

Amazon Kinesis is a platform to ingest real-time occasions from IoT units, POS techniques, and purposes, producing many sorts of occasions that want real-time evaluation. As a consequence of Rockset‘s means to offer a extremely scalable resolution to carry out real-time analytics of those occasions in sub-second latency with out worrying about schema, many Rockset customers select Kinesis with Rockset. Plus, Rockset can intelligently scale with the capabilities of a Kinesis stream, offering a seamless high-throughput expertise for our prospects whereas optimizing price.
Background on Amazon Kinesis
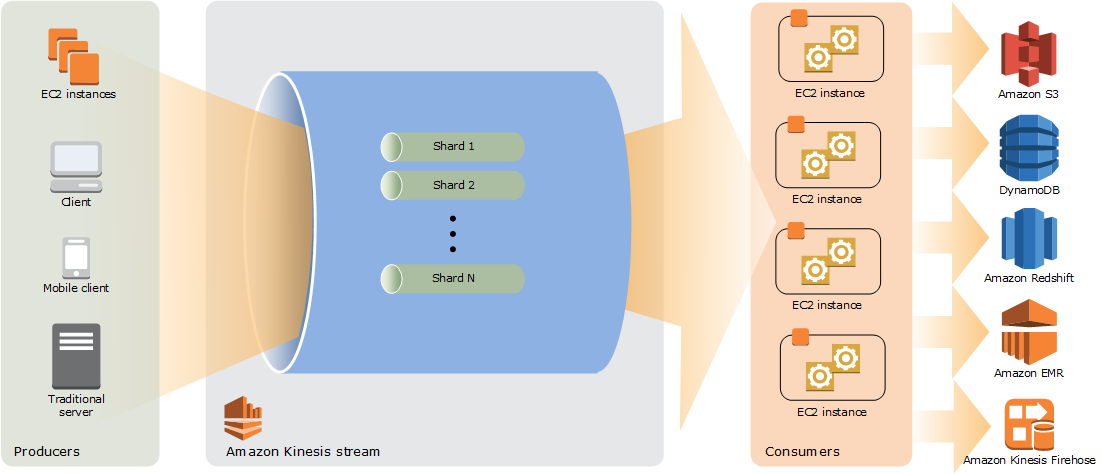
Picture Supply: https://docs.aws.amazon.com/streams/newest/dev/key-concepts.html
A Kinesis stream consists of shards, and every shard has a sequence of knowledge data. A shard might be considered an information pipe, the place the ordering of occasions is preserved. See Amazon Kinesis Knowledge Streams Terminology and Ideas for extra info.
Throughput and Latency
Throughput is a measure of the quantity of knowledge that’s transferred between supply and vacation spot. A Kinesis stream with a single shard can’t scale past a sure restrict due to the ordering ensures offered by a shard. To handle excessive throughput necessities when there are a number of purposes writing to a Kinesis stream, it is smart to extend the variety of shards configured for the stream in order that totally different purposes can write to totally different shards in parallel. Latency can be reasoned equally. A single shard accumulating occasions from a number of sources will improve end-to-end latency in delivering messages to the customers.
Capability Modes
On the time of creation of a Kinesis stream, there are two modes to configure shards/capability mode:
- Provisioned capability mode: On this mode, the variety of Kinesis shards is consumer configured. Kinesis will create as many shards as specified by the consumer.
- On-demand capability mode: On this mode, Kinesis responds to the incoming throughput to regulate the shard depend.
With this because the background, let’s discover the implications.
Price
AWS Kinesis prices prospects by the shard hour. The higher the variety of shards, the higher the price. If the shard utilization is predicted to be excessive with a sure variety of shards, it is smart to statically outline the variety of shards for a Kinesis stream. Nevertheless, if the site visitors sample is extra variable, it could be cheaper to let Kinesis scale shards based mostly on throughput by configuring the Kinesis stream with on-demand capability mode.
AWS Kinesis with Rockset
Shard Discovery and Ingestion
Earlier than we discover ingesting information from Kinesis into Rockset, let’s recap what a Rockset assortment is. A group is a container of paperwork that’s usually ingested from a supply. Customers can run analytical queries in SQL in opposition to this assortment. A typical configuration consists of mapping a Kinesis stream to a Rockset Assortment.
Whereas configuring a Rockset assortment for a Kinesis stream it isn’t required to specify the supply of the shards that have to be ingested into the gathering. The Rockset assortment will mechanically uncover shards which can be a part of the stream and give you a blueprint for producing ingestion jobs. Based mostly on this blueprint, ingestion jobs are coordinated that learn information from a Kinesis shard into the Rockset system. Inside the Rockset system, ordering of occasions inside every shard is preserved, whereas additionally benefiting from parallelization potential for ingesting information throughout shards.
