

This publish is co-written by Lisa Levy, Content material Specialist at Satori.
Knowledge democratization allows customers to find and acquire entry to information quicker, bettering knowledgeable data-driven choices and utilizing information to generate enterprise influence. It additionally will increase collaboration throughout groups and organizations, breaking down information silos and enabling cross-functional groups to work collectively extra successfully.
A big barrier to information democratization is making certain that information stays safe and compliant. The power to look, find, and masks delicate information is crucial for the information democratization course of. Amazon Redshift supplies quite a few options equivalent to role-based entry management (RBAC), row-level safety (RLS), column-level safety (CLS), and dynamic information masking to facilitate the safe use of knowledge.
On this two-part sequence, we discover how Satori, an Amazon Redshift Prepared companion, may also help Amazon Redshift customers automate safe entry to information and supply their information customers with self-service information entry. Satori integrates natively with each Amazon Redshift provisioned clusters and Amazon Redshift Serverless for simple setup of your Amazon Redshift information warehouse within the safe Satori portal.
Partially 1, we offer detailed steps on combine Satori together with your Amazon Redshift information warehouse and management how information is accessed with safety insurance policies.
Partially 2, we are going to discover arrange self-service information entry with Satori to information saved in Amazon Redshift.
Satori’s information safety platform
Satori is a knowledge safety platform that permits frictionless self-service entry for customers with built-in safety. Satori accelerates implementing information safety controls on datawarehouses like Amazon Redshift, is simple to combine, and doesn’t require any adjustments to your Amazon Redshift information, schema, or how your customers work together with information.
Integrating Satori with Amazon Redshift accelerates organizations’ capacity to utilize their information to generate enterprise worth. This quicker time-to-value is achieved by enabling corporations to handle information entry extra effectively and successfully.
By utilizing Satori with the Trendy Knowledge Structure on AWS, you could find and get entry to information utilizing a customized information portal, and corporations can set insurance policies equivalent to just-in-time entry to information and fine-grained entry management. Moreover, all information entry is audited. Satori seamlessly works with native Redshift objects, exterior tables that may be queried by way of Amazon Redshift Spectrum, as effectively shared database objects by way of Redshift information sharing.
Satori anonymizes information on the fly, primarily based in your necessities, in accordance with customers, roles, and datasets. The masking is utilized whatever the underlying database and doesn’t require writing code or making adjustments to your databases, information warehouses, and information lakes. Satori repeatedly displays information entry, identifies the placement of every dataset, and classifies the information in every column. The result’s a self-populating information stock, which additionally classifies the information for you and permits you to add your individual personalized classifications.
Satori integrates with id suppliers to counterpoint its id context and ship higher analytics and extra correct entry management insurance policies. Satori interacts with id suppliers both through API or through the use of the SAML protocol. Satori additionally integrates with enterprise intelligence (BI) instruments like Amazon QuickSight, Tableau, Energy BI and so forth. to observe and implement safety and privateness insurance policies for information customers who use BI instruments to entry information.
On this publish, we discover how organizations can speed up safe information use in Amazon Redshift with Satori, together with the advantages of integration and the required steps to begin. We’ll undergo an instance of integrating Satori with a Redshift cluster and look at how safety insurance policies are utilized dynamically when queried by way of DBeaver.
Conditions
It’s best to have the next conditions:
- An AWS account.
- A Redshift cluster and Redshift Severless endpoint to retailer and handle information. You possibly can create and handle your cluster by way of the AWS Administration Console, AWS Command Line Interface (AWS CLI), or Redshift API.
- A Satori account and the Satori connector for Amazon Redshift.
- A Redshift safety group. You’ll must configure your Redshift safety group to permit inbound visitors from the Satori connector for Amazon Redshift. Observe that Satori could be deployed as a software program as a service (SaaS) information entry controller or inside your VPC.
Put together the information
To arrange our instance, full the next steps:
- On the Amazon Redshift console, navigate to Question Editor v2.
For those who’re conversant in SQL Notebooks, you may obtain this SQL pocket book for the demonstration and import it to rapidly get began.
- Within the Amazon Redshift provisioned Cluster, Use the next code to create a desk, populate it, and create roles and customers:
Connect with provisioned cluster by way of Question Editor V2 and run the next SQL:
Repeat the above step for Redshift Serverless endpoint and get the namespace:
- Connect with Redshift provisioned cluster and create an outbound information share (producer) with the next SQL
- Connect with Redshift Serverless endpoint and execute the beneath statements to setup the inbound datashare.
- Optionally, create the credit_cards desk as an exterior desk through the use of this pattern file in Amazon S3 and including the desk to AWS Glue Knowledge Catalog by way of Glue Crawler. As soon as the desk is offered in Glue Knowledge Catalog, you may create the exterior schema in your Amazon Redshift Serverless endpoint utilizing the beneath SQL
Connect with Amazon Redshift
For those who don’t have a Satori account, you may both create a check drive account or get Satori from the AWS Market. Then full the next steps to hook up with Amazon Redshift:
- Log in to Satori.
- Select Knowledge Shops within the navigation pane, select Add Datastore, and select Amazon Redshift.

