


(Dilok Klaisataporn/Shutterstock)
ETL software program maker Fivetran this week launched outcomes of a benchmark check it ran evaluating the associated fee and efficiency of 5 cloud knowledge warehouses, together with BigQuery, Databricks, Redshift, Snowflake, and Synapse. The massive takeaway is that the entire cloud warehouses carry out properly, however some are simpler to make use of and tune than others.
As an ETL vendor, Fivetran usually will get requested by prospects which cloud knowledge warehouse they need to use, writes CEO George Fraser in a weblog submit Monday. To seek out out which warehouse was greatest, the corporate determined to do an apples-to-apples comparability (or no less than as shut to 1 as potential).
To conduct the check, Fivetran partnered with Brooklyn Knowledge Co., an information and analytics consultancy. They used the TPC-DS knowledge set, which is a call assist benchmark rolled out by the Transaction Processing Efficiency Council in 2015 that depicts knowledge from an imaginary retailer. The database included 1TB of knowledge, which is the smallest scale issue licensed by TPC-DS (it’s additionally obtainable in 3TB, 10TB, 30TB, and 100TB scale elements).
Fivetran and Brooklyn Knowledge Co. configured every knowledge warehouse three other ways to account for variations in price and efficiency. The lone exception was Google Cloud’s BigQuery, which may’t be configured as a result of it’s solely obtainable as an on-demand service. Whereas it ran AWS’s Amazon Redshift in three configurations, the companions solely reported the outcomes of 1 as a result of they weren’t in a position to reproduce outcomes throughout totally different configurations, they wrote.
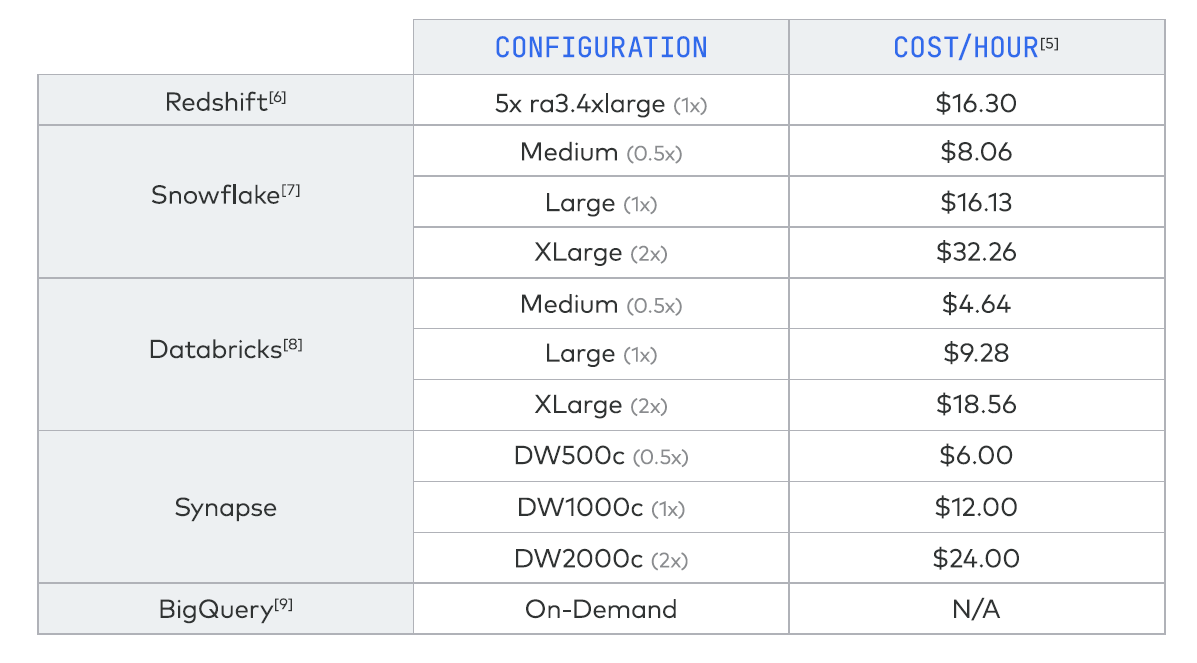
The configurations of the 5 warehouses (Supply: Fivetran Cloud Knowledge Warehouse Benchmark)
The companions then ran 99 TPC-DS queries towards the retail database, and calculated how lengthy it took every to run. These queries have been “complicated,” Fivetran stated, with numerous joins, aggregations, and subqueries. Every question was run solely as soon as, to forestall the database from caching the outcomes.
