
Because the deluge of huge information over a decade in the past, many organizations have discovered to construct functions to course of and analyze petabytes of information. Information lakes have served as a central repository to retailer structured and unstructured information at any scale and in numerous codecs. Nevertheless, as information processing at scale options develop, organizations have to construct increasingly options on high of their information lakes. One vital characteristic is to run completely different workloads equivalent to enterprise intelligence (BI), Machine Studying (ML), Information Science and information exploration, and Change Information Seize (CDC) of transactional information, with out having to keep up a number of copies of information. Moreover, the duty of sustaining and managing recordsdata within the information lake might be tedious and typically complicated.
Desk codecs like Apache Iceberg present options to those points. They allow transactions on high of information lakes and might simplify information storage, administration, ingestion, and processing. These transactional information lakes mix options from each the info lake and the info warehouse. You’ll be able to simplify your information technique by operating a number of workloads and functions on the identical information in the identical location. Nevertheless, utilizing these codecs requires constructing, sustaining, and scaling infrastructure and integration connectors that may be time-consuming, difficult, and dear.
On this put up, we present how one can construct a serverless transactional information lake with Apache Iceberg on Amazon Easy Storage Service (Amazon S3) utilizing Amazon EMR Serverless and Amazon Athena. We offer an instance for information ingestion and querying utilizing an ecommerce gross sales information lake.
Apache Iceberg overview
Iceberg is an open-source desk format that brings the ability of SQL tables to huge information recordsdata. It permits ACID transactions on tables, permitting for concurrent information ingestion, updates, and queries, all whereas utilizing acquainted SQL. Iceberg employs inside metadata administration that retains observe of information and empowers a set of wealthy options at scale. It permits you to time journey and roll again to previous variations of dedicated information transactions, management the desk’s schema evolution, simply compact information, and make use of hidden partitioning for quick queries.
Iceberg manages recordsdata on behalf of the person and unlocks use circumstances equivalent to:
- Concurrent information ingestion and querying, together with streaming and CDC
- BI and reporting with expressive easy SQL
- Empowering ML characteristic shops and coaching units
- Compliance and rules workloads, equivalent to GDPR discover and overlook
- Reinstating late-arriving information, which is dimensions information arriving later than the very fact information. For instance, the explanation for a flight delay might arrive properly after the truth that the fligh is delayed.
- Monitoring information adjustments and rollback
Construct your transactional information lake on AWS
You’ll be able to construct your trendy information structure with a scalable information lake that integrates seamlessly with an Amazon Redshift powered cloud warehouse. Furthermore, many shoppers are searching for an structure the place they’ll mix the advantages of an information lake and an information warehouse in the identical storage location. Within the following determine, we present a complete structure that makes use of the trendy information structure technique on AWS to construct a completely featured transactional information lake. AWS supplies flexibility and a large breadth of options to ingest information, construct AI and ML functions, and run analytics workloads with out having to deal with the undifferentiated heavy lifting.
Information might be organized into three completely different zones, as proven within the following determine. The primary zone is the uncooked zone, the place information might be captured from the supply as is. The remodeled zone is an enterprise-wide zone to host cleaned and remodeled information with the intention to serve a number of groups and use circumstances. Iceberg supplies a desk format on high of Amazon S3 on this zone to offer ACID transactions, but in addition to permit seamless file administration and supply time journey and rollback capabilities. The enterprise zone shops information particular to enterprise circumstances and functions aggregated and computed from information within the remodeled zone.
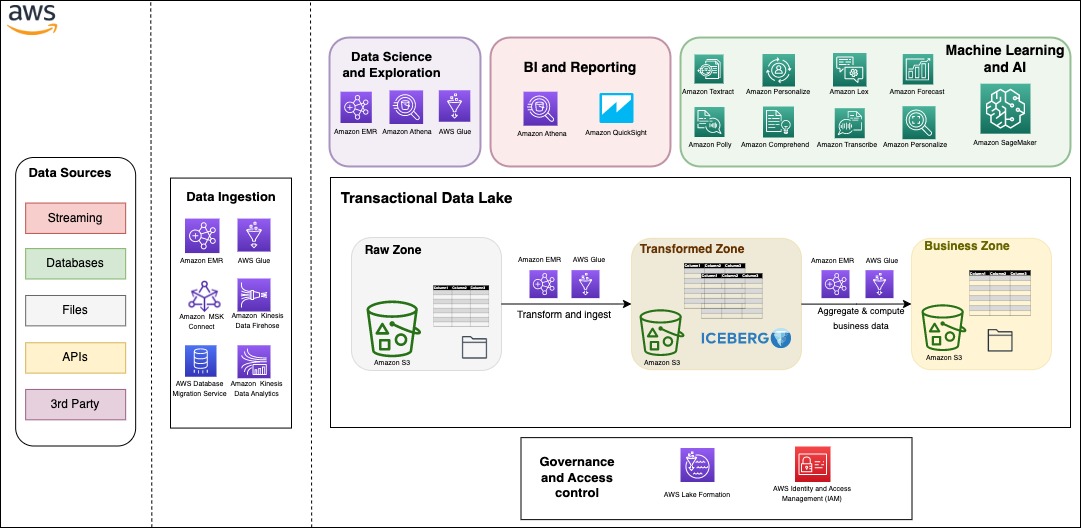
One vital facet to a profitable information technique for any group is information governance. On AWS, you may implement a radical governance technique with fine-grained entry management to the info lake with AWS Lake Formation.
