

In at present’s digital age, logging is a important side of utility improvement and administration, however effectively managing logs whereas complying with knowledge safety laws generally is a vital problem. Zoom, in collaboration with the AWS Information Lab workforce, developed an revolutionary structure to beat these challenges and streamline their logging and report deletion processes. On this submit, we discover the structure and the advantages it gives for Zoom and its customers.
Utility log challenges: Information administration and compliance
Utility logs are an integral part of any utility; they supply useful details about the utilization and efficiency of the system. These logs are used for a wide range of functions, reminiscent of debugging, auditing, efficiency monitoring, enterprise intelligence, system upkeep, and safety. Nonetheless, though these utility logs are obligatory for sustaining and enhancing the appliance, in addition they pose an attention-grabbing problem. These utility logs could include personally identifiable knowledge, reminiscent of consumer names, electronic mail addresses, IP addresses, and looking historical past, which creates an information privateness concern.
Legal guidelines such because the Common Information Safety Regulation (GDPR) and the California Client Privateness Act (CCPA) require organizations to retain utility logs for a selected time frame. The precise size of time required for knowledge storage varies relying on the particular regulation and the kind of knowledge being saved. The rationale for these knowledge retention durations is to make sure that firms aren’t holding private knowledge longer than obligatory, which might enhance the danger of information breaches and different safety incidents. This additionally helps be sure that firms aren’t utilizing private knowledge for functions apart from these for which it was collected, which could possibly be a violation of privateness legal guidelines. These legal guidelines additionally give people the fitting to request the deletion of their private knowledge, also referred to as the “proper to be forgotten.” People have the fitting to have their private knowledge erased, with out undue delay.
So, on one hand, organizations want to gather utility log knowledge to make sure the correct functioning of their providers, and hold the information for a selected time frame. However however, they could obtain requests from people to delete their private knowledge from the logs. This creates a balancing act for organizations as a result of they need to adjust to each knowledge retention and knowledge deletion necessities.
This problem turns into more and more difficult for bigger organizations that function in a number of international locations and states, as a result of every nation and state could have their very own guidelines and laws relating to knowledge retention and deletion. For instance, the Private Data Safety and Digital Paperwork Act (PIPEDA) in Canada and the Australian Privateness Act in Australia are related legal guidelines to GDPR, however they could have completely different retention durations or completely different exceptions. Due to this fact, organizations large or small should navigate this advanced panorama of information retention and deletion necessities, whereas additionally guaranteeing that they’re in compliance with all relevant legal guidelines and laws.
Zoom’s preliminary structure
Through the COVID-19 pandemic, using Zoom skyrocketed as increasingly folks had been requested to work and attend lessons from residence. The corporate needed to quickly scale its providers to accommodate the surge and labored with AWS to deploy capability throughout most Areas globally. With a sudden enhance within the giant variety of utility endpoints, they needed to quickly evolve their log analytics structure and labored with the AWS Information Lab workforce to rapidly prototype and deploy an structure for his or her compliance use case.
At Zoom, the information ingestion throughput and efficiency wants are very stringent. Information needed to be ingested from a number of thousand utility endpoints that produced over 30 million messages each minute, leading to over 100 TB of log knowledge per day. The prevailing ingestion pipeline consisted of writing the information to Apache Hadoop HDFS storage by Apache Kafka first after which operating every day jobs to maneuver the information to persistent storage. This took a number of hours whereas additionally slowing the ingestion and creating the potential for knowledge loss. Scaling the structure was additionally a problem as a result of HDFS knowledge must be moved round at any time when nodes had been added or eliminated. Moreover, transactional semantics on billions of information had been obligatory to assist meet compliance-related knowledge delete requests, and the present structure of every day batch jobs was operationally inefficient.
It was at the moment, by conversations with the AWS account workforce, that the AWS Information Lab workforce acquired concerned to help in constructing an answer for Zoom’s hyper-scale.
