

We not too long ago constructed the Berkeley Crossword Solver (BCS), the primary pc program to beat each human competitor on this planet’s prime crossword match. The BCS combines neural query answering and probabilistic inference to realize near-perfect efficiency on most American-style crossword puzzles, just like the one proven beneath:

Determine 1: Instance American-style crossword puzzle
Crosswords are difficult for people and computer systems alike. Many clues are obscure or underspecified and may’t be answered till crossing constraints are taken under consideration. Whereas some clues are much like factoid query answering, others require relational reasoning or understanding troublesome wordplay.
Listed here are a handful of instance clues from our dataset (solutions on the backside of this publish):
- They’re given out at Berkeley’s HAAS Faculty (4)
- Winter hrs. in Berkeley (3)
- Area ender that UC Berkeley was one of many first faculties to undertake (3)
- Angeleno at Berkeley, say (8)
The BCS makes use of a two-step course of to unravel crossword puzzles. First, it generates a chance distribution over doable solutions to every clue utilizing a query answering (QA) mannequin; second, it makes use of probabilistic inference, mixed with native search and a generative language mannequin, to deal with conflicts between proposed intersecting solutions.
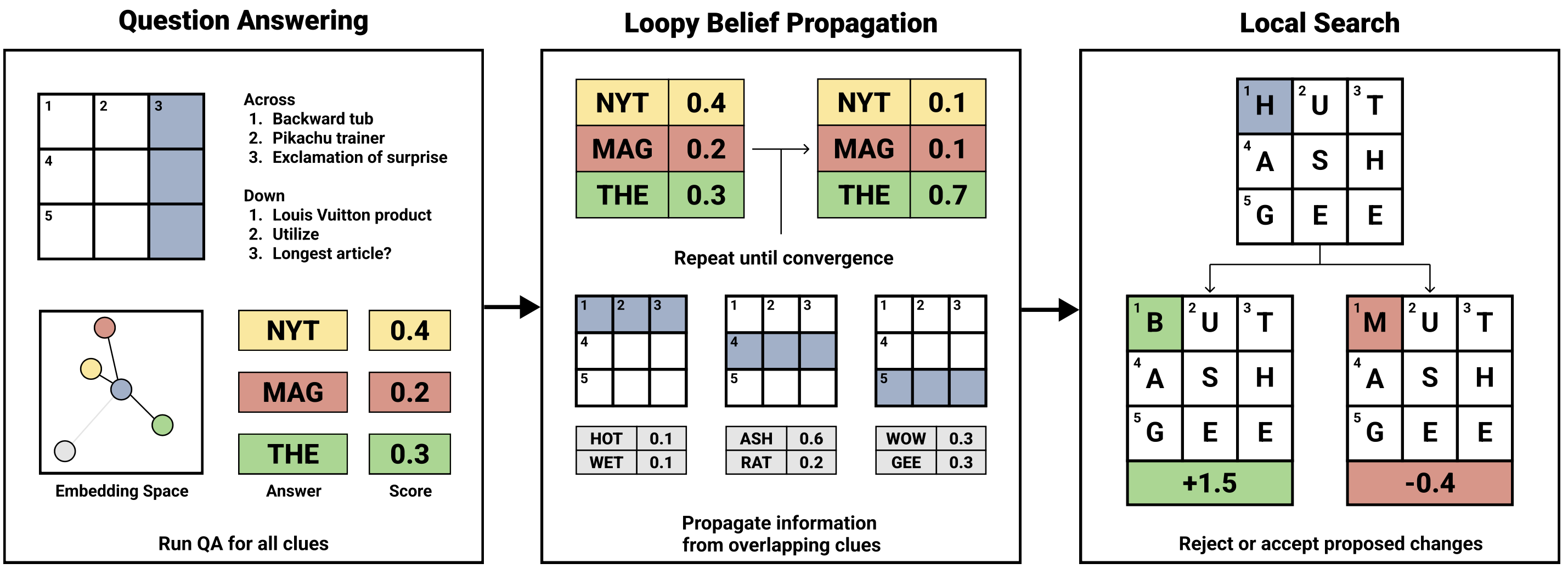
Determine 2: Structure diagram of the Berkeley Crossword Solver
The BCS’s query answering mannequin is predicated on DPR [Karpukhin et al., 2020], which is a bi-encoder mannequin sometimes used to retrieve passages which can be related to a given query. Slightly than passages, nonetheless, our method maps each questions and solutions right into a shared embedding area and finds solutions instantly. In comparison with the earlier state-of-the-art methodology for answering crossword clues, this method obtained a 13.4% absolute enchancment in top-1000 QA accuracy. We performed a guide error evaluation and located that our QA mannequin sometimes carried out nicely on questions involving data, commonsense reasoning, and definitions, however it typically struggled to know wordplay or theme-related clues.