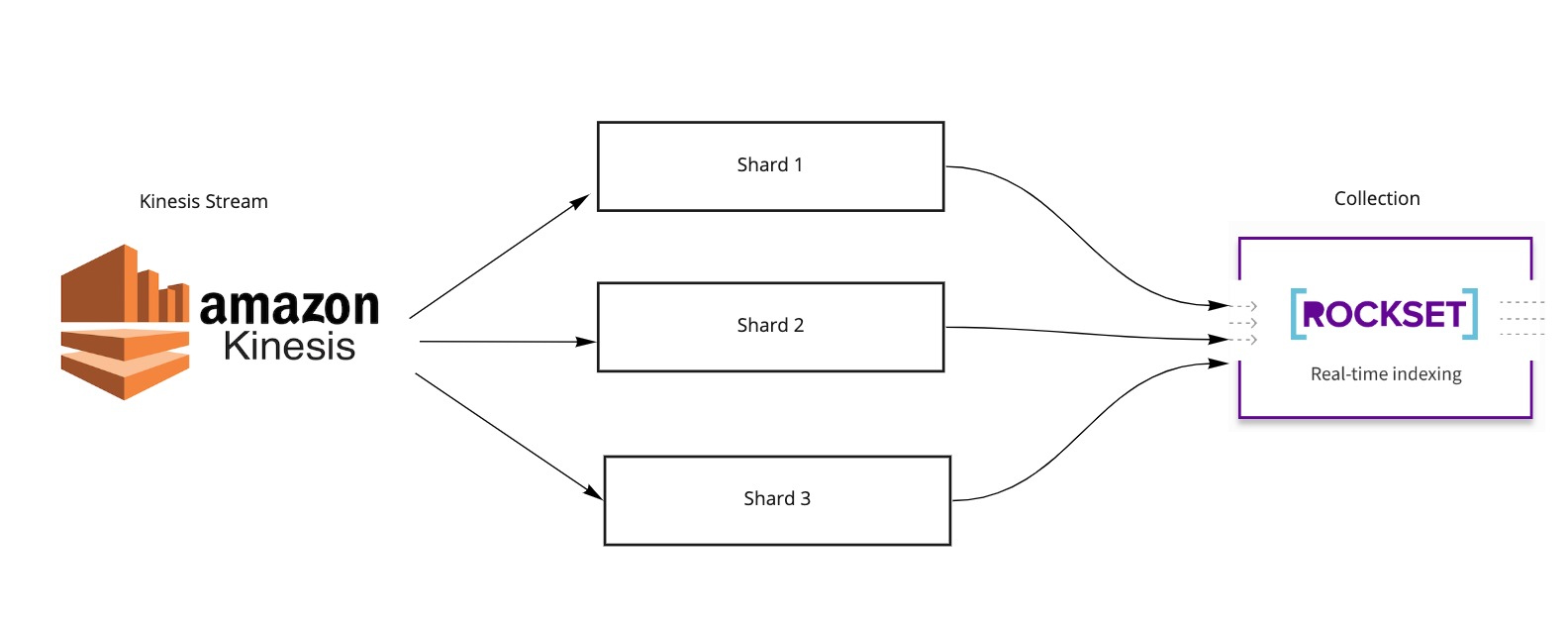
If the Kinesis shards are created statically, and simply as soon as throughout stream initialization, it’s easy to create ingestion jobs for every shard and run these in parallel. These ingestion jobs can be long-running, doubtlessly for the lifetime of the stream, and would regularly transfer information from the assigned shards to the Rockset assortment. If nevertheless, shards can develop or shrink in quantity, in response to both throughput (as within the case of on-demand capability mode) or consumer re-configuration (for instance, resetting shard depend for a stream configured within the provisioned capability mode), managing ingestion will not be as easy.
Shards That Wax and Wane
Resharding in Kinesis refers to an present shard being break up or two shards being merged right into a single shard. When a Kinesis shard is break up, it generates two baby shards from a single dad or mum shard. When two Kinesis shards are merged, it generates a single baby shard that has two dad and mom. In each these instances, the kid shard maintains a again pointer or a reference to the dad or mum shards. Utilizing the LIST SHARDS API, we will infer these shards and the relationships.
