

Machine Imaginative and prescient has come a great distance because the days of “how can a pc acknowledge this picture as an apple.” There are numerous instruments out there that may simply assist to establish the contents of a picture. This matter was coated within the earlier article Picture Recognition in Python and SQL Server, wherein an answer to programmatically figuring out a picture by its contents was offered. Optical Character Recognition (OCR) takes this a step additional, by permitting builders to extract the textual content offered in a picture. Extracting the textual content would permit for the textual content to be indexable and searchable. We can be protecting this matter in at the moment’s Python programming tutorial.
You may learn extra about picture recognition in our tutorial: Picture Recognition in Python and SQL Server.
What’s OCR?
OCR – or Optical Character Recognition – had been fairly a sizzling matter within the long-past days of digitizing paper artifacts corresponding to paperwork, newspapers and different such bodily media, however, as paper has passed by the wayside, OCR, whereas persevering with to be a sizzling analysis matter, briefly moved to the again burner as a “popular culture know-how.”
Using screenshots as a note-taking methodology modified that trajectory. Shoppers of knowledge sometimes don’t need to obtain PowerPoint shows and search by them. They merely take pictures of the slides they’re concerned about and save them for later. Recognizing the textual content in these pictures has grow to be a normal characteristic of most photograph administration software program. However how would a developer combine this know-how into his or her personal software program venture?
Google’s Tesseract providing provides software program builders entry to a “business grade” OCR software program at a “cut price basement” worth. Tesseract is open-source and supplied beneath the Apache 2.0 license which supplies builders a large berth in how this software program will be included in their very own choices. This software program improvement tutorial will concentrate on implementing Tesseract inside an Ubuntu Linux setting, since that is the simplest setting for a newbie to take advantage of.
OCR is Not a Silver Bullet
Earlier than stepping into the technical particulars, you will need to dispense with the concept that OCR can all the time magically learn all the textual content in a picture. Even with many years of exhausting work going into researching this, there are nonetheless cases wherein OCR might not be the most effective resolution for textual content extraction. There could also be conditions wherein totally different OCR software program could also be needed relying on the use case. Tesseract particularly might require further “coaching” (its jargon) to be higher at studying textual content information from photos. Tesseract all the time works higher with 300dpi (dots per inch) or larger photos. That is sometimes printing high quality versus internet high quality. You may additionally must “therapeutic massage” an enter picture earlier than it might be learn appropriately.
Nonetheless, out of the field, Tesseract will be “adequate” for the needs of extracting simply sufficient textual content from a picture to be able to accomplish what it’s possible you’ll must do in your software program software.
Learn: Greatest Python IDE and Code Editors
How one can Set up Tesseract
Putting in Tesseract in Debian-based Linux is straightforward. It’s installable as a software program package deal. For Debian-based Linux distributions corresponding to Kali or Ubuntu, use the next command:
$ sudo apt set up tesseract-ocr
Should you run into points putting in Tesseract on this method, it’s possible you’ll must replace your Linux set up as follows:
$ sudo apt replace -y; sudo apt improve -y
For different Linux distributions, Home windows or MacOS, it is going to be essential to construct from supply.
How one can Run Tesseract from the Command Line
As soon as Tesseract is put in, it may be run immediately from a terminal. Take into account the next photos, together with the textual content output generated by Tesseract. To show the extracted textual content in commonplace output, use the next command:
$ tesseract imageFile stdout
Listed below are some instance outputs, together with the unique picture with textual content. These come from slides which are sometimes the sorts that college students may take footage of in a classroom setting:
Instance 1

