

Amazon Redshift Serverless makes it straightforward to run and scale analytics in seconds with out the necessity to setup and handle information warehouse clusters. With Redshift Serverless, customers resembling information analysts, builders, enterprise professionals, and information scientists can get insights from information by merely loading and querying information within the information warehouse.
With Redshift Serverless, you may profit from the next options:
- Entry and analyze information with out the necessity to arrange, tune, and handle Amazon Redshift clusters
- Use Amazon Redshift’s SQL capabilities, industry-leading efficiency, and information lake integration to seamlessly question information throughout an information warehouse, information lake, and databases
- Ship persistently excessive efficiency and simplified operations for even essentially the most demanding and unstable workloads with clever and computerized scaling, with out under-provisioning or over-provisioning the compute assets
- Pay for the compute solely when the info warehouse is in use
On this publish, we focus on 4 totally different use circumstances of Redshift Serverless:
- Straightforward analytics – A startup firm must create a brand new information warehouse and experiences for advertising and marketing analytics. They’ve very restricted IT assets, and must get began shortly and simply with minimal infrastructure or administrative overhead.
- Self-service analytics – An current Amazon Redshift buyer has a provisioned Amazon Redshift cluster that’s right-sized for his or her present workload. A brand new staff wants fast self-service entry to the Amazon Redshift information to create forecasting and predictive fashions for the enterprise.
- Optimize workload efficiency – An current Amazon Redshift buyer is trying to optimize the efficiency of their variable reporting workloads throughout peak time.
- Value-optimization of sporadic workloads – An current buyer is trying to optimize the price of their Amazon Redshift producer cluster with sporadic batch ingestion workloads.
