

In recent times, language fashions (LMs) have develop into extra outstanding in pure language processing (NLP) analysis and are additionally changing into more and more impactful in follow. Scaling up LMs has been proven to enhance efficiency throughout a variety of NLP duties. As an illustration, scaling up language fashions can enhance perplexity throughout seven orders of magnitude of mannequin sizes, and new skills resembling multi-step reasoning have been noticed to come up because of mannequin scale. Nevertheless, one of many challenges of continued scaling is that coaching new, bigger fashions requires nice quantities of computational assets. Furthermore, new fashions are sometimes educated from scratch and don’t leverage the weights from beforehand current fashions.
On this weblog publish, we discover two complementary strategies for bettering current language fashions by a big margin with out utilizing huge computational assets. First, in “Transcending Scaling Legal guidelines with 0.1% Further Compute”, we introduce UL2R, which is a light-weight second stage of pre-training that makes use of a mixture-of-denoisers goal. UL2R improves efficiency throughout a variety of duties and even unlocks emergent efficiency on duties that beforehand had near random efficiency. Second, in “Scaling Instruction-Finetuned Language Fashions”, we discover fine-tuning a language mannequin on a set of datasets phrased as directions, a course of we name “Flan”. This method not solely boosts efficiency, but in addition improves the usability of the language mannequin to consumer inputs with out engineering of prompts. Lastly, we present that Flan and UL2R will be mixed as complementary methods in a mannequin referred to as Flan-U-PaLM 540B, which outperforms the unadapted PaLM 540B mannequin by 10% throughout a collection of difficult analysis benchmarks.
UL2R Coaching
Historically, most language fashions are pre-trained on both a causal language modeling goal that permits the mannequin to foretell the subsequent phrase in a sequence (e.g., GPT-3 or PaLM) or a denoising goal, the place the mannequin learns to recuperate the unique sentence from a corrupted sequence of phrases, (e.g., T5). Though there are some tradeoffs in language modeling goals in that causal LMs are higher at long-form era and LMs educated on a denoising goal are higher for fine-tuning, in prior work we demonstrated {that a} mixture-of-denoisers goal that features each goals leads to higher efficiency on each situations.
Nevertheless, pre-training a big language mannequin on a special goal from scratch will be computationally prohibitive. Therefore, we suggest UL2 Restore (UL2R), a further stage of continued pre-training with the UL2 goal that solely requires a comparatively small quantity of compute. We apply UL2R to PaLM and name the ensuing new language mannequin U-PaLM.
In empirical evaluations, we discovered that scaling curves enhance considerably with solely a small quantity of UL2 coaching. As an illustration, we present that through the use of UL2R on the intermediate checkpoint of PaLM 540B, we attain the efficiency of the ultimate PaLM 540B checkpoint whereas utilizing 2x much less compute (or a distinction of 4.4 million TPUv4 hours). Naturally, making use of UL2R to the ultimate PaLM 540B checkpoint additionally results in substantial enhancements, as described within the paper.
 |
| Compute versus mannequin efficiency of PaLM 540B and U-PaLM 540B on 26 NLP benchmarks (listed in Desk 8 within the paper). U-PaLM 540B continues coaching PaLM for a really small quantity of compute however offers a considerable achieve in efficiency. |
One other profit that we noticed from utilizing UL2R is that on some duties, efficiency is a lot better than fashions educated purely on the causal language modeling goal. As an illustration, there are various BIG-Bench duties which have been described as “emergent skills”, i.e., skills that may solely be noticed in sufficiently massive language fashions. Though the best way that emergent skills are mostly discovered is by scaling up the dimensions of the LM, we discovered that UL2R can really elicit emergent skills with out growing the dimensions of the LM.
As an illustration, within the Navigate activity from BIG-Bench, which measures the mannequin’s potential to carry out state monitoring, all fashions besides U-PaLM with lower than 1023 coaching FLOPs obtain roughly random efficiency. U-PaLM efficiency is greater than 10 factors above that. One other instance of that is the Snarks activity from BIG-Bench, which measures the mannequin’s potential to detect sarcasm. Once more, whereas all fashions lower than 1024 coaching FLOPs obtain roughly random efficiency, U-PaLM achieves nicely above even for the 8B and 62B fashions.