Answer overview
The AWS Information Lab provides accelerated, joint engineering engagements between clients and AWS technical sources to create tangible deliverables that speed up knowledge, analytics, synthetic intelligence (AI), machine studying (ML), serverless, and container modernization initiatives. The Information Lab has three choices: the Construct Lab, the Design Lab, and Resident Architect. Through the Construct and Design Labs, AWS Information Lab Options Architects and AWS specialists supported Zoom particularly by offering prescriptive architectural steerage, sharing finest practices, constructing a working prototype, and eradicating technical roadblocks to assist meet their manufacturing wants.
Zoom and the AWS workforce (collectively known as “the workforce” going ahead) recognized two main workflows for knowledge ingestion and deletion.
Information ingestion workflow
The next diagram illustrates the information ingestion workflow.

The workforce wanted to rapidly populate thousands and thousands of Kafka messages within the dev/check surroundings to attain this. To expedite the method, we (the workforce) opted to make use of Amazon Managed Streaming for Apache Kafka (Amazon MSK), which makes it easy to ingest and course of streaming knowledge in actual time, and we had been up and operating in beneath a day.
To generate check knowledge that resembled manufacturing knowledge, the AWS Information Lab workforce created a customized Python script that evenly populated over 1.2 billion messages throughout a number of Kafka partitions. To match the manufacturing setup within the improvement account, we needed to enhance the cloud quota restrict through a help ticket.
We used Amazon MSK and the Spark Structured Streaming functionality in Amazon EMR to ingest and course of the incoming Kafka messages with excessive throughput and low latency. Particularly, we inserted the information from the supply into EMR clusters at a most incoming charge of 150 million Kafka messages each 5 minutes, with every Kafka message holding 7–25 log knowledge information.
To retailer the information, we selected to make use of Apache Hudi because the desk format. We opted for Hudi as a result of it’s an open-source knowledge administration framework that gives record-level insert, replace, and delete capabilities on prime of an immutable storage layer like Amazon Easy Storage Service (Amazon S3). Moreover, Hudi is optimized for dealing with giant datasets and works effectively with Spark Structured Streaming, which was already getting used at Zoom.
After 150 million messages had been buffered, we processed the messages utilizing Spark Structured Streaming on Amazon EMR and wrote the information into Amazon S3 in Apache Hudi-compatible format each 5 minutes. We first flattened the message array, making a single report from the nested array of messages. Then we added a novel key, referred to as the Hudi report key, to every message. This key permits Hudi to carry out record-level insert, replace, and delete operations on the information. We additionally extracted the sphere values, together with the Hudi partition keys, from incoming messages.