Serverless structure overview
On this part, we present you methods to ingest and question information in your transactional information lake in a couple of steps. EMR Serverless is a serverless possibility that makes it simple for information analysts and engineers to run Spark-based analytics with out configuring, managing, and scaling clusters or servers. You’ll be able to run your Spark functions with out having to plan capability or provision infrastructure, whereas paying solely to your utilization. EMR Serverless helps Iceberg natively to create tables and question, merge, and insert information with Spark. Within the following structure diagram, Spark transformation jobs can load information from the uncooked zone or supply, apply the cleansing and transformation logic, and ingest information within the remodeled zone on Iceberg tables. Spark code can run instantaneously on an EMR Serverless software, which we display later on this put up.
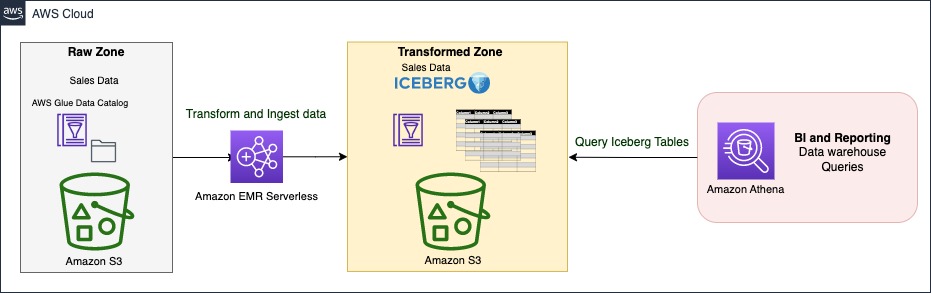
The Iceberg desk is synced with the AWS Glue Information Catalog. The Information Catalog supplies a central location to manipulate and hold observe of the schema and metadata. With Iceberg, ingestion, replace, and querying processes can profit from atomicity, snapshot isolation, and managing concurrency to maintain a constant view of information.
Athena is a serverless, interactive analytics service constructed on open-source frameworks, supporting open-table and file codecs. Athena supplies a simplified, versatile option to analyze petabytes of information the place it lives. To serve BI and reporting evaluation, it permits you to construct and run queries on Iceberg tables natively and integrates with quite a lot of BI instruments.
Gross sales information mannequin
Star schema and its variants are very fashionable for modeling information in information warehouses. They implement a number of truth tables and dimension tables. The very fact desk shops the principle transactional information from the enterprise logic with overseas keys to dimensional tables. Dimension tables maintain extra complementary information to counterpoint the very fact desk.
On this put up, we take the instance of gross sales information from the TPC-DS benchmark. We zoom in on a subset of the schema with the web_sales truth desk, as proven within the following determine. It shops numeric values about gross sales price, ship price, tax, and web revenue. Moreover, it has overseas keys to dimensional tables like date_dim, time_dim, buyer, and merchandise. These dimensional tables retailer data that give extra particulars. As an illustration, you may present when a sale occurred by which buyer for which merchandise.
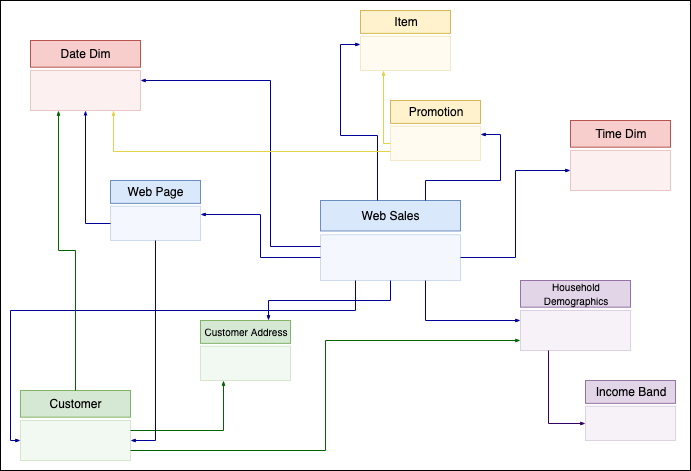
Dimension-based fashions have been used extensively to construct information warehouses. Within the following sections, we present methods to implement such a mannequin on high of Iceberg, offering information warehousing options on high of your information lake, and run completely different workloads in the identical location. We offer an entire instance of constructing a serverless structure with information ingestion utilizing EMR Serverless and Athena utilizing TPC-DS queries.
