
The previous few a long time have witnessed the fast improvement of Optical Character Recognition (OCR) expertise, which has advanced from an educational benchmark activity utilized in early breakthroughs of deep studying analysis to tangible merchandise obtainable in shopper gadgets and to third social gathering builders for every day use. These OCR merchandise digitize and democratize the precious data that’s saved in paper or image-based sources (e.g., books, magazines, newspapers, kinds, road indicators, restaurant menus) in order that they are often listed, searched, translated, and additional processed by state-of-the-art pure language processing methods.
Analysis in scene textual content detection and recognition (or scene textual content recognizing) has been the foremost driver of this fast improvement by way of adapting OCR to pure photos which have extra advanced backgrounds than doc photos. These analysis efforts, nonetheless, give attention to the detection and recognition of every particular person phrase in photos, with out understanding how these phrases compose sentences and articles.
Structure evaluation is one other related line of analysis that takes a doc picture and extracts its construction, i.e., title, paragraphs, headings, figures, tables and captions. These structure evaluation efforts are parallel to OCR and have been largely developed as unbiased methods which might be sometimes evaluated solely on doc photos. As such, the synergy between OCR and structure evaluation stays largely under-explored. We imagine that OCR and structure evaluation are mutually complementary duties that allow machine studying to interpret textual content in photos and, when mixed, may enhance the accuracy and effectivity of each duties.
With this in thoughts, we announce the Competitors on Hierarchical Textual content Detection and Recognition (the HierText Problem), hosted as a part of the seventeenth annual Worldwide Convention on Doc Evaluation and Recognition (ICDAR 2023). The competitors is hosted on the Strong Studying Competitors web site, and represents the primary main effort to unify OCR and structure evaluation. On this competitors, we invite researchers from world wide to construct techniques that may produce hierarchical annotations of textual content in photos utilizing phrases clustered into traces and paragraphs. We hope this competitors could have a major and long-term influence on image-based textual content understanding with the purpose to consolidate the analysis efforts throughout OCR and structure evaluation, and create new indicators for downstream data processing duties.
 |
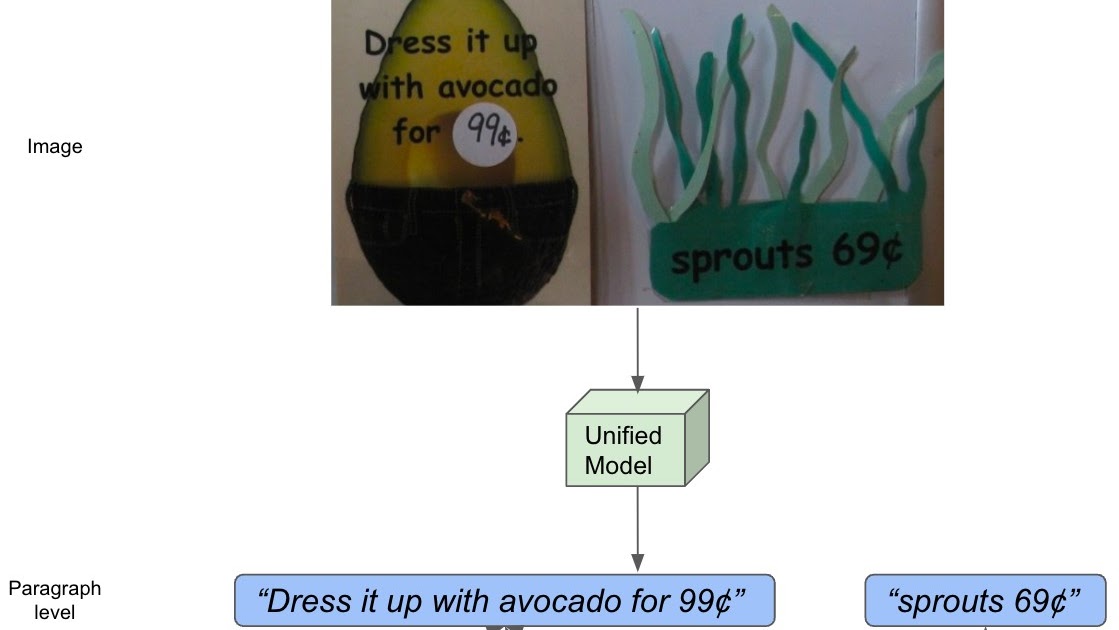
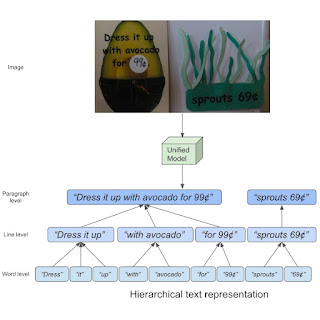
| The idea of hierarchical textual content illustration. |
Establishing a hierarchical textual content dataset
On this competitors, we use the HierText dataset that we printed at CVPR 2022 with our paper “In the direction of Finish-to-Finish Unified Scene Textual content Detection and Structure Evaluation”. It’s the primary real-image dataset that gives hierarchical annotations of textual content, containing phrase, line, and paragraph degree annotations. Right here, “phrases” are outlined as sequences of textual characters not interrupted by areas. “Strains” are then interpreted as “area“-separated clusters of “phrases” which might be logically related in a single course, and aligned in spatial proximity. Lastly, “paragraphs” are composed of “traces” that share the identical semantic subject and are geometrically coherent.