Straightforward analytics
In our first use case, a startup firm with restricted assets must create a brand new information warehouse and experiences for advertising and marketing analytics. The client doesn’t have any IT directors, and their employees is comprised of information analysts, an information scientist, and enterprise analysts. They need to create new advertising and marketing analytics shortly and simply, to find out the ROI and effectiveness of their advertising and marketing efforts. Given their restricted assets, they need minimal infrastructure and administrative overhead.
On this case, they will use Redshift Serverless to fulfill their wants. They’ll create a brand new Redshift Serverless endpoint in a couple of minutes and cargo their preliminary few TBs of selling dataset into Redshift Serverless shortly. Their information analysts, information scientists, and enterprise analysts can begin querying and analyzing the info with ease and derive enterprise insights shortly with out worrying about infrastructure, tuning, and administrative duties.
Getting began with Redshift Serverless is straightforward and fast. On the Get began with Amazon Redshift Serverless web page, you may choose the Use default settings possibility, which can create a default namespace and workgroup with the default settings, as proven within the following screenshots.

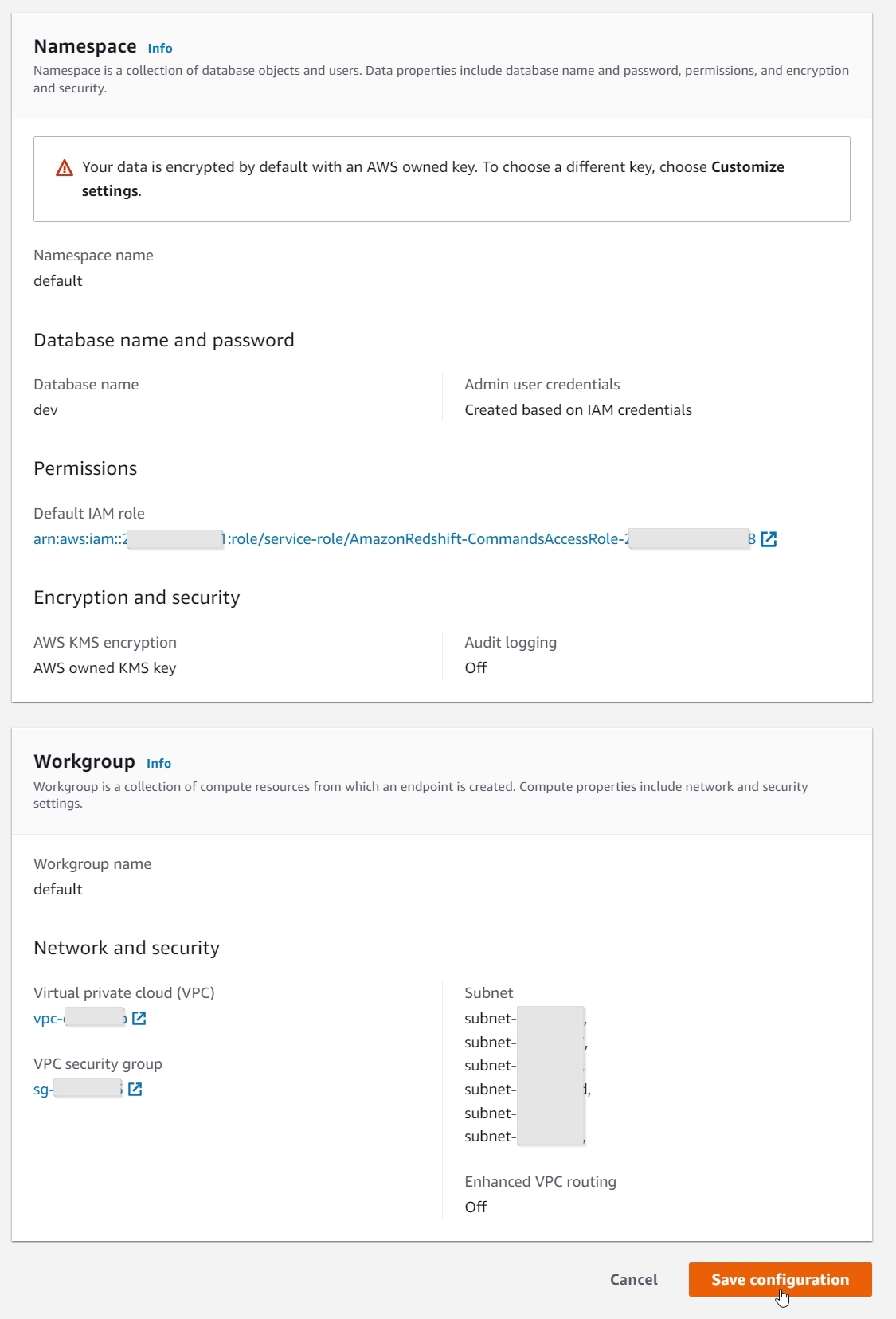
With only a single click on, you may create a brand new Redshift Serverless endpoint in minutes with information encryption enabled, and a default AWS Identification and Entry Administration (IAM) function, VPC, and safety group connected. You may also use the Customise settings choice to override these settings, if desired.
When the Redshift Serverless endpoint is on the market, select Question information to launch the Amazon Redshift Question Editor v2.
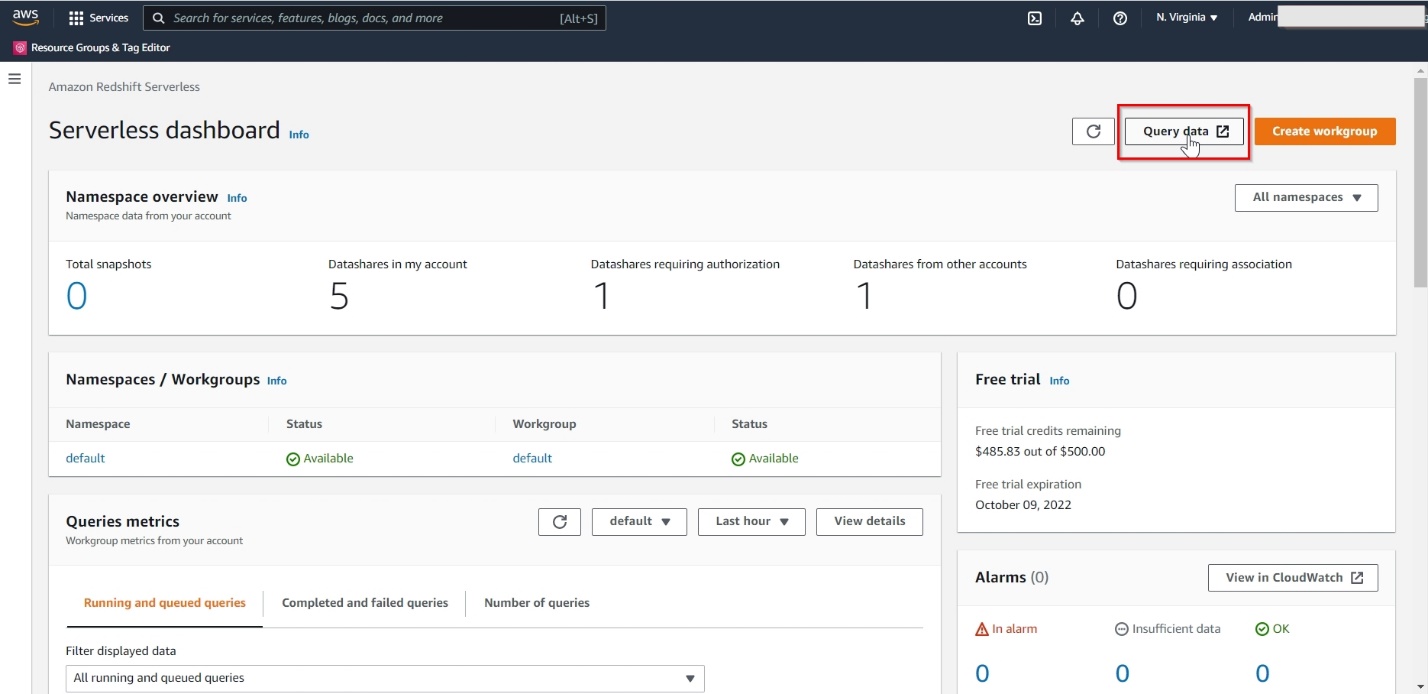
Question Editor v2 makes it straightforward to create database objects, load information, analyze and visualize information, and share and collaborate together with your groups.