Instance 2
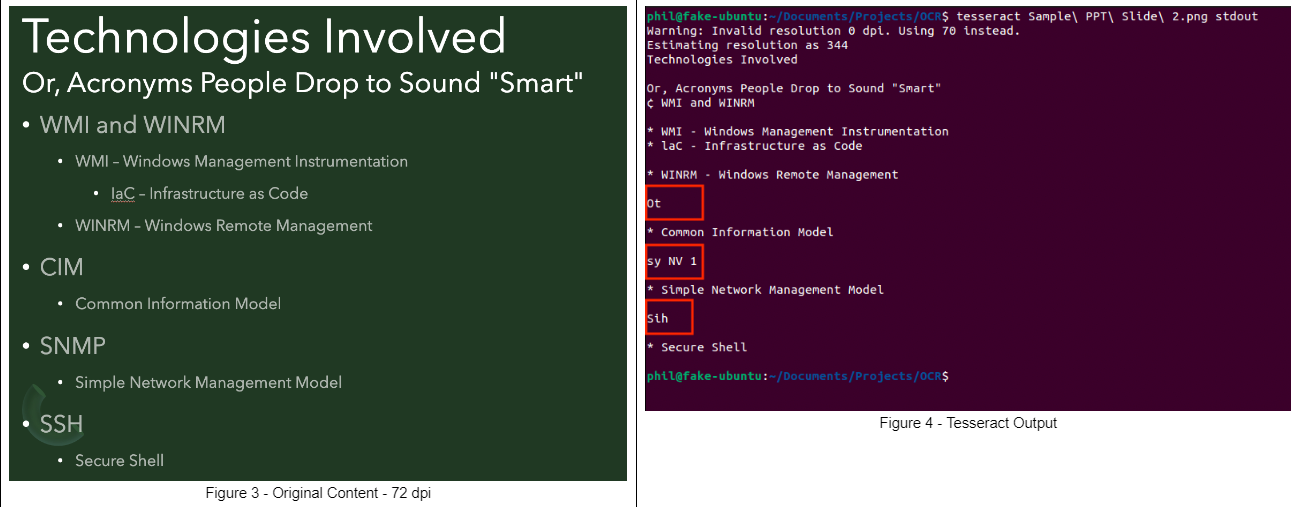
Instance 3

In every of the examples above, the textual content which “didn’t fairly” get captured precisely is highlighted with purple rectangles. That is doubtless as a result of presentation high quality picture dpi (72 dpi) used for these photos. As you may see beneath, some photos are learn higher than others:
Instance 4
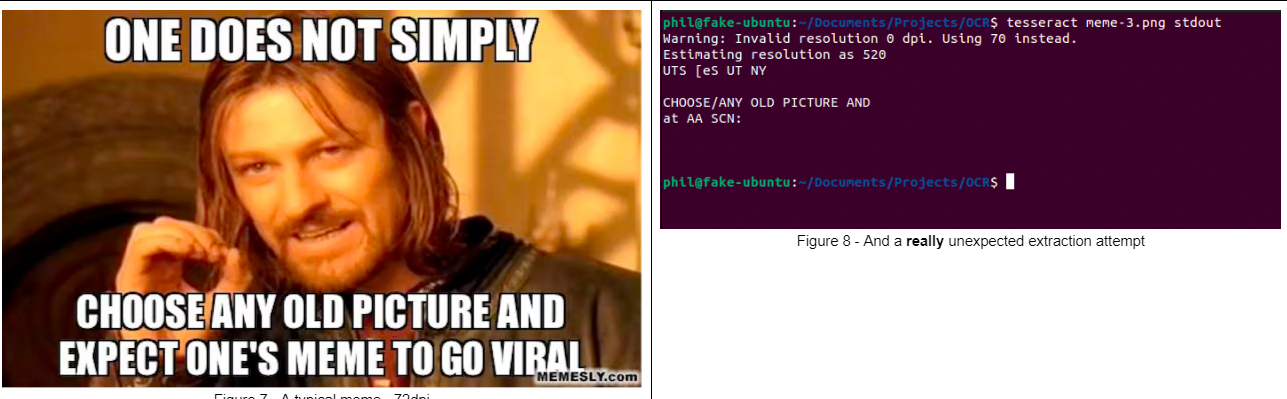 Observe: The above shouldn’t be a defect in Tesseract. It’s potential to “practice” Tesseract to acknowledge totally different fonts. Additionally, in case you are scanning paperwork, you may configure your scanner to learn at larger dpi ranges.
Observe: The above shouldn’t be a defect in Tesseract. It’s potential to “practice” Tesseract to acknowledge totally different fonts. Additionally, in case you are scanning paperwork, you may configure your scanner to learn at larger dpi ranges.
Programmatic Textual content Extraction in Python with pytessract
Naturally, extracting textual content inside the context of a program is the subsequent logical step. Whereas it’s all the time potential to make use of system calls from inside Python or another language to be able to execute the Tesseract program, it’s way more elegant to make use of an API to deal with such calls as a substitute.
One vital factor to notice: Whereas it isn’t “verboten” to name Tesseract through system calls in a programming language, you should take care to make sure that no unchecked consumer enter is handed to that system name. If no such checks are carried out, then it’s potential for an exterior consumer to run instructions in your system with a well-constructed filename or different info.
The Python module pytesseract offers a wrapper to the Tesseract software. pytesseract will be put in through the command:
$ pip3 set up pytesseract
Observe that should you entry Python 3.x through the python command versus python3, you’ll need to make use of the command:
$ pip set up pytesseract
The next pattern code will extract all of the textual content it will probably discover from any picture file within the present listing utilizing Python and pytesseract:
#!/usr/bin/python3
# mass-ocr-images.py
from PIL import Picture
import os
import pytesseract
import sys
# It's essential to specify the total path to the tesseract executable.
# In Linux, you will get this through the use of the command:
# which tesseract
pytesseract.pytesseract.tesseract_cmd = r'/usr/bin/tesseract'
def principal(argv):
for filename in os.listdir("."):
if str(filename) not in ['.', '..']:
nameParts = str(filename).break up(".")
if nameParts[-1].decrease() in ["gif", "png", "jpg", "jpeg", "tif", "tiff"]:
# Calls to the API ought to all the time be bounded by a timeout, simply in case.
strive:
print ("Discovered filename [" + str(filename) + "]")
ocrText = pytesseract.image_to_string(str(filename), timeout=5)
print (ocrText)
print ("")
besides Exception as err:
print ("Processing of [" + str(filename) + "] failed resulting from error [" + str(err) + "]")
if __name__ == "__main__":
principal(sys.argv[1:])
Utilizing a Database to Retailer Photographs and Extracted Textual content in Python
We will use a database to retailer each the photographs and the extracted textual content. This can permit for builders to write down an software that may search in opposition to the textual content and inform us which picture matches this textual content. The next code extends the primary itemizing by saving the collected information right into a MariaDB database:
#!/usr/bin/python3
# ocr-import-images.py
from PIL import Picture
import mysql.connector
import os
import pytesseract
import shutil
import sys
# It's essential to specify the total path to the tesseract executable.
# In Linux, you will get this through the use of the command:
# which tesseract
pytesseract.pytesseract.tesseract_cmd = r'/usr/bin/tesseract'
def principal(argv):
strive:
conn = mysql.connector.join(consumer="rd_user", password='myPW1234%', host="127.0.0.1", port=63306,
database="RazorDemo")