Conditions
For this walkthrough, you need to have the next conditions:
- An AWS account
- Primary data about information administration and SQL
Deploy answer sources with AWS CloudFormation
We offer an AWS CloudFormation template to deploy the info lake stack with the next sources:
- Two S3 buckets: one for scripts and question outcomes, and one for the info lake storage
- An Athena workgroup
- An EMR Serverless software
- An AWS Glue database and tables on exterior public S3 buckets of TPC-DS information
- An AWS Glue database for the info lake
- An AWS Identification and Entry Administration (IAM) function and polices
Full the next steps to create your sources:
- Launch the CloudFormation stack:
![]()
This robotically launches AWS CloudFormation in your AWS account with the CloudFormation template. It prompts you to check in as wanted.
- Preserve the template settings as is.
- Examine the I acknowledge that AWS CloudFormation would possibly create IAM sources field.
- Select Submit
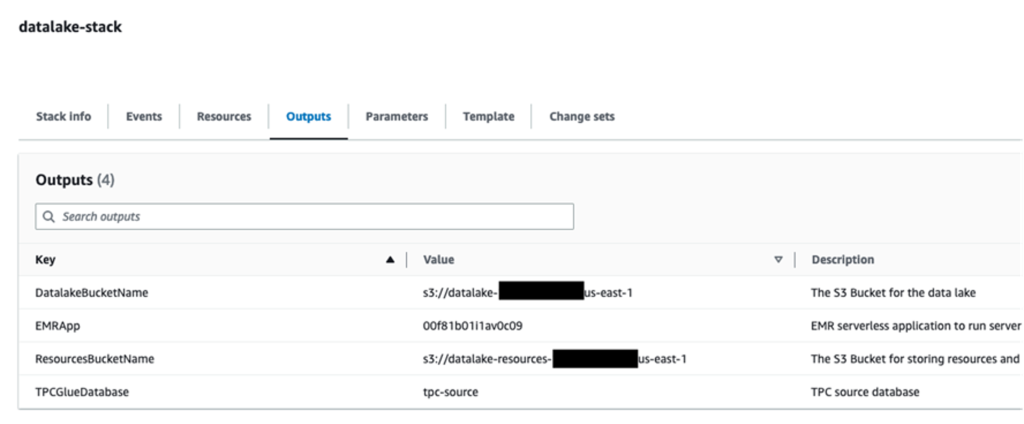
When the stack creation is full, examine the Outputs tab of the stack to confirm the sources created.
Add Spark scripts to Amazon S3
Full the next steps to add your Spark scripts:
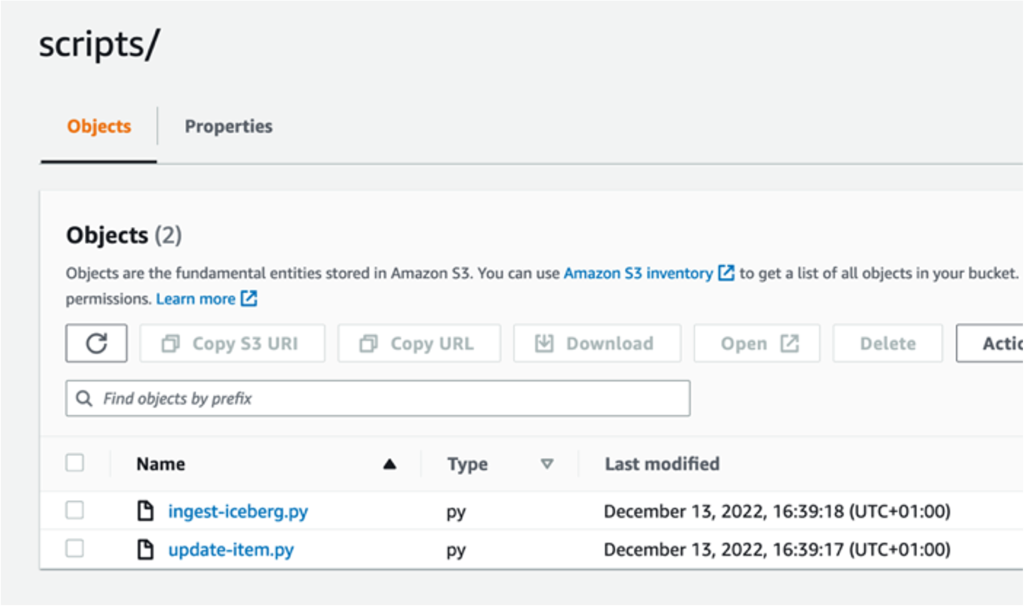
- Obtain the next scripts: ingest-iceberg.py and update-item.py.