The next screenshot illustrates creating new database tables utilizing the UI.
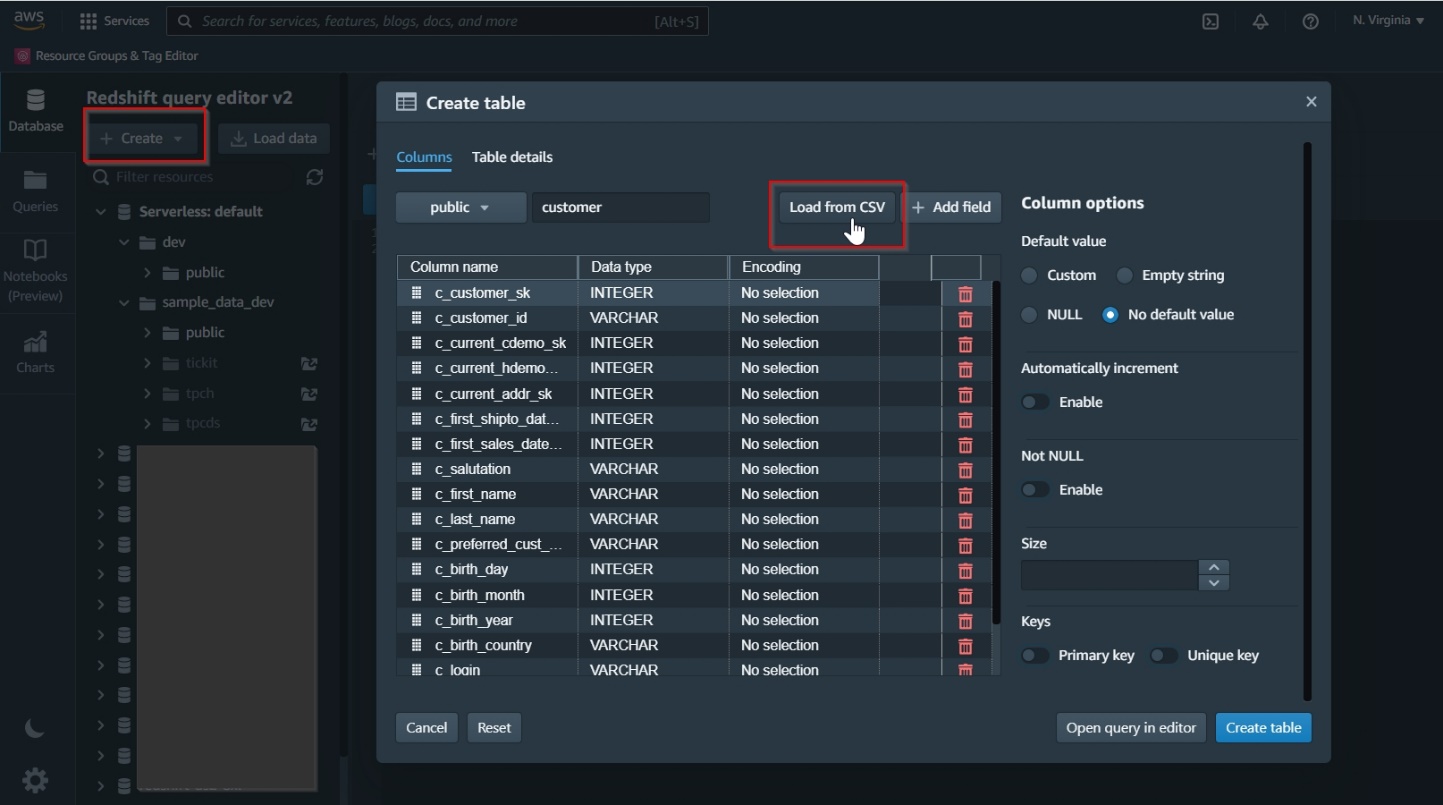
The next screenshot demonstrates loading information from Amazon Easy Storage Service (Amazon S3) utilizing the UI.