After operating the QA mannequin on every clue, the BCS runs crazy perception propagation to iteratively replace the reply possibilities within the grid. This enables info from excessive confidence predictions to propagate to tougher clues. After perception propagation converges, the BCS obtains an preliminary puzzle resolution by greedily taking the very best chance reply at every place.
The BCS then refines this resolution utilizing a neighborhood search that tries to exchange low confidence characters within the grid. Native search works by utilizing a guided proposal distribution wherein characters that had decrease marginal possibilities throughout perception propagation are iteratively changed till a regionally optimum resolution is discovered. We rating these alternate characters utilizing a character-level language mannequin (ByT5, Xue et al., 2022), that handles novel solutions higher than our closed-book QA mannequin.
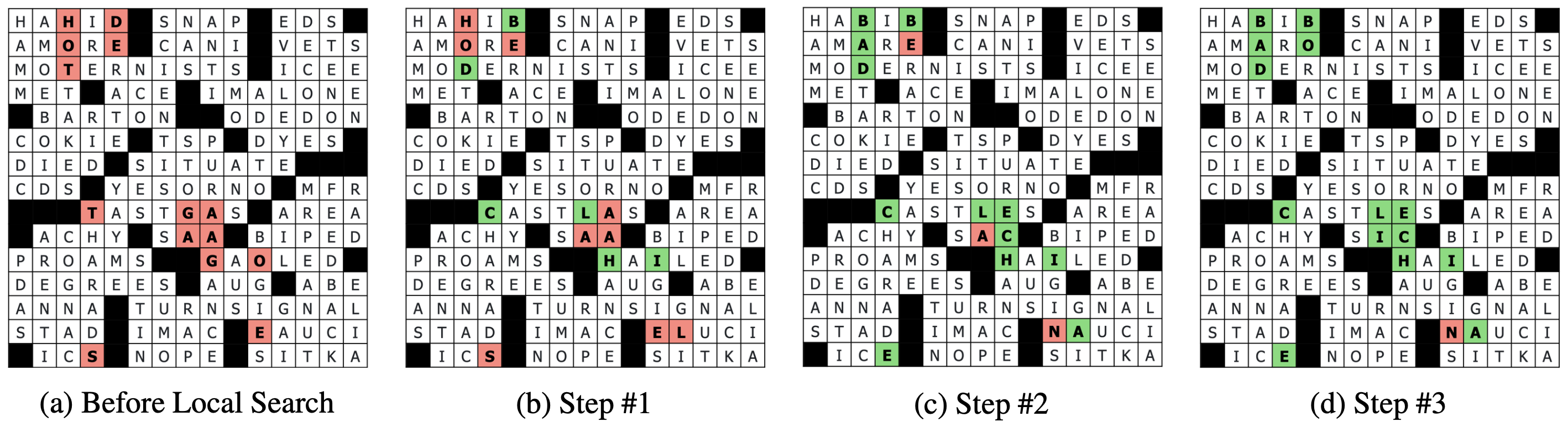
Determine 3: Instance modifications made by our native search process
We evaluated the BCS on puzzles from 5 main crossword publishers, together with The New York Instances. Our system obtains 99.7% letter accuracy on common, which jumps to 99.9% when you ignore puzzles that contain uncommon themes. It solves 81.7% of puzzles and not using a single mistake, which is a 24.8% enchancment over the earlier state-of-the-art system.
