


|
I’m excited to announce the supply of a distributed map for AWS Step Capabilities. This circulate extends help for orchestrating large-scale parallel workloads such because the on-demand processing of semi-structured information.
Step Operate’s map state executes the identical processing steps for a number of entries in a dataset. The prevailing map state is proscribed to 40 parallel iterations at a time. This restrict makes it difficult to scale information processing workloads to course of hundreds of things (or much more) in parallel. With the intention to obtain larger parallel processing previous to in the present day, you needed to implement advanced workarounds to the prevailing map state element.
The brand new distributed map state means that you can write Step Capabilities to coordinate large-scale parallel workloads inside your serverless purposes. Now you can iterate over hundreds of thousands of objects akin to logs, pictures, or .csv recordsdata saved in Amazon Easy Storage Service (Amazon S3). The brand new distributed map state can launch as much as ten thousand parallel workflows to course of information.
You possibly can course of information by composing any service API supported by Step Capabilities, however usually, you’ll invoke Lambda capabilities to course of the info with code written in your favourite programming language.
Step Capabilities distributed map helps a most concurrency of as much as 10,000 executions in parallel, which is properly above the concurrency supported by many different AWS providers. You need to use the utmost concurrency function of the distributed map to make sure that you don’t exceed the concurrency of a downstream service. There are two components to think about when working with different providers. First, the utmost concurrency supported by the service on your account. Second, the burst and ramping charges, which decide how rapidly you possibly can obtain the utmost concurrency.
Let’s use Lambda for instance. Your capabilities’ concurrency is the variety of situations that serve requests at a given time. The default most concurrency quota for Lambda is 1,000 per AWS Area. You possibly can ask for a rise at any time. For an preliminary burst of visitors, your capabilities’ cumulative concurrency in a Area can attain an preliminary stage of between 500 and 3000, which varies per Area. The burst concurrency quota applies to all of your capabilities within the Area.
When utilizing a distributed map, make sure you confirm the quota on downstream providers. Restrict the distributed map most concurrency throughout your growth, and plan for service quota will increase accordingly.
To check the brand new distributed map with the unique map state circulate, I created this desk.
| Unique map state circulate | New distributed map circulate | |
| Sub workflows |
|
|
| Parallel branches | Map iterations run in parallel, with an efficient most concurrency of round 40 at a time. | Can cross hundreds of thousands of things to a number of baby executions, with concurrency of as much as 10,000 executions at a time. |
| Enter supply | Accepts solely a JSON array as enter. | Accepts enter as Amazon S3 object record, JSON arrays or recordsdata, csv recordsdata, or Amazon S3 stock. |
| Payload | 256 KB | Every iteration receives a reference to a file (Amazon S3) or a single report from a file (state enter). Precise file processing functionality is proscribed by Lambda storage and reminiscence. |
| Execution historical past | 25,000 occasions | Every iteration of the map state is a baby execution, with as much as 25,000 occasions every (categorical mode has no restrict on execution historical past). |
Sub-workflows inside a distributed map work with each Normal workflows and the low-latency, short-duration Specific Workflows.
This new functionality is optimized to work with S3. I can configure the bucket and prefix the place my information are saved straight from the distributed map configuration. The distributed map stops studying after 100 million gadgets and helps JSON or csv recordsdata of as much as 10GB.
When processing giant recordsdata, take into consideration downstream service capabilities. Let’s take Lambda once more for instance. Every enter—a file on S3, for instance—should match inside the Lambda operate execution setting when it comes to short-term storage and reminiscence. To make it simpler to deal with giant recordsdata, Lambda Powertools for Python launched a brand new streaming function to fetch, remodel, and course of S3 objects with minimal reminiscence footprint. This enables your Lambda capabilities to deal with recordsdata bigger than the scale of their execution setting. To be taught extra about this new functionality, verify the Lambda Powertools documentation.
Let’s See It in Motion
For this demo, I’ll create a workflow that processes one thousand canine pictures saved on S3. The pictures are already saved on S3.
➜ ~ aws s3 ls awsnewsblog-distributed-map/pictures/
2022-11-08 15:03:36 27034 n02085620_10074.jpg
2022-11-08 15:03:36 34458 n02085620_10131.jpg
2022-11-08 15:03:36 12883 n02085620_10621.jpg
2022-11-08 15:03:36 34910 n02085620_1073.jpg
...
