

On this put up, we reveal the way to construct a easy web-based search software utilizing the just lately introduced Amazon OpenSearch Serverless, a serverless possibility for Amazon OpenSearch Service that makes it simple to run petabyte-scale search and analytics workloads with out having to consider clusters. The advantage of utilizing OpenSearch Serverless as a backend in your search software is that it routinely provisions and scales the underlying assets based mostly on the search visitors calls for, so that you don’t have to fret about infrastructure administration. You possibly can merely give attention to constructing your search software and analyzing the outcomes. OpenSearch Serverless is powered by the open-source OpenSearch mission, which consists of a search engine, and OpenSearch Dashboards, a visualization device to research your search outcomes.
Resolution overview
There are numerous methods to construct a search software. In our instance, we create a easy Java script entrance finish and name Amazon API Gateway, which triggers an AWS Lambda perform upon receiving person queries. As proven within the following diagram, API Gateway acts as a dealer between the entrance finish and the OpenSearch Serverless assortment. When the person queries the front-end webpage, API Gateway passes requests to the Python Lambda perform, which runs the queries on the OpenSearch Serverless assortment and returns the search outcomes.

To get began with the search software, you will need to first add the related dataset, a film catalog on this case, to the OpenSearch assortment and index them to make them searchable.
Create a set in OpenSearch Serverless
A assortment in OpenSearch Serverless is a logical grouping of a number of indexes that characterize a workload. You possibly can create a set utilizing the AWS Administration Console or AWS Software program Improvement Package (AWS SDK). Observe the steps in Preview: Amazon OpenSearch Serverless – Run Search and Analytics Workloads with out Managing Clusters to create and configure a set in OpenSearch Serverless.