The next screenshot exhibits an instance of analyzing and visualizing information.

Discuss with the video Get Began with Amazon Redshift Serverless to learn to arrange a brand new Redshift Serverless endpoint and begin analyzing your information in minutes.
Self-service analytics
In one other use case, a buyer is presently utilizing an Amazon Redshift provisioned cluster that’s right-sized for his or her present workloads. A brand new information science staff needs fast entry to the Amazon Redshift cluster information for a brand new workload that can construct predictive fashions for forecasting. The brand new staff members don’t know but how lengthy they may want entry and the way advanced their queries will probably be.
Including the brand new information science group to the present cluster introduced the next challenges:
- The extra compute capability wants of the brand new staff are unknown and exhausting to estimate
- As a result of the present cluster assets are optimally utilized, they should guarantee workload isolation to help the wants of the brand new staff with out impacting current workloads
- A chargeback or value allocation mannequin is desired for the assorted groups consuming information
To handle these points, they resolve to let the info science staff create their very own new Redshift Serverless occasion and grant them information share entry to the info they want from the prevailing Amazon Redshift provisioned cluster. The next diagram illustrates the brand new structure.
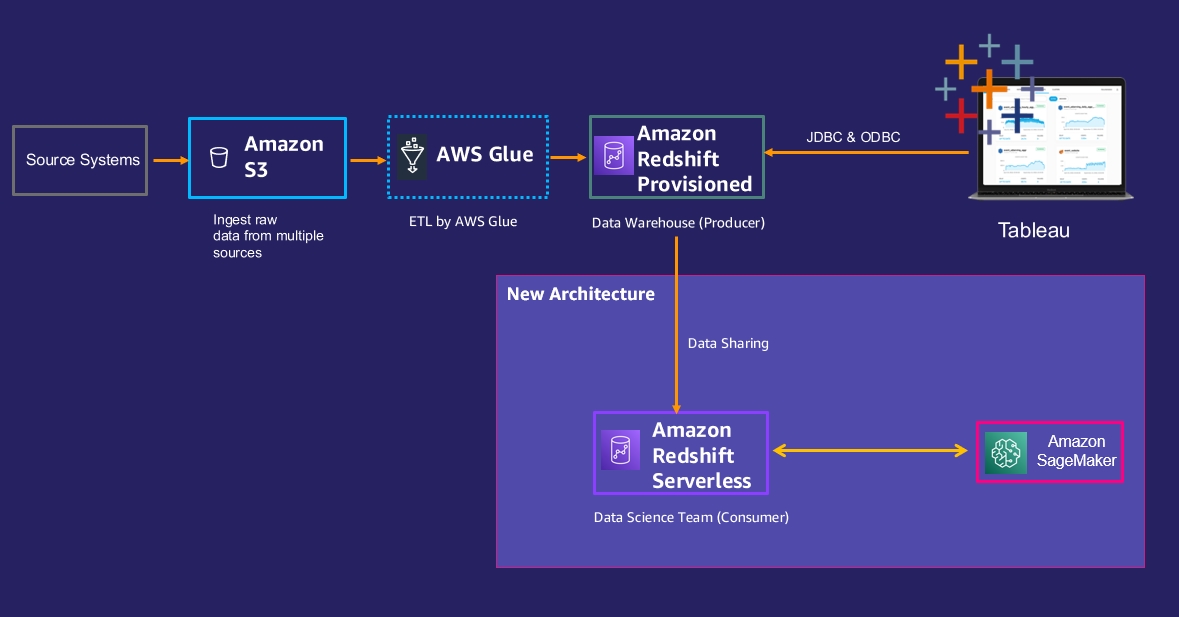
The next steps have to be carried out to implement this structure:
- The information science staff can create a brand new Redshift Serverless endpoint, as described within the earlier use case.
- Allow information sharing between the Amazon Redshift provisioned cluster (producer) and the info science Redshift Serverless endpoint (client) utilizing these high-level steps:
- Create a brand new information share.
- Add a schema to the info share.
- Add objects you need to share to the info share.
- Grant utilization on this information share to the Redshift Serverless client namespace, utilizing the Redshift Serverless endpoint’s namespace ID.
- Notice that the Redshift Serverless endpoint is encrypted by default; the provisioned Redshift producer cluster additionally must be encrypted for information sharing to work between them.
The next screenshot exhibits pattern SQL instructions to allow information sharing on the Amazon Redshift provisioned producer cluster.

On the Amazon Redshift Serverless client, create a database from the info share after which question the shared objects.
