

Databricks Delta Dwell Tables (DLT) radically simplifies the event of the sturdy information processing pipelines by reducing the quantity of code that information engineers want to put in writing and keep. And in addition reduces the necessity for information upkeep & infrastructure operations, whereas enabling customers to seamlessly promote code & pipelines configurations between environments. However folks nonetheless must carry out testing of the code within the pipelines, and we frequently get questions on how folks can do it effectively.
On this weblog publish we’ll cowl the next gadgets based mostly on our expertise working with a number of prospects:
- How you can apply DevOps greatest practices to Delta Dwell Tables.
- How you can construction the DLT pipeline’s code to facilitate unit & integration testing.
- How you can carry out unit testing of particular person transformations of your DLT pipeline.
- How you can carry out integration testing by executing the complete DLT pipeline.
- How you can promote the DLT belongings between levels.
- How you can put all the things collectively to type a CI/CD pipeline (with Azure DevOps for instance).
Making use of DevOps practices to DLT: The massive image
The DevOps practices are geared toward shortening the software program improvement life cycle (SDLC) offering the prime quality on the identical time. Sometimes they embrace under steps:
- Model management of the supply code & infrastructure.
- Code critiques.
- Separation of environments (improvement/staging/manufacturing).
- Automated testing of particular person software program parts & the entire product with the unit & integration exams.
- Steady integration (testing) & steady deployment of adjustments (CI/CD).
All of those practices will be utilized to Delta Dwell Tables pipelines as properly:
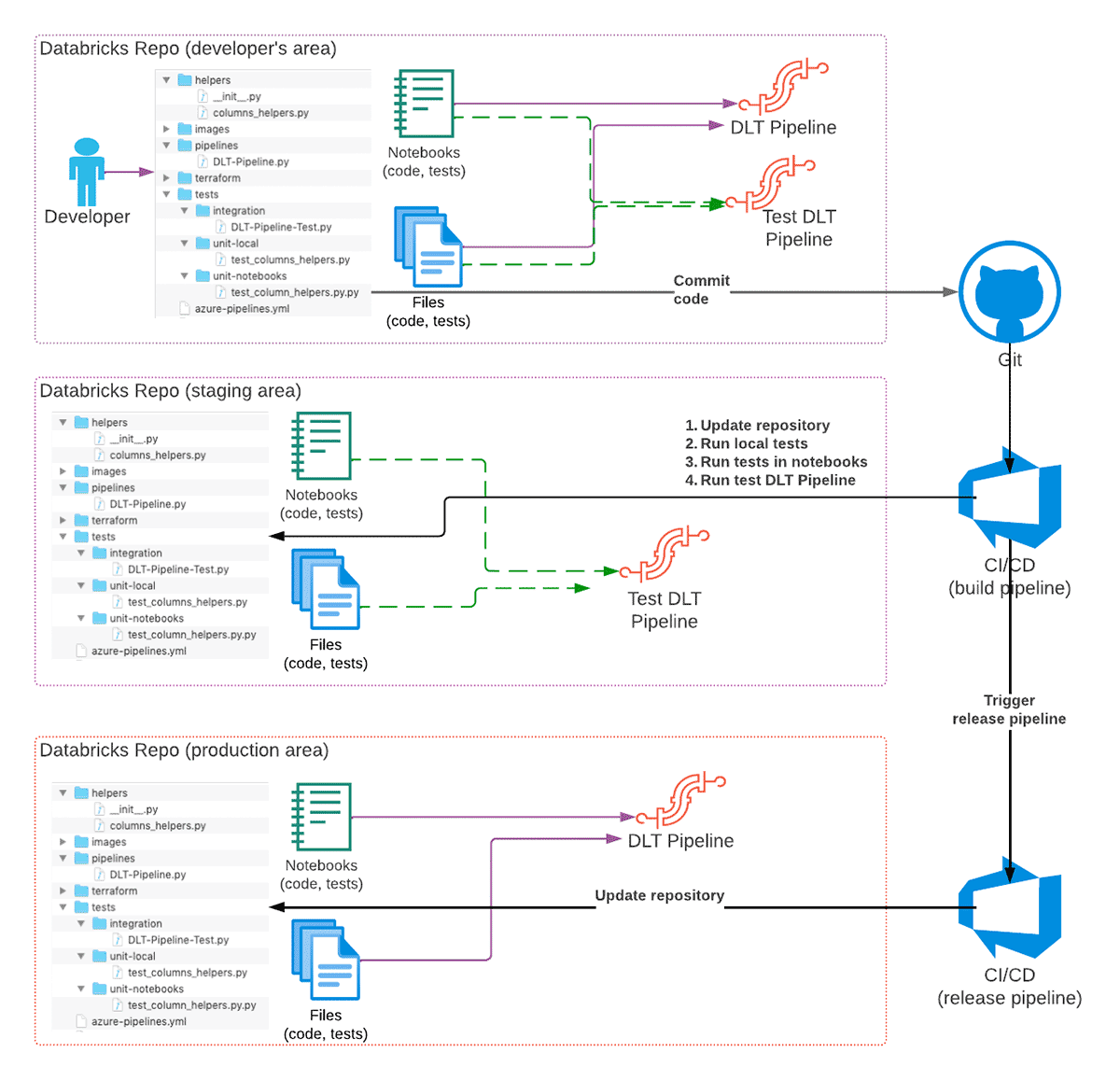
To realize this we use the next options of Databricks product portfolio:
The advisable high-level improvement workflow of a DLT pipeline is as following:
- A developer is creating the DLT code in their very own checkout of a Git repository utilizing a separate Git department for adjustments.