This structure allowed end-users to question the information saved in Amazon S3 utilizing Amazon Athena with the AWS Glue Information Catalog or utilizing Apache Hive and Presto.
Information deletion workflow
The next diagram illustrates the information deletion workflow.
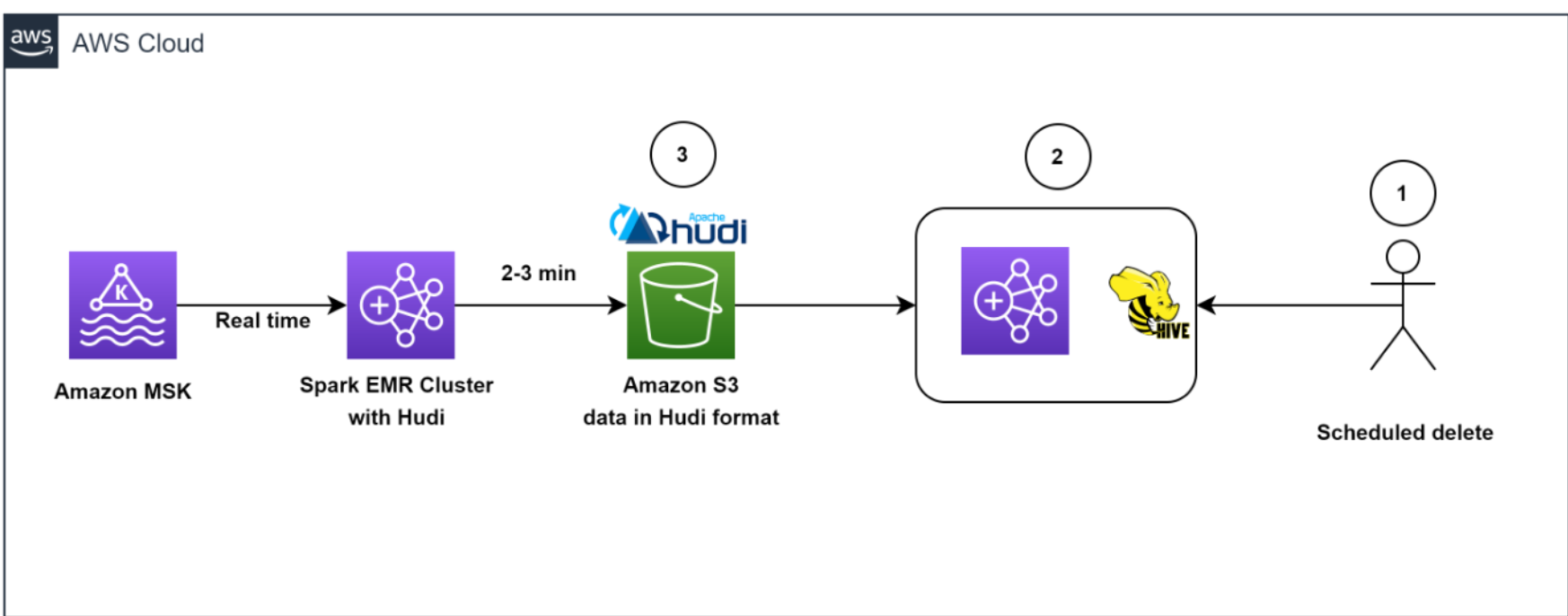
Our structure allowed for environment friendly knowledge deletions. To assist adjust to the customer-initiated knowledge retention coverage for GDPR deletes, scheduled jobs ran every day to establish the information to be deleted in batch mode.
We then spun up a transient EMR cluster to run the GDPR upsert job to delete the information. The information was saved in Amazon S3 in Hudi format, and Hudi’s built-in index allowed us to effectively delete information utilizing bloom filters and file ranges. As a result of solely these information that contained the report keys wanted to be learn and rewritten, it solely took about 1–2 minutes to delete 1,000 information out of the 1 billion information, which had beforehand taken hours to finish as whole partitions had been learn.
Total, our resolution enabled environment friendly deletion of information, which offered an extra layer of information safety that was important for Zoom, in gentle of its GDPR necessities.
Architecting to optimize scale, efficiency, and value
On this part, we share the next methods Zoom took to optimize scale, efficiency, and value:
- Optimizing ingestion
- Optimizing throughput and Amazon EMR utilization
- Decoupling ingestion and GDPR deletion utilizing EMRFS
- Environment friendly deletes with Apache Hudi
- Optimizing for low-latency reads with Apache Hudi
- Monitoring
Optimizing ingestion
To maintain the storage in Kafka lean and optimum, in addition to to get a real-time view of information, we created a Spark job to learn incoming Kafka messages in batches of 150 million messages and wrote to Amazon S3 in Hudi-compatible format each 5 minutes. Even throughout the preliminary phases of the iteration, once we hadn’t began scaling and tuning but, we had been capable of efficiently load all Kafka messages persistently beneath 2.5 minutes utilizing the Amazon EMR runtime for Apache Spark.
Optimizing throughput and Amazon EMR utilization
We launched a cost-optimized EMR cluster and switched from uniform occasion teams to utilizing EMR occasion fleets. We selected occasion fleets as a result of we would have liked the flexibleness to make use of Spot Cases for activity nodes and needed to diversify the danger of operating out of capability for a selected occasion kind in our Availability Zone.
We began experimenting with check runs by first altering the variety of Kafka partitions from 400 to 1,000, after which altering the variety of activity nodes and occasion varieties. Primarily based on the outcomes of the run, the AWS workforce got here up with the advice to make use of Amazon EMR with three core nodes (r5.16xlarge (64 vCPUs every)) and 18 activity nodes utilizing Spot fleet situations (a mix of r5.16xlarge (64 vCPUs), r5.12xlarge (48 vCPUs), r5.8xlarge (32 vCPUs)). These suggestions helped Zoom to cut back their Amazon EMR prices by greater than 80% whereas assembly their desired efficiency objectives of ingesting 150 million Kafka messages beneath 5 minutes.