- Add your cluster identifier from the Amazon Redshift console. Satori will robotically detect the Area the place your cluster resides inside your AWS account.
- Satori will generate a Satori hostname in your cluster, which you’ll use to hook up with your Redshift cluster
- On this demonstration, we are going to add a Redshift provisioned cluster and a Redshift Serverless endpoint to create two datastores in Satori


- Permit inbound entry for the Satori IP addresses listed in your Redshift cluster safety group.
For extra particulars on connecting Satori to your Redshift cluster, discuss with Including an AWS Redshift Knowledge Retailer to Satori.
- Beneath Authentication Settings, enter your root or superuser credentials for every datastore.

- Depart the remainder of the tabs with their default settings and select Save.
Now your information shops are able to be accessed by way of Satori.
Create a dataset
Full the next steps to create a dataset:
- Select Datasets within the navigation pane and select Add New Dataset.
- Choose your datastore and enter the small print of your dataset.

A dataset generally is a assortment of database objects that you simply categorize as a dataset. For Redshift provisioned cluster, we created a buyer dataset with particulars on the database and schema. You too can optionally select to give attention to a selected desk inside the schema and even exclude sure schemas or tables from the dataset.
For Redshift Serverless, we created a dataset that with all datastore areas, to incorporate the shared desk and Exterior desk

- Select Save.
- For every dataset, navigate to Consumer Entry Guidelines and create dataset person entry insurance policies for the roles we created.

- Allow Give Satori Management Over Entry to the Dataset.
- Optionally, you may add expiration and revoke time configurations to the entry insurance policies to restrict how lengthy entry is granted to the Redshift cluster.
Create a safety coverage for the dataset
Satori supplies a number of masking profile templates that you should use as a baseline and customise earlier than including them to your safety insurance policies. Full the next steps to create your safety coverage:
- Select Masking Profiles within the navigation pane and use the Restrictive Coverage template to create a masking coverage.

- Present a descriptive identify for the coverage.
- You possibly can customise the coverage additional so as to add customized fields and their respective masking insurance policies. The next instance exhibits the extra area Credit score Card Quantity that was added with the motion to masks the whole lot however the final 4 characters.
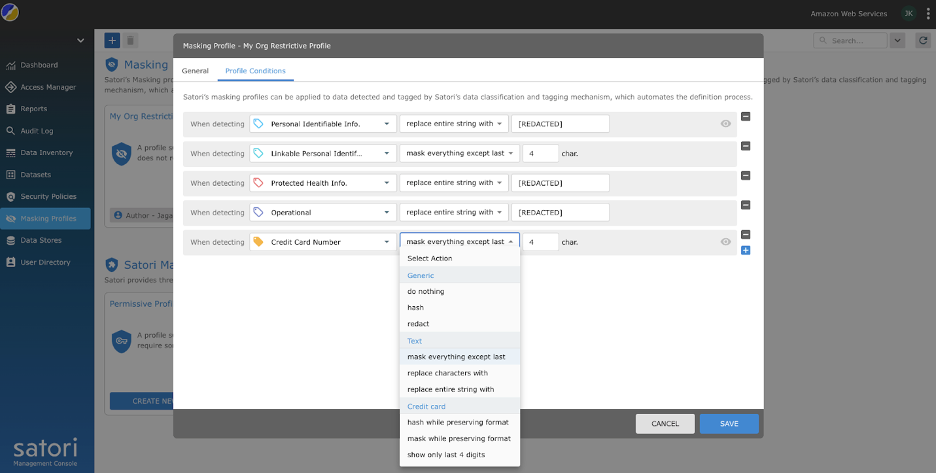
- Select Safety Insurance policies within the navigation pane and create a safety coverage referred to as Buyer Knowledge Safety Coverage.