- When code is prepared & examined, code is dedicated to Git and a pull request is created.
- CI/CD system reacts to the commit and begins the construct pipeline (CI a part of CI/CD) that can replace a staging Databricks Repo with the adjustments, and set off execution of unit exams.
a) Optionally, the mixing exams could possibly be executed as properly, though in some circumstances this could possibly be carried out just for some branches, or as a separate pipeline. - If all exams are profitable and code is reviewed, the adjustments are merged into the principle (or a devoted department) of the Git repository.
- Merging of adjustments into a selected department (for instance, releases) could set off a launch pipeline (CD a part of CI/CD) that can replace the Databricks Repo within the manufacturing atmosphere, so code adjustments will take impact when pipeline runs subsequent time.
As illustration for the remainder of the weblog publish we’ll use a quite simple DLT pipeline consisting simply of two tables, illustrating typical bronze/silver layers of a typical Lakehouse structure. Full supply code along with deployment directions is accessible on GitHub.

Observe: DLT offers each SQL and Python APIs, in many of the weblog we deal with Python implementation, though we are able to apply many of the greatest practices additionally for SQL-based pipelines.
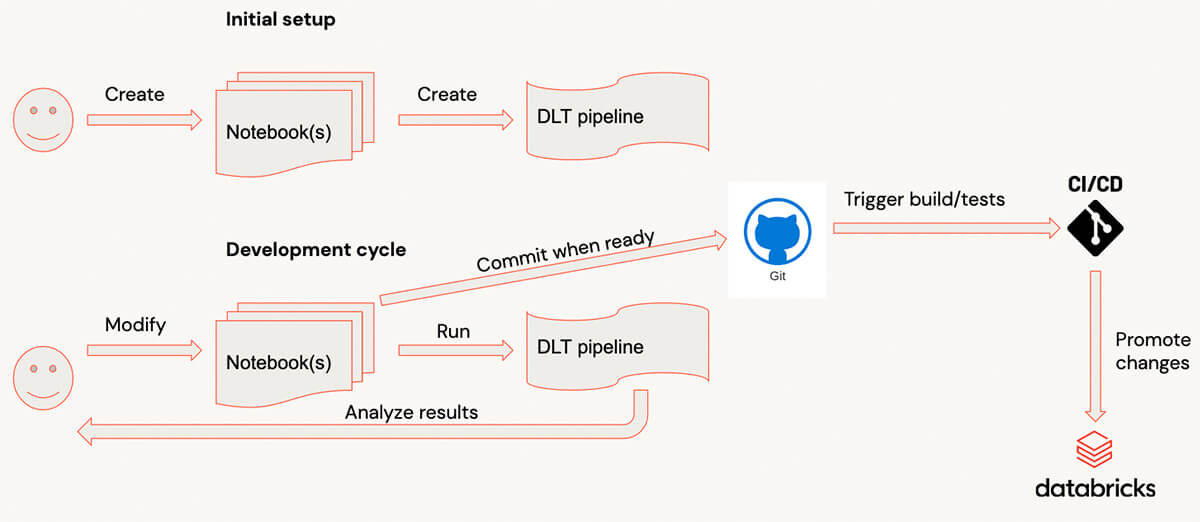
Improvement cycle with Delta Dwell Tables
When creating with Delta Dwell Tables, typical improvement course of appears to be like as follows:
- Code is written within the pocket book(s).
- When one other piece of code is prepared, a consumer switches to DLT UI and begins the pipeline. (To make this course of sooner it’s advisable to run the pipeline within the Improvement mode, so that you don’t want to attend for sources repeatedly).
- When a pipeline is completed or failed due to the errors, the consumer analyzes outcomes, and provides/modifies the code, repeating the method.
- When code is prepared, it’s dedicated.
For complicated pipelines, such dev cycle may have a big overhead as a result of the pipeline’s startup could possibly be comparatively lengthy for complicated pipelines with dozens of tables/views and when there are numerous libraries connected. For customers it might be simpler to get very quick suggestions by evaluating the person transformations & testing them with pattern information on interactive clusters.
