


As we speak we kick off a sequence of weblog posts about thrilling new developments from Google Analysis. Please preserve your eye on this house and search for the title “Google Analysis, 2022 & Past” for extra articles within the sequence.
I’ve all the time been excited about computer systems due to their skill to assist individuals higher perceive the world round them. During the last decade, a lot of the analysis carried out at Google has been in pursuit of the same imaginative and prescient — to assist individuals higher perceive the world round them and get issues carried out. We wish to construct extra succesful machines that companion with individuals to perform an enormous number of duties. All types of duties. Complicated, information-seeking duties. Artistic duties, like creating music, drawing new photos, or creating movies. Evaluation and synthesis duties, like crafting new paperwork or emails from a number of sentences of steerage, or partnering with individuals to collectively write software program collectively. We wish to remedy advanced mathematical or scientific issues. Remodel modalities, or translate the world’s info into any language. Diagnose advanced ailments, or perceive the bodily world. Accomplish advanced, multi-step actions in each the digital software program world and the bodily world of robotics.
We’ve demonstrated early variations of a few of these capabilities in analysis artifacts, and we’ve partnered with many groups throughout Google to ship a few of these capabilities in Google merchandise that contact the lives of billions of customers. However essentially the most thrilling points of this journey nonetheless lie forward!
With this publish, I’m kicking off a sequence through which researchers throughout Google will spotlight some thrilling progress we have made in 2022 and current our imaginative and prescient for 2023 and past. I’ll start with a dialogue of language, pc imaginative and prescient, multi-modal fashions, and generative machine studying fashions. Over the subsequent a number of weeks, we are going to focus on novel developments in analysis subjects starting from accountable AI to algorithms and pc techniques to science, well being and robotics. Let’s get began!
| * Different articles within the sequence might be linked as they’re launched. |
Language Fashions
The progress on bigger and extra highly effective language fashions has been one of the vital thrilling areas of machine studying (ML) analysis during the last decade. Vital advances alongside the way in which have included new approaches like sequence-to-sequence studying and our improvement of the Transformer mannequin, which underlies a lot of the advances on this house in the previous couple of years. Though language fashions are educated on surprisingly easy aims, like predicting the subsequent token in a sequence of textual content given the previous tokens, when giant fashions are educated on sufficiently giant and numerous corpora of textual content, the fashions can generate coherent, contextual, natural-sounding responses, and can be utilized for a variety of duties, equivalent to producing artistic content material, translating between languages, serving to with coding duties, and answering questions in a useful and informative manner. Our ongoing work on LaMDA explores how these fashions can be utilized for protected, grounded, and high-quality dialog to allow contextual multi-turn conversations.
Pure conversations are clearly an vital and emergent manner for individuals to work together with computer systems. Quite than contorting ourselves to work together in ways in which greatest accommodate the restrictions of computer systems, we are able to as an alternative have pure conversations to perform all kinds of duties. I’m excited concerning the progress we’ve made in making LaMDA helpful and factual.
In April, we described our work on PaLM, a big, 540 billion parameter language mannequin constructed utilizing our Pathways software program infrastructure and educated on a number of TPU v4 Pods. The PaLM work demonstrated that, regardless of being educated solely on the target of predicting the subsequent token, large-scale language fashions educated on giant quantities of multi-lingual information and supply code are able to bettering the state-of-the-art throughout all kinds of pure language, translation, and coding duties, regardless of by no means having been educated to particularly carry out these duties. This work offered further proof that rising the size of the mannequin and coaching information can considerably enhance capabilities.
 |
| Efficiency comparability between the PaLM 540B parameter mannequin and the prior state-of-the-art (SOTA) on 58 duties from the Huge-bench suite. (See paper for particulars.) |
We have now additionally seen vital success in utilizing giant language fashions (LLMs) educated on supply code (as an alternative of pure language textual content information) that may help our inside builders, as described in ML-Enhanced Code Completion Improves Developer Productiveness. Utilizing quite a lot of code completion solutions from a 500 million parameter language mannequin for a cohort of 10,000 Google software program builders utilizing this mannequin of their IDE, we’ve seen that 2.6% of all code comes from solutions generated by the mannequin, lowering coding iteration time for these builders by 6%. We’re engaged on enhanced variations of this and hope to roll it out to much more builders.
One of many broad key challenges in synthetic intelligence is to construct techniques that may carry out multi-step reasoning, studying to interrupt down advanced issues into smaller duties and mixing options to these to handle the bigger downside. Our current work on Chain of Thought prompting, whereby the mannequin is inspired to “present its work” in fixing new issues (much like how your fourth-grade math instructor inspired you to indicate the steps concerned in fixing an issue, fairly than simply writing down the reply you got here up with), helps language fashions observe a logical chain of thought and generate extra structured, organized and correct responses. Just like the fourth-grade math pupil that exhibits their work, not solely does this make the problem-solving method way more interpretable, additionally it is extra probably that the right reply might be discovered for advanced issues that require a number of steps of reasoning.
