routinely adjusts occasion scaling to match visitors patterns, saving on infrastructure prices whereas optimizing efficiency and latency.
Databricks Mannequin Serving has launched optimizations for serving massive language fashions (LLM) extra effectively, leading to as much as a 3-5x discount in latency and value. To make use of Optimized LLM Serving, you merely present the mannequin and its weights, and Databricks takes care of the remaining, making certain your mannequin performs optimally.
This streamlines the method, permitting you to focus on integrating LLM into your utility relatively than coping with low-level mannequin optimization. Presently, Databricks Mannequin Serving routinely optimizes MPT and Llama2 fashions, with plans to assist further fashions sooner or later.

{kind=link}