- On the Amazon S3 console, go to the
datalake-resources-<AccountID>-us-east-1bucket you created earlier. - Create a brand new folder named
scripts. - Add the 2 PySpark scripts:
ingest-iceberg.pyandupdate-item.py.
Create Iceberg tables and ingest TPC-DS information
To create your Iceberg tables and ingest the info, full the next steps:
- On the Amazon EMR console, select EMR Serverless within the navigation pane.
- Select Handle functions.
- Select the appliance
datalake-app.

- Select Begin software.
As soon as began, it is going to provision the pre-initialized capability as configured at creation (one Spark driver and two Spark executors). The pre-initialized capability are sources that will likely be provisioned while you begin your software. They can be utilized immediately while you submit jobs. Nevertheless, they incur costs even when they’re not used when the appliance is in a began state. By default, the appliance is ready to cease when idle for quarter-hour.
Now that the EMR software has began, we are able to submit the Spark ingest job ingest-iceberg.py. The job creates the Iceberg tables after which masses information from the beforehand created AWS Glue Information Catalog tables on TPC-DS information in an exterior bucket.
- Navigate to the
datalake-app. - On the Job runs tab, select Submit job.
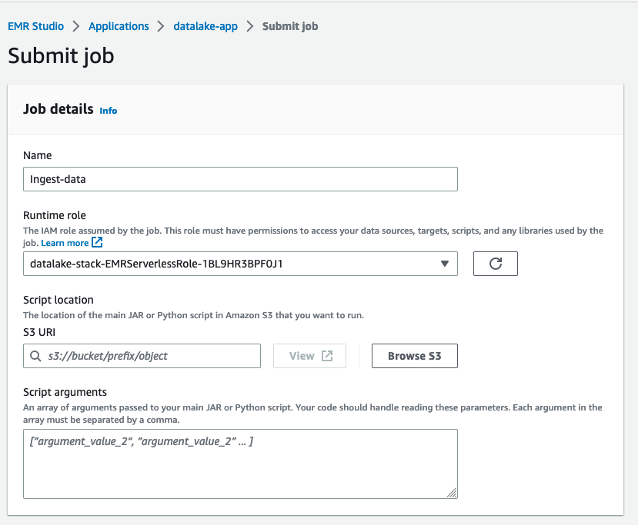
- For Identify, enter
ingest-data. - For Runtime function, select the IAM function created by the CloudFormation stack.
- For Script location, enter the S3 path to your useful resource bucket (
datalake-resource-<####>-us-east-1>scripts>ingest-iceberg.py).
- Below Spark properties, select Edit in textual content.
- Enter the next properties, changing <BUCKET_NAME> together with your information lake bucket title
datalake-<####>-us-east-1(not datalake-resources)
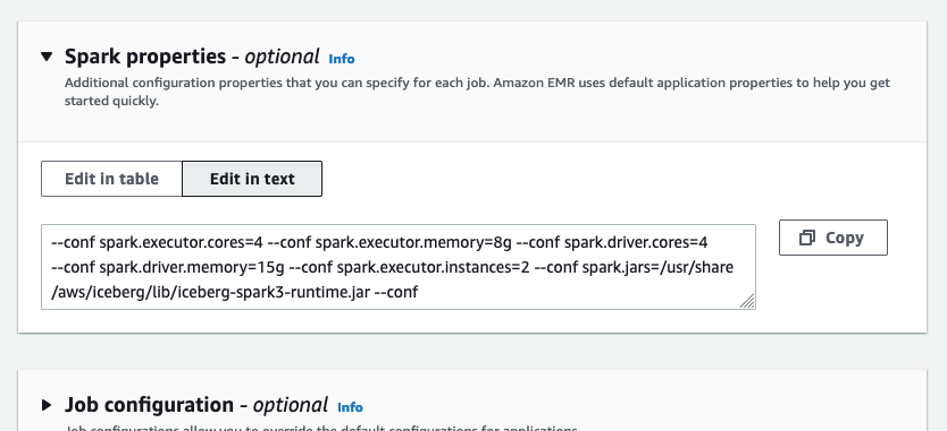
- Submit the job.