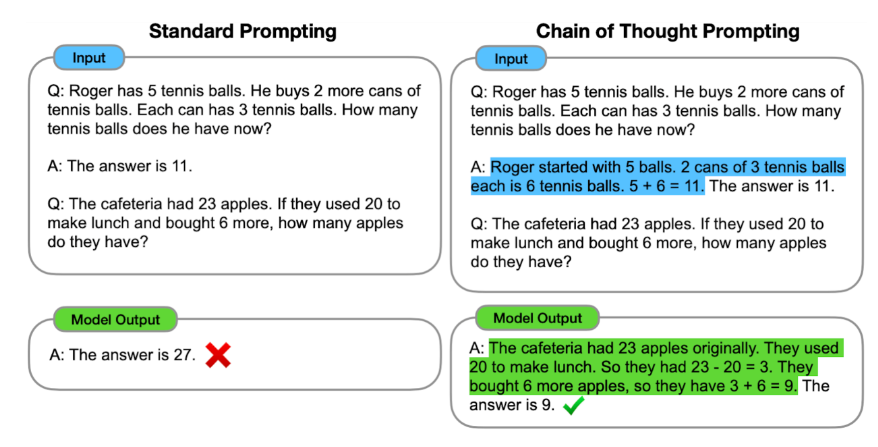 |
| Fashions that use customary prompting straight present the reply to a multi-step reasoning downside. In distinction, chain of thought prompting teaches the mannequin to deconstruct the issue into intermediate reasoning steps, higher enabling it to achieve the right remaining reply. |
One of many areas the place multi-step reasoning is most clearly useful and measurable is within the skill of fashions to unravel advanced mathematical reasoning and scientific issues. A key analysis query is whether or not ML fashions can study to unravel advanced issues utilizing multi-step reasoning. By taking the general-purpose PaLM language mannequin and fine-tuning it on a big corpus of mathematical paperwork and scientific analysis papers from arXiv, after which utilizing Chain of Thought prompting and self-consistency decoding, the Minerva effort was capable of display substantial enhancements over the state-of-the-art for mathematical reasoning and scientific issues throughout all kinds of scientific and mathematical benchmark suites.
| MATH | MMLU-STEM | OCWCourses | GSM8k | |
| Minerva | 50.3% | 75% | 30.8% | 78.5% |
| Printed state-of-the-art | 6.9% | 55% | – | 74.4% |
| Minerva 540B considerably improves state-of-the-art efficiency on STEM analysis datasets. |
Chain of Thought prompting is a method of better-expressing pure language prompts and examples to a mannequin to enhance its skill to deal with new duties. The same realized immediate tuning, through which a big language mannequin is fine-tuned on a corpus of problem-domain–particular textual content, has proven nice promise. In “Giant Language Fashions Encode Scientific Data”, we demonstrated that realized immediate tuning can adapt a general-purpose language mannequin to the medical area with comparatively few examples and that the ensuing mannequin can obtain 67.6% accuracy on US Medical License Examination questions (MedQA), surpassing the prior ML state-of-the-art by over 17%. Whereas nonetheless quick in comparison with the talents of clinicians, comprehension, recall of data and medical reasoning all enhance with mannequin scale and instruction immediate tuning, suggesting the potential utility of LLMs in medication. Continued work might help to create protected, useful language fashions for medical utility.
Giant language fashions educated on a number of languages also can assist with translation from one language to a different, even once they have by no means been taught to explicitly translate textual content. Conventional machine translation techniques normally depend on parallel (translated) textual content to study to translate from one language to a different. Nevertheless, since parallel textual content exists for a comparatively small variety of languages, many languages are sometimes not supported in machine translation techniques. In “Unlocking Zero-Useful resource Machine Translation to Assist New Languages in Google Translate” and the accompanying papers “Constructing Machine Translation Techniques for the Subsequent Thousand Languages” and “In the direction of the Subsequent 1000 Languages in Multilingual Machine Translation: Exploring the Synergy Between Supervised and Self-Supervised Studying”, we describe a set of strategies that use massively multilingual language fashions educated on monolingual (non-parallel) datasets to add 24 new languages spoken by 300 million individuals to Google Translate.
 |
| The quantity of monolingual information per language versus the quantity of parallel (translated) information per language. A small variety of languages have giant quantities of parallel information, however there’s a lengthy tail of languages with solely monolingual information. |
One other method is represented with realized gentle prompts, the place as an alternative of developing new enter tokens to signify a immediate, we add a small variety of tunable parameters per job that may be realized from a number of job examples. This method typically yields excessive efficiency on duties for which we have now realized gentle prompts, whereas permitting the massive pre-trained language mannequin to be shared throughout 1000’s of various duties. It is a particular instance of the extra normal strategy of job adaptors, which permit a big portion of the parameters to be shared throughout duties whereas nonetheless permitting task-specific adaptation and tuning.
 |
| As scale will increase, immediate tuning, which circumstances frozen fashions utilizing tunable gentle prompts, matches the efficiency of mannequin tuning, regardless of utilizing 25,000 fewer parameters. |
Apparently, the utility of language fashions can develop considerably as their sizes improve as a result of emergence of recent capabilities. “Characterizing Emergent Phenomena in Giant Language Fashions” examines the typically shocking attribute that these fashions should not capable of carry out specific advanced duties very successfully till reaching a sure scale. However then, as soon as a vital quantity of studying has occurred (which varies by job), they immediately present giant jumps within the skill to carry out a posh job precisely (as proven beneath). This raises the query of what new duties will turn out to be possible when these fashions are educated additional.
 |
| The power to carry out multi-step arithmetic (left), succeed on college-level exams (center), and establish the supposed that means of a phrase in context (proper) all emerge just for fashions of sufficiently giant scale. The fashions proven embody LaMDA, GPT-3, Gopher, Chinchilla, and PaLM. |
Moreover, language fashions of ample scale have the power to study and adapt to new info and duties, which makes them much more versatile and highly effective. As these fashions proceed to enhance and turn out to be extra subtle, they are going to probably play an more and more vital function in lots of points of our lives.