Decoupling ingestion and GDPR deletion utilizing EMRFS
A well known good thing about separation of storage and compute is that you may scale the 2 independently. However a not-so-obvious benefit is that you may decouple steady workloads from sporadic workloads. Beforehand knowledge was saved in HDFS. Useful resource-intensive GDPR delete jobs and knowledge motion jobs would compete for sources with the stream ingestion, inflicting a backlog of greater than 5 hours in upstream Kafka clusters, which was near filling up the Kafka storage (which solely had 6 hours of information retention) and doubtlessly inflicting knowledge loss. Offloading knowledge from HDFS to Amazon S3 allowed us the liberty to launch impartial transient EMR clusters on demand to carry out knowledge deletion, serving to to make sure that the continuing knowledge ingestion from Kafka into Amazon EMR just isn’t starved for sources. This enabled the system to ingest knowledge each 5 minutes and full every Spark Streaming learn in 2–3 minutes. One other facet impact of utilizing EMRFS is a cost-optimized cluster, as a result of we eliminated reliance on Amazon Elastic Block Retailer (Amazon EBS) volumes for over 300 TB storage that was used for 3 copies (together with two replicas) of HDFS knowledge. We now pay for just one copy of the information in Amazon S3, which gives 11 9s of sturdiness and is comparatively cheap storage.
Environment friendly deletes with Apache Hudi
What concerning the battle between ingest writes and GDPR deletes when operating concurrently? That is the place the ability of Apache Hudi stands out.
Apache Hudi gives a desk format for knowledge lakes with transactional semantics that permits the separation of ingestion workloads and updates when run concurrently. The system was capable of persistently delete 1,000 information in lower than a minute. There have been some limitations in concurrent writes in Apache Hudi 0.7.0, however the Amazon EMR workforce rapidly addressed this by back-porting Apache Hudi 0.8.0, which helps optimistic concurrency management, to the present (on the time of the AWS Information Lab collaboration) Amazon EMR 6.4 launch. This saved time in testing and allowed for a fast transition to the brand new model with minimal testing. This enabled us to question the information straight utilizing Athena rapidly with out having to spin up a cluster to run advert hoc queries, in addition to to question the information utilizing Presto, Trino, and Hive. The decoupling of the storage and compute layers offered the flexibleness to not solely question knowledge throughout completely different EMR clusters, but additionally delete knowledge utilizing a very impartial transient cluster.
Optimizing for low-latency reads with Apache Hudi
To optimize for low-latency reads with Apache Hudi, we would have liked to deal with the difficulty of too many small information being created inside Amazon S3 because of the steady streaming of information into the information lake.
We utilized Apache Hudi’s options to tune file sizes for optimum querying. Particularly, we lowered the diploma of parallelism in Hudi from the default worth of 1,500 to a decrease quantity. Parallelism refers back to the variety of threads used to jot down knowledge to Hudi; by lowering it, we had been capable of create bigger information that had been extra optimum for querying.
As a result of we would have liked to optimize for high-volume streaming ingestion, we selected to implement the merge on learn desk kind (as a substitute of copy on write) for our workload. This desk kind allowed us to rapidly ingest the incoming knowledge into delta information in row format (Avro) and asynchronously compact the delta information into columnar Parquet information for quick reads. To do that, we ran the Hudi compaction job within the background. Compaction is the method of merging row-based delta information to provide new variations of columnar information. As a result of the compaction job would use extra compute sources, we adjusted the diploma of parallelism for insertion to a decrease worth of 1,000 to account for the extra useful resource utilization. This adjustment allowed us to create bigger information with out sacrificing efficiency throughput.
Total, our method to optimizing for low-latency reads with Apache Hudi allowed us to raised handle file sizes and enhance the general efficiency of our knowledge lake.
Monitoring
The workforce monitored MSK clusters with Prometheus (an open-source monitoring software). Moreover, we showcased tips on how to monitor Spark streaming jobs utilizing Amazon CloudWatch metrics. For extra data, consult with Monitor Spark streaming purposes on Amazon EMR.