You’ll be able to monitor the job progress. 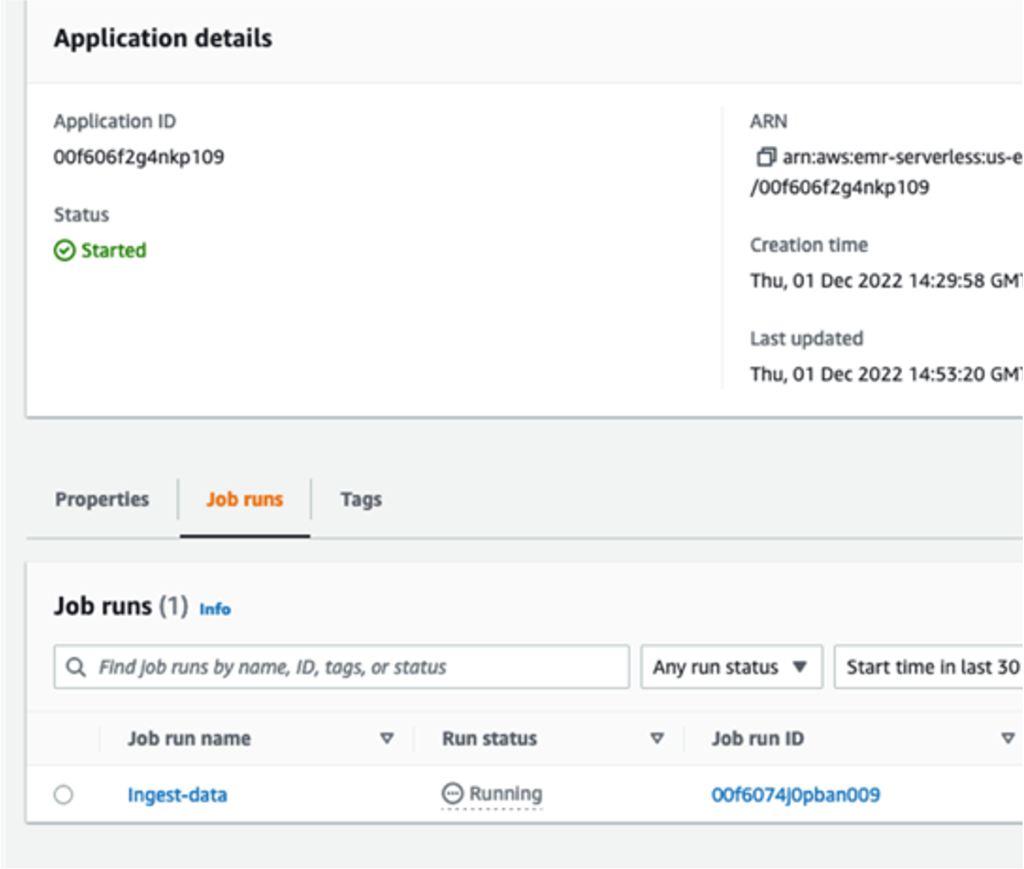
Question Iceberg tables
On this part, we offer examples of information warehouse queries from TPC-DS on the Iceberg tables.
- On the Athena console, open the question editor.
- For Workgroup, swap to
DatalakeWorkgroup.

- Select Acknowledge.
 The queries in
The queries in DatalakeWorkgroup will run on Athena engine model 3.
- On the Saved queries tab, select a question to run in your Iceberg tables.
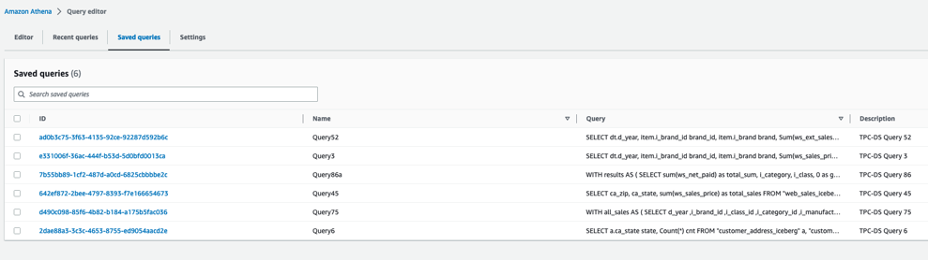 The next queries are listed:
The next queries are listed:
- Query3 – Report the whole prolonged gross sales worth per merchandise model of a particular producer for all gross sales in a particular month of the yr.
- Query45 – Report the whole net gross sales for purchasers in particular zip codes, cities, counties, or states, or particular objects for a given yr and quarter.
- Query52 – Report the whole of prolonged gross sales worth for all objects of a particular model in a particular yr and month.