Laptop Imaginative and prescient
Laptop imaginative and prescient continues to evolve and make fast progress. One development that began with our work on Imaginative and prescient Transformers in 2020 is to make use of the Transformer structure in pc imaginative and prescient fashions fairly than convolutional neural networks. Though the localized feature-building abstraction of convolutions is a robust method for a lot of pc imaginative and prescient issues, it’s not as versatile as the final consideration mechanism in transformers, which may make the most of each native and non-local details about the picture all through the mannequin. Nevertheless, the total consideration mechanism is difficult to use to increased decision photographs, because it scales quadratically with picture dimension.
In “MaxViT: Multi-Axis Imaginative and prescient Transformer”, we discover an method that mixes each native and non-local info at every stage of a imaginative and prescient mannequin, however scales extra effectively than the total consideration mechanism current within the unique Imaginative and prescient Transformer work. This method outperforms different state-of-the-art fashions on the ImageNet-1k classification job and varied object detection duties, however with considerably decrease computational prices.
 |
| In MaxViT, a multi-axis consideration mechanism conducts blocked native and dilated international consideration sequentially adopted by a FFN, with solely a linear complexity. The pixels in the identical colours are attended collectively. |
In “Pix2Seq: A Language Modeling Framework for Object Detection”, we discover a easy and generic technique that tackles object detection from a very completely different perspective. Not like current approaches which can be task-specific, we forged object detection as a language modeling job conditioned on the noticed pixel inputs with the mannequin educated to “learn out” the areas and different attributes concerning the objects of curiosity within the picture. Pix2Seq achieves aggressive outcomes on the large-scale object detection COCO dataset in comparison with current highly-specialized and well-optimized detection algorithms, and its efficiency may be additional improved by pre-training the mannequin on a bigger object detection dataset.
 |
| The Pix2Seq framework for object detection. The neural community perceives a picture, and generates a sequence of tokens for every object, which correspond to bounding packing containers and sophistication labels. |
One other long-standing problem in pc imaginative and prescient is to higher perceive the 3-D construction of real-world objects from one or a number of 2-D photographs. We have now been making an attempt a number of approaches to make progress on this space. In “Giant Movement Body Interpolation”, we demonstrated that quick slow-motion movies may be created by interpolating between two photos that have been taken many seconds aside, even when there may need been vital motion in some components of the scene. In “View Synthesis with Transformers”, we present methods to mix two new strategies, gentle area neural rendering (LFNR) and generalizable patch-based neural rendering (GPNR), to synthesize novel views of a scene, a long-standing problem in pc imaginative and prescient. LFNR is a way that may precisely reproduce view-dependent results through the use of transformers that study to mix reference pixel colours. Whereas LFNR works effectively on single scenes, its skill to generalize to novel scenes is restricted. GPNR overcomes this through the use of a sequence of transformers with canonicalized positional encodings that may be educated on a set of scenes to synthesize views of recent scenes. Collectively, these strategies allow high-quality view synthesis of novel scenes from simply a few photographs of the scene, as proven beneath:
 |
| By combining LFNR and GPNR, fashions are capable of produce new views of a scene given only some photographs of it. These fashions are notably efficient when dealing with view-dependent results just like the refractions and translucency on the check tubes. Supply: Nonetheless photographs from the NeX/Shiny dataset. |
Going even additional, in “LOLNerf: Study from One Look”, we discover the power to study a top quality illustration from only a single 2-D picture. By coaching on many alternative examples of specific classes of objects (e.g., numerous single photographs of various cats), we are able to study sufficient concerning the anticipated 3-D construction of objects to create a 3-D mannequin from only a single picture of a novel class (e.g., only a single picture of your cat, as proven within the LOLCats clips beneath).
 |
| Prime: Instance cat photographs from AFHQ. Backside: A synthesis of novel 3-D views created by LOLNeRF. |
A normal thrust of this work is to develop strategies that assist computer systems have a greater understanding of the 3-D world — a longstanding dream of pc imaginative and prescient!
Multimodal Fashions
Most previous ML work has centered on fashions that take care of a single modality of knowledge (e.g., language fashions, picture classification fashions, or speech recognition fashions). Whereas there was loads of wonderful progress in these areas, the longer term is much more thrilling as we sit up for multi-modal fashions that may flexibly deal with many alternative modalities concurrently, each as mannequin inputs and as mannequin outputs. We have now pushed on this course in some ways over the previous yr.
 |
| Quite than counting on particular person fashions tailor-made to particular duties or domains, the subsequent technology of multi-modal fashions can deal with completely different modalities concurrently by activating solely the mannequin pathways mandatory for a given downside. |
There are two key questions when constructing a multi-modal mannequin that have to be addressed to greatest allow cross-modality options and studying:
- How a lot modality-specific processing needs to be carried out earlier than permitting the realized representations to be merged?
- What’s the only approach to combine the representations?