Create an index and ingest knowledge
After your assortment is created and energetic, you may add the film knowledge to an index on this assortment. Indexes maintain paperwork, and every doc on this instance represents a film document. Paperwork are similar to rows within the database desk. Every doc (the film document) consists of 10 fields which can be sometimes looked for in a film catalog, just like the director, actor, launch date, style, title, or plot of the film. The next is a pattern film JSON doc:
For the search catalog, you may add the sample-movies.bulk dataset sourced from the Web Motion pictures Database (IMDb). OpenSearch Serverless gives the identical ingestion pipeline and purchasers to ingest the info as OpenSearch Service, comparable to Fluentd, Logstash, and Postman. Alternatively, you should utilize the OpenSearch Dashboards Dev Instruments to ingest and search the info with out configuring any further pipelines. To take action, log in to OpenSearch Dashboards utilizing your SAML credentials and select Dev instruments.
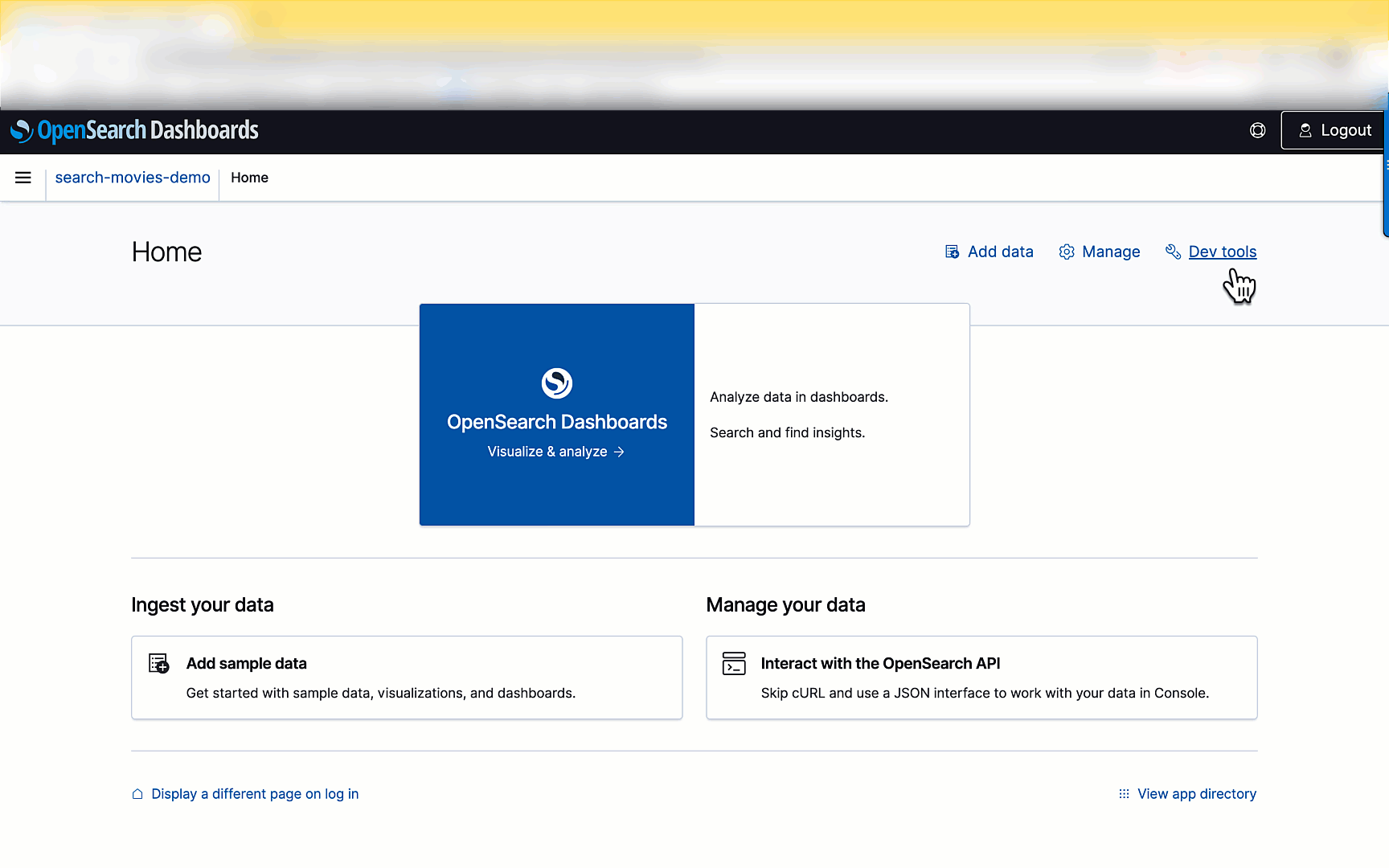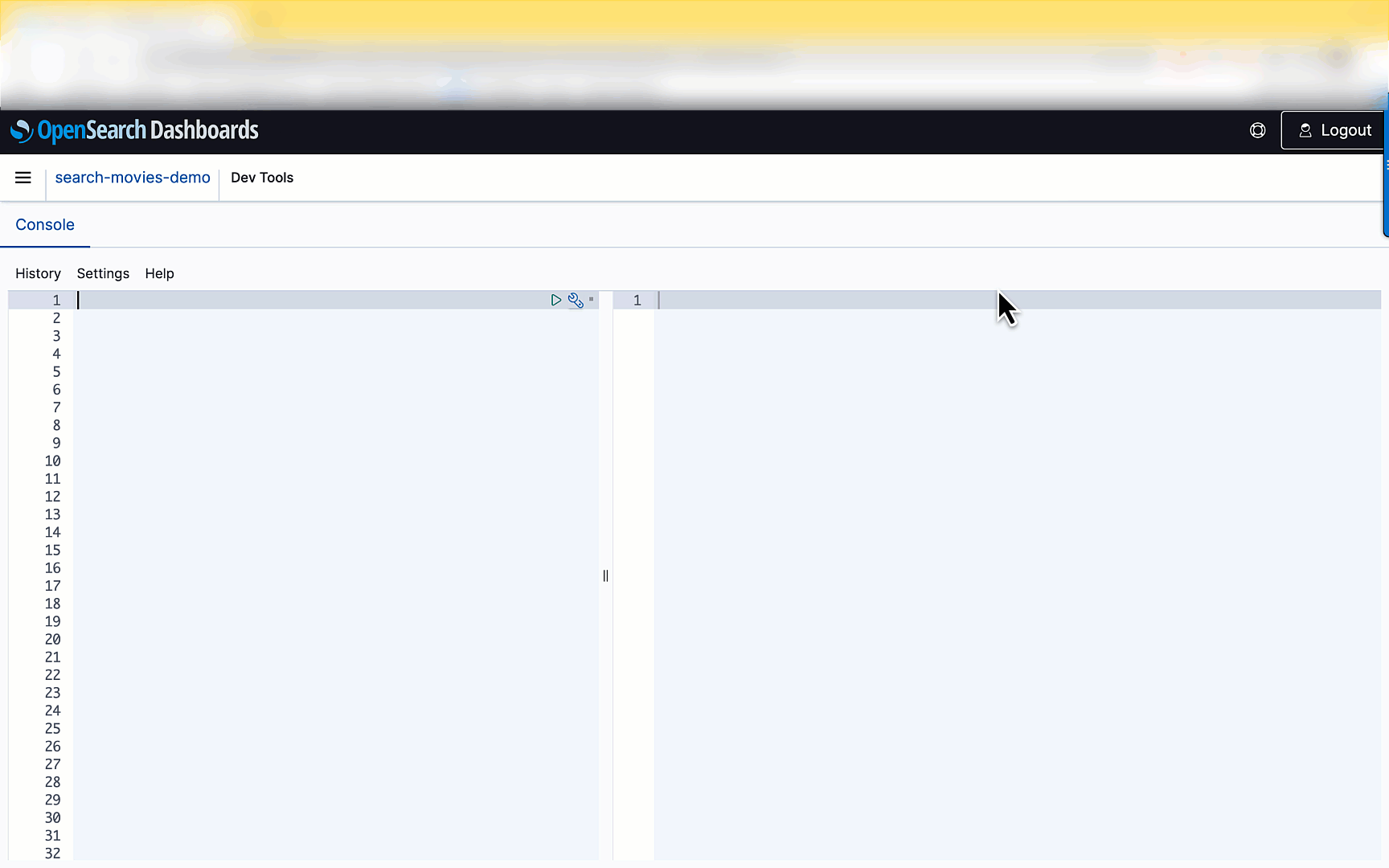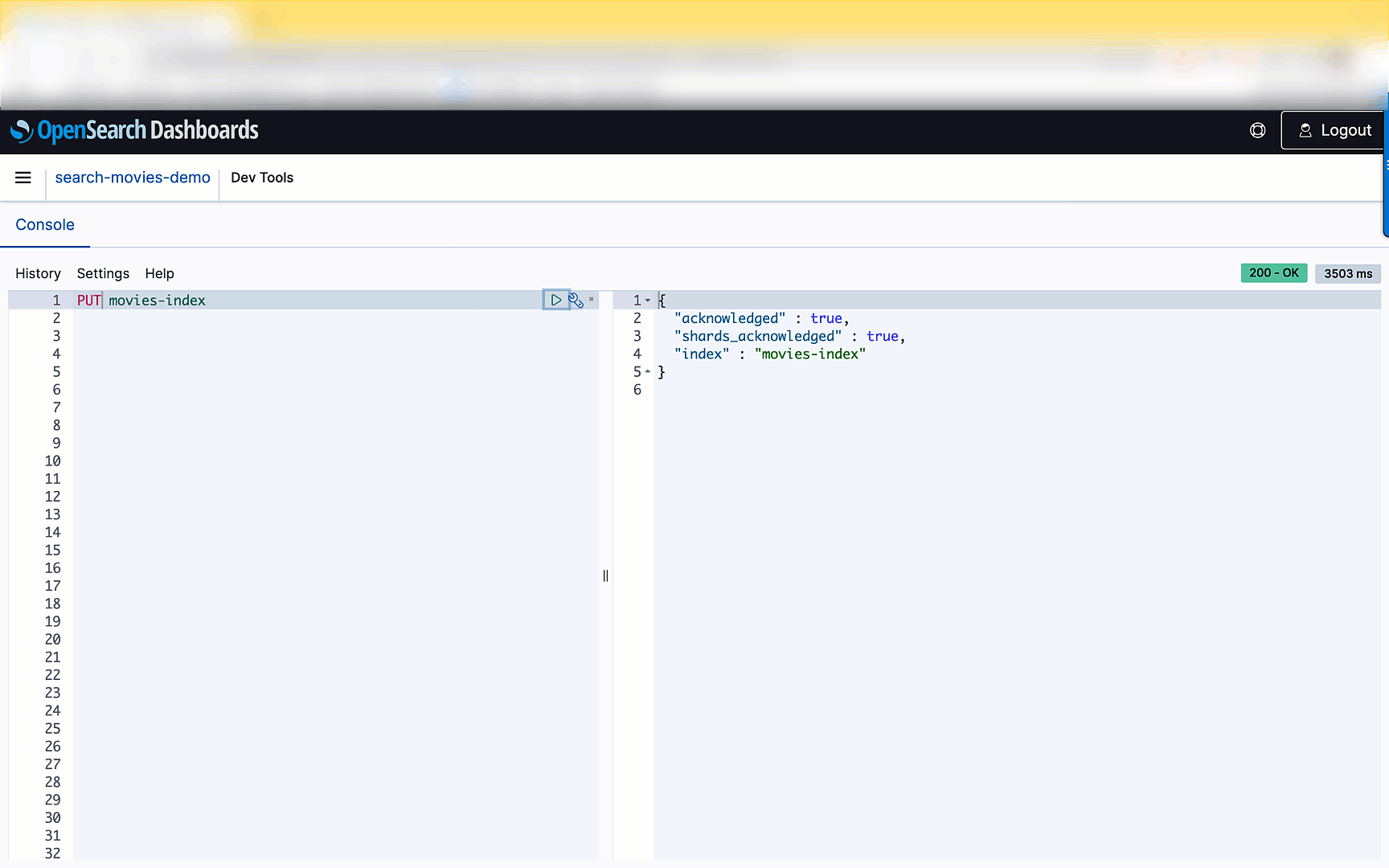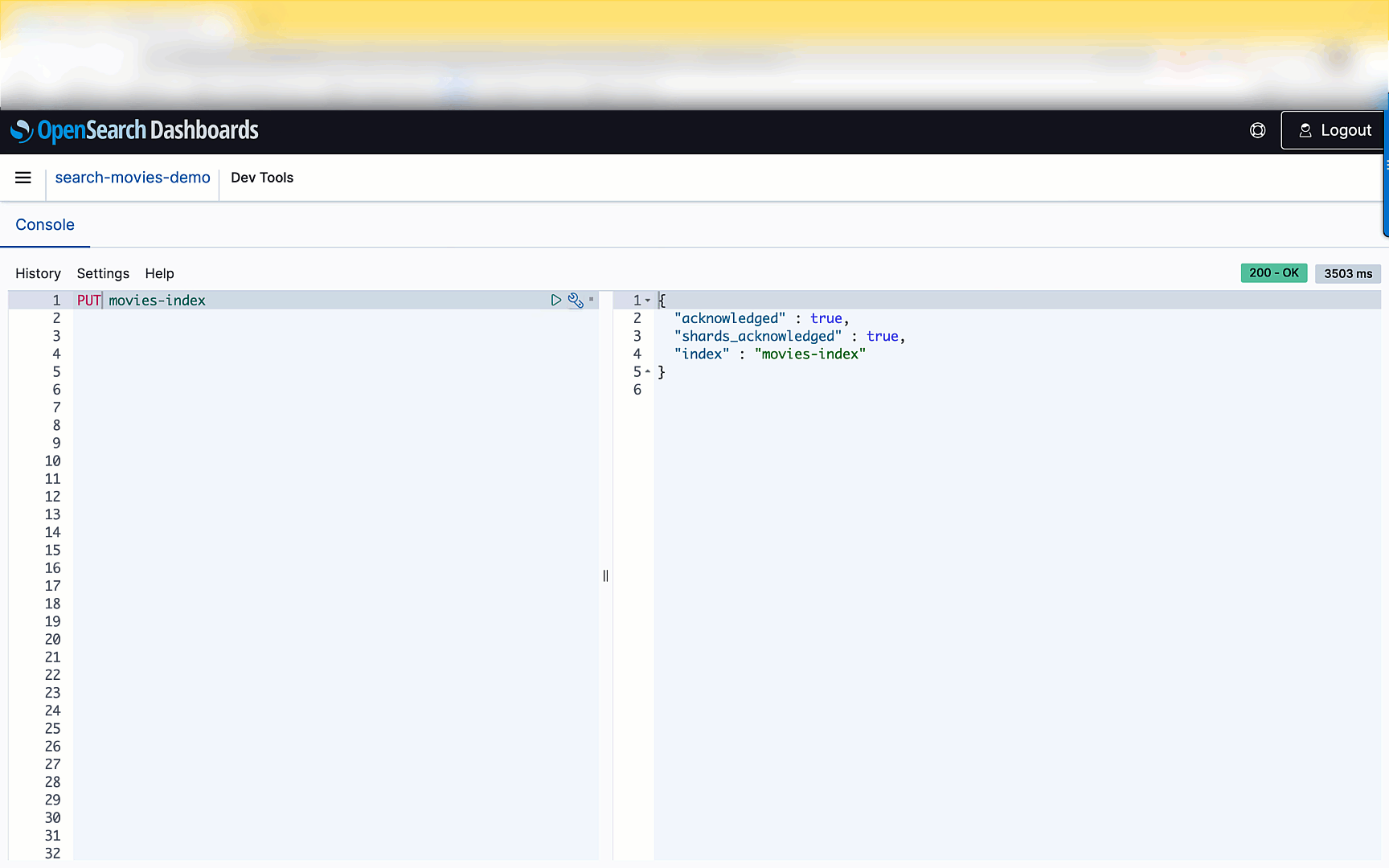
To create a brand new index, use the PUT command adopted by the index identify:
A affirmation message is displayed upon profitable creation of your index.
After the index is created, you may ingest paperwork into the index. OpenSearch supplies the choice to ingest a number of paperwork in a single request utilizing the _bulk request. Enter POST /_bulk within the left pane as proven within the following screenshot, then copy and paste the contents of the sample-movies.bulk file you downloaded earlier.

You have got efficiently created the films index and uploaded 1,500 data into the catalog! Now let’s combine the film catalog together with your search software.
Combine the Lambda perform with an OpenSearch Serverless endpoint
On this step, you create a Lambda perform that queries the film catalog in OpenSearch Serverless and returns the consequence. For extra info, see our tutorial on making a Lambda perform for connecting to and querying an OpenSearch Service area. You possibly can reuse the identical code by changing the parameters to align to OpenSearch Serverless’s necessities. Substitute <my-region> together with your corresponding area (for instance, us-west-2), use aoss as an alternative of es for service, change <hostname> with the OpenSearch assortment endpoint, and <index-name> together with your index (on this case, movies-index).
The next is a snippet of the Lambda code. You could find the entire code within the tutorial.
This Lambda perform returns a listing of flicks based mostly on a search string (comparable to film title, director, or actor) supplied by the person.
Subsequent, you must configure the permissions in OpenSearch Serverless’s knowledge entry coverage to let the Lambda perform entry the gathering.
