

Organizations throughout all industries have advanced information processing necessities for his or her analytical use instances throughout totally different analytics methods, comparable to information lakes on AWS, information warehouses (Amazon Redshift), search (Amazon OpenSearch Service), NoSQL (Amazon DynamoDB), machine studying (Amazon SageMaker), and extra. Analytics professionals are tasked with deriving worth from information saved in these distributed methods to create higher, safe, and cost-optimized experiences for his or her prospects. For instance, digital media corporations search to mix and course of datasets in inside and exterior databases to construct unified views of their buyer profiles, spur concepts for revolutionary options, and improve platform engagement.
In these eventualities, prospects in search of a serverless information integration providing use AWS Glue as a core part for processing and cataloging information. AWS Glue is effectively built-in with AWS providers and accomplice merchandise, and offers low-code/no-code extract, remodel, and cargo (ETL) choices to allow analytics, machine studying (ML), or utility improvement workflows. AWS Glue ETL jobs could also be one part in a extra advanced pipeline. Orchestrating the run of and managing dependencies between these elements is a key functionality in an information technique. Amazon Managed Workflows for Apache Airflows (Amazon MWAA) orchestrates information pipelines utilizing distributed applied sciences together with on-premises assets, AWS providers, and third-party elements.
On this submit, we present methods to simplify monitoring an AWS Glue job orchestrated by Airflow utilizing the most recent options of Amazon MWAA.
Overview of answer
This submit discusses the next:
- Learn how to improve an Amazon MWAA atmosphere to model 2.4.3.
- Learn how to orchestrate an AWS Glue job from an Airflow Directed Acyclic Graph (DAG).
- The Airflow Amazon supplier bundle’s observability enhancements in Amazon MWAA. Now you can consolidate run logs of AWS Glue jobs on the Airflow console to simplify troubleshooting information pipelines. The Amazon MWAA console turns into a single reference to observe and analyze AWS Glue job runs. Beforehand, help groups wanted to entry the AWS Administration Console and take handbook steps for this visibility. This characteristic is obtainable by default from Amazon MWAA model 2.4.3.
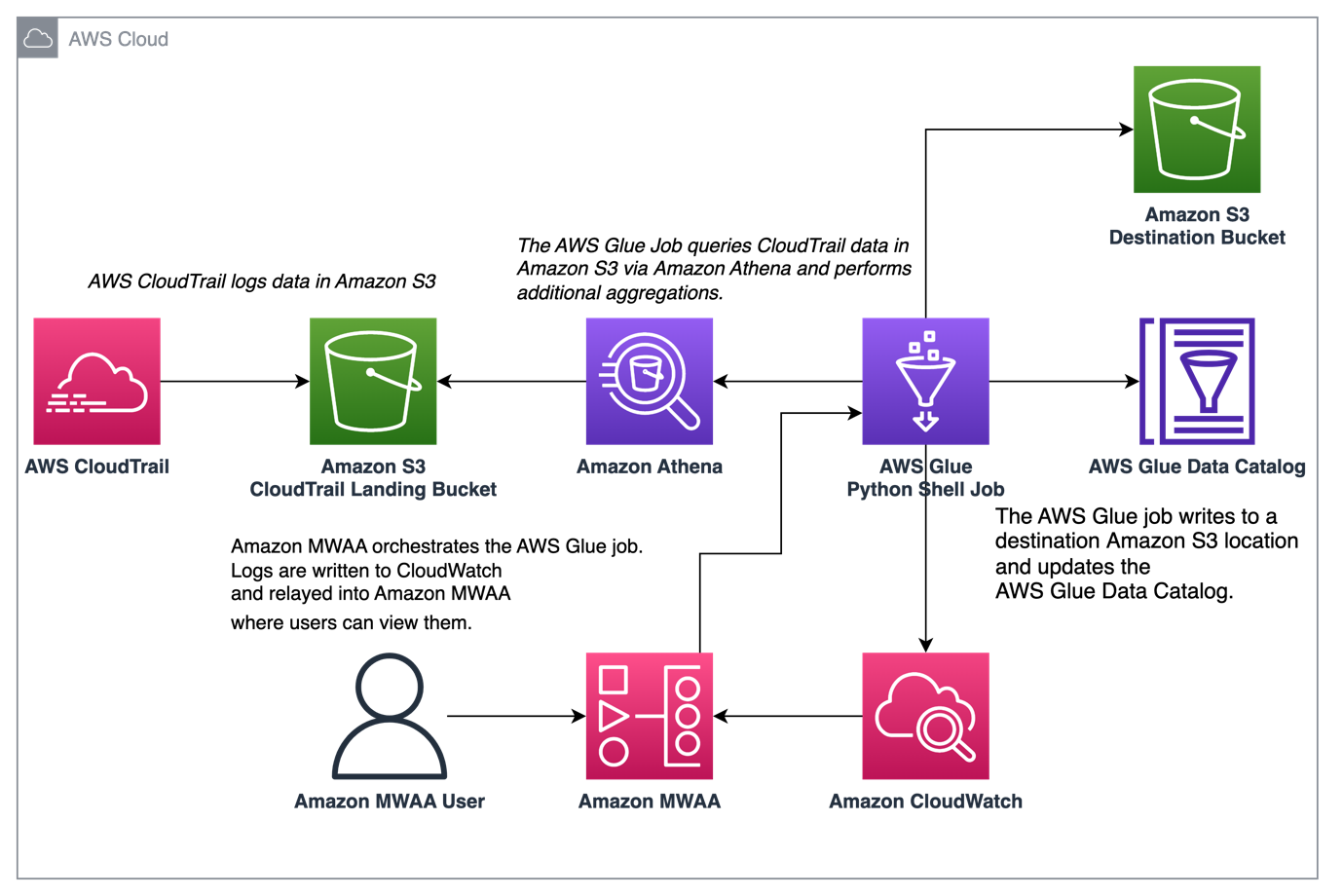
The next diagram illustrates our answer structure.
Stipulations
You want the next stipulations:
Arrange the Amazon MWAA atmosphere
For directions on creating your atmosphere, seek advice from Create an Amazon MWAA atmosphere. For current customers, we suggest upgrading to model 2.4.3 to reap the benefits of the observability enhancements featured on this submit.
The steps to improve Amazon MWAA to model 2.4.3 differ relying on whether or not the present model is 1.10.12 or 2.2.2. We talk about each choices on this submit.
Stipulations for establishing an Amazon MWAA atmosphere
You could meet the next stipulations:
Improve from model 1.10.12 to 2.4.3
In case you’re utilizing Amazon MWAA model 1.10.12, seek advice from Migrating to a brand new Amazon MWAA atmosphere to improve to 2.4.3.
Improve from model 2.0.2 or 2.2.2 to 2.4.3
In case you’re utilizing Amazon MWAA atmosphere model 2.2.2 or decrease, full the next steps:
- Create a necessities.txt for any customized dependencies with particular variations required in your DAGs.
- Add the file to Amazon S3 within the applicable location the place the Amazon MWAA atmosphere factors to the necessities.txt for putting in dependencies.
- Observe the steps in Migrating to a brand new Amazon MWAA atmosphere and choose model 2.4.3.
Replace your DAGs