Outcomes
The collaboration between Zoom and the AWS Information Lab demonstrated vital enhancements in knowledge ingestion, processing, storage, and deletion utilizing an structure with Amazon EMR and Apache Hudi. One key good thing about the structure was a discount in infrastructure prices, which was achieved by using cloud-native applied sciences and the environment friendly administration of information storage. One other profit was an enchancment in knowledge administration capabilities.
We confirmed that the prices of EMR clusters will be lowered by about 82% whereas bringing the storage prices down by about 90% in comparison with the prior HDFS-based structure. All of this whereas making the information out there within the knowledge lake inside 5 minutes of ingestion from the supply. We additionally demonstrated that knowledge deletions from an information lake containing a number of petabytes of information will be carried out rather more effectively. With our optimized method, we had been capable of delete roughly 1,000 information in simply 1–2 minutes, as in comparison with the beforehand required 3 hours or extra.
Conclusion
In conclusion, the log analytics course of, which entails amassing, processing, storing, analyzing, and deleting log knowledge from numerous sources reminiscent of servers, purposes, and gadgets, is important to help organizations in working to satisfy their service resiliency, safety, efficiency monitoring, troubleshooting, and compliance wants, reminiscent of GDPR.
This submit shared what Zoom and the AWS Information Lab workforce have achieved collectively to unravel important knowledge pipeline challenges, and Zoom has prolonged the answer additional to optimize extract, remodel, and cargo (ETL) jobs and useful resource effectivity. Nonetheless, you can too use the structure patterns offered right here to rapidly construct cost-effective and scalable options for different use circumstances. Please attain out to your AWS workforce for extra data or contact Gross sales.
Concerning the Authors
 Sekar Srinivasan is a Sr. Specialist Options Architect at AWS targeted on Massive Information and Analytics. Sekar has over 20 years of expertise working with knowledge. He’s enthusiastic about serving to clients construct scalable options modernizing their structure and producing insights from their knowledge. In his spare time he likes to work on non-profit initiatives targeted on underprivileged Youngsters’s schooling.
Sekar Srinivasan is a Sr. Specialist Options Architect at AWS targeted on Massive Information and Analytics. Sekar has over 20 years of expertise working with knowledge. He’s enthusiastic about serving to clients construct scalable options modernizing their structure and producing insights from their knowledge. In his spare time he likes to work on non-profit initiatives targeted on underprivileged Youngsters’s schooling.
 Chandra Dhandapani is a Senior Options Architect at AWS, the place he makes a speciality of creating options for purchasers in Analytics, AI/ML, and Databases. He has loads of expertise in constructing and scaling purposes throughout completely different industries together with Healthcare and Fintech. Exterior of labor, he’s an avid traveler and enjoys sports activities, studying, and leisure.
Chandra Dhandapani is a Senior Options Architect at AWS, the place he makes a speciality of creating options for purchasers in Analytics, AI/ML, and Databases. He has loads of expertise in constructing and scaling purposes throughout completely different industries together with Healthcare and Fintech. Exterior of labor, he’s an avid traveler and enjoys sports activities, studying, and leisure.
 Amit Kumar Agrawal is a Senior Options Architect at AWS, primarily based out of San Francisco Bay Space. He works with giant strategic ISV clients to architect cloud options that handle their enterprise challenges. Throughout his free time he enjoys exploring the outside together with his household.
Amit Kumar Agrawal is a Senior Options Architect at AWS, primarily based out of San Francisco Bay Space. He works with giant strategic ISV clients to architect cloud options that handle their enterprise challenges. Throughout his free time he enjoys exploring the outside together with his household.
 Viral Shah is a Analytics Gross sales Specialist working with AWS for five years serving to clients to achieve success of their knowledge journey. He has over 20+ years of expertise working with enterprise clients and startups, primarily within the knowledge and database house. He likes to journey and spend high quality time together with his household.
Viral Shah is a Analytics Gross sales Specialist working with AWS for five years serving to clients to achieve success of their knowledge journey. He has over 20+ years of expertise working with enterprise clients and startups, primarily within the knowledge and database house. He likes to journey and spend high quality time together with his household.

{kind=link}