
Since its introduction in 2012, Amazon DynamoDB has been one of the widespread NoSQL databases within the cloud. DynamoDB, not like a conventional RDBMS, scales horizontally, obviating the necessity for cautious capability planning, resharding, and database upkeep. In consequence, DynamoDB is the database of selection for firms constructing event-driven architectures and user-friendly, performant functions at scale. As such, DynamoDB is central to many fashionable functions in advert tech, gaming, IoT, and monetary providers.
Nonetheless, whereas DynamoDB is nice for real-time transactions it doesn’t do as properly for analytics workloads. Analytics workloads are the place Rockset shines. To allow these workloads, Rockset supplies a totally managed sync to DynamoDB tables with its built-in connector. The information from DynamoDB is robotically listed in an inverted index, a column index and a row index which might then be queried rapidly and effectively.
As such, the DynamoDB connector is certainly one of our most generally used knowledge connectors. We see customers transfer large quantities of knowledge–TBs price of knowledge–utilizing the DynamoDB connector. Given the dimensions of the use, we quickly uncovered shortcomings with our connector.
How the DynamoDB Connector At the moment Works with Scan API
At a excessive degree, we ingest knowledge into Rockset utilizing the present connector in two phases:
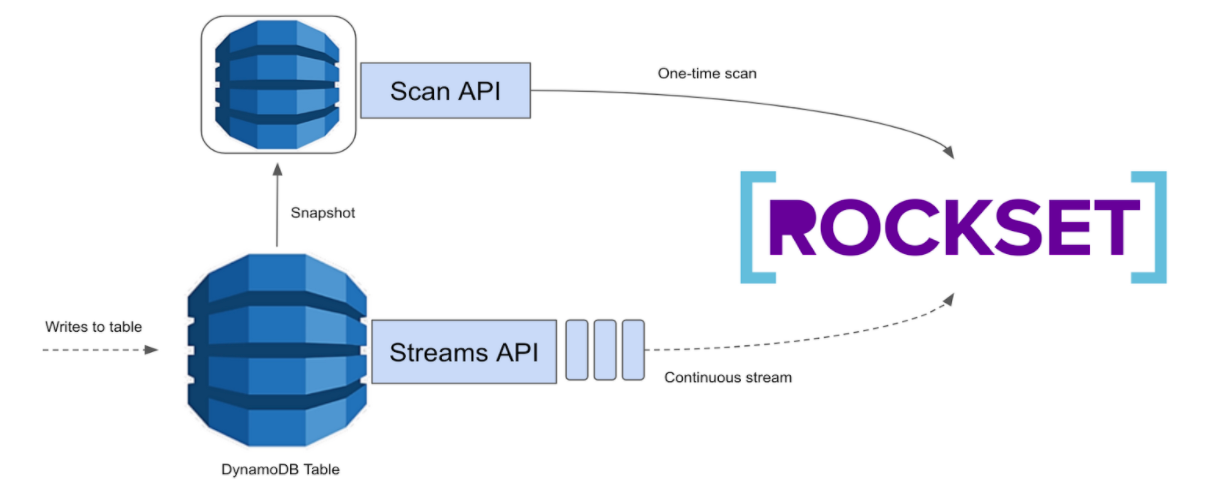
- Preliminary Dump: This part makes use of DynamoDB’s Scan API for a one-time scan of the complete desk
- Streaming: This part makes use of DynamoDB’s Streams API and consumes steady updates made to a DynamoDB desk in a streaming vogue.
Roughly, the preliminary dump provides us a snapshot of the info, on which the updates from the streaming part apply. Whereas the preliminary dump utilizing the Scan API works properly for small sizes, it doesn’t at all times do properly for giant knowledge dumps.
There are two principal points with DynamoDB’s preliminary dump because it stands as we speak:
- Unconfigurable section sizes: Dynamo doesn’t at all times steadiness segments uniformly, typically resulting in a straggler section that’s inordinately bigger than the others. As a result of parallelism is at section granularity, we now have seen straggler segments enhance the full ingestion time for a number of customers in manufacturing.
- Fastened Dynamo stream retention: DynamoDB Streams seize change data in a log for as much as 24 hours. Which means if the preliminary dump takes longer than 24 hours the shards that have been checkpointed firstly of the preliminary dump can have expired by then, resulting in knowledge loss.
Enhancing the DynamoDB Connector with Export to S3
When AWS introduced the launch of latest performance that lets you export DynamoDB desk knowledge to Amazon S3, we began evaluating this strategy to see if this might assist overcome the shortcomings with the older strategy.
At a excessive degree, as an alternative of utilizing the Scan API to get a snapshot of the info, we use the brand new export desk to S3 performance. Whereas not a drop-in alternative for the Scan API, we tweaked the streaming part which, along with the export to S3, is the idea of our new connector.

Whereas the previous connector took nearly 20 hours to ingest 1TB finish to finish with manufacturing workload operating on the DynamoDB desk, the brand new connector takes solely about 1 hour, finish to finish. What’s extra, ingesting 20TB from DynamoDB takes solely 3.5 hours, finish to finish! All you could present is an S3 bucket!
Advantages of the brand new strategy:
- Doesn’t have an effect on the provisioned learn capability, and thus any manufacturing workload, operating on the DynamoDB desk
- The export course of is rather a lot quicker than customized table-scan options
- S3 duties could be configured to unfold the load evenly in order that we don’t must cope with a closely imbalanced section like with DynamoDB
- Checkpointing with S3 comes totally free (we only recently constructed assist for this)
We’re opening up entry for public beta, and can’t wait so that you can take this for a spin! Signal-up right here.
Joyful ingesting and glad querying!

{kind=link}