

Immediately many individuals have digital entry to their medical data, together with their physician’s medical notes. Nevertheless, medical notes are onerous to grasp due to the specialised language that clinicians use, which incorporates unfamiliar shorthand and abbreviations. In actual fact, there are literally thousands of such abbreviations, a lot of that are particular to sure medical specialities and locales or can imply a number of issues in numerous contexts. For instance, a physician may write of their medical notes, “pt referred to pt for lbp“, which is supposed to convey the assertion: “Affected person referred to bodily remedy for low again ache.” Arising with this translation is hard for laypeople and computer systems as a result of some abbreviations are unusual in on a regular basis language (e.g., “lbp” means “low again ache”), and even acquainted abbreviations, comparable to “pt” for “affected person”, can have alternate meanings, comparable to “bodily remedy.” To disambiguate between a number of meanings, the encircling context should be thought of. It’s no straightforward process to decipher all of the meanings, and prior analysis means that increasing the shorthand and abbreviations may also help sufferers higher perceive their well being, diagnoses, and coverings.
In “Deciphering medical abbreviations with a privateness defending machine studying system”, printed in Nature Communications, we report our findings on a normal technique that deciphers medical abbreviations in a approach that’s each state-of-the-art and is on-par with board licensed physicians on this process. We constructed the mannequin utilizing solely public information on the net that wasn’t related to any affected person (i.e., no doubtlessly delicate information) and evaluated efficiency on actual, de-identified notes from inpatient and outpatient clinicians from totally different well being methods. To allow the mannequin to generalize from web-data to notes, we created a technique to algorithmically re-write giant quantities of web textual content to look as if it have been written by a physician (referred to as web-scale reverse substitution), and we developed a novel inference technique, (referred to as elicitive inference).
 |
| The mannequin enter is a string that will or might not include medical abbreviations. We educated a mannequin to output a corresponding string by which all abbreviations are concurrently detected and expanded. If the enter string doesn’t include an abbreviation, the mannequin will output the unique string. By Rajkomar et al used underneath CC BY 4.0/ Cropped from authentic. |
Rewriting Textual content to Embrace Medical Abbreviations
Constructing a system to translate medical doctors’ notes would often begin with a big, consultant dataset of medical textual content the place all abbreviations are labeled with their meanings. However no such dataset for normal use by researchers exists. We due to this fact sought to develop an automatic technique to create such a dataset however with out the usage of any precise affected person notes, which could embody delicate information. We additionally wished to make sure that fashions educated on this information would nonetheless work nicely on actual medical notes from a number of hospital websites and sorts of care, comparable to each outpatient and inpatient.
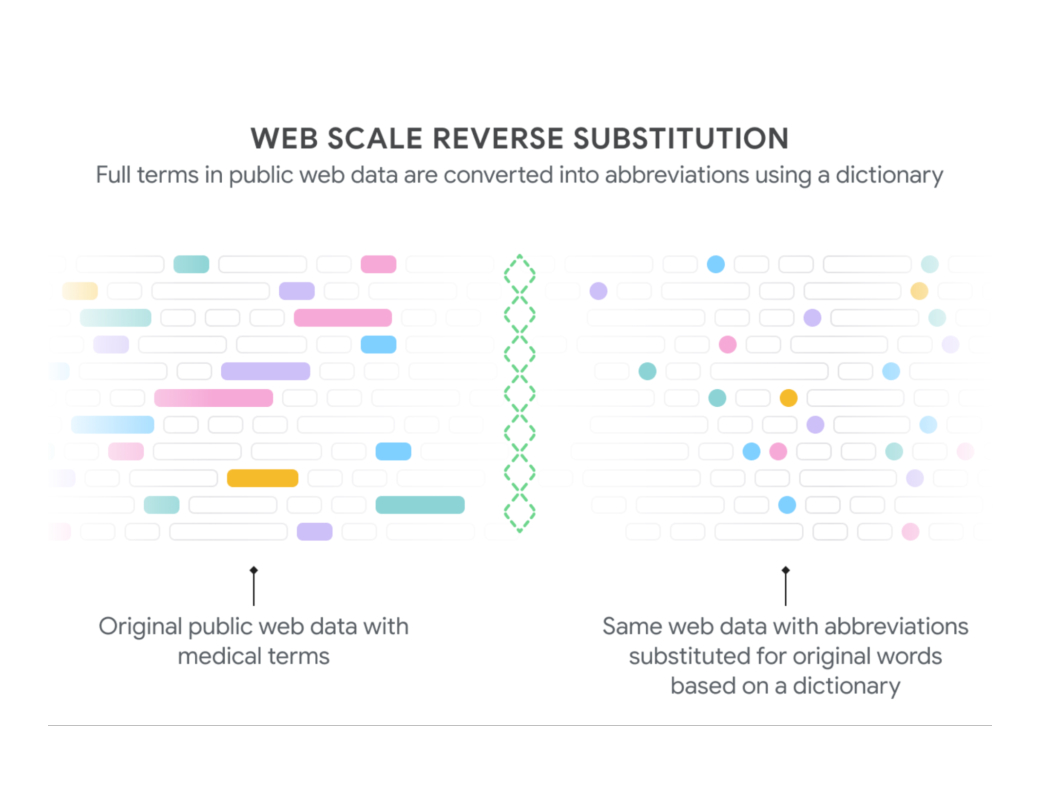
To do that, we referenced a dictionary of hundreds of medical abbreviations and their expansions, and located sentences on the net that contained makes use of of the expansions from this dictionary. We then “rewrote” these sentences by abbreviating every enlargement, leading to internet information that regarded prefer it was written by a physician. For example, if a web site contained the phrase “sufferers with atrial fibrillation can have chest ache,” we might rewrite this sentence to “pts with af can have cp.” We then used the abbreviated textual content as enter to the mannequin, with the unique textual content serving because the label. This method offered us with giant quantities of knowledge to coach our mannequin to carry out abbreviation enlargement.