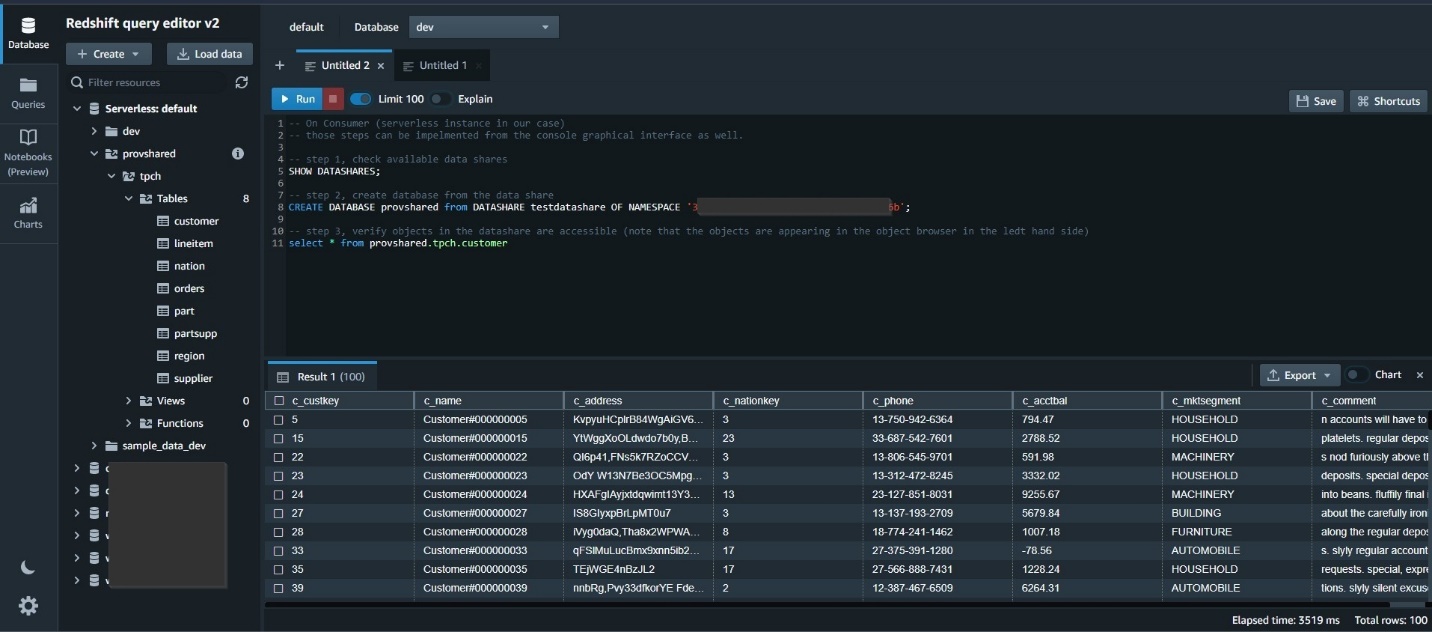
For extra particulars about configuring Amazon Redshift information sharing, consult with Sharing Amazon Redshift information securely throughout Amazon Redshift clusters for workload isolation.
With this structure, we are able to resolve the three challenges talked about earlier:
- Redshift Serverless permits the info science staff to create a brand new Amazon Redshift database with out worrying about capability wants, and arrange information sharing with the Amazon Redshift provisioned producer cluster inside half-hour. This tackles the primary problem.
- Amazon Redshift information sharing means that you can share dwell, transactionally constant information throughout provisioned and Serverless Redshift databases, and information sharing may even occur when the producer is paused. The brand new workload is remoted and runs by itself compute assets, with out impacting the efficiency of the Amazon Redshift provisioned producer cluster. This addresses the second problem.
- Redshift Serverless isolates the price of the brand new workload to the brand new staff and allows a simple chargeback mannequin. This tackles the third problem.
Optimized workload efficiency
For our third use case, an Amazon Redshift buyer utilizing an Amazon Redshift provisioned cluster is in search of efficiency optimization throughout peak occasions for his or her workload. They want an answer to handle dynamic workloads with out over-provisioning or under-provisioning assets and construct a scalable structure.
An evaluation of the workload on the cluster exhibits that the cluster has two totally different workloads:
- The primary workload is streaming ingestion, which runs steadily through the day.
- The second workload is reporting, which runs on an advert hoc foundation through the day with some scheduled jobs through the night time. It was famous that the reporting jobs run wherever between 8–12 hours every day.
The provisioned cluster was sized as 12 nodes of ra3.4xlarge to deal with each workloads operating in parallel.