In our work on “Multi-modal Bottleneck Transformers” and the accompanying “Consideration Bottlenecks for Multimodal Fusion” paper, we discover these tradeoffs and discover that bringing collectively modalities after a number of layers of modality-specific processing after which mixing the options from completely different modalities by a bottleneck layer is more practical than different strategies (as illustrated by the Bottleneck Mid Fusion within the determine beneath). This method considerably improves accuracy on quite a lot of video classification duties by studying to make use of a number of modalities of knowledge to make classification choices.
 |
| Pattern consideration configurations for multi-modal transformer encoders. Crimson and blue rows of dots signify encoder layers. Typical approaches to fusion of multi-modal transformer encoder options (“full fusion”) use pairwise self consideration throughout hidden items in a layer (left). Bottleneck fusion (center) restricts consideration stream inside a layer by tight latent items referred to as consideration bottlenecks. Bottleneck mid fusion (proper) applies bottleneck fusion solely to later layers within the mannequin for optimum efficiency. |
Combining modalities can usually enhance accuracy on even single-modality duties. That is an space we have now been exploring for a few years, together with our work on DeViSE, which mixes picture representations and word-embedding representations to enhance picture classification accuracy, even on unseen object classes. A contemporary variant of this normal thought is present in Locked-image Tuning (LiT), a way that provides language understanding to an current pre-trained picture mannequin. This method contrastively trains a textual content encoder to match picture representations from a robust pre-trained picture encoder. This easy technique is information and compute environment friendly, and considerably improves zero-shot picture classification efficiency in comparison with current contrastive studying approaches.
 |
| LiT-tuning contrastively trains a textual content encoder to match a pre-trained picture encoder. The textual content encoder learns to compute representations that align to these from the picture encoder. |
One other instance of the uni-modal utility of multi-modal fashions is noticed when co-training on associated modalities, like photographs and movies. On this case, one can usually enhance accuracy on video motion classification duties in comparison with coaching on video information alone (particularly when coaching information in a single modality is restricted).
Combining language with different modalities is a pure step for bettering how customers work together with computer systems. We have now explored this course in fairly quite a lot of methods this yr. One of the crucial thrilling is in combining language and imaginative and prescient inputs, both nonetheless photographs or movies. In “PaLI: Scaling Language-Picture Studying”, we launched a unified language-image mannequin educated to carry out many duties in over 100 languages. These duties span imaginative and prescient, language, and multimodal picture and language functions, equivalent to visible query answering, picture captioning, object detection, picture classification, optical character recognition, textual content reasoning, and others. By combining a imaginative and prescient transformer (ViT) with a text-based transformer encoder, after which a transformer-based decoder to generate textual solutions, and coaching the entire system end-to-end on many alternative duties concurrently, the system achieves state-of-the-art outcomes throughout many alternative benchmarks.
For instance, PaLI achieves state-of-the-art outcomes on the CrossModal-3600 benchmark, a various check of multilingual, multi-modal capabilities with a mean CIDEr rating of 53.4 throughout 35 languages (bettering on the earlier greatest rating of 28.9). Because the determine beneath exhibits, having a single mannequin that may concurrently perceive a number of modalities and lots of languages and deal with many duties, equivalent to captioning and query answering, will result in pc techniques the place you’ll be able to have a pure dialog about other forms of sensory inputs, asking questions and getting solutions to your wants in all kinds of languages (“In Thai, are you able to say what’s above the desk on this picture?”, “What number of parakeets do you see sitting on the branches?”, “Describe this picture in Swahili”, “What Hindi textual content is on this picture?”).
 |
| The PaLI mannequin addresses a variety of duties within the language-image, language-only and image-only area utilizing the identical API (e.g., visual-question answering, picture captioning, scene-text understanding, and so on.). The mannequin is educated to help over 100 languages and tuned to carry out multilingually for a number of language-image duties. |
In the same vein, our work on FindIt allows pure language questions on visible photographs to be answered by a unified, general-purpose and multitask visible grounding mannequin that may flexibly reply various kinds of grounding and detection queries.
 |
| FindIt is a unified mannequin for referring expression comprehension (first column), text-based localization (second), and the item detection job (third). FindIt can reply precisely when examined on object varieties and courses not identified throughout coaching, e.g., “Discover the desk” (fourth). We present the MattNet outcomes for comparability. |
The world of video query answering (e.g., given a baking video, with the ability to reply a query like “What’s the second ingredient poured into the bowl?”) requires the power to understand each textual inputs (the query) and video inputs (the related video) to provide a textual reply. In “Environment friendly Video-Textual content Studying with Iterative Co-tokenization”, multi-stream video inputs, that are variations of the identical video enter (e.g., a excessive decision, low frame-rate video and a low decision, excessive frame-rate video), are effectively fused along with the textual content enter to provide a text-based reply by the decoder. As an alternative of processing the inputs straight, the video-text iterative co-tokenization mannequin learns a diminished variety of helpful tokens from the fused video-language inputs. This course of is finished iteratively, permitting the present characteristic tokenization to have an effect on the collection of tokens on the subsequent iteration, thus refining the choice.