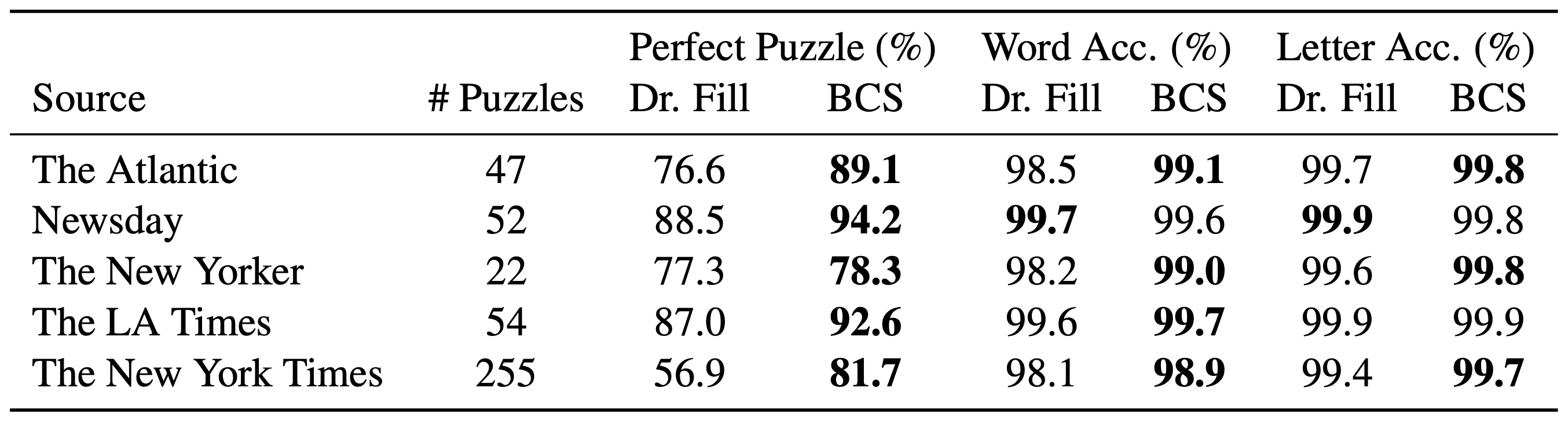
Determine 4: Outcomes in comparison with earlier state-of-the-art Dr. Fill
The American Crossword Puzzle Match (ACPT) is the most important and longest-running crossword match and is organized by Will Shortz, the New York Instances crossword editor. Two prior approaches to pc crossword fixing gained mainstream consideration and competed within the ACPT: Proverb and Dr. Fill. Proverb is a 1998 system that ranked 213th out of 252 opponents within the match. Dr. Fill’s first competitors was in ACPT 2012, and it ranked 141st out of 650 opponents. We teamed up with Dr. Fill’s creator Matt Ginsberg and mixed an early model of our QA system with Dr. Fill’s search process to win first place within the 2021 ACPT towards over a thousand opponents. Our submission solved all seven puzzles in beneath a minute, lacking simply three letters throughout two puzzles.
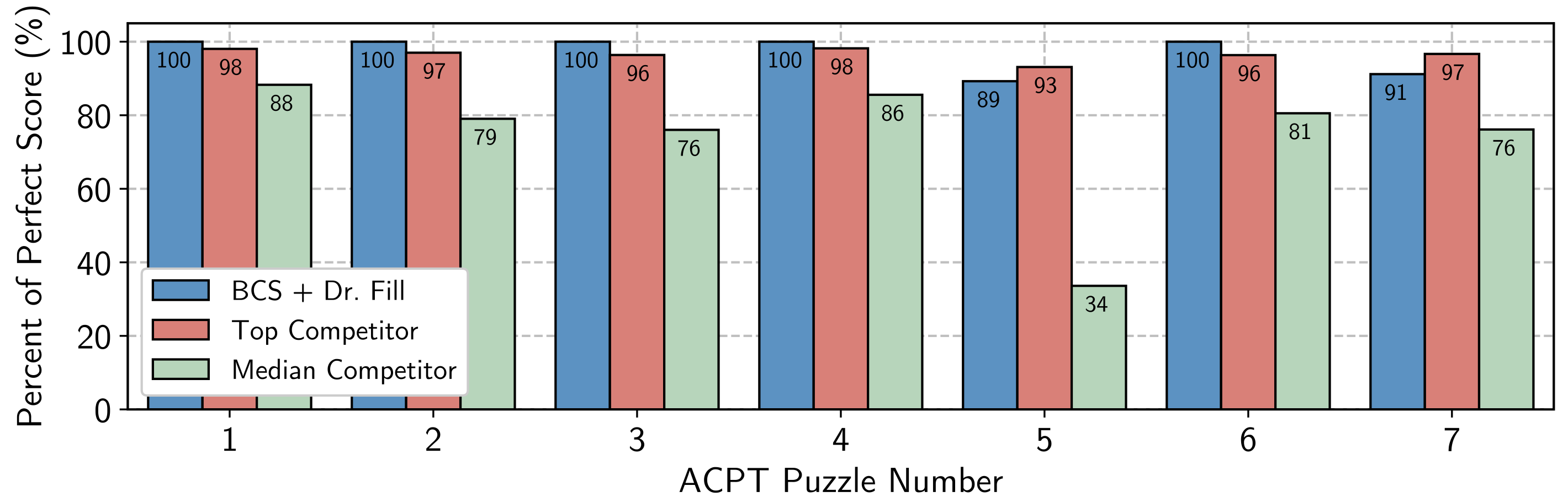
Determine 5: Outcomes from the 2021 American Crossword Puzzle Match (ACPT)
We’re actually excited concerning the challenges that stay in crosswords, together with dealing with troublesome themes and extra complicated wordplay. To encourage future work, we’re releasing a dataset of 6.4M query reply clues, a demo of the Berkeley Crossword Solver, and our code at http://berkeleycrosswordsolver.com.
Solutions to clues: MBAS, PST, EDU, INSTATER

{kind=link}