
Think about using to work in your self-driving automotive. As you method a cease signal, as an alternative of stopping, the automotive hastens and goes by way of the cease signal as a result of it interprets the cease signal as a pace restrict signal. How did this occur? Although the automotive’s machine studying (ML) system was educated to acknowledge cease indicators, somebody added stickers to the cease signal, which fooled the automotive into considering it was a 45-mph pace restrict signal. This easy act of placing stickers on a cease signal is one instance of an adversarial assault on ML methods.
On this SEI Weblog publish, I study how ML methods might be subverted and, on this context, clarify the idea of adversarial machine studying. I additionally study the motivations of adversaries and what researchers are doing to mitigate their assaults. Lastly, I introduce a primary taxonomy delineating the methods by which an ML mannequin might be influenced and present how this taxonomy can be utilized to tell fashions which are strong towards adversarial actions.
What’s Adversarial Machine Studying?
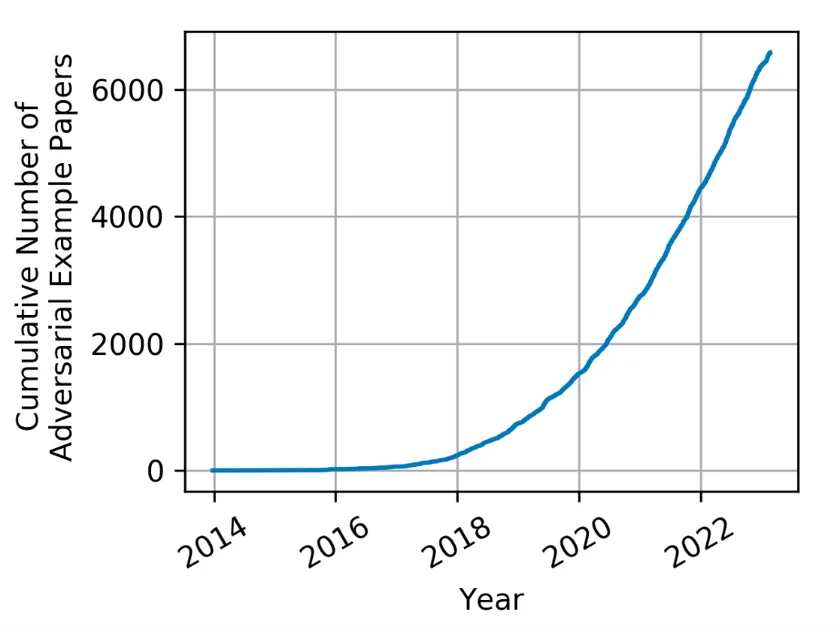
The idea of adversarial machine studying has been round for a very long time, however the time period has solely not too long ago come into use. With the explosive progress of ML and synthetic intelligence (AI), adversarial ways, methods, and procedures have generated loads of curiosity and have grown considerably.
When ML algorithms are used to construct a prediction mannequin after which built-in into AI methods, the main focus is often on maximizing efficiency and guaranteeing the mannequin’s capacity to make correct predictions (that’s, inference). This deal with functionality typically makes safety a secondary concern to different priorities, comparable to correctly curated datasets for coaching fashions, the usage of correct ML algorithms acceptable to the area, and tuning the parameters and configurations to get the most effective outcomes and chances. However analysis has proven that an adversary can exert an affect on an ML system by manipulating the mannequin, information, or each. By doing so, an adversary can then power an ML system to
- study the unsuitable factor
- do the unsuitable factor
- reveal the unsuitable factor
To counter these actions, researchers categorize the spheres of affect an adversary can have on a mannequin right into a easy taxonomy of what an adversary can accomplish or what a defender must defend towards.
How Adversaries Search to Affect Fashions
To make an ML mannequin study the unsuitable factor, adversaries take purpose on the mannequin’s coaching information, any foundational fashions, or each. Adversaries exploit this class of vulnerabilities to affect fashions utilizing strategies, comparable to information and parameter manipulation, which practitioners time period poisoning. Poisoning assaults trigger a mannequin to incorrectly study one thing that the adversary can exploit at a future time. For instance, an attacker would possibly use information poisoning methods to deprave a provide chain for a mannequin designed to categorise site visitors indicators. The attacker may exploit threats to the information by inserting triggers into coaching information that may affect future mannequin conduct in order that the mannequin misclassifies a cease signal as a pace restrict signal when the set off is current (Determine 2). A provide chain assault is efficient when a foundational mannequin is poisoned after which posted for others to obtain. Fashions which are poisoned from provide chain kind of assaults can nonetheless be prone to the embedded triggers ensuing from poisoning the information.

