


Evaluation of Digital Well being Information (EHR) has an amazing potential for enhancing affected person care, quantitatively measuring efficiency of medical practices, and facilitating medical analysis. Statistical estimation and machine studying (ML) fashions educated on EHR knowledge can be utilized to foretell the likelihood of varied illnesses (comparable to diabetes), observe affected person wellness, and predict how sufferers reply to particular medicine. For such fashions, researchers and practitioners want entry to EHR knowledge. Nevertheless, it may be difficult to leverage EHR knowledge whereas guaranteeing knowledge privateness and conforming to affected person confidentiality rules (comparable to HIPAA).
Typical strategies to anonymize knowledge (e.g., de-identification) are sometimes tedious and dear. Furthermore, they will distort necessary options from the unique dataset, reducing the utility of the info considerably; they will also be vulnerable to privateness assaults. Alternatively, an strategy based mostly on producing artificial knowledge can keep each necessary dataset options and privateness.
To that finish, we suggest a novel generative modeling framework in “EHR-Protected: Producing Excessive-Constancy and Privateness-Preserving Artificial Digital Well being Information“. With the progressive methodology in EHR-Protected, we present that artificial knowledge can fulfill two key properties: (i) excessive constancy (i.e., they’re helpful for the duty of curiosity, comparable to having related downstream efficiency when a diagnostic mannequin is educated on them), (ii) meet sure privateness measures (i.e., they don’t reveal any actual affected person’s identification). Our state-of-the-art outcomes stem from novel approaches for encoding/decoding options, normalizing advanced distributions, conditioning adversarial coaching, and representing lacking knowledge.
 |
| Producing artificial knowledge from the unique knowledge with EHR-Protected. |
Challenges of Producing Reasonable Artificial EHR Information
There are a number of basic challenges to producing artificial EHR knowledge. EHR knowledge comprise heterogeneous options with completely different traits and distributions. There could be numerical options (e.g., blood stress) and categorical options with many or two classes (e.g., medical codes, mortality end result). A few of these could also be static (i.e., not various through the modeling window), whereas others are time-varying, comparable to common or sporadic lab measurements. Distributions may come from completely different households — categorical distributions could be extremely non-uniform (e.g., for under-represented teams) and numerical distributions could be extremely skewed (e.g., a small proportion of values being very massive whereas the overwhelming majority are small). Relying on a affected person’s situation, the variety of visits may range drastically — some sufferers go to a clinic solely as soon as whereas some go to a whole bunch of occasions, resulting in a variance in sequence lengths that’s usually a lot larger in comparison with different time-series knowledge. There generally is a excessive ratio of lacking options throughout completely different sufferers and time steps, as not all lab measurements or different enter knowledge are collected.
 |
 |
| Examples of actual EHR knowledge: temporal numerical options (higher) and temporal categorical options (decrease). |
EHR-Protected: Artificial EHR Information Era Framework
EHR-Protected consists of sequential encoder-decoder structure and generative adversarial networks (GANs), depicted within the determine beneath. As a result of EHR knowledge are heterogeneous (as described above), direct modeling of uncooked EHR knowledge is difficult for GANs. To bypass this, we suggest using a sequential encoder-decoder structure, to be taught the mapping from the uncooked EHR knowledge to the latent representations, and vice versa.
 |
| Block diagram of EHR-Protected framework. |
Whereas studying the mapping, esoteric distributions of numerical and categorical options pose an ideal problem. For instance, some values or numerical ranges may dominate the distribution, however the functionality of modeling uncommon instances is important. The proposed characteristic mapping and stochastic normalization (remodeling authentic characteristic distributions into uniform distributions with out info loss) are key to dealing with such knowledge by changing to distributions for which the coaching of encoder-decoder and GAN are extra steady (particulars could be discovered within the paper). The mapped latent representations, generated by the encoder, are then used for GAN coaching. After coaching each the encoder-decoder framework and GANs, EHR-Protected can generate artificial heterogeneous EHR knowledge from any enter, for which we feed randomly sampled vectors. Notice that solely the educated generator and decoders are used for producing artificial knowledge.