cursor = conn.cursor()
for filename in os.listdir("."):
if str(filename) not in ['.', '..']:
nameParts = str(filename).break up(".")
if nameParts[-1].decrease() in ["gif", "png", "jpg", "jpeg", "tif", "tiff"]:
# Calls to the API ought to all the time be bounded by a timeout, simply in case.
strive:
print ("Discovered filename [" + str(filename) + "]")
ocrText = pytesseract.image_to_string(str(filename), timeout=5)
fout = open("temp.txt", "w")
fout.write (ocrText)
fout.shut()
# Insert the database document:
sql0 = "insert into Photographs (file_name) values (%s)"
values0 = [str(filename)]
cursor.execute(sql0, values0)
conn.commit()
# We want the first key identifier created by the final insert so we are able to insert the extracted
# textual content and binary information.
lastInsertID = cursor.lastrowid
print ("Rcdid of insert is [" + str(lastInsertID) + "]")
# We have to copy the picture file and the textual content file to a listing that's readable by the
# database.
shutil.copyfile("temp.txt", "/tmp/db-tmp/temp.txt")
shutil.copyfile(str(filename), "/tmp/db-tmp/" + str(filename))
# Additionally, FILE privileges could also be wanted for the MariaDB consumer account:
# grant file on *.* to 'rd_user'@'%';
# flush privileges;
sql1 = "replace Photographs set extracted_text=LOAD_FILE(%s), file_data=LOAD_FILE(%s) the place rcdid=%s"
values1 = ["/tmp/db-tmp/temp.txt", "/tmp/db-tmp/" + str(filename), str(lastInsertID)]
cursor.execute(sql1, values1)
conn.commit()
os.take away("/tmp/db-tmp/temp.txt")
os.take away("/tmp/db-tmp/" + str(filename))
besides Exception as err:
print ("Processing of [" + str(filename) + "] failed resulting from error [" + str(err) + "]")
cursor.shut()
conn.shut()
besides Exception as err:
print ("Processing failed resulting from error [" + str(err) + "]")
if __name__ == "__main__":
principal(sys.argv[1:])
The Python code instance above interacts with a MariaDB desk that has the next construction:
create desk Photographs (rcdid int not null auto_increment major key, file_name varchar(255) not null, extracted_text longtext null, file_data longblob null);
Within the code instance above, longtext and longblob have been chosen as a result of these information sorts are supposed to level to massive volumes of textual content or binary information, respectively.
How one can Load File Knowledge into MariaDB
Loading binary or non-standard textual content into any database can pose all kinds of challenges, particularly if textual content encoding is a priority. In hottest RDBMS, binary information is sort of by no means inserted into or up to date in a database document through a typical insert assertion that’s used for different kinds of knowledge. As an alternative, specialised statements are used for such duties.
For MariaDB, particularly, FILE permissions are required for any such operations. These aren’t assigned in a typical GRANT assertion that grants privileges on a database to a consumer account. As an alternative, FILE permissions should be granted to the server itself, with a separate set of instructions. To do that in MariaDB for the rd_user account utilized in our second code instance, it is going to be essential to log into MariaDB with its root account and execute the next instructions:
grant file on *.* to 'rd_user'@'%'; flush privileges;
As soon as FILE permissions are granted, the LOAD FILE command can be utilized to load longtext or longblob information into a specific current document. The next instance present the right way to connect longtext or longblob information to an current document in a MariaDB database:
-- For the extracted textual content, which might comprise non-standard characters.
replace Photographs set extracted_text=LOAD_FILE('/tmp/take a look at.txt') the place rcdid=rcdid
-- For the binary picture information
replace Photographs set file_data=LOAD_FILE('/tmp/myImage.png') the place rcdid=rcdid
Should you use a typical choose * assertion on this information after operating these updates, then you’ll get a consequence that’s not terribly helpful:

