

Amazon Athena is a serverless and interactive question service that means that you can simply analyze information in Amazon Easy Storage Service (Amazon S3) and 25-plus information sources, together with on-premises information sources or different cloud techniques utilizing SQL or Python. Athena built-in capabilities embrace querying for geospatial information; for instance, you may rely the variety of earthquakes in every Californian county. One drawback of analyzing at county-level is that it might offer you a deceptive impression of which elements of California have had essentially the most earthquakes. It’s because the counties aren’t equally sized; a county could have had extra earthquakes just because it’s an enormous county. What if we wished a hierarchical system that allowed us to zoom out and in to combination information over completely different equally-sized geographic areas?
On this put up, we current an answer that makes use of Uber’s Hexagonal Hierarchical Spatial Index (H3) to divide the globe into equally-sized hexagons. We then use an Athena user-defined perform (UDF) to find out which hexagon every historic earthquake occurred in. As a result of the hexagons are equally-sized, this evaluation offers a good impression of the place earthquakes are likely to happen.
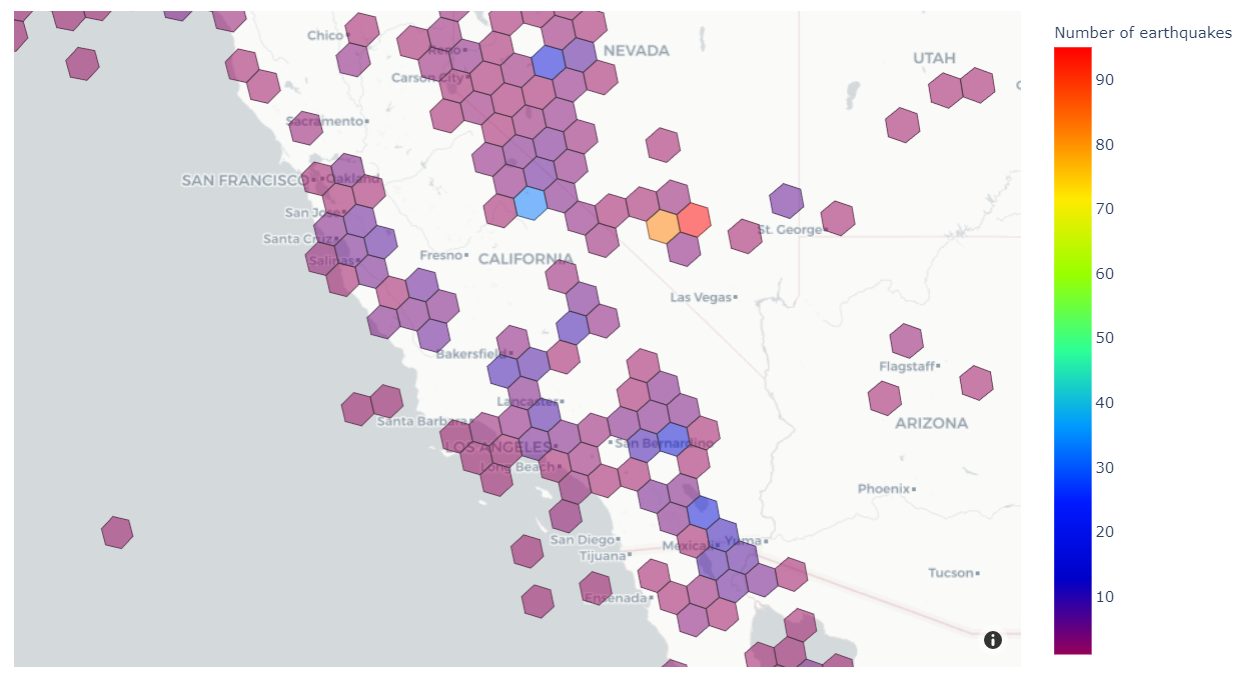
On the finish, we’ll produce a visualization just like the one beneath that exhibits the variety of historic earthquakes in several areas of the western US.
H3 divides the globe into equal-sized common hexagons. The variety of hexagons depends upon the chosen decision, which can differ from 0 (122 hexagons, every with edge lengths of about 1,100 km) to fifteen (569,707,381,193,162 hexagons, every with edge lengths of about 50 cm). H3 allows evaluation on the space stage, and every space has the identical measurement and form.
Resolution overview
The answer extends Athena’s built-in geospatial capabilities by making a UDF powered by AWS Lambda. Lastly, we use an Amazon SageMaker pocket book to run Athena queries which are rendered as a choropleth map. The next diagram illustrates this structure.
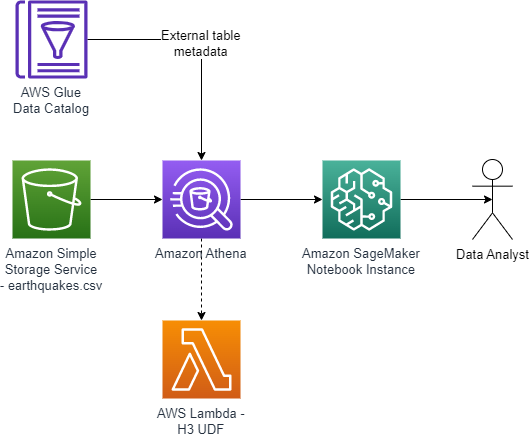
The tip-to-end structure is as follows:
- A CSV file of historic earthquakes is uploaded into an S3 bucket.
- An AWS Glue exterior desk is created primarily based on the earthquake CSV.
- A Lambda perform calculates H3 hexagons for parameters (latitude, longitude, decision). The perform is written in Java and will be referred to as as a UDF utilizing queries in Athena.
- A SageMaker pocket book makes use of an AWS SDK for pandas bundle to run a SQL question in Athena, together with the UDF.
- A Plotly Specific bundle renders a choropleth map of the variety of earthquakes in every hexagon.
Conditions
For this put up, we use Athena to learn information in Amazon S3 utilizing the desk outlined within the AWS Glue Information Catalog related to our earthquake dataset. By way of permissions, there are two major necessities:
Configure Amazon S3
Step one is to create an S3 bucket to retailer the earthquake dataset, as follows:
- Obtain the CSV file of historic earthquakes from GitHub.
- On the Amazon S3 console, select Buckets within the navigation pane.
- Select Create bucket.
- For Bucket title, enter a globally distinctive title to your information bucket.
- Select Create folder, and enter the folder title
earthquakes. - Add the file to the S3 bucket. On this instance, we add the
earthquakes.csvfile to theearthquakesprefix.
Create a desk in Athena
Navigate to Athena console to create a desk. Full the next steps:
- On the Athena console, select Question editor.
- Choose your most well-liked Workgroup utilizing the drop-down menu.