- On the Lambda console, navigate to your perform.
- On the Configuration tab, within the Permissions part, beneath Execution function, copy the worth for Function identify.

- Add this function identify as one of many principals of your
movie-searchassortment’s knowledge entry coverage.
Principals could be AWS Identification and Entry Administration (IAM) customers, function ARNs, or SAML identities. These principals should be inside the present AWS account.

After you add the function identify as a principal, you may see the function ARN up to date in your rule, as present within the following screenshot.
Now you may grant assortment and index permissions to this principal.
For extra particulars about knowledge entry insurance policies, confer with Information entry management for Amazon OpenSearch Serverless. Skipping this step or not working it accurately will lead to permission errors, and your Lambda code gained’t be capable to question the film catalog.

Configure API Gateway
API Gateway acts as a entrance door for purposes to entry the code working on Lambda. To create, configure, and deploy the API for the GET methodology, confer with the steps within the tutorial. For API Gateway to go the requests to the Lambda perform, configure it as a set off to invoke the Lambda perform.
The subsequent step is to combine it with the entrance finish.
Take a look at the net software
To construct the front-end UI, you may obtain the next pattern JavaScript net service. Open the scripts/search.js file and replace the apigatewayendpoint variable to level to your API Gateway endpoint:
You possibly can entry the front-end software by opening index.html in your browser. When the person runs a question on the front-end software, it calls API Gateway and Lambda to serve up the content material hosted within the OpenSearch Serverless assortment.

Whenever you search the film catalog, the Lambda perform runs the next question:
The question returns paperwork based mostly on a supplied question string. Let’s have a look at the parameters used within the question:
- dimension – The
dimensionparameter is the utmost variety of paperwork to return. On this case, a most of 25 outcomes is returned. - multi_match – You employ a match question when matching bigger items of textual content, particularly once you’re utilizing OpenSearch’s relevance to type your outcomes. With a
multi_matchquestion, you may question throughout a number of fields specified within the question. - fields – The checklist of fields you’re querying.
In a seek for “Harry Potter,” the doc with the matching time period each within the title and plot fields seems increased than different paperwork with the matching time period solely within the title discipline.

Congratulations! You have got configured and deployed a search software fronted by API Gateway, working Lambda features for the queries served by OpenSearch Serverless.
Clear up
To keep away from undesirable prices, delete the OpenSearch Service assortment, Lambda perform, and API Gateway that you simply created.
Conclusion
On this put up, you realized the way to construct a easy search software utilizing OpenSearch Serverless. With OpenSearch Serverless, you don’t have to fret about managing the underlying infrastructure. OpenSearch Serverless helps the identical ingestion and question APIs because the OpenSearch Venture. You possibly can rapidly get began by ingesting the info into your OpenSearch Service assortment, after which carry out searches on the info utilizing your net interface.
In subsequent posts, we dive deeper into many different search queries and options that you should utilize to make your search software much more efficient.
We’d love to listen to how you’re constructing your search purposes at present. If you happen to’re simply getting began with OpenSearch Serverless, we advocate getting hands-on with the Getting began with Amazon OpenSearch Serverless workshop.
Concerning the authors
 Aish Gunasekar is a Specialist Options architect with a give attention to Amazon OpenSearch Service. Her ardour at AWS is to assist clients design extremely scalable architectures and assist them of their cloud adoption journey. Exterior of labor, she enjoys mountain climbing and baking.
Aish Gunasekar is a Specialist Options architect with a give attention to Amazon OpenSearch Service. Her ardour at AWS is to assist clients design extremely scalable architectures and assist them of their cloud adoption journey. Exterior of labor, she enjoys mountain climbing and baking.
 Pavani Baddepudi is a senior product supervisor working in search companies at AWS. Her pursuits embody distributed methods, networking, and safety.
Pavani Baddepudi is a senior product supervisor working in search companies at AWS. Her pursuits embody distributed methods, networking, and safety.

{kind=link}