- Query6 – Checklist all of the states with not less than 10 clients who throughout a given month purchased objects with the worth tag not less than 20% greater than the common worth of things in the identical class.
- Query75 – For two consecutive years, observe the gross sales of things by model, class, and class.
- Query86a – Roll up the online gross sales for a given yr by class and sophistication, and rank the gross sales amongst friends throughout the guardian. For every group, compute the sum of gross sales and site with the hierarchy and rank throughout the group.
These queries are examples of queries utilized in decision-making and reporting in a corporation. You’ll be able to run them within the order you need. For this put up, we begin with Query3.
- Earlier than you run the question, verify that Database is ready to
datalake.

- Now you may run the question.

- Repeat these steps to run the opposite queries.
Replace the merchandise desk
After operating the queries, we put together a batch of updates and inserts of data into the merchandise desk.
- First, run the next question to rely the variety of data within the
merchandiseIceberg desk:
This could return 102,000 data.
- Choose merchandise data with a worth greater than $90:
It will return 1,112 data.
The update-item.py job takes these 1,112 data, modifies 11 data to alter the title of the model to Unknown, and adjustments the remaining 1,101 data’ i_item_id key to flag them as new data. In consequence, a batch of 11 updates and 1,101 inserts are merged into the item_iceberg desk.
The 11 data to be up to date are these with worth greater than $90, and the model title begins with corpnameless.
- Run the next question:
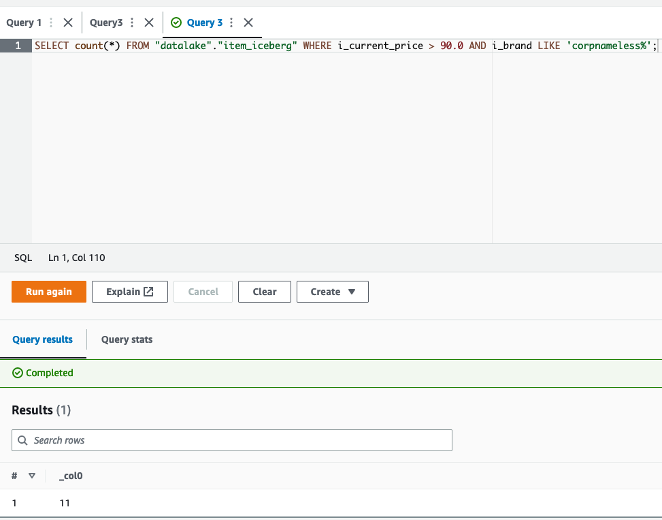
The result’s 11 data. The item_update.py job replaces the model title with Unknown and merges the batch into the Iceberg desk.
Now you may return to the EMR Serverless console and run the job on the EMR Serverless software.
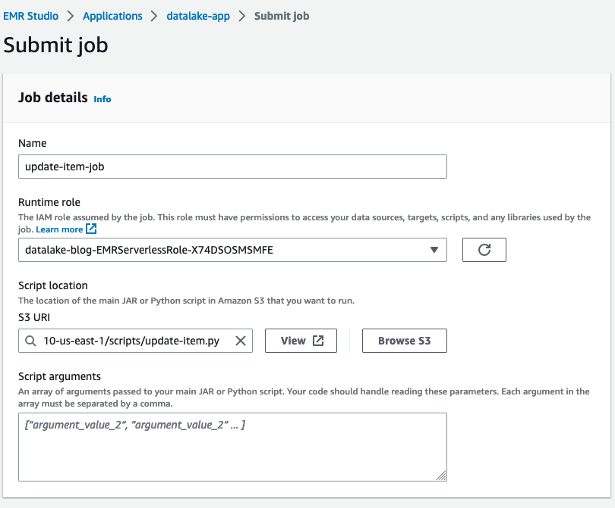
- On the appliance particulars web page, select Submit job.
- For Identify, enter
update-item-job. - For Runtime function¸ use the identical function that you simply used beforehand.
- For S3 URI, enter the
update-item.pyscript location.