To construct this dataset, we first annotated photos from the Open Photos dataset utilizing the Google Cloud Platform (GCP) Textual content Detection API. We filtered by way of these annotated photos, conserving solely photos wealthy in textual content content material and structure construction. Then, we labored with our third-party companions to manually appropriate all transcriptions and to label phrases, traces and paragraph composition. Consequently, we obtained 11,639 transcribed photos, break up into three subsets: (1) a prepare set with 8,281 photos, (2) a validation set with 1,724 photos, and (3) a check set with 1,634 photos. As detailed within the paper, we additionally checked the overlap between our dataset, TextOCR, and Intel OCR (each of which additionally extracted annotated photos from Open Photos), ensuring that the check photos within the HierText dataset weren’t additionally included within the TextOCR or Intel OCR coaching and validation splits and vice versa. Beneath, we visualize examples utilizing the HierText dataset and show the idea of hierarchical textual content by shading every textual content entity with completely different colours. We are able to see that HierText has a range of picture area, textual content structure, and excessive textual content density.
 |
| Samples from the HierText dataset. Left: Illustration of every phrase entity. Center: Illustration of line clustering. Proper: Illustration paragraph clustering. |
Dataset with highest density of textual content
Along with the novel hierarchical illustration, HierText represents a brand new area of textual content photos. We word that HierText is at present probably the most dense publicly obtainable OCR dataset. Beneath we summarize the traits of HierText as compared with different OCR datasets. HierText identifies 103.8 phrases per picture on common, which is greater than 3x the density of TextOCR and 25x extra dense than ICDAR-2015. This excessive density poses distinctive challenges for detection and recognition, and as a consequence HierText is used as one of many major datasets for OCR analysis at Google.
| Dataset | Coaching break up | Validation break up | Testing break up | Phrases per picture | ||||||||||
| ICDAR-2015 | 1,000 | 0 | 500 | 4.4 | ||||||||||
| TextOCR | 21,778 | 3,124 | 3,232 | 32.1 | ||||||||||
| Intel OCR | 19,1059 | 16,731 | 0 | 10.0 | ||||||||||
| HierText | 8,281 | 1,724 | 1,634 | 103.8 |
| Evaluating a number of OCR datasets to the HierText dataset. |
Spatial distribution
We additionally discover that textual content within the HierText dataset has a way more even spatial distribution than different OCR datasets, together with TextOCR, Intel OCR, IC19 MLT, COCO-Textual content and IC19 LSVT. These earlier datasets are inclined to have well-composed photos, the place textual content is positioned in the course of the photographs, and are thus simpler to determine. Quite the opposite, textual content entities in HierText are broadly distributed throughout the photographs. It is proof that our photos are from extra numerous domains. This attribute makes HierText uniquely difficult amongst public OCR datasets.
 |
| Spatial distribution of textual content cases in numerous datasets. |
The HierText problem
The HierText Problem represents a novel activity and with distinctive challenges for OCR fashions. We invite researchers to take part on this problem and be a part of us in ICDAR 2023 this yr in San Jose, CA. We hope this competitors will spark analysis neighborhood curiosity in OCR fashions with wealthy data representations which might be helpful for novel down-stream duties.
Acknowledgements
The core contributors to this challenge are Shangbang Lengthy, Siyang Qin, Dmitry Panteleev, Alessandro Bissacco, Yasuhisa Fujii and Michalis Raptis. Ashok Popat and Jake Walker supplied worthwhile recommendation. We additionally thank Dimosthenis Karatzas and Sergi Robles from Autonomous College of Barcelona for serving to us arrange the competitors web site.

{kind=link}