Clients who upgraded from an older Amazon MWAA atmosphere could have to make updates to current DAGs. In Airflow model 2.4.3, the Airflow atmosphere will use the Amazon supplier bundle model 6.0.0 by default. This bundle could embrace some doubtlessly breaking modifications, comparable to modifications to operator names. For instance, the AWSGlueJobOperator has been deprecated and changed with the GlueJobOperator. To take care of compatibility, replace your Airflow DAGs by changing any deprecated or unsupported operators from earlier variations with the brand new ones. Full the next steps:
- Navigate to Amazon AWS Operators.
- Choose the suitable model put in in your Amazon MWAA occasion (6.0.0. by default) to discover a record of supported Airflow operators.
- Make the mandatory modifications within the current DAG code and add the modified recordsdata to the DAG location in Amazon S3.
Orchestrate the AWS Glue job from Airflow
This part covers the small print of orchestrating an AWS Glue job inside Airflow DAGs. Airflow eases the event of knowledge pipelines with dependencies between heterogeneous methods comparable to on-premises processes, exterior dependencies, different AWS providers, and extra.
Orchestrate CloudTrail log aggregation with AWS Glue and Amazon MWAA
On this instance, we undergo a use case of utilizing Amazon MWAA to orchestrate an AWS Glue Python Shell job that persists aggregated metrics based mostly on CloudTrail logs.
CloudTrail allows visibility into AWS API calls which can be being made in your AWS account. A typical use case with this information could be to assemble utilization metrics on principals performing in your account’s assets for auditing and regulatory wants.
As CloudTrail occasions are being logged, they’re delivered as JSON recordsdata in Amazon S3, which aren’t superb for analytical queries. We wish to mixture this information and persist it as Parquet recordsdata to permit for optimum question efficiency. As an preliminary step, we are able to use Athena to do the preliminary querying of the info earlier than doing further aggregations in our AWS Glue job. For extra details about creating an AWS Glue Information Catalog desk, seek advice from Creating the desk for CloudTrail logs in Athena utilizing partition projection information. After we’ve explored the info through Athena and determined what metrics we wish to retain in mixture tables, we are able to create an AWS Glue job.
Create an CloudTrail desk in Athena
First, we have to create a desk in our Information Catalog that permits CloudTrail information to be queried through Athena. The next pattern question creates a desk with two partitions on the Area and date (known as snapshot_date). You’ll want to change the placeholders in your CloudTrail bucket, AWS account ID, and CloudTrail desk identify:
create exterior desk if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`(
`eventversion` string remark 'from deserializer',
`useridentity` struct<sort:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<sort:string,principalid:string,arn:string,accountid:string,username:string>>> remark 'from deserializer',
`eventtime` string remark 'from deserializer',
`eventsource` string remark 'from deserializer',
`eventname` string remark 'from deserializer',
`awsregion` string remark 'from deserializer',
`sourceipaddress` string remark 'from deserializer',
`useragent` string remark 'from deserializer',
`errorcode` string remark 'from deserializer',
`errormessage` string remark 'from deserializer',
`requestparameters` string remark 'from deserializer',
`responseelements` string remark 'from deserializer',
`additionaleventdata` string remark 'from deserializer',
`requestid` string remark 'from deserializer',
`eventid` string remark 'from deserializer',
`assets` array<struct<arn:string,accountid:string,sort:string>> remark 'from deserializer',
`eventtype` string remark 'from deserializer',
`apiversion` string remark 'from deserializer',
`readonly` string remark 'from deserializer',
`recipientaccountid` string remark 'from deserializer',
`serviceeventdetails` string remark 'from deserializer',
`sharedeventid` string remark 'from deserializer',
`vpcendpointid` string remark 'from deserializer')
PARTITIONED BY (
`area` string,
`snapshot_date` string)
ROW FORMAT SERDE
'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT
'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.area.sort'='enum',
'projection.area.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1',
'projection.snapshot_date.format'='yyyy/mm/dd',
'projection.snapshot_date.interval'='1',
'projection.snapshot_date.interval.unit'='days',
'projection.snapshot_date.vary'='2020/10/01,now',
'projection.snapshot_date.sort'='date',
'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${area}/${snapshot_date}')Run the previous question on the Athena console, and word the desk identify and AWS Glue Information Catalog database the place it was created. We use these values later within the Airflow DAG code.
Pattern AWS Glue job code
The next code is a pattern AWS Glue Python Shell job that does the next:
- Takes arguments (which we move from our Amazon MWAA DAG) on what day’s information to course of
- Makes use of the AWS SDK for Pandas to run an Athena question to do the preliminary filtering of the CloudTrail JSON information outdoors AWS Glue
- Makes use of Pandas to do easy aggregations on the filtered information
- Outputs the aggregated information to the AWS Glue Information Catalog in a desk
- Makes use of logging throughout processing, which will likely be seen in Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta
# Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO)
LOGGER.data(f"Handed Args :: {sys.argv}")
sql_query_template = """
choose
area,
useridentity.arn,
eventsource,
eventname,
useragent
from "{cloudtrail_glue_db}"."{cloudtrail_table}"
the place snapshot_date="{process_date}"
and area in ('us-east-1','us-east-2')
"""
required_args = ['CLOUDTRAIL_GLUE_DB',
'CLOUDTRAIL_TABLE',
'TARGET_BUCKET',
'TARGET_DB',
'TARGET_TABLE',
'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys)
LOGGER.data(f"Parsed Args :: {JOB_ARGS}")
# if course of date was not handed as an argument, course of yesterday's information
process_date = (
JOB_ARGS['PROCESS_DATE']
if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE"
else (datetime.at the moment() - timedelta(days=1)).strftime("%Y-%m-%d")
)
LOGGER.data(f"Taking snapshot for :: {process_date}")
RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID']
final_query = sql_query_template.format(
process_date=process_date.change("-","/"),
cloudtrail_glue_db=RAW_CLOUDTRAIL_DB,
cloudtrail_table=RAW_CLOUDTRAIL_TABLE
)
LOGGER.data(f"Operating Question :: {final_query}")
raw_cloudtrail_df = wr.athena.read_sql_query(
sql=final_query,
database=RAW_CLOUDTRAIL_DB,
ctas_approach=False,
s3_output=f"s3://{TARGET_BUCKET}/athena-results",
)
raw_cloudtrail_df['ct']=1
agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date
LOGGER.data(agg_df.data(verbose=True))
upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}"
if not agg_df.empty:
LOGGER.data(f"Add to {upload_path}")
attempt:
response = wr.s3.to_parquet(
df=agg_df,
path=upload_path,
dataset=True,
database=TARGET_DB,
desk=TARGET_TABLE,
mode="overwrite_partitions",
schema_evolution=True,
partition_cols=["snapshot_date"],
compression="snappy",
index=False
)
LOGGER.data(response)
besides Exception as exc:
LOGGER.error("Importing to S3 failed")
LOGGER.exception(exc)
elevate exc
else:
LOGGER.data(f"Dataframe was empty, nothing to add to {upload_path}")
The next are some key benefits on this AWS Glue job:
- We use an Athena question to make sure preliminary filtering is finished outdoors of our AWS Glue job. As such, a Python Shell job with minimal compute remains to be ample for aggregating a big CloudTrail dataset.
- We make sure the analytics library-set choice is turned on when creating our AWS Glue job to make use of the AWS SDK for Pandas library.
Create an AWS Glue job
Full the next steps to create your AWS Glue job:
- Copy the script within the previous part and put it aside in a neighborhood file. For this submit, the file known as
script.py. - On the AWS Glue console, select ETL jobs within the navigation pane.
- Create a brand new job and choose Python Shell script editor.
- Choose Add and edit an current script and add the file you saved domestically.
- Select Create.