Structuring the DLT pipeline’s code
To have the ability to consider particular person capabilities & make them testable it is essential to have appropriate code construction. Standard method is to outline all information transformations as particular person capabilities receiving & returning Spark DataFrames, and name these capabilities from DLT pipeline capabilities that can type the DLT execution graph. One of the simplest ways to realize that is to make use of information in repos performance that enables to show Python information as regular Python modules that could possibly be imported into Databricks notebooks or different Python code. DLT natively helps information in repos that enables importing Python information as Python modules (please be aware, that when utilizing information in repos, the 2 entries are added to the Python’s sys.path – one for repo root, and one for the present listing of the caller pocket book). With this, we are able to begin to write our code as a separate Python file positioned within the devoted folder beneath the repo root that will probably be imported as a Python module:
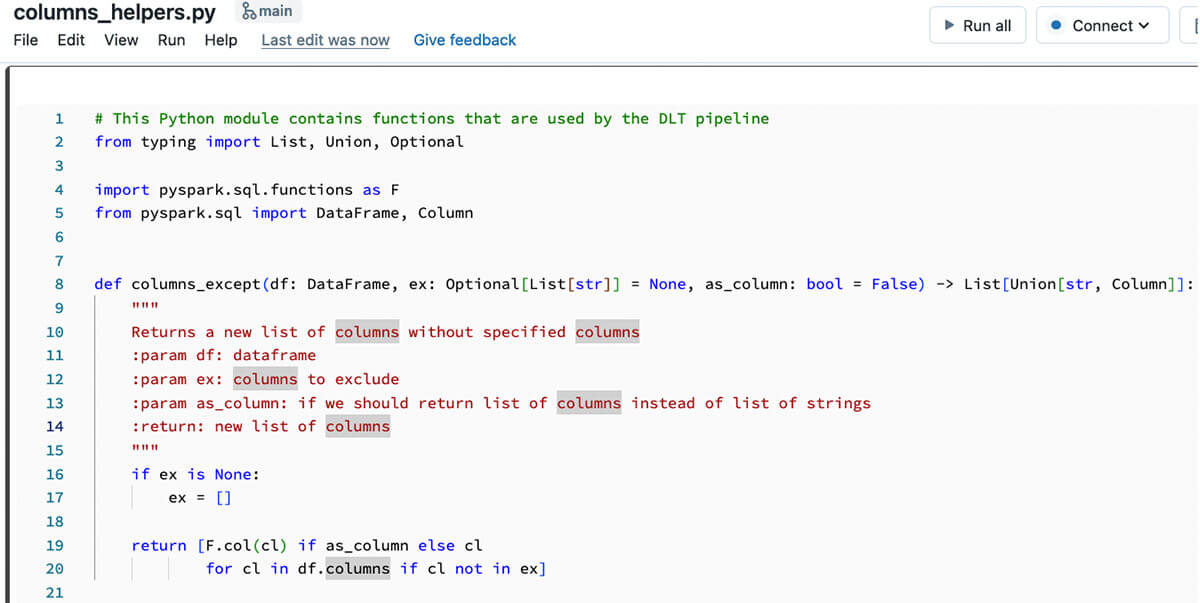
And the code from this Python package deal could possibly be used contained in the DLT pipeline code:
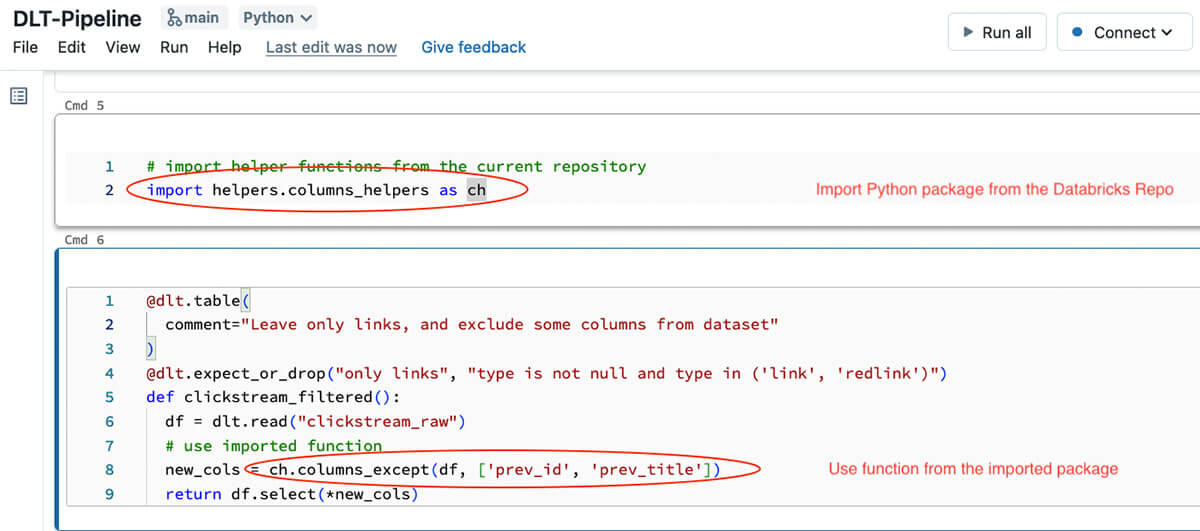
Observe, that perform on this explicit DLT code snippet may be very small – all it is doing is simply studying information from the upstream desk, and making use of our transformation outlined within the Python module. With this method we are able to make DLT code easier to grasp and simpler to check domestically or utilizing a separate pocket book connected to an interactive cluster. Splitting the transformation logic right into a separate Python module permits us to interactively check transformations from notebooks, write unit exams for these transformations and in addition check the entire pipeline (we’ll speak about testing within the subsequent sections).