- Affiliate the coverage with the masking profile created within the earlier step.
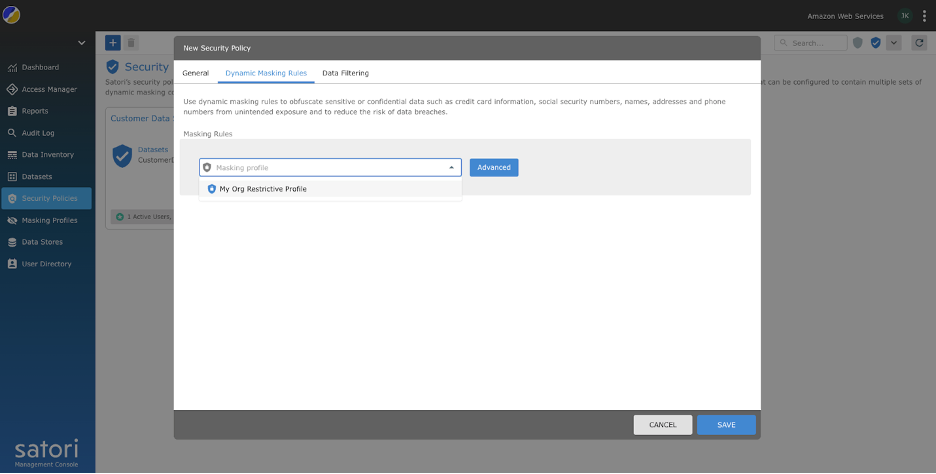
- Affiliate the created safety coverage with the datasets by enhancing the dataset and navigating to the Safety Insurance policies tab.

Now that the mixing, coverage, and entry controls are set, let’s question the information by way of DBeaver.
Question safe information
To question your information, connect with the Redshift cluster and Redshift Serverless endpoint utilizing their respective Satori hostname that was obtained earlier.

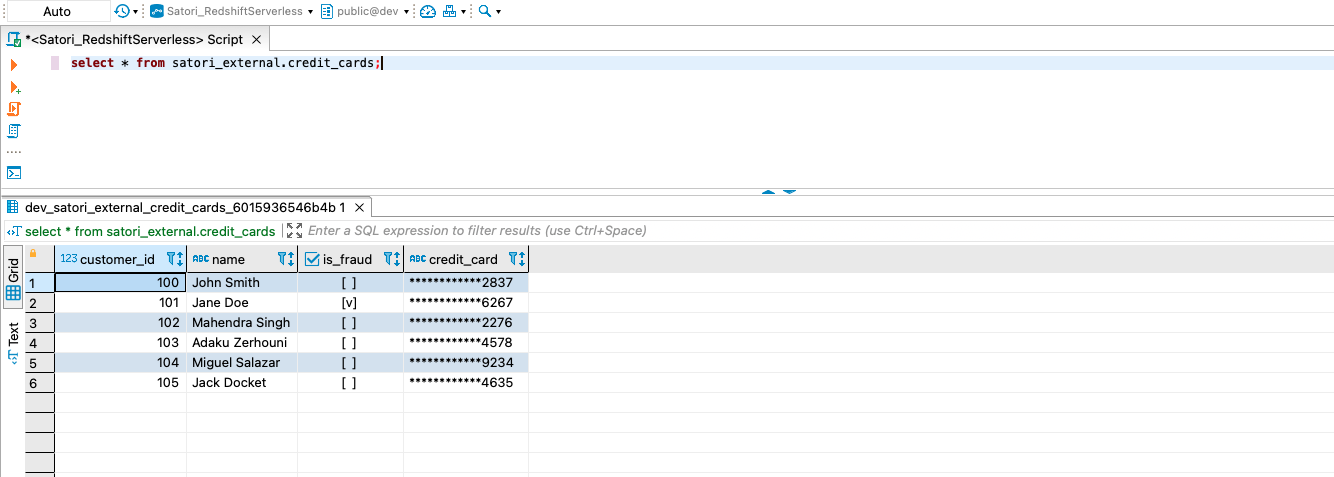
If you question the information in Redshift provisioned cluster, you will notice the safety insurance policies utilized to the outcome set at runtime.

If you question the information in Redshift Serverless endpoint, you will notice the safety insurance policies utilized to credit_cards desk shared from the Redshift provisioned cluster.

You’ll get related outcomes with insurance policies utilized should you question the exterior desk in Amazon S3 from Redshift Serverless endpoint
Abstract
On this publish, we described how Satori may also help you with safe information entry out of your Redshift cluster with out requiring any adjustments to your Redshift information, schema, or how your customers work together with information. Partially 2, we are going to discover arrange self-service information entry to information saved in Amazon Redshift with the totally different roles we created as a part of the preliminary setup.
Satori is offered on the AWS Market. To study extra, begin a free trial or request a demo assembly.
Concerning the authors
 Jagadish Kumar is a Senior Analytics Specialist Options Architect at AWS targeted on Amazon Redshift. He’s deeply obsessed with Knowledge Structure and helps prospects construct analytics options at scale on AWS.
Jagadish Kumar is a Senior Analytics Specialist Options Architect at AWS targeted on Amazon Redshift. He’s deeply obsessed with Knowledge Structure and helps prospects construct analytics options at scale on AWS.
 Lisa Levy is a Content material Specialist at Satori. She publishes informative content material to successfully describe how Satori’s information safety platform enhances organizational productiveness.
Lisa Levy is a Content material Specialist at Satori. She publishes informative content material to successfully describe how Satori’s information safety platform enhances organizational productiveness.

{kind=link}