To optimize these workloads, the next structure was proposed and applied:
- Configure an Amazon Redshift provisioned cluster with simply 4 nodes of ra3.4xlarge, to deal with the streaming ingestion workload solely. The next screenshots illustrate how to do that on the Amazon Redshift console, through an elastic resize operation of the prevailing Amazon Redshift provisioned cluster by decreasing variety of nodes from 12 to 4:


- Create a brand new Redshift Serverless endpoint to be utilized by the reporting workload with 128 RPU (Redshift Processing Models) in lieu of 8 nodes ra3.4xlarge. For extra particulars about organising Redshift Serverless, consult with the primary use case concerning straightforward analytics.
- Allow information sharing between the Amazon Redshift provisioned cluster because the producer and Redshift Serverless as the patron utilizing the serverless namespace ID, just like the way it was configured earlier within the self-service analytics use case. For extra details about easy methods to configure Amazon Redshift information sharing, consult with Sharing Amazon Redshift information securely throughout Amazon Redshift clusters for workload isolation.
The next diagram compares the present structure and the brand new structure utilizing Redshift Serverless.
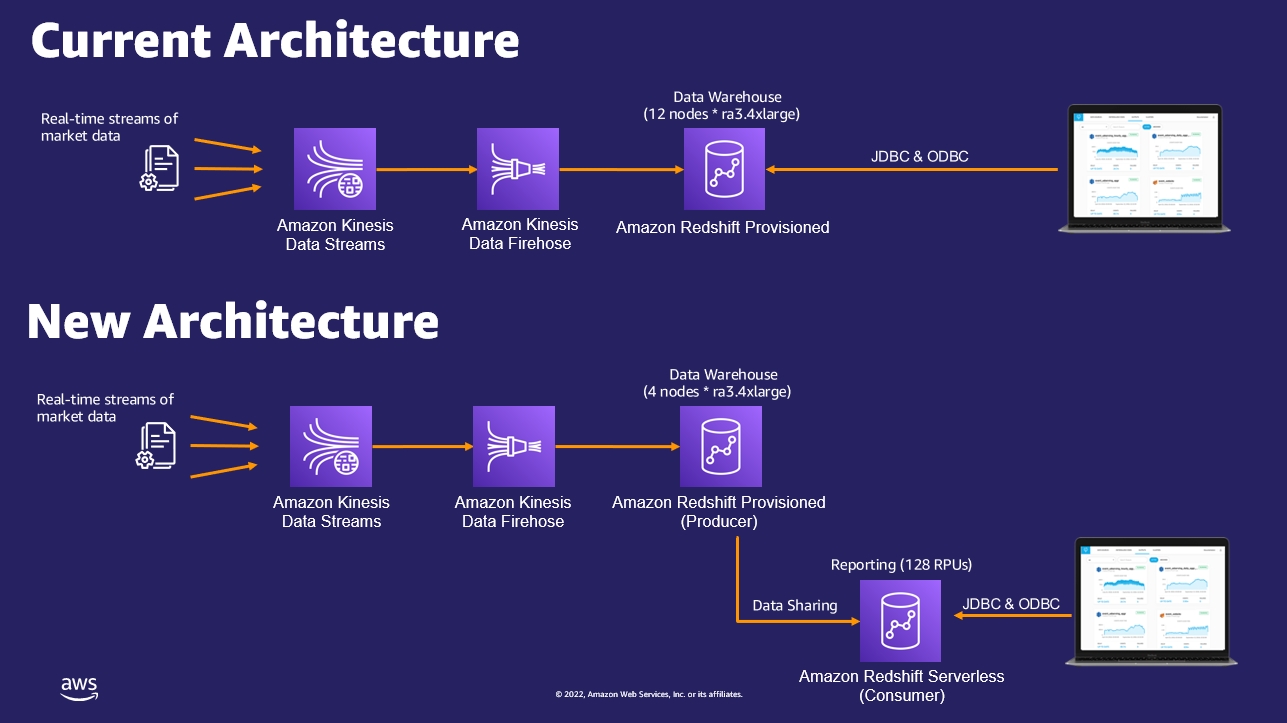
After finishing this setup, the shopper ran the streaming ingestion workload on the Amazon Redshift provisioned occasion (producer) and reporting workloads on Redshift Serverless (client) based mostly on the beneficial structure. The next enhancements had been noticed:
- The streaming ingestion workload carried out the identical because it did on the previous 12-node Amazon Redshift provisioned cluster.
- Reporting customers noticed a efficiency enchancment of 30% through the use of Redshift Serverless. It was capable of scale compute assets dynamically inside seconds, as further advert hoc customers ran experiences and queries with out impacting the streaming ingestion workload.
- This structure sample is expandable so as to add extra shoppers like information scientists, by organising one other Redshift Serverless occasion as a brand new client.