 |
| An instance enter query for the video query answering job “What’s the second ingredient poured into the bowl?” which requires deeper understanding of each the visible and textual content inputs. The video is an instance from the 50 Salads dataset, used underneath the Artistic Commons license. |
The method of making high-quality video content material usually contains a number of levels, from video capturing to video and audio modifying. In some circumstances, dialogue is re-recorded in a studio (known as dialog alternative, post-sync or dubbing) to attain prime quality and change unique audio that may have been recorded in noisy or different suboptimal circumstances. Nevertheless, the dialog alternative course of may be troublesome and tedious as a result of the newly recorded audio must be effectively synced with the video, usually requiring a number of edits to match the precise timing of mouth actions. In “VDTTS: Visually-Pushed Textual content-To-Speech”, we discover a multi-modal mannequin for undertaking this job extra simply. Given desired textual content and the unique video frames of a speaker, the mannequin can generate speech output of the textual content that matches the video whereas additionally recovering points of prosody, equivalent to timing or emotion. The system exhibits substantial enhancements on quite a lot of metrics associated to video-sync, speech high quality, and speech pitch. Apparently, the mannequin can produce video-synchronized speech with none specific constraints or losses within the mannequin coaching to advertise this.
| Unique | VDTTS | VDTTS video-only | TTS |
| Unique shows the unique video clip. VDTTS shows the audio predicted utilizing each the video frames and the textual content as enter. VDTTS video-only shows audio predictions utilizing video frames solely. TTS shows audio predictions utilizing textual content solely. Transcript: “completely love dancing I’ve no dance expertise in any way however as that”. |
In “Look and Discuss: Pure Conversations with Google Assistant”, we present how an on-device multi-modal mannequin can use each video and audio enter to make interacting with Google Assistant way more pure. The mannequin learns to make use of quite a lot of visible and auditory cues, equivalent to gaze course, proximity, face matching, voice matching and intent classification, to extra precisely decide if a close-by individual is definitely making an attempt to speak to the Google Assistant gadget, or merely occurs to be speaking close to the gadget with out the intent of inflicting the gadget to take any motion. With simply the audio or visible options alone, this dedication could be way more troublesome.
Multi-modal fashions don’t should be restricted to only combining human-oriented modalities like pure language or imagery, and they’re more and more vital for real-world autonomous car and robotics functions. On this context, such fashions can take the uncooked output of sensors which can be in contrast to any human senses, equivalent to 3-D level cloud information from Lidar items on autonomous automobiles, and may mix this with information from different sensors, like car cameras, to higher perceive the atmosphere round them and to make higher choices. In “4D-Internet for Studying Multi-Modal Alignment for 3D and Picture Inputs in Time”, the 3-D level cloud information from Lidar is fused with the RGB information from the digital camera in real-time, with a self-attention mechanism controlling how the options are combined collectively and weighted at completely different layers. The mixture of the completely different modalities and the usage of time-oriented options offers considerably improved accuracy in 3-D object recognition over utilizing both modality by itself. Newer work on Lidar-camera fusion launched learnable alignment and higher geometric processing by inverse augmentation to additional enhance the accuracy of 3-D object recognition.
 |
| 4D-Internet successfully combines 3D LiDAR level clouds in time with RGB photographs, additionally streamed in time as video, studying the connections between completely different sensors and their characteristic representations. |
Having single fashions that perceive many alternative modalities fluidly and contextually and that may generate many alternative sorts of outputs (e.g., language, photographs or speech) in that context, is a way more helpful, normal goal framing of ML. We’re enthusiastic about the place this may take us as a result of it should allow new thrilling functions in lots of Google merchandise and likewise advance the fields of well being, science, creativity, robotics and extra!
Generative Fashions
The standard and capabilities of generative fashions for imagery, video, and audio has proven actually gorgeous and extraordinary advances in 2022. There are all kinds of approaches for generative fashions, which should study to mannequin advanced information units (e.g., pure photographs). Generative adversarial networks, developed in 2014, arrange two fashions working towards one another. One is a generator, which tries to generate a practical trying picture (maybe conditioned on an enter to the mannequin, just like the class of picture to generate), and the opposite is a discriminator, which is given the generated picture and an actual picture and tries to find out which of the 2 is generated and which is actual, therefore the adversarial side. Every mannequin is making an attempt to get higher and higher at profitable the competitors towards the opposite, leading to each fashions getting higher and higher at their job, and ultimately, the generative mannequin can be utilized in isolation to generate photographs.
Diffusion fashions, launched in “Deep Unsupervised Studying utilizing Nonequilibrium Thermodynamics” in 2015, systematically and slowly destroy construction in a knowledge distribution by an iterative ahead diffusion course of. They then study a reverse diffusion course of that may restore the construction within the information that has been misplaced, even given excessive ranges of noise. The ahead course of can be utilized to generate noisy beginning factors for the reverse diffusion course of conditioned on varied helpful, controllable inputs to the mannequin, in order that the reverse diffusion (generative) course of turns into controllable. Which means it’s potential to ask the mannequin to “generate a picture of a grapefruit”, a way more helpful functionality than simply “generate a picture” if what you’re after is certainly a sampling of photographs of grapefruits.
 |
Varied types of autoregressive fashions have additionally been utilized to the duty of picture technology. In 2016, “Pixel Recurrent Neural Networks” launched PixelRNN, a recurrent structure, and PixelCNN, the same however extra environment friendly convolutional structure that was additionally investigated in “Conditional Picture Technology with PixelCNN Decoders”. These two architectures helped lay the muse for pixel-level technology utilizing deep neural networks. They have been adopted in 2017 by VQ-VAE, proposed in “Neural Discrete Illustration Studying”, a vector-quantized variational autoencoder. Combining this with PixelCNN yielded high-quality photographs. Then, in 2018 Picture Transformer used the autoregressive Transformer mannequin to generate photographs.