- Within the SQL editor, use the next code to create a desk within the default database:
Create a Lambda perform for the Athena UDF
For an intensive clarification on how one can construct Athena UDFs, see Querying with consumer outlined features. We use Java 11 and Uber H3 Java binding to construct the H3 UDF. We offer the implementation of the UDF on GitHub.
There are a number of choices for deploying a UDF utilizing Lambda. On this instance, we use the AWS Administration Console. For manufacturing deployments, you most likely wish to use infrastructure as code such because the AWS Cloud Growth Package (AWS CDK). For details about how one can use the AWS CDK to deploy the Lambda perform, consult with the venture code repository. One other potential deployment possibility is utilizing AWS Serverless Utility Repository (SAR).
Deploy the UDF
Deploy the Uber H3 binding UDF utilizing the console as follows:
- Go to binary listing within the GitHub repository, and obtain
aws-h3-athena-udf-*.jarto your native desktop. - Create a Lambda perform referred to as
H3UDFwith Runtime set to Java 11 (Corretto), and Structure set to x86_64.
- Add the
aws-h3-athena-udf*.jarfile.
- Change the handler title to
com.aws.athena.udf.h3.H3AthenaHandler.
- Within the Basic configuration part, select Edit to set the reminiscence of the Lambda perform to 4096 MB, which is an quantity of reminiscence that works for our examples. Chances are you’ll must set the reminiscence measurement bigger to your use instances.