The ultimate structure of the Databricks Repo, with unit & integration exams, could look as following:
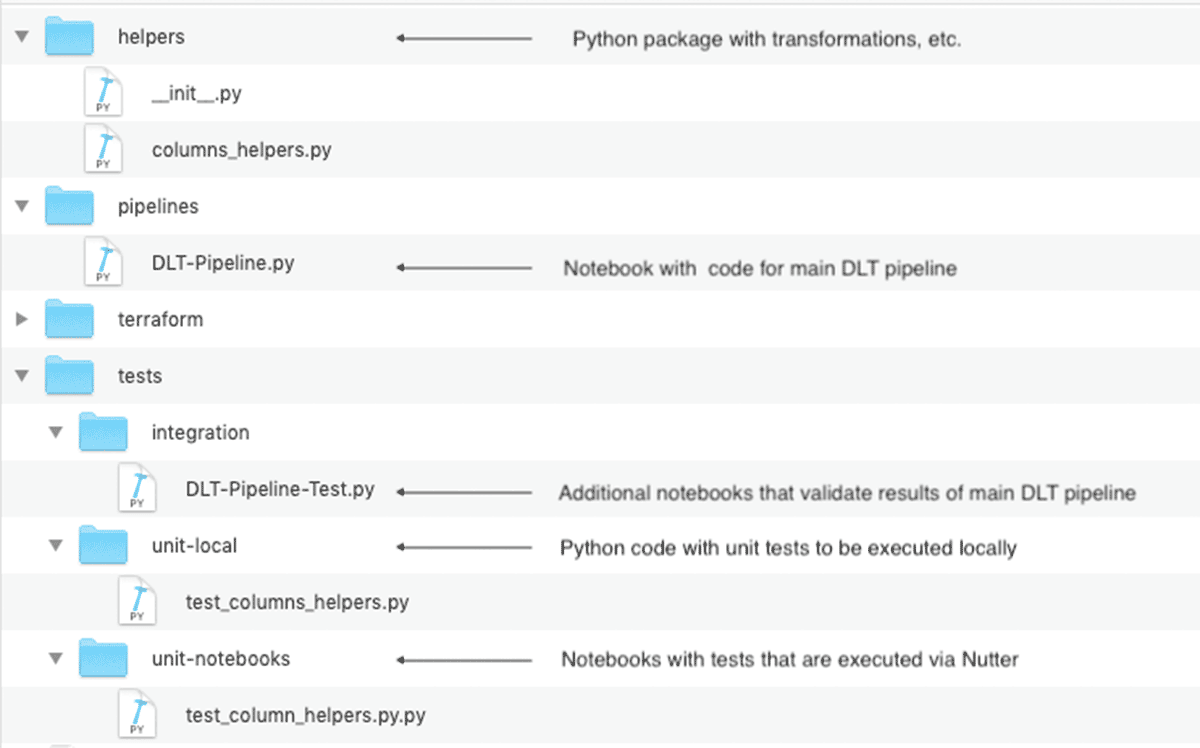
This code construction is very vital for greater initiatives which will encompass the a number of DLT pipelines sharing the widespread transformations.
Implementing unit exams
As talked about above, splitting transformations right into a separate Python module permits us simpler write unit exams that can verify conduct of the person capabilities. We’ve a selection of how we are able to implement these unit exams:
- we are able to outline them as Python information that could possibly be executed domestically, for instance, utilizing pytest. This method has following benefits:
- we are able to develop & check these transformations utilizing the IDE, and for instance, sync the native code with Databricks repo utilizing the Databricks extension for Visible Studio Code or dbx sync command in case you use one other IDE.
- such exams could possibly be executed contained in the CI/CD construct pipeline with out want to make use of Databricks sources (though it could rely if some Databricks-specific performance is used or the code could possibly be executed with PySpark).
- we have now entry to extra improvement associated instruments – static code & code protection evaluation, code refactoring instruments, interactive debugging, and many others.
- we are able to even package deal our Python code as a library, and fasten to a number of initiatives.
- we are able to outline them within the notebooks – with this method:
- we are able to get suggestions sooner as we at all times can run pattern code & exams interactively.
- we are able to use further instruments like Nutter to set off execution of notebooks from the CI/CD construct pipeline (or from the native machine) and accumulate outcomes for reporting.
The demo repository accommodates a pattern code for each of those approaches – for native execution of the exams, and executing exams as notebooks. The CI pipeline reveals each approaches.
Please be aware that each of those approaches are relevant solely to the Python code – in case you’re implementing your DLT pipelines utilizing SQL, then it is advisable observe the method described within the subsequent part.