The concept of “reverse substituting” the long-forms for his or her abbreviations was launched in prior analysis, however our distributed algorithm permits us to increase the method to giant, web-sized datasets. Our algorithm, referred to as web-scale reverse substitution (WSRS), is designed to make sure that uncommon phrases happen extra incessantly and customary phrases are down-sampled throughout the general public internet to derive a extra balanced dataset. With this information in-hand, we educated a collection of enormous transformer-based language fashions to broaden the net textual content.
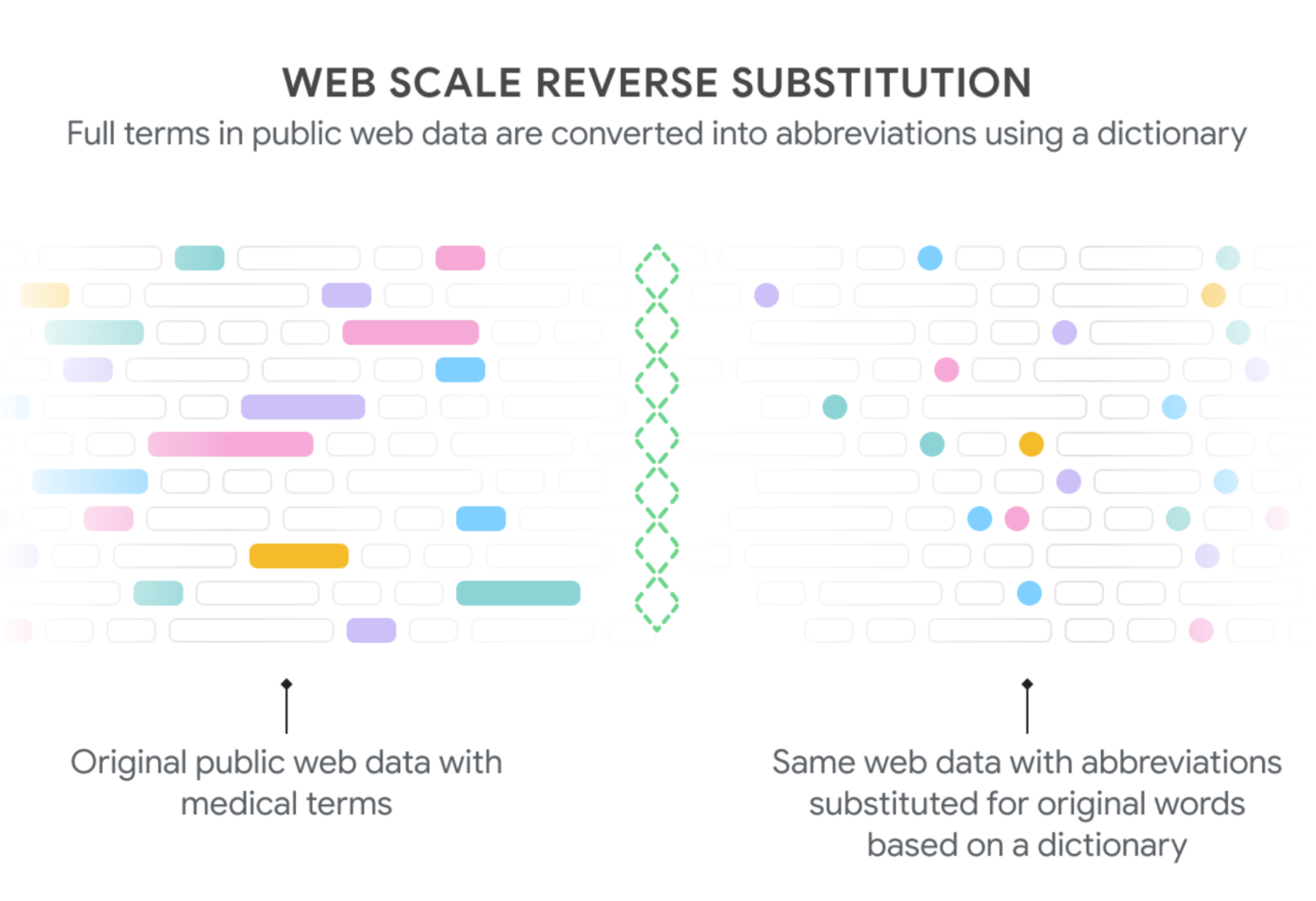 |
| We generate textual content to coach our mannequin on the decoding process by extracting phrases from public internet pages which have corresponding medical abbreviations (shaded containers on the left) after which substituting within the acceptable abbreviations (shaded dots, proper). Since some phrases are discovered way more incessantly than others (“affected person” greater than “posterior tibialis”, each of which will be abbreviated “pt”), we downsampled widespread expansions to derive a extra balanced dataset throughout the hundreds of abbreviations. By Rajkomar et al used underneath CC BY 4.0. |
Adapting Protein Alignment Algorithms to Unstructured Medical Textual content
Analysis of those fashions on the actual process of abbreviation enlargement is tough. As a result of they produce unstructured textual content as output, we had to determine which abbreviations within the enter correspond to which enlargement within the output. To attain this, we created a modified model of the Needleman Wunsch algorithm, which was initially designed for divergent sequence alignment in molecular biology, to align the mannequin enter and output and extract the corresponding abbreviation-expansion pairs. Utilizing this alignment method, we have been in a position to consider the mannequin’s capability to detect and broaden abbreviations precisely. We evaluated Textual content-to-Textual content Switch Transformer (T5) fashions of assorted sizes (starting from 60 million to over 60 billion parameters) and located that bigger fashions carried out translation higher than smaller fashions, with the most important mannequin attaining the finest efficiency.
Creating New Mannequin Inference Methods to Coax the Mannequin
Nevertheless, we did discover one thing sudden. Once we evaluated the efficiency on a number of exterior take a look at units from actual medical notes, we discovered the fashions would go away some abbreviations unexpanded, and for bigger fashions, the issue of incomplete enlargement was even worse. That is primarily attributable to the truth that whereas we substitute expansions on the net for his or her abbreviations, now we have no approach of dealing with the abbreviations which are already current. Because of this the abbreviations seem in each the unique and rewritten textual content used as respective labels and enter, and the mannequin learns to not broaden them.