Use the Lambda perform as an Athena UDF
After you create the Lambda perform, you’re prepared to make use of it as a UDF. The next screenshot exhibits the perform particulars.
Now you can use the perform as an Athena UDF. On the Athena console, run the next command:

The udf/examples folder within the GitHub repository contains extra examples of the Athena queries.
Creating the UDFs
Now that we confirmed you how one can deploy a UDF for Athena utilizing Lambda, let’s dive deeper into how one can develop these sorts of UDFs. As defined in Querying with consumer outlined features, with a view to develop a UDF, we first must implement a category that inherits UserDefinedFunctionHandler. Then we have to implement the features inside the category that can be utilized as UDFs of Athena.
We start the UDF implementation by defining a category H3AthenaHandler that inherits the UserDefinedFunctionHandler. Then we implement features that act as wrappers of features outlined within the Uber H3 Java binding. We ensure that all of the features outlined within the H3 Java binding API are mapped, in order that they can be utilized in Athena as UDFs. For instance, we map the lat_lng_to_cell_address perform used within the previous instance to the latLngToCell of the H3 Java binding.
On high of the decision to the Java binding, most of the features within the H3AthenaHandler test whether or not the enter parameter is null. The null test is helpful as a result of we don’t assume the enter to be non-null. In observe, null values for an H3 index or deal with usually are not uncommon.
The next code exhibits the implementation of the get_resolution perform:
Some H3 API features corresponding to cellToLatLng return Listing<Double> of two components, the place the primary factor is the latitude and the second is longitude. The H3 UDF that we implement gives a perform that returns well-known textual content (WKT) illustration. For instance, we offer cell_to_lat_lng_wkt, which returns a Level WKT string as a substitute of Listing<Double>. We are able to then use the output of cell_to_lat_lng_wkt together with the built-in spatial Athena perform ST_GeometryFromText as follows:
Athena UDF solely helps scalar information varieties and doesn’t help nested varieties. Nevertheless, some H3 APIs return nested varieties. For instance, the polygonToCells perform in H3 takes a Listing<Listing<Listing<GeoCoord>>>. Our implementation of polygon_to_cells UDF receives a Polygon WKT as a substitute. The next exhibits an instance Athena question utilizing this UDF:
Use SageMaker notebooks for visualization
A SageMaker pocket book is a managed machine studying compute occasion that runs a Jupyter pocket book utility. On this instance, we’ll use a SageMaker pocket book to put in writing and run our code to visualise our outcomes, but when your use case contains Apache Spark then utilizing Amazon Athena for Apache Spark could be an incredible selection. For recommendation on safety greatest practices for SageMaker, see Constructing safe machine studying environments with Amazon SageMaker. You may create your personal SageMaker pocket book by following these directions:
- On the SageMaker console, select Pocket book within the navigation pane.
- Select Pocket book cases.
- Select Create pocket book occasion.
- Enter a reputation for the pocket book occasion.
- Select an present IAM position or create a job that means that you can run SageMaker and grants entry to Amazon S3 and Athena.
- Select Create pocket book occasion.