➜ ~ aws s3 ls awsnewsblog-distributed-map/pictures/ | wc -l
1000The workflow and the S3 bucket should be in the identical Area.
To get began, I navigate to the Step Capabilities web page of the AWS Administration Console and choose Create state machine. On the subsequent web page, I select to design my workflow utilizing the visible editor. The distributed map works with Normal workflows, and I maintain the default choice as-is. I choose Subsequent to enter the visible editor.
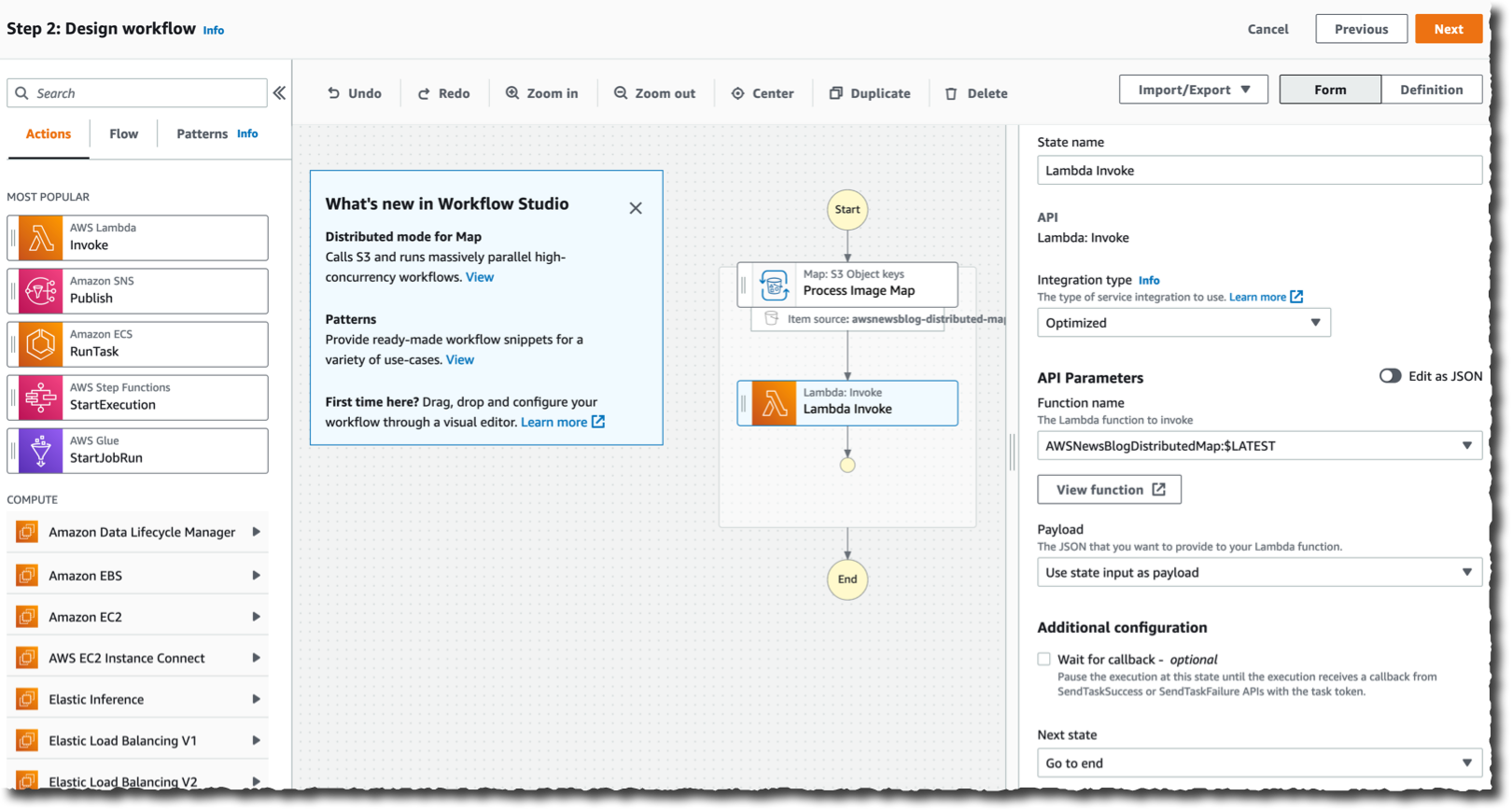
 Within the visible editor, I search and choose the Map element on the left-side pane, and I drag it to the workflow space. On the best aspect, I configure the element. I select Distributed as Processing mode and Amazon S3 as Merchandise Supply.