Implementing integration exams
Whereas unit exams give us assurance that particular person transformations are working as they need to, we nonetheless must make it possible for the entire pipeline additionally works. Normally that is carried out as an integration check that runs the entire pipeline, however normally it’s executed on the smaller quantity of knowledge, and we have to validate execution outcomes. With Delta Dwell Tables, there are a number of methods to implement integration exams:
- Implement it as a Databricks Workflow with a number of duties – equally what is usually carried out for non-DLT code.
- Use DLT expectations to verify pipeline’s outcomes.
Implementing integration exams with Databricks Workflows
On this case we are able to implement integration exams with Databricks Workflows with a number of duties (we are able to even move information, akin to, information location, and many others. between duties utilizing job values). Sometimes such a workflow consists of the next duties:
- Setup information for DLT pipeline.
- Execute pipeline on this information.
- Carry out validation of produced outcomes.
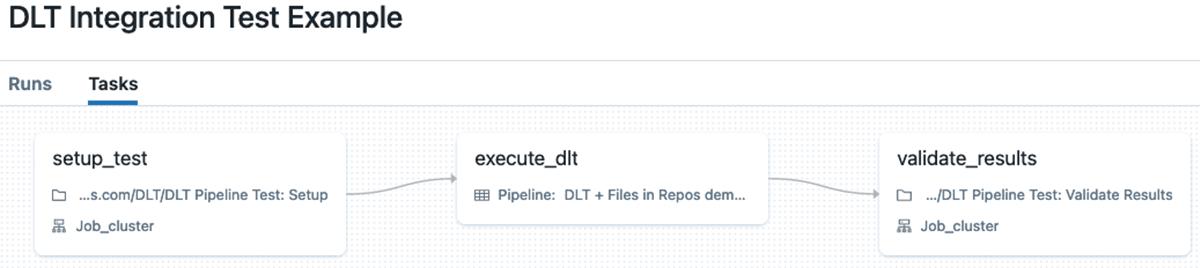
The principle disadvantage of this method is that it requires writing fairly a big quantity of the auxiliary code for setup and validation duties, plus it requires further compute sources to execute the setup and validation duties.
Use DLT expectations to implement integration exams
We will implement integration exams for DLT by increasing the DLT pipeline with further DLT tables that can apply DLT expectations to information utilizing the fail operator to fail the pipeline if outcomes do not match to offered expectations. It’s extremely simple to implement – simply create a separate DLT pipeline that can embrace further pocket book(s) that outline DLT tables with expectations connected to them.
For instance, to verify that silver desk contains solely allowed information within the kind column we are able to add following DLT desk and fasten expectations to it:
@dlt.desk(remark="Examine kind")
@dlt.expect_all_or_fail({"legitimate kind": "kind in ('hyperlink', 'redlink')",
"kind will not be null": "kind will not be null"})
def filtered_type_check():
return dlt.learn("clickstream_filtered").choose("kind")Ensuing DLT pipeline for integration check could look as following (we have now two further tables within the execution graph that verify that information is legitimate):
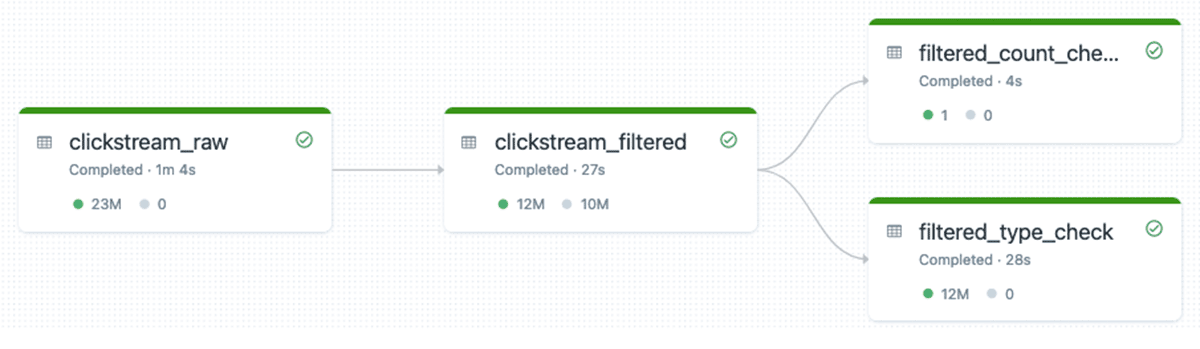
That is the advisable method to performing integration testing of DLT pipelines. With this method, we don’t want any further compute sources – all the things is executed in the identical DLT pipeline, so get cluster reuse, all information is logged into the DLT pipeline’s occasion log that we are able to use for reporting, and many others.
Please seek advice from DLT documentation for extra examples of utilizing DLT expectations for superior validations, akin to, checking uniqueness of rows, checking presence of particular rows within the outcomes, and many others. We will additionally construct libraries of DLT expectations as shared Python modules for reuse between totally different DLT pipelines.
Selling the DLT belongings between environments
Once we’re speaking about promotion of adjustments within the context of DLT, we’re speaking about a number of belongings:
- Supply code that defines transformations within the pipeline.