- Anticipate the pocket book standing to vary from
CreatingtoInService. - Open the pocket book occasion by selecting Jupyter or JupyterLab.
Discover the info
We’re now able to discover the info.
- On the Jupyter console, below New, select Pocket book.
- On the Choose Kernel drop-down menu, select conda_python3.
- Add new cells by selecting the plus signal.
- In your first cell, obtain the next Python modules that aren’t included in the usual SageMaker surroundings:
GeoJSON is a well-liked format for storing spatial information in a JSON format. The
geojsonmodule means that you can simply learn and write GeoJSON information with Python. The second module we set up,awswrangler, is the AWS SDK for pandas. It is a very straightforward technique to learn information from numerous AWS information sources into Pandas information frames. We use it to learn earthquake information from the Athena desk. - Subsequent, we import all of the packages that we use to import the info, reshape it, and visualize it:
- We start importing our information utilizing the
athena.read_sql._queryperform in AWS SDK for pandas. The Athena question has a subquery that makes use of the UDF so as to add a columnh3_cellto every row within theearthquakesdesk, primarily based on the latitude and longitude of the earthquake. The analytic performCOUNTis then used to seek out out the variety of earthquakes in every H3 cell. For this visualization, we’re solely serious about earthquakes inside the US, so we filter out rows within the information body which are outdoors the world of curiosity:The next screenshot exhibits our outcomes.

Comply with together with the remainder of the steps in our Jupyter pocket book to see how we analyze and visualize our instance with H3 UDF information.
Visualize the outcomes
To visualise our outcomes, we use the Plotly Specific module to create a choropleth map of our information. A choropleth map is a sort of visualization that’s shaded primarily based on quantitative values. It is a nice visualization for our use case as a result of we’re shading completely different areas primarily based on the frequency of earthquakes.
Within the ensuing visible, we are able to see the ranges of frequency of earthquakes in several areas of North America. Observe, the H3 decision on this map is decrease than within the earlier map, which makes every hexagon cowl a bigger space of the globe.

Clear up
To keep away from incurring additional prices in your account, delete the sources you created:
- On the SageMaker console, choose the pocket book and on the Actions menu, select Cease.
- Anticipate the standing of the pocket book to vary to
Stopped, then choose the pocket book once more and on the Actions menu, select Delete. - On the Amazon S3 console, choose the bucket you created and select Empty.
- Enter the bucket title and select Empty.
- Choose the bucket once more and select Delete.
- Enter the bucket title and select Delete bucket.
- On the Lambda console, choose the perform title and on the Actions menu, select Delete.
Conclusion
On this put up, you noticed how one can prolong features in Athena for geospatial evaluation by including your personal user-defined perform. Though we used Uber’s H3 geospatial index on this demonstration, you may convey your personal geospatial index to your personal customized geospatial evaluation.
On this put up, we used Athena, Lambda, and SageMaker notebooks to visualise the outcomes of our UDFs within the western US. Code examples are within the h3-udf-for-athena GitHub repo.
As a subsequent step, you may modify the code on this put up and customise it to your personal wants to achieve additional insights from your personal geographical information. For instance, you possibly can visualize different instances corresponding to droughts, flooding, and deforestation.
In regards to the Authors
 John Telford is a Senior Guide at Amazon Net Providers. He’s a specialist in massive information and information warehouses. John has a Pc Science diploma from Brunel College.
John Telford is a Senior Guide at Amazon Net Providers. He’s a specialist in massive information and information warehouses. John has a Pc Science diploma from Brunel College.
 Anwar Rizal is a Senior Machine Studying guide primarily based in Paris. He works with AWS prospects to develop information and AI options to sustainably develop their enterprise.
Anwar Rizal is a Senior Machine Studying guide primarily based in Paris. He works with AWS prospects to develop information and AI options to sustainably develop their enterprise.
 Pauline Ting is a Information Scientist within the AWS Skilled Providers group. She helps prospects in attaining and accelerating their enterprise consequence by growing sustainable AI/ML options. In her spare time, Pauline enjoys touring, browsing, and making an attempt new dessert locations.
Pauline Ting is a Information Scientist within the AWS Skilled Providers group. She helps prospects in attaining and accelerating their enterprise consequence by growing sustainable AI/ML options. In her spare time, Pauline enjoys touring, browsing, and making an attempt new dessert locations.

{kind=link}