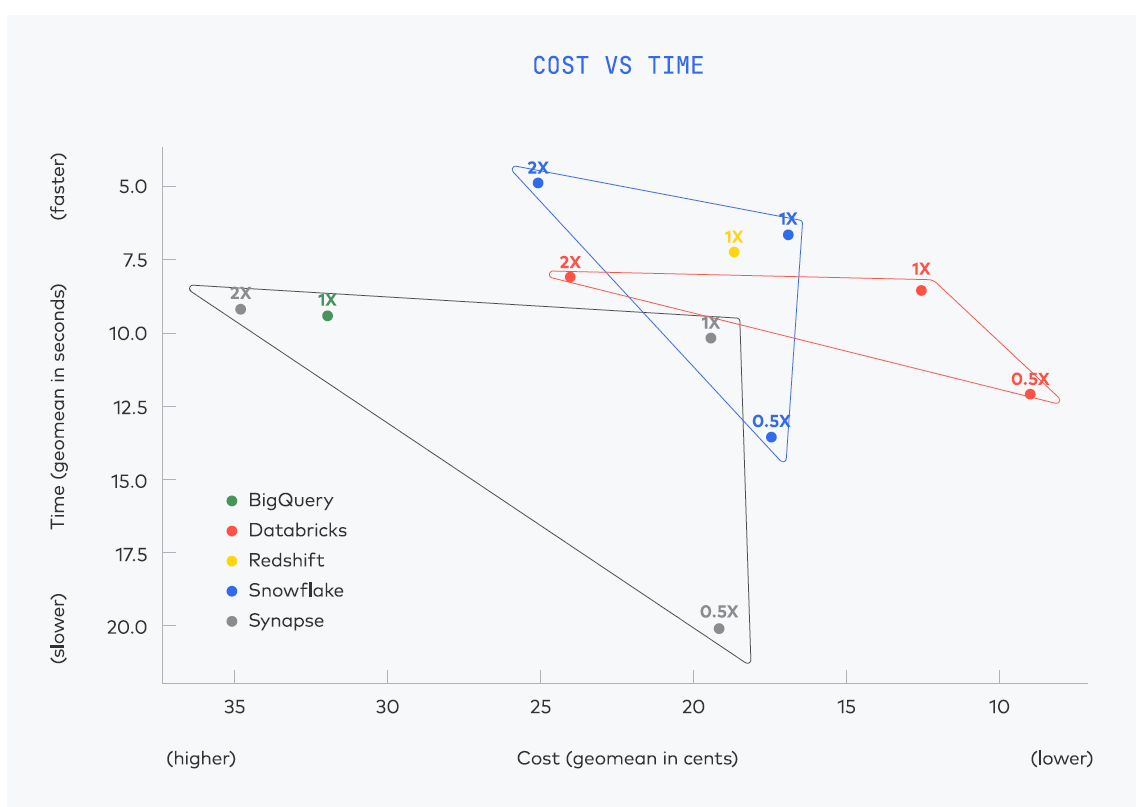
The outcomes of the checks present that every one 5 warehouses are pretty equal by way of efficiency and value, with a particular cluster of warehouse outcomes showing on the associated fee vs time graph. “All warehouses had glorious execution velocity, appropriate for advert hoc, interactive querying,” Fivetran wrote in its report.
Snowflake achieved the quickest common question execution time with the 2X configuration (an XLarge occasion working on AWS), with a geomean time of about 5 seconds per question. Nonetheless, at a value of $32.26 per hour, Snowflake 2X was additionally the costliest setup.
The only Amazon Redshift end result, in a 1X configuration working on a 5x ra3.4xlarge AWS occasion, sat proper in the midst of the pack, with a $16.30 price per hour. Redshift’s benchmark end result was only a hair slower and a pair cents dearer than Snowflake’s 1X occasion.
Databricks achieved the bottom price per hour, $4.64, with the 0.5x configuration, which ran on a Medium occasion on AWS. With a geomean time of about 8 seconds per question, Databricks’ 2X configuration was a tad slower than Snowflake’s 2X configuration, at roughly the identical price per question. Its 1X configuration was a smidge slower than AWS’s, however considerably cheaper than both Snowflake’s or AWS’s 1X end result.
Nonetheless, these outcomes could change. “We have now been made conscious of a number of points with our Databricks outcomes, and we’re at present re-running that portion of the benchmark,” Fivetran CEO Fraser said within the weblog on Tuesday.