Within the visible editor, I search and choose the Map element on the left-side pane, and I drag it to the workflow space. On the best aspect, I configure the element. I select Distributed as Processing mode and Amazon S3 as Merchandise Supply.
Distributed maps are natively built-in with S3. I enter the identify of the bucket (awsnewsblog-distributed-map) and the prefix (pictures) the place my pictures are saved.
 On the Runtime Settings part, I select Specific for Youngster workflow kind. I additionally could determine to limit the Concurrency limit. It helps to make sure we function inside the concurrency quotas of the downstream providers (Lambda on this demo) for a selected account or Area.
On the Runtime Settings part, I select Specific for Youngster workflow kind. I additionally could determine to limit the Concurrency limit. It helps to make sure we function inside the concurrency quotas of the downstream providers (Lambda on this demo) for a selected account or Area.
By default, the output of my sub-workflows can be aggregated as state output, as much as 256KB. To course of bigger outputs, I could select to Export map state outcomes to Amazon S3.

Lastly, I outline what to do for every file. On this demo, I wish to invoke a Lambda operate for every file within the S3 bucket. The operate exists already. I seek for and choose the Lambda invocation motion on the left-side pane. I drag it to the distributed map element. Then, I take advantage of the right-side configuration panel to pick out the precise Lambda operate to invoke: AWSNewsBlogDistributedMap on this instance.
When I’m completed, I choose Subsequent. I choose Subsequent once more on the Assessment generated code web page (not proven right here).
On the Specify state machine settings web page, I enter a Title for my state machine and the IAM Permissions to run. Then, I choose Create state machine.
 Now I’m prepared to begin the execution. On the State machine web page, I choose the brand new workflow and choose Begin execution. I can optionally enter a JSON doc to cross to the workflow. On this demo, the workflow doesn’t deal with the enter information. I go away it as-is, and I choose Begin execution.
Now I’m prepared to begin the execution. On the State machine web page, I choose the brand new workflow and choose Begin execution. I can optionally enter a JSON doc to cross to the workflow. On this demo, the workflow doesn’t deal with the enter information. I go away it as-is, and I choose Begin execution.
 |
 |
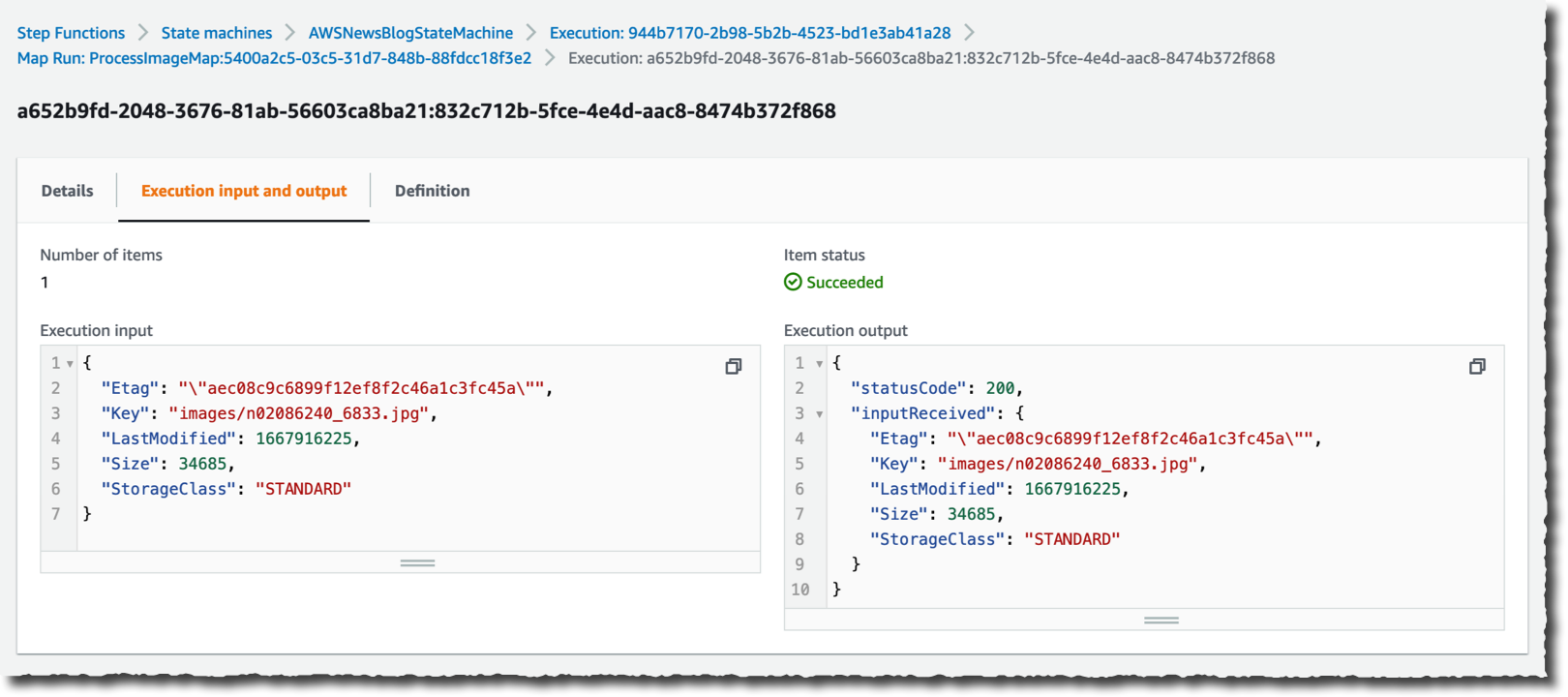
Through the execution of the workflow, I can monitor the progress. I observe the variety of iterations, and the variety of gadgets efficiently processed or in error.