Datasets
We give attention to two real-world EHR datasets to showcase the EHR-Protected framework, MIMIC-III and eICU. Each are inpatient datasets that include various lengths of sequences and embody a number of numerical and categorical options with lacking elements.
Constancy Outcomes
The constancy metrics give attention to the standard of synthetically generated knowledge by measuring the realisticness of the artificial knowledge. Greater constancy implies that it’s harder to distinguish between artificial and actual knowledge. We consider the constancy of artificial knowledge when it comes to a number of quantitative and qualitative analyses.
Visualization
Having related protection and avoiding under-representation of sure knowledge regimes are each necessary for artificial knowledge technology. Because the beneath t-SNE analyses present, the protection of the artificial knowledge (blue) may be very related with the unique knowledge (pink). With membership inference metrics (will probably be launched within the privateness part), we additionally confirm that EHR-Protected doesn’t simply memorize the unique practice knowledge.
 |
| t-SNE analyses on temporal and static knowledge on MIMIC-III (higher) and eICU (decrease) datasets. |
Statistical Similarity
We offer quantitative comparisons of statistical similarity between authentic and artificial knowledge for every characteristic. Most statistics are well-aligned between authentic and artificial knowledge — for instance a measure of the KS statistics, i.e,. the utmost distinction within the cumulative distribution operate (CDF) between the unique and the artificial knowledge, are largely decrease than 0.03. Extra detailed tables could be discovered within the paper. The determine beneath exemplifies the CDF graphs for authentic vs. artificial knowledge for 3 options — general they appear very shut normally.
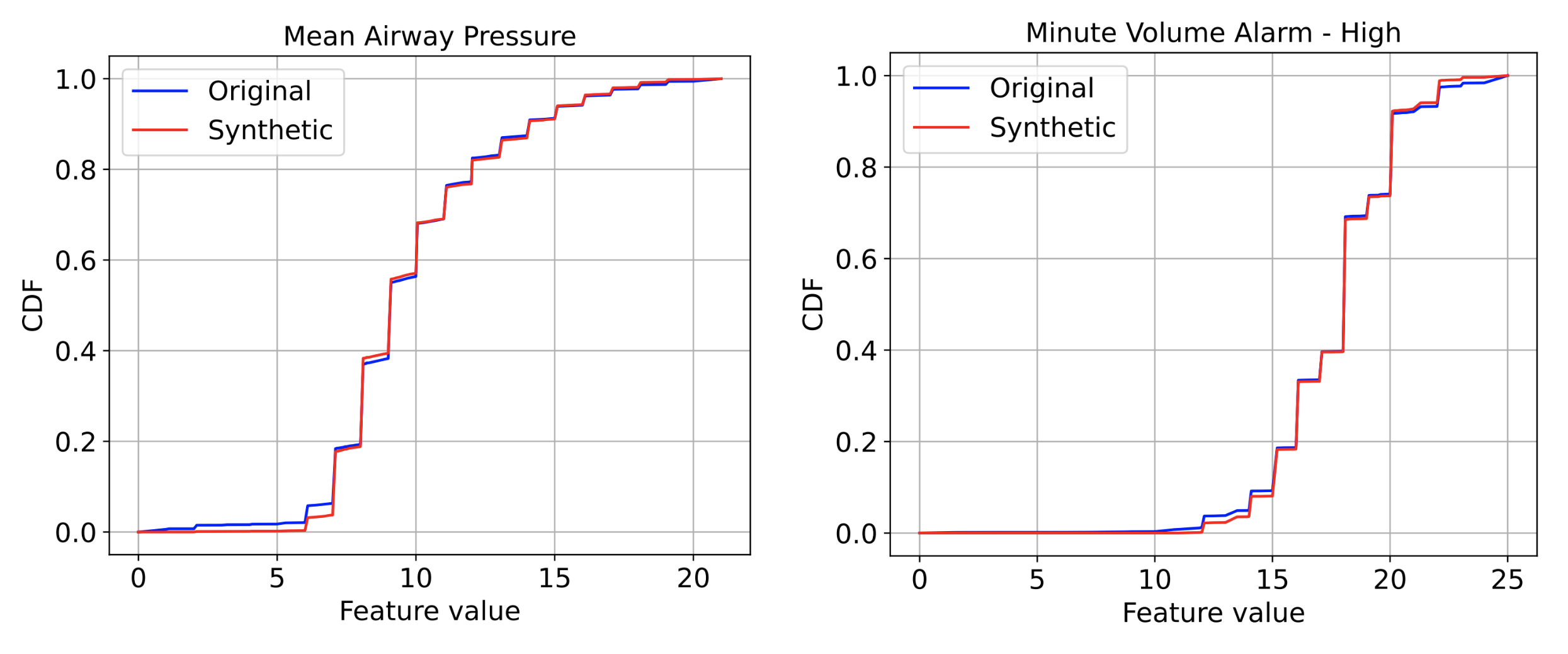 |
| CDF graphs of two options between authentic and artificial EHR knowledge. Left: Imply Airway Stress. Proper: Minute Quantity Alarm. |
Utility
As a result of one of the crucial necessary use instances of artificial knowledge is enabling ML improvements, we give attention to the constancy metric that measures the power of fashions educated on artificial knowledge to make correct predictions on actual knowledge. We examine such mannequin efficiency to an equal mannequin educated with actual knowledge. Related mannequin efficiency would point out that the artificial knowledge captures the related informative content material for the duty. As one of many necessary potential use instances of EHR, we give attention to the mortality prediction job. We think about 4 completely different predictive fashions: Gradient Boosting Tree Ensemble (GBDT), Random Forest (RF), Logistic Regression (LR), Gated Recurrent Items (GRU).