The outcomes of the benchmark (Supply: Fivetran Cloud Knowledge Warehouse Benchmark)
The three outcomes for Microsoft Azure Synapse confirmed the most important selection when plotted on the associated fee vs. time graph. The Synapse 1X end result was pretty near the 1X outcomes for Snowflake, Databricks, and AWS. However its 2X end result (configured as DW2000c, or occupying 2000 knowledge warehouse items in Azure) generated solely marginal enhancements in velocity, whereas costing practically twice as a lot (though it nonetheless was cheaper than Snowflake’s 2X end result when computed utilizing Fivetran’s “price per hour” metric).
BigQuery was the odd man out, each by way of the outcomes and configuration (because it’s solely obtainable as an on-demand providing). The 1X configuration that Fivetran and Brooklyn Knowledge Co. used for BigQuery generated appropriate efficiency, coming in round 9 geomean seconds per question, which was proper in the midst of the pack (Synapse 1X was barely slower). However with a geomean price of about $0.32 per question, BigQuery within the sole 1X configuration was dearer than each different knowledge warehouse, apart from Synapse (with a geomean of about $0.35 per question).
Evaluating BigQuery pricing to the others was the trickiest a part of this complete benchmark, Fivetran advised Datanami. “BigQuery has a singular pay-per-query pricing mannequin. To be able to evaluate BigQuery to different methods, we have now to make assumptions about how well-matched a typical buyer’s workload is to a typical prospects knowledge warehouse,” an organization spokesperson wrote by way of e-mail. “Beneath the assumptions that we made, BigQuery is considerably dearer. Nonetheless, the BigQuery pay-per-query mannequin implies that BigQuery prospects by no means have any wasted capability, so below some circumstances BigQuery will probably be cheaper.”
4 of the info warehouses have made vital enhancements because the final time Fivetran ran this benchmark, which was again in 2020 (Azure Synapse being the lone knowledge warehouse that Fivetran didn’t check in 2020). However Databricks logged the most important enchancment, “which isn’t shocking since they fully rewrote their SQL execution engine,” Fivetran wrote within the report.
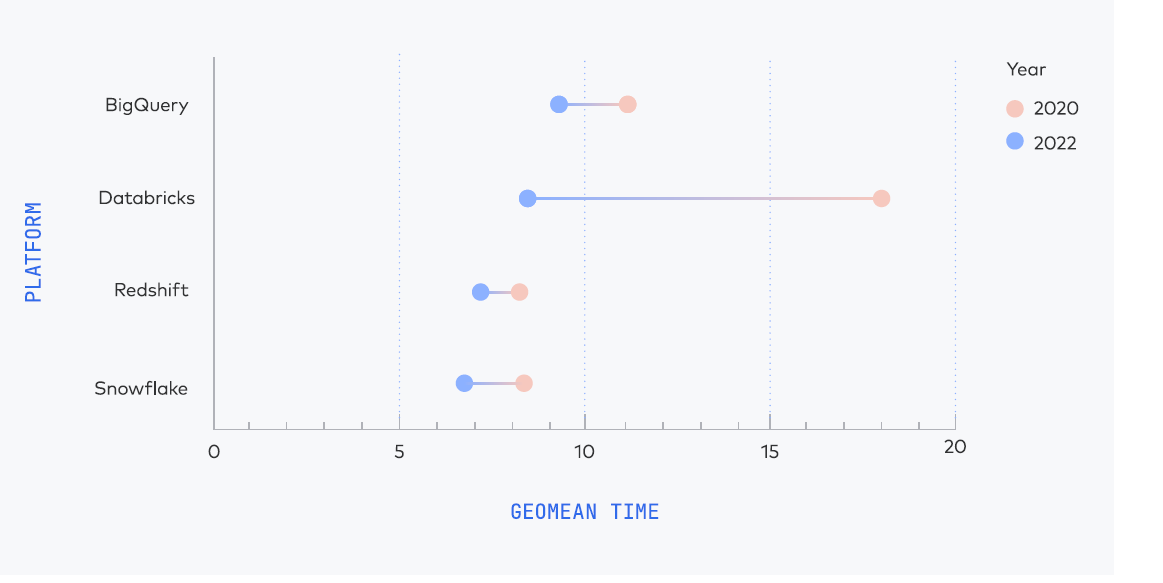
4 knowledge warehouses confirmed huge enchancment in comparison with Fivetran’s earlier benchmark (Supply: Fivetran Cloud Knowledge Warehouse Benchmark)
It’s price noting that Fivetran didn’t do lots of the issues that customers would usually do to squeeze probably the most efficiency from their cloud knowledge warehouse. For example, it didn’t use kind keys, clustering keys, or date partitioning.