Attackers can even manipulate ML methods into doing the unsuitable factor. This class of vulnerabilities causes a mannequin to carry out in an sudden method. As an example, assaults might be designed to trigger a classification mannequin to misclassify through the use of an adversarial sample that implements an evasion assault. Ian Goodfellow, Jonathon Shlens, and Christian Szegedy produced one of many seminal works of analysis on this space. They added an imperceptible-to-humans adversarial noise sample to a picture, which forces an ML mannequin to misclassify the picture. The researchers took a picture of a panda that the ML mannequin labeled correctly, then generated and utilized a particular noise sample to the picture. The ensuing picture gave the impression to be the identical Panda to a human observer (Determine 3). Nevertheless, when this picture was labeled by the ML mannequin, it produced a prediction results of gibbon, thus inflicting the mannequin to do the unsuitable factor.

Lastly, adversaries may cause ML to reveal the unsuitable factor. On this class of vulnerabilities, an adversary makes use of an ML mannequin to disclose some side of the mannequin, or the coaching dataset, that the mannequin’s creator didn’t intend to disclose. Adversaries can execute these assaults in a number of methods. In a mannequin extraction assault, an adversary can create a replica of a mannequin that the creator desires to maintain non-public. To execute this assault, the adversary solely wants to question a mannequin and observe the outputs. This class of assault is regarding to ML-enabled utility programming interface (API) suppliers since it may possibly allow a buyer to steal the mannequin that allows the API.
Adversaries use mannequin inversion assaults to disclose details about the dataset that was used to coach a mannequin. If the adversaries can acquire a greater understanding of the courses and the non-public dataset used, they will use this info to open a door for a follow-on assault or to compromise the privateness of coaching information. The idea of mannequin inversion was illustrated by Matt Fredrikson et al. of their paper Mannequin Inversion Assaults that Exploit Confidence Data and Primary Countermeasures, which examined a mannequin educated with a dataset of faces.
On this paper the authors demonstrated how an adversary makes use of a mannequin inversion assault to show an preliminary random noise sample right into a face from the ML system. The adversary does so through the use of a generated noise sample as an enter to a educated mannequin after which utilizing conventional ML mechanisms to repetitively information the refinement of the sample till the boldness stage will increase. Utilizing the outcomes of the mannequin as a information, the noise sample finally begins wanting like a face. When this face was introduced to human observers, they have been in a position to hyperlink it again to the unique particular person with better than 80 p.c accuracy (Determine 4).

Defending In opposition to Adversarial AI
Defending a machine studying system towards an adversary is a tough drawback and an space of energetic analysis with few confirmed generalizable options. Whereas generalized and confirmed defenses are uncommon, the adversarial ML analysis neighborhood is tough at work producing particular defenses that may be utilized to guard towards particular assaults. Growing take a look at and analysis pointers will assist practitioners establish flaws in methods and consider potential defenses. This space of analysis has developed right into a race within the adversarial ML analysis neighborhood by which defenses are proposed by one group after which disproved by others utilizing current or newly developed strategies. Nevertheless, the plethora of things influencing the effectiveness of any defensive technique preclude articulating a easy menu of defensive methods geared to the assorted strategies of assault. Slightly, we now have targeted on robustness testing.
ML fashions that efficiently defend towards assaults are sometimes assumed to be strong, however the robustness of ML fashions have to be proved by way of take a look at and analysis. The ML neighborhood has began to define the situations and strategies for performing robustness evaluations on ML fashions. The primary consideration is to outline the situations underneath which the protection or adversarial analysis will function. These situations ought to have a acknowledged purpose, a practical set of capabilities your adversary has at its disposal, and a top level view of how a lot information the adversary has of the system.
Subsequent, it’s best to guarantee your evaluations are adaptive. Particularly, each analysis ought to construct upon prior evaluations but in addition be unbiased and symbolize a motivated adversary. This method permits a holistic analysis that takes all info under consideration and isn’t overly targeted on one error occasion or set of analysis situations.
Lastly, scientific requirements of reproducibility ought to apply to your analysis. For instance, you need to be skeptical of any outcomes obtained and vigilant in proving the outcomes are right and true. The outcomes obtained needs to be repeatable, reproducible, and never depending on any particular situations or environmental variables that prohibit unbiased replica.
The Adversarial Machine Studying Lab on the SEI’s AI Division is researching the event of defenses towards adversarial assaults. We leverage our experience with adversarial machine studying to enhance mannequin robustness and the testing, measurement, and robustness of ML fashions. We encourage anybody fascinated about studying extra about how we are able to assist your machine studying efforts to achieve out to us at data@sei.cmu.edu.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}