- On the Job particulars tab, enter a reputation in your AWS Glue job.
- For IAM function, select an current function or create a brand new function that has the required permissions for Amazon S3, AWS Glue, and Athena. The function wants to question the CloudTrail desk you created earlier and write to an output location.
You need to use the next pattern coverage code. Substitute the placeholders along with your CloudTrail logs bucket, output desk identify, output AWS Glue database, output S3 bucket, CloudTrail desk identify, AWS Glue database containing the CloudTrail desk, and your AWS account ID.
{
"Model": "2012-10-17",
"Assertion": [
{
"Action": [
"s3:List*",
"s3:Get*"
],
"Useful resource": [
"arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*",
"arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*"
],
"Impact": "Enable",
"Sid": "GetS3CloudtrailData"
},
{
"Motion": [
"glue:Get*",
"glue:BatchGet*"
],
"Useful resource": [
"arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog",
"arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>",
"arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*"
],
"Impact": "Enable",
"Sid": "GetGlueCatalogCloudtrailData"
},
{
"Motion": [
"s3:PutObject*",
"s3:Abort*",
"s3:DeleteObject*",
"s3:GetObject*",
"s3:GetBucket*",
"s3:List*",
"s3:Head*"
],
"Useful resource": [
"arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>",
"arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*"
],
"Impact": "Enable",
"Sid": "WriteOutputToS3"
},
{
"Motion": [
"glue:CreateTable",
"glue:CreatePartition",
"glue:UpdatePartition",
"glue:UpdateTable",
"glue:DeleteTable",
"glue:DeletePartition",
"glue:BatchCreatePartition",
"glue:BatchDeletePartition",
"glue:Get*",
"glue:BatchGet*"
],
"Useful resource": [
"arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog",
"arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>",
"arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*"
],
"Impact": "Enable",
"Sid": "AllowOutputToGlue"
},
{
"Motion": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Useful resource": "arn:aws:logs:*:*:/aws-glue/*",
"Impact": "Enable",
"Sid": "LogsAccess"
},
{
"Motion": [
"s3:GetObject*",
"s3:GetBucket*",
"s3:List*",
"s3:DeleteObject*",
"s3:PutObject",
"s3:PutObjectLegalHold",
"s3:PutObjectRetention",
"s3:PutObjectTagging",
"s3:PutObjectVersionTagging",
"s3:Abort*"
],
"Useful resource": [
"arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>",
"arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*"
],
"Impact": "Enable",
"Sid": "AccessToAthenaResults"
},
{
"Motion": [
"athena:StartQueryExecution",
"athena:StopQueryExecution",
"athena:GetDataCatalog",
"athena:GetQueryResults",
"athena:GetQueryExecution"
],
"Useful resource": [
"arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog",
"arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog",
"arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary"
],
"Impact": "Enable",
"Sid": "AllowAthenaQuerying"
}
]
}
For Python model, select Python 3.9.
- Choose Load frequent analytics libraries.
- For Information processing models, select 1 DPU.
- Go away the opposite choices as default or modify as wanted.