- Settings for a selected Delta Dwell Tables pipeline.
The only technique to promote the code is to make use of Databricks Repos to work with the code saved within the Git repository. Apart from preserving your code versioned, Databricks Repos means that you can simply propagate the code adjustments to different environments utilizing the Repos REST API or Databricks CLI.
From the start, DLT separates code from the pipeline configuration to make it simpler to advertise between levels by permitting to specify the schemas, information places, and many others. So we are able to outline a separate DLT configuration for every stage that can use the identical code, whereas permitting you to retailer information in several places, use totally different cluster sizes,and many others.
To outline pipeline settings we are able to use Delta Dwell Tables REST API or Databricks CLI’s pipelines command, however it turns into tough in case it is advisable use occasion swimming pools, cluster insurance policies, or different dependencies. On this case the extra versatile various is Databricks Terraform Supplier’s databricks_pipeline useful resource that enables simpler dealing with of dependencies to different sources, and we are able to use Terraform modules to modularize the Terraform code to make it reusable. The offered code repository accommodates examples of the Terraform code for deploying the DLT pipelines into the a number of environments.
Placing all the things collectively to type a CI/CD pipeline
After we carried out all the person elements, it is comparatively simple to implement a CI/CD pipeline. GitHub repository features a construct pipeline for Azure DevOps (different programs could possibly be supported as properly – the variations are normally within the file construction). This pipeline has two levels to point out skill to execute totally different units of exams relying on the particular occasion:
- onPush is executed on push to any Git department besides releases department and model tags. This stage solely runs & reviews unit exams outcomes (each native & notebooks).
- onRelease is executed solely on commits to the releases department, and along with the unit exams it can execute a DLT pipeline with integration check.
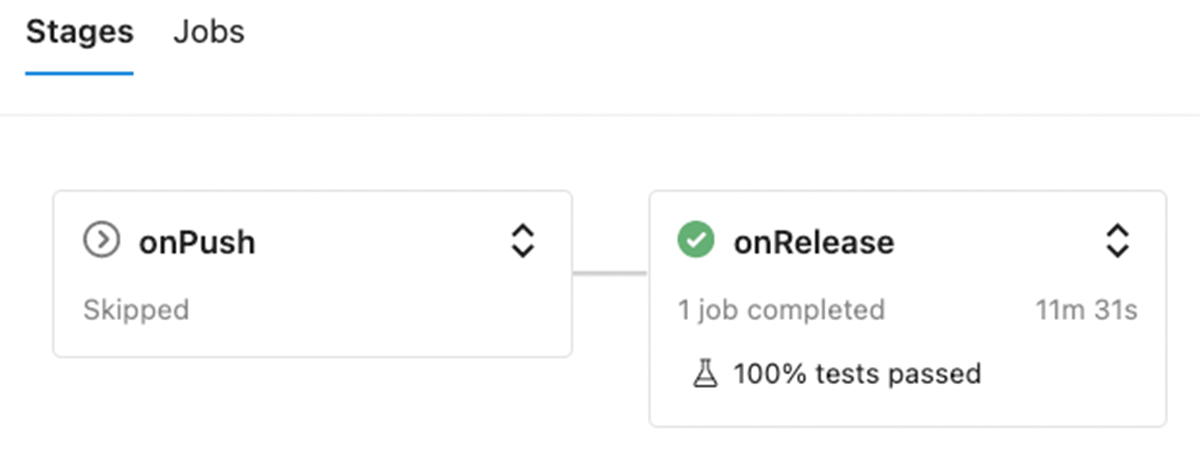
Apart from the execution of the mixing check within the onRelease stage, the construction of each levels is identical – it consists of following steps:
- Checkout the department with adjustments.
- Arrange atmosphere – set up Poetry which is used for managing Python atmosphere administration, and set up of required dependencies.
- Replace Databricks Repos within the staging atmosphere.
- Execute native unit exams utilizing the PySpark.
- Execute the unit exams carried out as Databricks notebooks utilizing Nutter.
- For
releasesdepartment, execute integration exams. - Gather check outcomes & publish them to Azure DevOps.