Till comparatively lately, all of those picture technology strategies have been able to producing photographs which can be comparatively low high quality in comparison with actual world photographs. Nevertheless, a number of current advances have opened the door for a lot better picture technology efficiency. One is Contrastic Language-Picture Pre-training (CLIP), a pre-training method for collectively coaching a picture encoder and a textual content decoder to foretell [image, text] pairs. This pre-training job of predicting which caption goes with which picture proved to be an environment friendly and scalable approach to study picture illustration and yielded good zero-shot efficiency on datasets like ImageNet.
Along with CLIP, the toolkit of generative picture fashions has lately grown. Giant language mannequin encoders have been proven to successfully situation picture technology on lengthy pure language descriptions fairly than only a restricted variety of pre-set classes of photographs. Considerably bigger coaching datasets of photographs and accompanying captions (which may be reversed to function textual content→picture exemplars) have improved general efficiency. All of those components collectively have given rise to a variety of fashions capable of generate high-resolution photographs with robust adherence even to very detailed and improbable prompts.
We focus right here on two current advances from groups in Google Analysis, Imagen and Parti.
Imagen is predicated on the Diffusion work mentioned above. Of their 2022 paper “Photorealistic Textual content-to-Picture Diffusion Fashions with Deep Language Understanding”, the authors present {that a} generic giant language mannequin (e.g., T5), pre-trained on text-only corpora, is surprisingly efficient at encoding textual content for picture synthesis. Considerably surprisingly, rising the dimensions of the language mannequin in Imagen boosts each pattern constancy and image-text alignment way more than rising the dimensions of the picture diffusion mannequin. The work affords a number of advances to Diffusion-based picture technology, together with a brand new memory-efficient structure referred to as Environment friendly U-Internet and Classifier-Free Diffusion Steerage, which improves efficiency by often “dropping out” conditioning info throughout coaching. Classifier-free steerage forces the mannequin to study to generate from the enter information alone, thus serving to it keep away from issues that come up from over-relying on the conditioning info. “Steerage: a cheat code for diffusion fashions” offers a pleasant clarification.
Parti makes use of an autoregressive Transformer structure to generate picture pixels primarily based on a textual content enter. In “Vector-quantized Picture Modeling with Improved VQGAN”, launched in 2021, an encoder primarily based on Imaginative and prescient Transformer is proven to considerably enhance the output of a vector-quantized GAN mannequin, VQGAN. That is prolonged in “Scaling Autoregressive Fashions for Content material-Wealthy Textual content-to-Picture Technology”, launched in 2022, the place a lot better outcomes are obtained by scaling the Transformer encoder-decoder to 20B parameters. Parti additionally makes use of classifier-free steerage, described above, to sharpen the generated photographs. Maybe not shocking on condition that it’s a language mannequin, Parti is especially good at choosing up on refined cues within the immediate.
 |
 |
| Left: Imagen generated picture from the advanced immediate, “A wall in a royal citadel. There are two work on the wall. The one on the left is an in depth oil portray of the royal raccoon king. The one on the best an in depth oil portray of the royal raccoon queen.” Proper: Parti generated picture from the immediate, “A teddy bear carrying a bike helmet and cape automobile browsing on a taxi cab in New York Metropolis. dslr photograph.” |
Person Management
The advances described above make it potential to generate lifelike nonetheless photographs primarily based on textual content descriptions. Nevertheless, typically textual content alone shouldn’t be ample to allow you to create what you need — e.g., take into account “A canine being chased by a unicorn on the seaside” vs. “My canine being chased by a unicorn on the seaside”. So, we have now carried out subsequent analysis in offering new methods for customers to manage the technology course of. In “DreamBooth: Nice Tuning Textual content-to-Picture Diffusion Fashions for Topic-Pushed Technology”, customers are capable of fine-tune a educated mannequin like Imagen or Parti to generate new photographs primarily based on a mix of textual content and user-furnished photographs (as illustrated beneath and with extra particulars and examples on the DreamBooth website). This permits customers to position photographs of themselves (or e.g., their pets) into generated photographs, thus permitting for way more person management. That is exemplified in “Immediate-to-Immediate Picture Modifying with Cross Consideration Management”, the place customers are capable of edit photographs utilizing textual content prompts like “make the automobile right into a bicycle” and in Imagen Editor, which permits customers to iteratively edit photographs by filling in masked areas utilizing textual content prompts.
 |
| DreamBooth allows management over the picture technology course of utilizing each enter photographs and textual prompts. |
Generative Video
One of many subsequent analysis challenges we’re tackling is to create generative fashions for video that may produce excessive decision, prime quality, temporally constant movies with a excessive degree of controllability. It is a very difficult space as a result of in contrast to photographs, the place the problem was to match the specified properties of the picture with the generated pixels, with video there’s the added dimension of time. Not solely should all of the pixels in every body match what needs to be taking place within the video in the meanwhile, they need to even be according to different frames, each at a really fine-grained degree (a number of frames away, in order that movement appears easy and pure), but additionally at a coarse-grained degree (if we requested for a two minute video of a airplane taking off, circling, and touchdown, we should make 1000’s of frames which can be according to this high-level video goal). This yr we’ve made various thrilling progress on this lofty purpose by two efforts, Imagen Video and Phenaki, every utilizing considerably completely different approaches.