- Select Save to save lots of your job configuration.
Configure an Amazon MWAA DAG to orchestrate the AWS Glue job
The next code is for a DAG that may orchestrate the AWS Glue job that we created. We reap the benefits of the next key options on this DAG:
"""Pattern DAG"""
import airflow.utils
from airflow.suppliers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils
# permit backfills through DAG run parameters
process_date="{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}"
dag = DAG(
dag_id = "CLOUDTRAIL_LOGS_PROCESSING",
default_args = {
'depends_on_past':False,
'start_date':airflow.utils.dates.days_ago(0),
'retries':1,
'retry_delay':timedelta(minutes=5),
'catchup': False
},
schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday
dagrun_timeout = timedelta(minutes=30),
max_active_runs = 1,
max_active_tasks = 1 # since there is just one job in our DAG
)
## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator(
task_id="<<<some-task-id>>>",
job_name="<<<GLUE_JOB_NAME>>>",
script_args={
"--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>",
"--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>",
"--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>",
"--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>",
"--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # ought to exist already
"--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>",
"--PROCESS_DATE": process_date
},
region_name="us-east-1",
dag=dag,
verbose=True
)
glue_ingestion_job
Enhance observability of AWS Glue jobs in Amazon MWAA
The AWS Glue jobs write logs to Amazon CloudWatch. With the latest observability enhancements to Airflow’s Amazon supplier bundle, these logs at the moment are built-in with Airflow job logs. This consolidation offers Airflow customers with end-to-end visibility immediately within the Airflow UI, eliminating the necessity to search in CloudWatch or the AWS Glue console.
To make use of this characteristic, make sure the IAM function connected to the Amazon MWAA atmosphere has the next permissions to retrieve and write the mandatory logs:
{
"Model": "2012-10-17",
"Assertion": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:GetLogEvents",
"logs:GetLogRecord",
"logs:DescribeLogStreams",
"logs:FilterLogEvents",
"logs:GetLogGroupFields",
"logs:GetQueryResults",
],
"Useful resource": [
"arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name
]
}
]
}If verbose=true, the AWS Glue job run logs present within the Airflow job logs. The default is fake. For extra data, seek advice from Parameters.
When enabled, the DAGs learn from the AWS Glue job’s CloudWatch log stream and relay them to the Airflow DAG AWS Glue job step logs. This offers detailed insights into an AWS Glue job’s run in actual time through the DAG logs. Observe that AWS Glue jobs generate an output and error CloudWatch log group based mostly on the job’s STDOUT and STDERR, respectively. All logs within the output log group and exception or error logs from the error log group are relayed into Amazon MWAA.
AWS admins can now restrict a help staff’s entry to solely Airflow, making Amazon MWAA the only pane of glass on job orchestration and job well being administration. Beforehand, customers wanted to examine AWS Glue job run standing within the Airflow DAG steps and retrieve the job run identifier. They then wanted to entry the AWS Glue console to search out the job run historical past, seek for the job of curiosity utilizing the identifier, and eventually navigate to the job’s CloudWatch logs to troubleshoot.
Create the DAG
To create the DAG, full the next steps:
- Save the previous DAG code to a neighborhood .py file, changing the indicated placeholders.
The values in your AWS account ID, AWS Glue job identify, AWS Glue database with CloudTrail desk, and CloudTrail desk identify ought to already be identified. You may modify the output S3 bucket, output AWS Glue database, and output desk identify as wanted, however be certain the AWS Glue job’s IAM function that you just used earlier is configured accordingly.
- On the Amazon MWAA console, navigate to your atmosphere to see the place the DAG code is saved.
The DAGs folder is the prefix inside the S3 bucket the place your DAG file ought to be positioned.
- Add your edited file there.