 |
| Mortality prediction efficiency with the mannequin educated on actual vs. artificial knowledge. Left: MIMIC-III. Proper: eICU. |
Within the determine above we see that in most situations, coaching on artificial vs. actual knowledge are extremely related when it comes to Space Beneath Receiver Working Traits Curve (AUC). On MIMIC-III, the most effective mannequin (GBDT) on artificial knowledge is barely 2.6% worse than the most effective mannequin on actual knowledge; whereas on eICU, the most effective mannequin (RF) on artificial knowledge is barely 0.9% worse.
Privateness Outcomes
We think about three completely different privateness assaults to quantify the robustness of the artificial knowledge with respect to privateness.
- Membership inference assault: An adversary predicts whether or not a recognized topic was a gift within the coaching knowledge used for coaching the artificial knowledge mannequin.
- Re-identification assault: The adversary explores the likelihood of some options being re-identified utilizing artificial knowledge and matching to the coaching knowledge.
- Attribute inference assault: The adversary predicts the worth of delicate options utilizing artificial knowledge.
 |
| Privateness danger analysis throughout three privateness metrics: membership-inference (top-left), re-identification (top-right), and attribute inference (backside). The perfect worth of privateness danger for membership inference is random guessing (0.5). For re-identification, the perfect case is to interchange the artificial knowledge with disjoint holdout authentic knowledge. |
The determine above summarizes the outcomes together with the perfect achievable worth for every metric. We observe that the privateness metrics are very near the perfect in all instances. The chance of understanding whether or not a pattern of the unique knowledge is a member used for coaching the mannequin may be very near random guessing; it additionally verifies that EHR-Protected doesn’t simply memorize the unique practice knowledge. For the attribute inference assault, we give attention to the prediction job of inferring particular attributes (e.g., gender, faith, and marital standing) from different attributes. We examine prediction accuracy when coaching a classifier with actual knowledge towards the identical classifier educated with artificial knowledge. As a result of the EHR-Protected bars are all decrease, the outcomes reveal that entry to artificial knowledge doesn’t result in larger prediction efficiency on particular options as in comparison with entry to the unique knowledge.