Imagen Video generates excessive decision movies with Cascaded Diffusion Fashions (described in additional element in “Imagen Video: Excessive Definition Video Technology from Diffusion Fashions”). Step one is to take an enter textual content immediate (“A cheerful elephant carrying a birthday hat strolling underneath the ocean”) and encode it into textual embeddings with a T5 textual content encoder. A base video diffusion mannequin then generates a really tough sketch 16 body video at 40×24 decision and three frames per second. That is then adopted by a number of temporal super-resolution (TSR) and spatial super-resolution (SSR) fashions to upsample and generate a remaining 128 body video at 1280×768 decision and 24 frames per second — leading to 5.3s of excessive definition video. The ensuing movies are excessive decision, and are spatially and temporally constant, however nonetheless fairly quick at ~5 seconds lengthy.
“Phenaki: Variable Size Video Technology From Open Area Textual Description”, launched in 2022, introduces a brand new Transformer-based mannequin for studying video representations, which compresses the video to a small illustration of discrete tokens. Textual content conditioning is achieved by coaching a bi-directional Transformer mannequin to generate video tokens primarily based on a textual content description. These generated video tokens are then decoded to create the precise video. As a result of the mannequin is causal in time, it may be used to generate variable-length movies. This opens the door to multi-prompt storytelling as illustrated within the video beneath.
 |
| Phenaki video generated from the advanced immediate, “A photorealistic teddy bear is swimming within the ocean at San Francisco. The teddy bear goes underneath water. The teddy bear retains swimming underneath the water with colourful fishes. A panda bear is swimming underneath water.” |
It’s potential to mix the Imagen Video and Phenaki fashions to profit from each the high-resolution particular person frames from Imagen and the long-form movies from Phenaki. Essentially the most simple manner to do that is to make use of Imagen Video to deal with super-resolution of quick video segments, whereas counting on the auto-regressive Phenaki mannequin to generate the long-timescale video info.
Generative Audio
Along with visual-oriented generative fashions, we have now made vital progress on generative fashions for audio. In “AudioLM, a Language Modeling Method to Audio Technology” (and the accompanying paper), we describe methods to leverage advances in language modeling to generate audio with out being educated on annotated information. Utilizing a language-modeling method for uncooked audio information as an alternative of textual information introduces quite a lot of challenges that should be addressed.
First, the information price for audio is considerably increased, resulting in for much longer sequences — whereas a written sentence may be represented by a number of dozen characters, its audio waveform usually comprises a whole bunch of 1000’s of values. Second, there’s a one-to-many relationship between textual content and audio. Which means the identical sentence may be uttered in a different way by completely different audio system with completely different talking types, emotional content material and different audio background circumstances.
To take care of this, we separate the audio technology course of into two steps. The primary entails a sequence of coarse, semantic tokens that seize each native dependencies (e.g., phonetics in speech, native melody in piano music) and international long-term construction (e.g., language syntax and semantic content material in speech, concord and rhythm in piano music), whereas closely downsampling the audio sign to permit for modeling lengthy sequences. One a part of the mannequin generates a sequence of coarse semantic tokens conditioned on the previous sequence of such tokens. We then depend on a portion of the mannequin that may use a sequence of coarse tokens to generate fine-grained audio tokens which can be near the ultimate generated waveform.
When educated on speech, and with none transcript or annotation, AudioLM generates syntactically and semantically believable speech continuations whereas additionally sustaining speaker identification and prosody for unseen audio system. AudioLM will also be used to generate coherent piano music continuations, regardless of being educated with none symbolic illustration of music. You’ll be able to hearken to extra samples right here.
Concluding Ideas on Generative Fashions
2022 has introduced thrilling advances in media technology. Computer systems can now work together with pure language and higher perceive your artistic course of and what you would possibly wish to create. This unlocks thrilling new methods for computer systems to assist customers create photographs, video, and audio — in ways in which surpass the boundaries of conventional instruments!
This has impressed extra analysis curiosity in how customers can management the generative course of. Advances in text-to-image and text-to-video have unlocked language as a robust approach to management technology, whereas work like Dream Sales space has made it potential for customers to kickstart the generative course of with their very own photographs. 2023 and past will certainly be marked by advances within the high quality and pace of media technology itself. Alongside these advances, we may also see new person experiences, permitting for extra artistic expression.
It’s also value noting that though these artistic instruments have large prospects for serving to people with artistic duties, they introduce quite a lot of considerations — they may doubtlessly generate dangerous content material of assorted sorts, or generate pretend imagery or audio content material that’s troublesome to tell apart from actuality. These are all points we take into account rigorously when deciding when and methods to deploy these fashions responsibly.
Accountable AI
AI have to be pursued responsibly. Highly effective language fashions might help individuals with many duties, however with out care they’ll additionally generate misinformation or poisonous textual content. Generative fashions can be utilized for wonderful artistic functions, enabling individuals to manifest their creativeness in new and wonderful methods, however they will also be used to create dangerous imagery or realistic-looking photographs of occasions that by no means occurred.