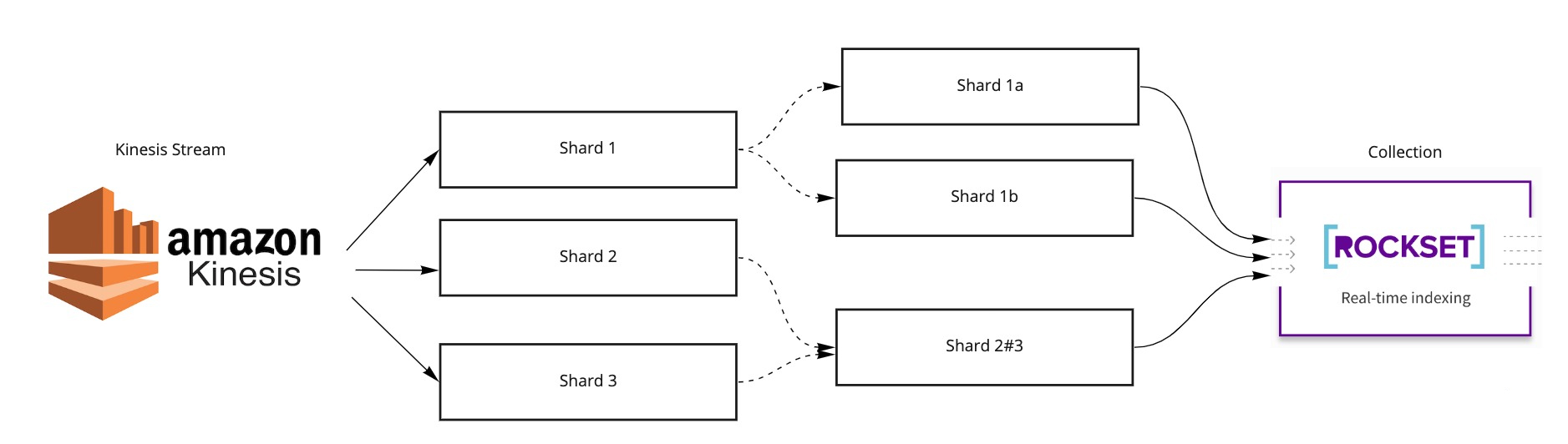
Selecting a Knowledge Construction
Let’s go a bit of beneath the floor into the world of engineering. Why can we not maintain all shards in a flat record and begin ingestion jobs for all of them in parallel? Keep in mind what we stated about shards sustaining occasions so as. This ordering assure have to be honored throughout shard generations, too. In different phrases, we can’t course of a baby shard with out processing its dad or mum shard(s). The astute reader may already be occupied with a hierarchical information construction like a tree or a DAG (directed acyclic graph). Certainly, we select a DAG as the info construction (solely as a result of in a tree you can not have a number of dad or mum nodes for a kid node). Every node in our DAG refers to a shard. The blueprint we referred to earlier has assumed the type of a DAG.
Placing the Blueprint Into Motion
Now we’re able to schedule ingestion jobs by referring to the DAG, aka blueprint. Traversing a DAG in an order that respects ordering is achieved through a standard approach referred to as topological sorting. There’s one caveat, nevertheless. Although a topological sorting ends in an order that doesn’t violate dependency relationships, we will optimize a bit of additional. If a baby shard has two dad or mum shards, we can’t course of the kid shard till the dad or mum shards are absolutely processed. However there is no such thing as a dependency relationship between these two dad or mum shards. So, to optimize processing throughput, we will schedule ingestion jobs for these two dad or mum shards to run in parallel. This yields the next algorithm:
void schedule(Node present, Set<Node> output) {
if (processed(present)) {
return;
}
boolean flag = false;
for (Node dad or mum: present.getParents()) {
if (!processed(dad or mum)) {
flag = true;
schedule(dad or mum, output);
}
}
if (!flag) {
output.add(present);
}
}
The above algorithm ends in a set of shards that may be processed in parallel. As new shards get created on Kinesis or present shards get merged, we periodically ballot Kinesis for the newest shard info so we will modify our processing state and spawn new ingestion jobs, or wind down present ingestion jobs as wanted.
Protecting the Home Manageable
In some unspecified time in the future, the shards get deleted by the retention coverage set on the stream. We are able to clear up the shard processing info we now have cached accordingly in order that we will preserve our state administration in verify.
To Sum Up
We’ve seen how Kinesis makes use of the idea of shards to take care of occasion ordering and on the similar time present means to scale them out/in in response to throughput or consumer reconfiguration. We’ve additionally seen how Rockset responds to this virtually in lockstep to maintain up with the throughput necessities, offering our prospects a seamless expertise. By supporting on-demand capability mode with Kinesis information streams, Rockset ingestion additionally permits our prospects to profit from any price financial savings supplied by this mode.
If you’re fascinated with studying extra or contributing to the dialogue on this subject, please be a part of the Rockset Group. Glad sharding!
Rockset is the real-time analytics database within the cloud for contemporary information groups. Get quicker analytics on brisker information, at decrease prices, by exploiting indexing over brute-force scanning.

{kind=link}