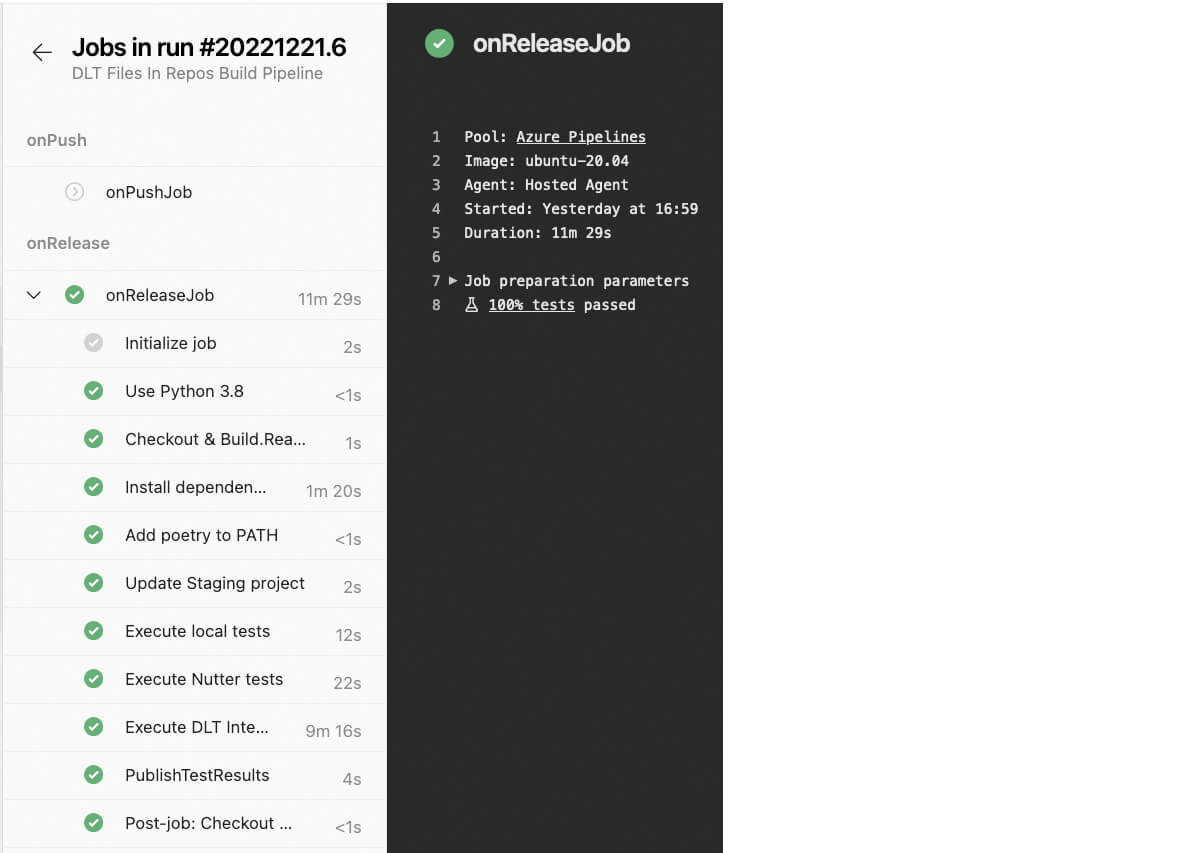
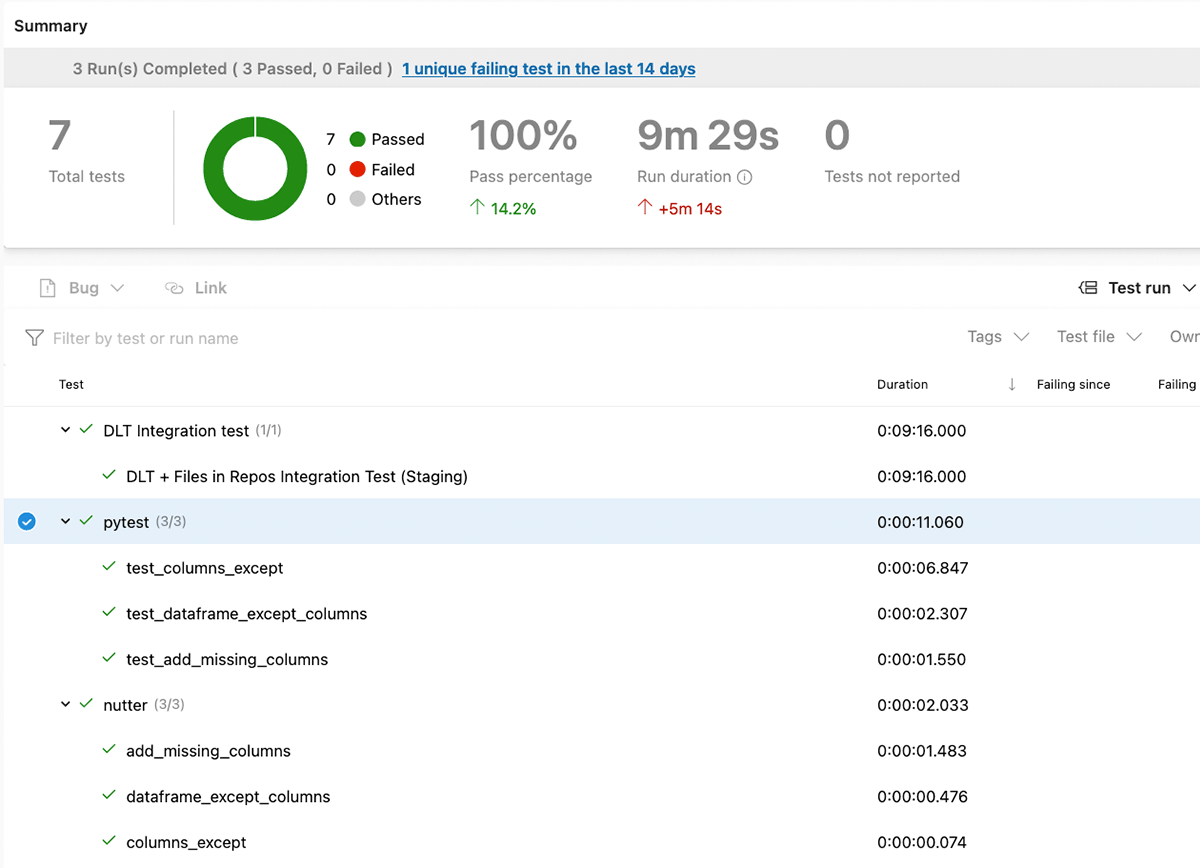
Outcomes of exams execution are reported again to the Azure DevOps, so we are able to monitor them:
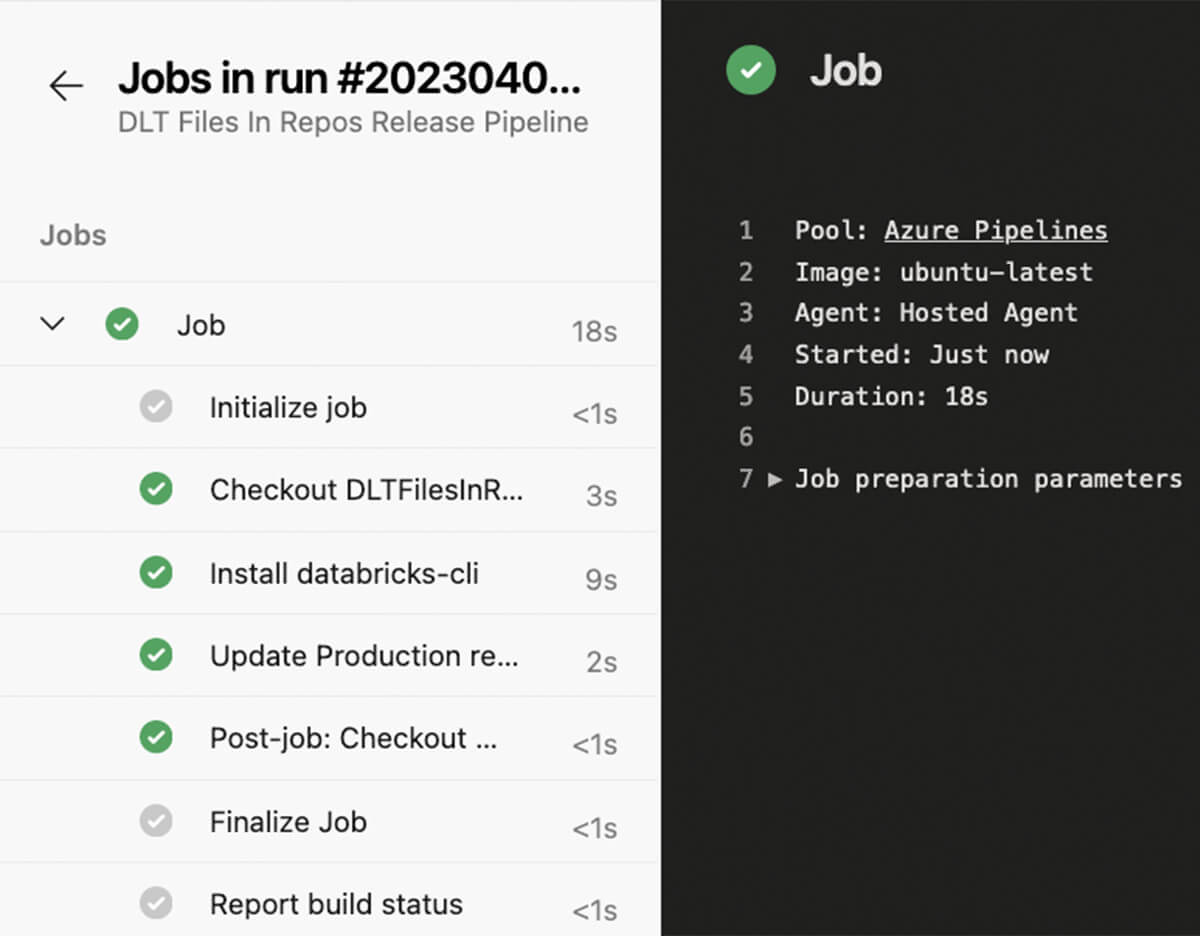
If commits had been carried out to the releases department and all exams had been profitable, the launch pipeline could possibly be triggered, updating the manufacturing Databricks repo, so adjustments within the code will probably be taken into consideration on the subsequent run of DLT pipeline.
Attempt to apply approaches described on this weblog publish to your Delta Dwell Desk pipelines! The offered demo repository accommodates all essential code along with setup directions and Terraform code for deployment of all the things to Azure DevOps.

{kind=link}