- Open the Amazon MWAA console to verify that the DAG seems within the desk.

Run the DAG
To run the DAG, full the next steps:
- Select from the next choices:
- Set off DAG – This causes yesterday’s information for use as the info to course of
- Set off DAG w/ config – With this feature, you may move in a special date, doubtlessly for backfills, which is retrieved utilizing
dag_run.confwithin the DAG code after which handed into the AWS Glue job as a parameter

The next screenshot exhibits the extra configuration choices if you happen to select Set off DAG w/ config.

- Monitor the DAG because it runs.
- When the DAG is full, open the run’s particulars.
On the suitable pane, you may view the logs, or select Activity Occasion Particulars for a full view.

- View the AWS Glue job output logs in Amazon MWAA with out utilizing the AWS Glue console because of the
GlueJobOperatorverbose flag.

The AWS Glue job can have written outcomes to the output desk you specified.
- Question this desk through Athena to verify it was profitable.

Abstract
Amazon MWAA now offers a single place to trace AWS Glue job standing and allows you to use the Airflow console as the only pane of glass for job orchestration and well being administration. On this submit, we walked by means of the steps to orchestrate AWS Glue jobs through Airflow utilizing GlueJobOperator. With the brand new observability enhancements, you may seamlessly troubleshoot AWS Glue jobs in a unified expertise. We additionally demonstrated methods to improve your Amazon MWAA atmosphere to a suitable model, replace dependencies, and alter the IAM function coverage accordingly.
For extra details about frequent troubleshooting steps, seek advice from Troubleshooting: Creating and updating an Amazon MWAA atmosphere. For in-depth particulars of migrating to an Amazon MWAA atmosphere, seek advice from Upgrading from 1.10 to 2. To study in regards to the open-source code modifications for elevated observability of AWS Glue jobs within the Airflow Amazon supplier bundle, seek advice from the relay logs from AWS Glue jobs.
Lastly, we suggest visiting the AWS Massive Information Weblog for different materials on analytics, ML, and information governance on AWS.
Concerning the Authors
 Rushabh Lokhande is a Information & ML Engineer with the AWS Skilled Companies Analytics Observe. He helps prospects implement massive information, machine studying, and analytics options. Outdoors of labor, he enjoys spending time with household, studying, working, and golf.
Rushabh Lokhande is a Information & ML Engineer with the AWS Skilled Companies Analytics Observe. He helps prospects implement massive information, machine studying, and analytics options. Outdoors of labor, he enjoys spending time with household, studying, working, and golf.
 Ryan Gomes is a Information & ML Engineer with the AWS Skilled Companies Analytics Observe. He’s enthusiastic about serving to prospects obtain higher outcomes by means of analytics and machine studying options within the cloud. Outdoors of labor, he enjoys health, cooking, and spending high quality time with family and friends.
Ryan Gomes is a Information & ML Engineer with the AWS Skilled Companies Analytics Observe. He’s enthusiastic about serving to prospects obtain higher outcomes by means of analytics and machine studying options within the cloud. Outdoors of labor, he enjoys health, cooking, and spending high quality time with family and friends.
 Vishwa Gupta is a Senior Information Architect with the AWS Skilled Companies Analytics Observe. He helps prospects implement massive information and analytics options. Outdoors of labor, he enjoys spending time with household, touring, and making an attempt new meals.
Vishwa Gupta is a Senior Information Architect with the AWS Skilled Companies Analytics Observe. He helps prospects implement massive information and analytics options. Outdoors of labor, he enjoys spending time with household, touring, and making an attempt new meals.

{kind=link}