“If what sort of queries are going to run in your warehouse, you should utilize these options to tune your tables and make particular queries a lot quicker,” the corporate stated in its report. “Nonetheless, typical Fivetran customers run every kind of unpredictable queries on their warehouses, so there’ll at all times be lots of queries that don’t profit from tuning.”
Nonetheless, it did use some performance-boosting options. It used column compression encodings in Redshift and column retailer indexing in Synapse. It did this to get a balanced have a look at efficiency for these knowledge warehouses, since Snowflake, Databricks, and BigQuery apply compression routinely, the corporate says.
In its report, Fivetran supplied an fascinating historical past of different TPC-DS benchmarks, together with some run by distributors.
It famous {that a} November 2021 Databricks TPC-DS run, which fashioned the idea for its declare that its warehouse was 2.7x quicker and 12x cheaper than Snowflake’s. For example, Databricks ran used the 100TB knowledge set, quite than the 1TB set. It additionally used a 4XL endpoint, which Fivetran used the L configuration. Databricks additionally tuned some tables utilizing timestamp-partitioning, custom-made the variety of partitions, and ran the “analyze” command instantly after loading to replace column statistics. It additionally reported its leads to complete runtime, which displays the time of the longest-running queries, whereas Fivetran used a geomean, which gave equal weight to all queries.
“Databricks revealed the code to breed their benchmark on the TPC-DS web site, which could be very useful for understanding the distinction,” Fivetran famous. “It could be nice if they might additionally publish the code they used for his or her Snowflake comparability, specifically it might be fascinating to see in the event that they used timestamp-partitioning in Snowflake.”

Performance amongst all cloud knowledge warehouses are comparable (ramcreations/Shutterstock)
Gigaom, sponsored by Microsoft, ran a benchmark in 2019 that pitted BigQuery, Redshift, Snowflake, and Azure SQL Knowledge Warehouse (as Synapse was referred to as then). They used the 30TB knowledge set and used a lot greater methods than Fivetran did, however the outcomes have been slower than what Fivetran was in a position to accomplish.
“It’s unusual that they noticed such gradual efficiency, on condition that their clusters have been 5-10x bigger however their knowledge was solely 3x bigger than ours,” Fivetran wrote.
An October 2016 Amazon in contrast RedShift with BigQuery, and concluded (maybe not surprisingly) that Redshift was 6x quicker and that BigQuery execution occasions usually exceeded one minute per question.
“Benchmarks from distributors that declare their very own product is the perfect needs to be taken with a grain of salt,” Fivetran wrote. “There are various particulars not laid out in Amazon’s weblog submit. For instance, they used an enormous Redshift cluster–did they allocate all reminiscence to a single consumer to make this benchmark full super-fast, regardless that that’s not a sensible configuration? We don’t know. It could be nice if AWS would publish the code obligatory to breed their benchmark, so we may consider how real looking it’s.”
All cloud knowledge warehouses can run the simple queries quick, however that’s not that useful, since most real-world queries are complicated. What issues most in the long run, Fivetran says, is whether or not the warehouses can run the tough, real-world queries in an affordable period of time.
Even with this objective, it’s powerful to focus on any of the warehouses as a lot better than the others, or to search out fault with any of them for being gradual.
“These warehouses all have glorious value and efficiency,” Fivetran concludes. “We shouldn’t be stunned that they’re comparable: The essential strategies for making a quick columnar knowledge warehouse have been well-known because the C-Retailer paper was revealed in 2005. These knowledge warehouses undoubtedly use the usual efficiency methods: columnar storage, cost-based question planning, pipelined execution and just-in-time compilation. We needs to be skeptical of any benchmark claiming one knowledge warehouse is dramatically quicker than one other.”
Crucial variations between cloud knowledge warehouses, Fivetran says, are the “qualitative variations brought on by their design selections: Some warehouses emphasize tunability, others ease of use. When you’re evaluating knowledge warehouses, you must demo a number of methods, and select the one which strikes the fitting steadiness for you.”
In terms of ease of use, BigQuery and Snowflake excel over the others, Fivetran says. Databricks and Redshift, in the meantime, are extra tuneable, the corporate says.
You may entry Fivetran’s knowledge warehouse benchmark right here.
Associated Gadgets:
Databricks Claims 30x Benefit within the Lakehouse, However Does It Maintain Water?
Oracle Broadcasts New ML Capabilities for MySQL HeatWave
New TPC Benchmark Places an Finish to Tall SQL-on-Hadoop Tales

{kind=link}