To deal with this, we developed a brand new inference-chaining method by which the mannequin output is fed once more as enter to coax the mannequin to make additional expansions so long as the mannequin is assured within the enlargement. In technical phrases, our best-performing method, which we name elicitive inference, entails analyzing the outputs from a beam search above a sure log-likelihood threshold. Utilizing elicitive inference, we have been in a position to obtain state-of-the-art functionality of increasing abbreviations in a number of exterior take a look at units.
 |
| Actual instance of the mannequin’s enter (left) and output (proper). |
Comparative Efficiency
We additionally sought to grasp how sufferers and medical doctors at the moment carry out at deciphering medical notes, and the way our mannequin in contrast. We discovered that lay individuals (individuals with out particular medical coaching) demonstrated lower than 30% comprehension of the abbreviations current within the pattern medical texts. Once we allowed them to make use of Google Search, their comprehension elevated to just about 75%, nonetheless leaving 1 out of 5 abbreviations indecipherable. Unsurprisingly, medical college students and educated physicians carried out significantly better on the process with an accuracy of 90%. We discovered that our largest mannequin was able to matching or exceeding consultants, with an accuracy of 98%.
How does the mannequin carry out so nicely in comparison with physicians on this process? There are two necessary elements within the mannequin’s excessive comparative efficiency. A part of the discrepancy is that there have been some abbreviations that clinicians didn’t even try to broaden (comparable to “cm” for centimeter), which partly lowered the measured efficiency. This may appear unimportant, however for non-english audio system, these abbreviations will not be acquainted, and so it might be useful to have them written out. In distinction, our mannequin is designed to comprehensively broaden abbreviations. As well as, clinicians are accustomed to abbreviations they generally see of their speciality, however different specialists use shorthand that aren’t understood by these outdoors their fields. Our mannequin is educated on hundreds of abbreviations throughout a number of specialities and due to this fact can decipher a breadth of phrases.
In the direction of Improved Well being Literacy
We expect there are quite a few avenues by which giant language fashions (LLMs) may also help advance the well being literacy of sufferers by augmenting the knowledge they see and skim. Most LLMs are educated on information that doesn’t appear to be medical be aware information, and the distinctive distribution of this information makes it difficult to deploy these fashions in an out-of-the-box vogue. Now we have demonstrated find out how to overcome this limitation. Our mannequin additionally serves to “normalize” medical be aware information, facilitating further capabilities of ML to make the textual content simpler for sufferers of all instructional and health-literacy ranges to grasp.
Acknowledgements
This work was carried out in collaboration with Yuchen Liu, Jonas Kemp, Benny Li, Ming-Jun Chen, Yi Zhang, Afroz Mohiddin, and Juraj Gottweis. We thank Lisa Williams, Yun Liu, Arelene Chung, and Andrew Dai for a lot of helpful conversations and discussions about this work.

{kind=link}