Value-optimization
In our closing use case, a buyer is utilizing an Amazon Redshift provisioned cluster as a producer to ingest information from totally different sources. The information is then shared with different Amazon Redshift provisioned client clusters for information science modeling and reporting functions.
Their present Amazon Redshift provisioned producer cluster has 8 nodes of ra3.4xlarge and is positioned within the us-east-1 Area. The information supply from the totally different information sources is scattered between midnight to eight:00 AM, and the info ingestion jobs take round 3 hours to run in whole daily. The client is presently on the on-demand value mannequin and has scheduled every day jobs to pause and resume the cluster to reduce prices. The cluster resumes daily at midnight and pauses at 8:00 AM, with a complete runtime of 8 hours a day.
The present annual value of this cluster is one year * 8 hours * 8 nodes * $3.26 (node value per hour) = $76,153.6 per 12 months.
To optimize the price of this workload, the next structure was proposed and applied:
- Arrange a brand new Redshift Serverless endpoint with 64 RPU as the bottom configuration to be utilized by the info ingestion producer staff. For extra details about organising Redshift Serverless, consult with the primary use case concerning straightforward analytics.
- Restore the most recent snapshot from the prevailing Amazon Redshift provisioned producer cluster into Redshift Serverless by selecting the Restore to serverless namespace possibility, as proven within the following screenshot.
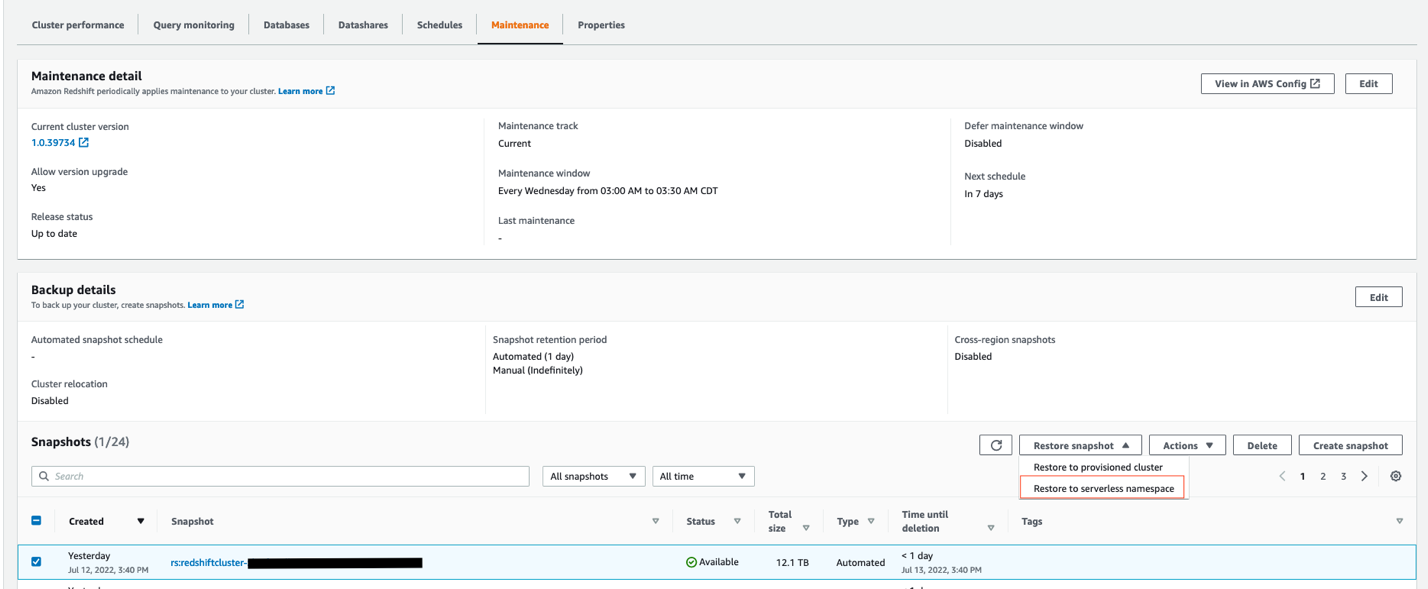
- Allow information sharing between Redshift Serverless because the producer and the Amazon Redshift provisioned cluster as the patron, just like the way it was configured earlier within the self-service analytics use case.
The next diagram compares the present structure to the brand new structure.