As an alternative, choose substrings of the information:
![]()
The results of this question is extra helpful, at the very least for guaranteeing the information populated:

To extract this information again into recordsdata, use specialised choose statements, as proven beneath:
choose extracted_text into dumpfile '/tmp/ppt-slide-3-text.txt' from Photographs the place rcdid=117; choose file_data into dumpfile '/tmp/Pattern PPT Slide 3.png' from Photographs the place rcdid=117;
Observe that, other than writing the output to the recordsdata above, there is no such thing as a “particular output” from both of those queries.
The listing into which the recordsdata can be created should be writable by the consumer account beneath which the MariaDB daemon is operating. Recordsdata with the identical names as extracted recordsdata can not exist already.
The file information ought to match what was initially loaded:

The picture may also match:

The picture as learn from the database, together with utilizing the fim command to view it.
These SQL Statements can then be integrated into an exterior software for the needs of retrieving this info.
How one can Question Photographs in a Database
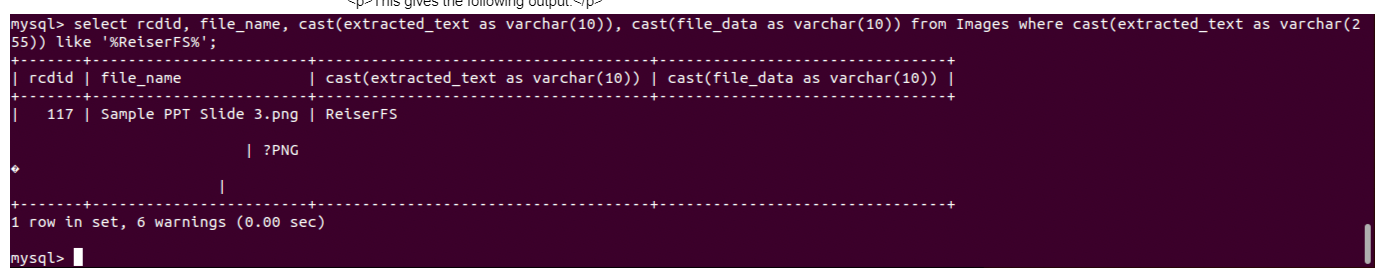
With the photographs loaded into the database, together with their extracted OCR textual content, typical SQL queries can be utilized to discover a specific picture:

Observe that, in MariaDB, typical textual content comparisons don’t work with longtext columns. These should be forged as varchars.
This provides the next output:
Last Ideas on Extracting Textual content from Photographs with Python and MariaDB
Google’s Tesseract providing can simply permit so that you can incorporate on-the-fly OCR into your purposes. This can permit to your customers to extra simply and extra readily have the ability to extract and use the textual content that could be contained in these photos. However out-of-the-box Tesseract can go a lot, a lot additional. For all the “gibberish” outcomes proven above, Tesseract will be educated by a developer to learn characters that it can not acknowledge, additional extending its usability.
Given how applied sciences corresponding to AI have gotten extra mainstream, it isn’t too far of a stretch to think about that OCR will solely get higher and simpler to do as time goes on, however Tesseract is a good start line. OCR is already used for complicated duties like “on the fly” language translation. That was thought-about unimaginable not that way back. Who is aware of how a lot additional we are able to go?
Learn extra Python programming tutorials and guides to software program improvement.

{kind=link}