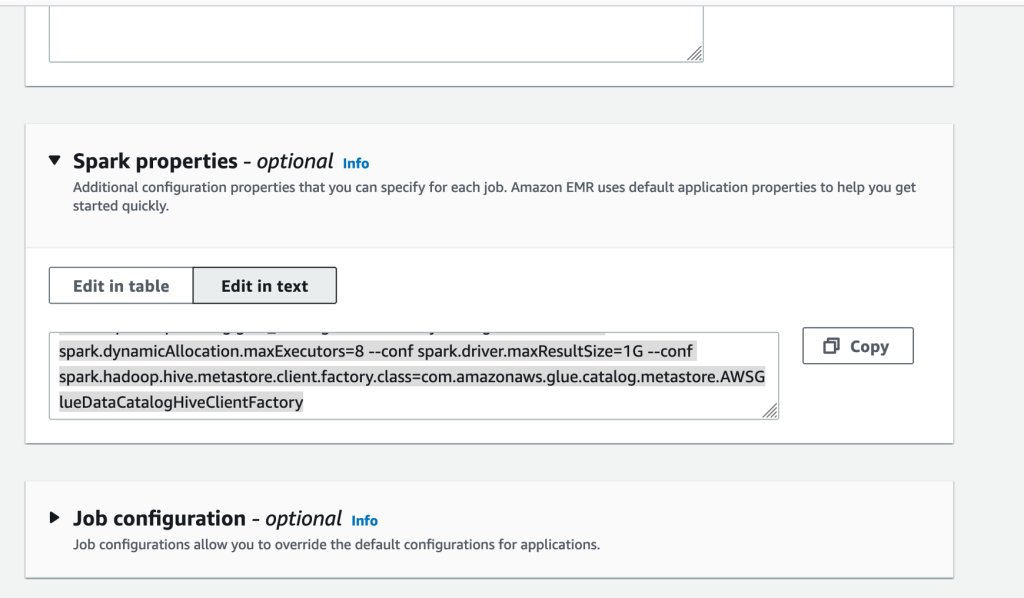
- Below Spark properties, select Edit in textual content.
- Enter the next properties, changing the <BUCKET-NAME> with your individual
datalake-<####>-us-east-1:
- Then submit the job.

- After the job finishes efficiently, return to the Athena console and run the next question:
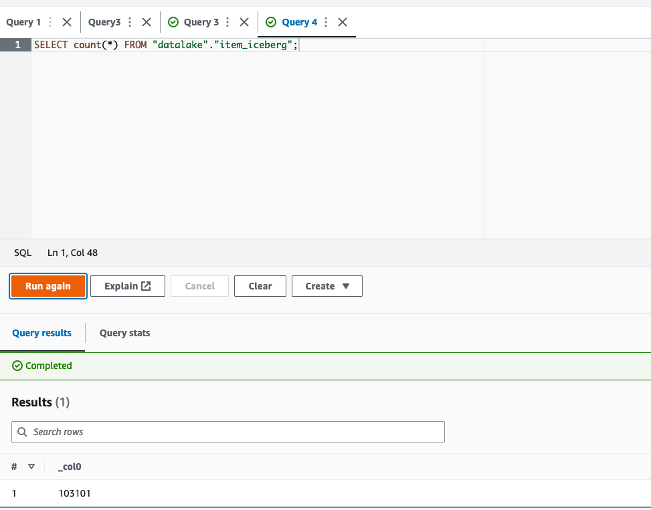
The returned result’s 103,101 = 102,000 + (1,112 – 11). The batch was merged efficiently.
Time journey
To run a time journey question, full the next steps:
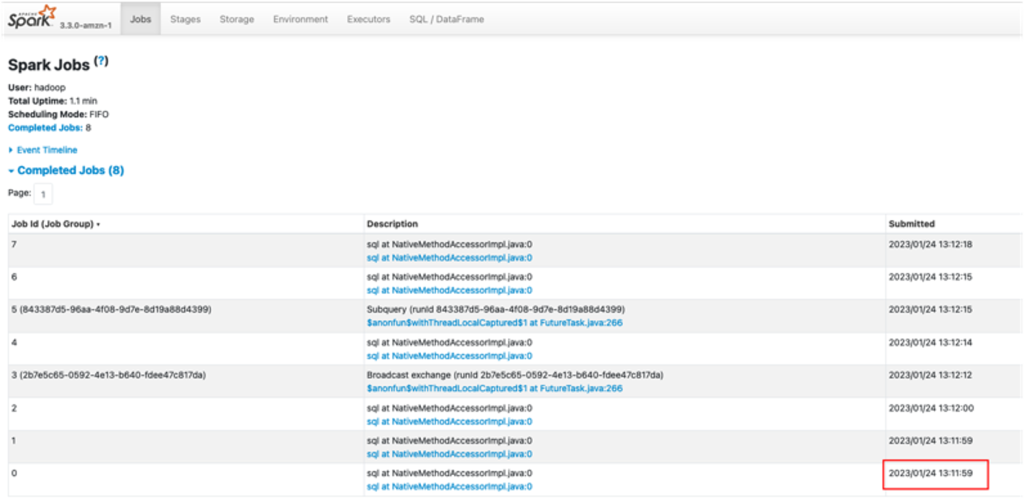
- Get the timestamp of the job run by way of the appliance particulars web page on the EMR Serverless console, or the Spark UI on the Historical past Server, as proven within the following screenshot.