These are advanced subjects to grapple with. Leaders in ML and AI should lead not solely in state-of-the-art applied sciences, but additionally in state-of-the-art approaches to duty and implementation. In 2018, we have been one of many first corporations to articulate AI Ideas that put useful use, customers, security, and avoidance of harms above all, and we have now pioneered many greatest practices, like the usage of mannequin and information playing cards. Greater than phrases on paper, we apply our AI Ideas in observe. You’ll be able to see our newest AI Ideas progress replace right here, together with case research on text-to-image technology fashions, strategies for avoiding gender bias in translations, and extra inclusive and equitable analysis pores and skin tones. Comparable updates have been revealed in 2021, 2020, and 2019. As we pursue AI each boldly and responsibly, we proceed to study from customers, different researchers, affected communities, and our experiences.
Our accountable AI method contains the next:
- Give attention to AI that’s helpful and advantages customers and society.
- Deliberately apply our AI Ideas (that are grounded in useful makes use of and avoidance of hurt), processes, and governance to information our work in AI, from analysis priorities to productization and makes use of.
- Apply the scientific technique to AI R&D with analysis rigor, peer overview, readiness critiques, and accountable approaches to entry and externalization.
- Collaborate with multidisciplinary specialists, together with social scientists, ethicists, and different groups with socio-technical experience.
- Hear, study and enhance primarily based on suggestions from builders, customers, governments, and representatives of affected communities.
- Conduct common critiques of our AI analysis and utility improvement, together with use circumstances. Present transparency on what we’ve realized.
- Keep on high of present and evolving areas of concern and danger (e.g., security, bias and toxicity) and tackle, analysis and innovate to answer challenges and dangers as they emerge.
- Lead on and assist form accountable governance, accountability, and regulation that encourages innovation and maximizes the advantages of AI whereas mitigating dangers.
- Assist customers and society perceive what AI is (and isn’t) and methods to profit from its potential.
In a subsequent weblog publish, leaders from our Accountable AI workforce will focus on work from 2022 in additional element and their imaginative and prescient for the sphere within the subsequent few years.
Concluding Ideas
We’re excited by the transformational advances mentioned above, lots of which we’re making use of to make Google merchandise extra useful to billions of customers — together with Search, Assistant, Advertisements, Cloud, Gmail, Maps, YouTube, Workspace, Android, Pixel, Nest, and Translate. These newest advances are making their manner into actual person experiences that may dramatically change how we work together with computer systems.
Within the area of language fashions, due to our invention of the Transformer mannequin and advances like sequence-to-sequence studying, individuals can have a pure dialog (with a pc!) — and get surprisingly good responses (from a pc!). Because of new approaches in pc imaginative and prescient, computer systems might help individuals create and work together in 3D, fairly than 2D. And due to new advances in generative fashions, computer systems might help individuals create photographs, movies, and audio — in methods they weren’t capable of earlier than with conventional instruments (e.g., a keyboard and mouse). Mixed with advances like pure language understanding, computer systems can perceive what you’re making an attempt to create — and make it easier to notice surprisingly good outcomes!
One other transformation altering how individuals work together with computer systems is the rising capabilities of multi-modal fashions. We’re working in direction of with the ability to create a single mannequin that may perceive many alternative modalities fluidly — understanding what every modality represents in context — after which truly generate completely different modes in that context. We’re excited by progress in direction of this purpose! For instance, we launched a unified language mannequin that may carry out imaginative and prescient, language, query answering and object detection duties in over 100 languages with state-of-the-art outcomes throughout varied benchmarks. In future functions, individuals can interact extra senses to get computer systems to do what they need — e.g., “Describe this picture in Swahili.” We’ve proven that on-device multi-modal fashions could make interacting with Google Assistant extra pure. And we’ve demonstrated fashions that may, in varied mixtures, generate photographs, video, and audio managed by pure language, photographs, and audio. Extra thrilling issues to return on this house!
As we innovate, we have now a duty to customers and society to thoughtfully pursue and develop these new applied sciences in accordance with our AI Ideas. It’s not sufficient for us to develop state-of-the-art applied sciences, however we should additionally be certain that they’re protected earlier than broadly releasing them into the world, and we take this duty very significantly.
New advances in AI current an thrilling horizon of recent methods computer systems might help individuals get issues carried out. For Google, many will improve or remodel our longstanding mission to arrange the world’s info and make it universally accessible and helpful. Over 20 years later, we consider this mission is as daring as ever. As we speak, what excites us is how we’re making use of many of those advances in AI to boost and remodel person experiences — serving to extra individuals higher perceive the world round them and get extra issues carried out. My very own longstanding imaginative and prescient of computer systems!
Acknowledgements
Thanks to all the Analysis Neighborhood at Google for his or her contributions to this work! As well as, I’d particularly wish to thank the various Googlers who offered useful suggestions within the writing of this publish and who might be contributing to the opposite posts on this sequence, together with Martin Abadi, Ryan Babbush, Vivek Bandyopadhyay, Kendra Byrne, Esmeralda Cardenas, Alison Carroll, Zhifeng Chen, Charina Chou, Lucy Colwell, Greg Corrado, Corinna Cortes, Marian Croak, Tulsee Doshi, Toju Duke, Doug Eck, Sepi Hejazi Moghadam, Pritish Kamath, Julian Kelly, Sanjiv Kumar, Ronit Levavi Morad, Pasin Manurangsi, Yossi Matias, Kathy Meier-Hellstern, Vahab Mirrokni, Hartmut Neven, Adam Paszke, David Patterson, Mangpo Phothilimthana, John Platt, Ben Poole, Tom Small, Vadim Smelyanskiy, Vincent Vanhoucke, and Leslie Yeh.

{kind=link}