 I can drill down on one particular execution to see the main points.
I can drill down on one particular execution to see the main points.
With only a few clicks, I created a large-scale and closely parallel workflow in a position to deal with a really giant amount of knowledge.
Which AWS Service Ought to I Use
As typically occurs on AWS, you would possibly observe an overlap between this new functionality and current providers akin to AWS Glue, Amazon EMR, or Amazon S3 Batch Operations. Let’s attempt to differentiate the use instances.
In my psychological mannequin, information scientists and information engineers use AWS Glue and EMR to course of giant quantities of knowledge. Alternatively, utility builders will use Step Capabilities so as to add serverless information processing into their purposes. Step Capabilities is ready to scale from zero rapidly, which makes it an excellent match for interactive workloads the place clients could also be ready for the outcomes. Lastly, system directors and IT operation groups are seemingly to make use of Amazon S3 Batch Operations for single-step IT automation operations akin to copying, tagging, or altering permissions on billions of S3 objects.
Pricing and Availability
AWS Step Capabilities’ distributed map is usually obtainable within the following ten AWS Areas: US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Singapore, Sydney, Tokyo), Canada (Central), and Europe (Frankfurt, Eire, Stockholm).
The pricing mannequin for the prevailing inline map state doesn’t change. For the brand new distributed map state, we cost one state transition per iteration. Pricing varies between Areas, and it begins at $0.025 per 1,000 state transitions. While you course of your information utilizing categorical workflows, you might be additionally charged based mostly on the variety of requests on your workflow and its period. Once more, costs range between Areas, however they begin at $1.00 per 1 million requests and $0.06 per GB-hour (prorated to 100ms).
For a similar quantity of iterations, you’ll observe a value discount when utilizing the mix of the distributed map and commonplace workflows in comparison with the prevailing inline map. While you use categorical workflows, anticipate the prices to remain the identical for extra worth with the distributed map.
I’m actually excited to find what you’ll construct utilizing this new functionality and the way it will unlock innovation. Go begin to construct extremely parallel serverless information processing workflows in the present day!

{kind=link}