This time could possibly be simply minutes earlier than you ran the replace Spark job.
- Convert the timestamp from the format
YYYY/MM/DD hh:mm:ss to YYYY-MM-DDThh:mm:ss.sTZDwith time zone. For instance, from2023/02/20 14:40:41to2023-02-20 14:40:41.000 UTC. - On the Athena console, run the next question to rely the
merchandisedesk data at a time earlier than the replace job, changing <TRAVEL_TIME> together with your time:
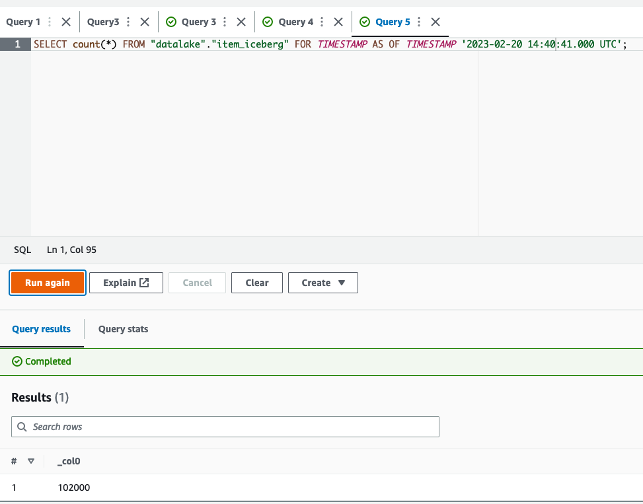
The question will give 102,000 in consequence, the anticipated desk dimension earlier than operating the replace job.
- Now you may run a question with a timestamp after the profitable run of the replace job (for instance,
2023-02-20 15:06:00.000 UTC):
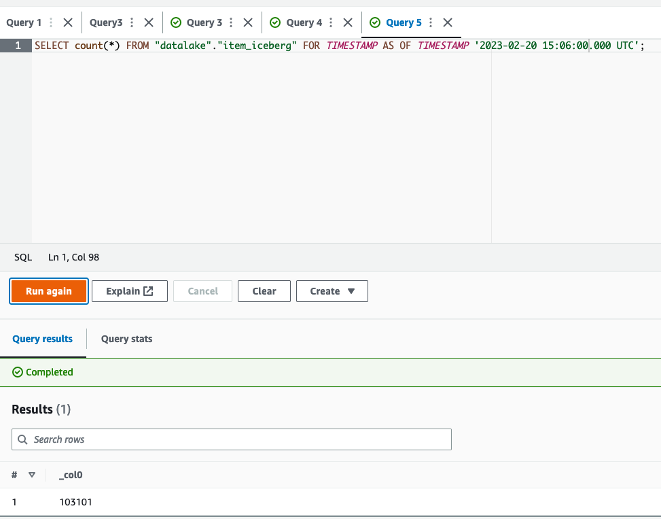
The question will now give 103,101 as the scale of the desk at the moment, after the replace job efficiently completed.
Moreover, you may question in Athena based mostly on the model ID of a snapshot in Iceberg. Nevertheless, for extra superior use circumstances, equivalent to to roll again to a given model or to search out model IDs, you should utilize Iceberg’s SDK or Spark on Amazon EMR.
Clear up
Full the next steps to scrub up your sources:
- On the Amazon S3 console, empty your buckets.
- On the Athena console, delete the workgroup
DatalakeWorkgroup. - On the EMR Studio console, cease the appliance
datalake-app. - On the AWS CloudFormation console, delete the CloudFormation stack.
Conclusion
On this put up, we created a serverless transactional information lake with Iceberg tables, EMR Serverless, and Athena. We used TPC-DS gross sales information with 10 GB information and greater than 7 million data within the truth desk. We demonstrated how simple it’s to depend on SQL and Spark to run serverless jobs for information ingestion and upserts. Furthermore, we confirmed methods to run complicated BI queries immediately on Iceberg tables from Athena for reporting.
You can begin constructing your serverless transactional information lake on AWS at the moment, and dive deep into the options and optimizations Iceberg supplies to construct analytics functions extra simply. Iceberg may also aid you sooner or later to enhance efficiency and scale back prices.
Concerning the Creator

Houssem is a Specialist Options Architect at AWS with a deal with analytics. He’s enthusiastic about information and rising applied sciences in analytics. He holds a PhD on information administration within the cloud. Previous to becoming a member of AWS, he labored on a number of huge information tasks and revealed a number of analysis papers in worldwide conferences and venues.

{kind=link}