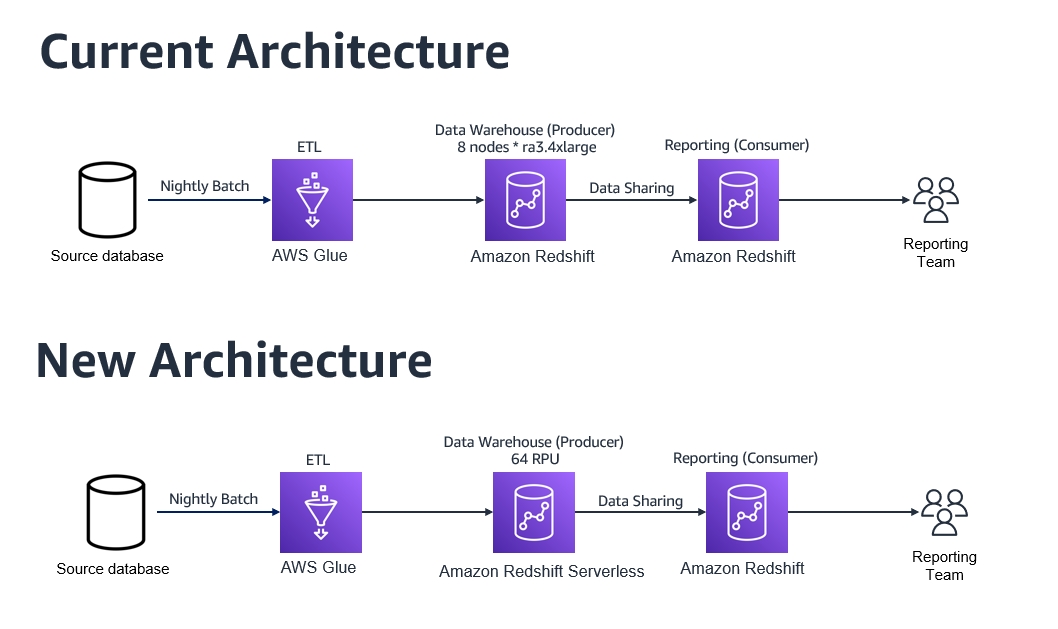
By shifting to Redshift Serverless, the shopper realized the next advantages:
- Value financial savings – With Redshift Serverless, the shopper pays for compute solely when the info warehouse is in use. On this situation, the shopper noticed a financial savings of as much as 65% on their annual prices through the use of Redshift Serverless because the producer, whereas nonetheless getting higher efficiency on their workloads. The Redshift Serverless annual value on this case equals one year * 3 hours * 64 RPUs * $0.375 (RPU value per hour) = $26,280, in comparison with $76,153.6 for his or her former provisioned producer cluster. Additionally, the Redshift Serverless 64 RPU baseline configuration provides the shopper extra compute assets than their former 8 nodes of ra3.4xlarge cluster, leading to higher efficiency total.
- Much less administration overhead – As a result of the shopper doesn’t want to fret about pausing and resuming their Amazon Redshift cluster any extra, the administration of their information warehouse is simplified by shifting their producer Amazon Redshift cluster to Redshift Serverless.
Conclusion
On this publish, we mentioned 4 totally different use circumstances, demonstrating the advantages of Amazon Redshift Serverless—from its straightforward analytics, ease of use, superior efficiency, and value financial savings that may be realized from the pay-per-use pricing mannequin.
Amazon Redshift offers flexibility and selection in information warehousing. Amazon Redshift Provisioned is a superb selection for patrons who want a customized provisioning surroundings with extra granular controls; and with Redshift Serverless, you can begin new information warehousing workloads in minutes with dynamic auto scaling, no infrastructure administration, and a pay-per-use pricing mannequin.
We encourage you to begin utilizing Amazon Redshift Serverless at present and benefit from the many advantages it provides.
In regards to the Authors
 Ahmed Shehata is a Information Warehouse Specialist Options Architect with Amazon Internet Companies, based mostly out of Toronto.
Ahmed Shehata is a Information Warehouse Specialist Options Architect with Amazon Internet Companies, based mostly out of Toronto.
 Manish Vazirani is an Analytics Platform Specialist at AWS. He’s a part of the Information-Pushed Every little thing (D2E) program, the place he helps prospects develop into extra data-driven.
Manish Vazirani is an Analytics Platform Specialist at AWS. He’s a part of the Information-Pushed Every little thing (D2E) program, the place he helps prospects develop into extra data-driven.
 Rohit Bansal is an Analytics Specialist Options Architect at AWS. He has practically twenty years of expertise serving to prospects modernize their information platforms. He’s obsessed with serving to prospects construct scalable, cost-effective information and analytics options within the cloud. In his spare time, he enjoys spending time along with his household, journey, and street biking.
Rohit Bansal is an Analytics Specialist Options Architect at AWS. He has practically twenty years of expertise serving to prospects modernize their information platforms. He’s obsessed with serving to prospects construct scalable, cost-effective information and analytics options within the cloud. In his spare time, he enjoys spending time along with his household, journey, and street biking.

{kind=link}