Comparability to Various Strategies
We examine EHR-Protected to alternate options (TimeGAN, RC-GAN, C-RNN-GAN) proposed for time-series artificial knowledge technology. As proven beneath, EHR-Protected considerably outperforms every.
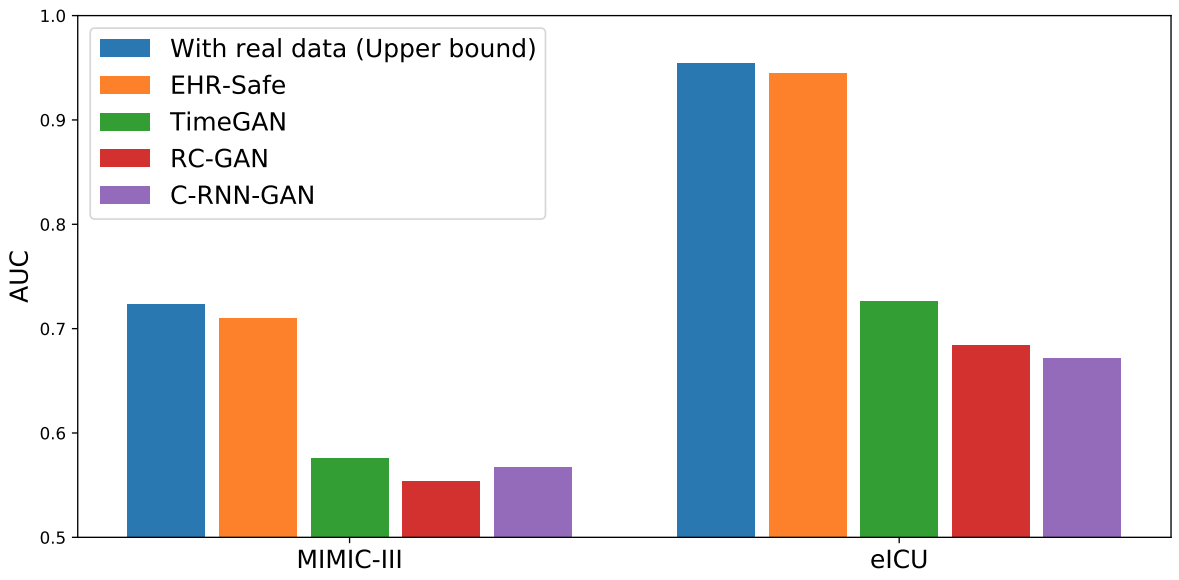 |
| Downstream job efficiency (AUC) compared to alternate options. |
Conclusions
We suggest a novel generative modeling framework, EHR-Protected, that may generate extremely life like artificial EHR knowledge which can be strong to privateness assaults. EHR-Protected is predicated on generative adversarial networks utilized to the encoded uncooked knowledge. We introduce a number of improvements within the structure and coaching mechanisms which can be motivated by the important thing challenges of EHR knowledge. These improvements are key to our outcomes that present almost-identical properties with actual knowledge (when desired downstream capabilities are thought-about) with almost-ideal privateness preservation. An necessary future course is generative modeling functionality for multimodal knowledge, together with textual content and picture, as trendy EHR knowledge may comprise each.
Acknowledgements
We gratefully acknowledge the contributions of Michel Mizrahi, Nahid Farhady Ghalaty, Thomas Jarvinen, Ashwin S. Ravi, Peter Brune, Fanyu Kong, Dave Anderson, George Lee, Arie Meir, Farhana Bandukwala, Elli Kanal, and Tomas Pfister.

{kind=link}