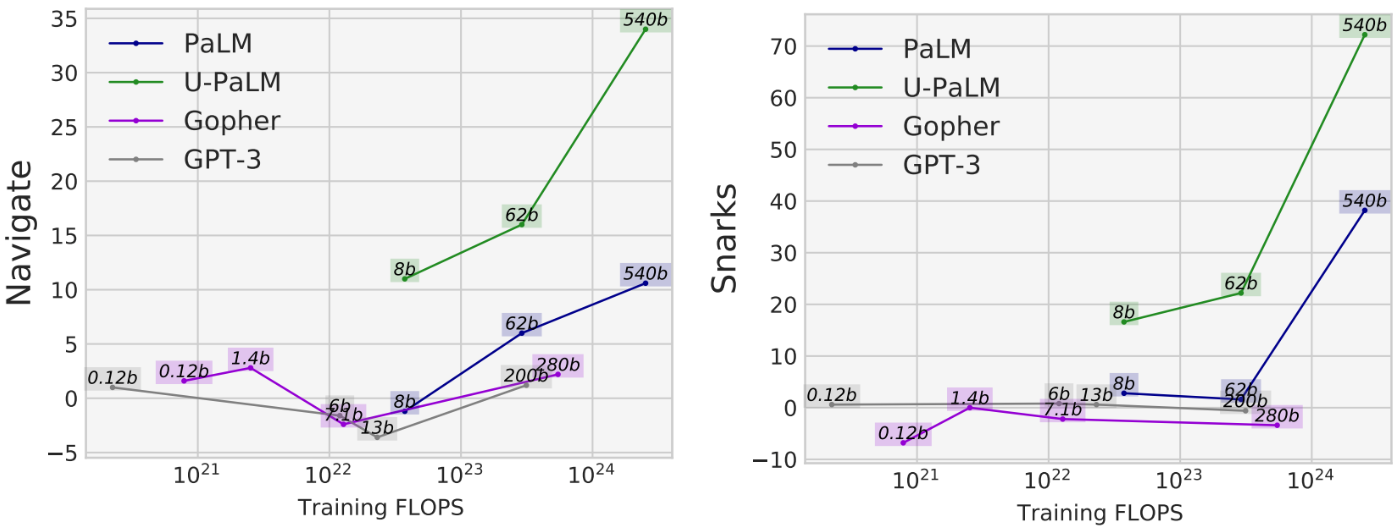 |
| For 2 skills from BIG-Bench that reveal emergent activity efficiency, U-PaLM achieves emergence at a smaller mannequin measurement attributable to its use of the UL2R goal. |
Instruction High-quality-Tuning
In our second paper, we discover instruction fine-tuning, which entails fine-tuning LMs on a set of NLP datasets phrased as directions. In prior work, we utilized instruction fine-tuning to a 137B-parameter mannequin on 62 NLP duties, resembling answering a trivia query, classifying the sentiment of a film, or translating a sentence to Spanish.
On this work we fine-tune a 540B parameter language mannequin on greater than 1.8K duties. Furthermore, whereas earlier efforts solely fine-tuned a LM with few-shot exemplars (e.g., MetaICL) or zero-shot with out exemplars (e.g., FLAN, T0), we fine-tune on a mix of each. We additionally embrace chain of thought fine-tuning information, which permits the mannequin to carry out multi-step reasoning. We name our improved methodology “Flan”, for fine-tuning language fashions. Notably, even with fine-tuning on 1.8K duties, Flan solely makes use of a small portion of compute in comparison with pre-training (e.g., for PaLM 540B, Flan solely requires 0.2% of the pre-training compute).
 |
| We fine-tune language fashions on 1.8K duties phrased as directions, and consider them on unseen duties, which aren’t included in fine-tuning. We fine-tune each with and with out exemplars (i.e., zero-shot and few-shot) and with and with out chain of thought, enabling generalization throughout a variety of analysis situations. |
Within the paper, we instruction–fine-tune LMs of a variety of sizes to research the joint impact of scaling each the dimensions of the LM and the variety of fine-tuning duties. As an illustration, for the PaLM class of LMs, which incorporates fashions of 8B, 62B, and 540B parameters. We consider our fashions on 4 difficult benchmark analysis suites (MMLU, BBH, TyDiQA, and MGSM), and discover that each scaling the variety of parameters and variety of fine-tuning duties improves efficiency on unseen duties.
 |
| Each scaling as much as a 540B parameter mannequin and utilizing 1.8K fine-tuning duties improves the efficiency on unseen duties. The y-axis is the normalized common over 4 analysis suites (MMLU, BBH, TyDiQA, and MGSM). |
Along with higher efficiency, instruction fine-tuning a LM permits it to answer consumer directions at inference time, with out few-shot exemplars or immediate engineering. This makes LMs extra user-friendly throughout a variety of inputs. As an illustration, LMs with out instruction fine-tuning can typically repeat the enter or fail to observe directions, however instruction fine-tuning mitigates such errors.
 |
| Our instruction–fine-tuned language mannequin, Flan-PaLM, responds higher to directions in comparison with the PaLM mannequin with out instruction fine-tuning. |
Placing Them Collectively
Lastly, we present that UL2R and Flan will be mixed to coach the Flan-U-PaLM mannequin. Since Flan makes use of new information from NLP duties and permits zero-shot instruction following, we apply Flan because the second technique after UL2R. We once more consider on the 4 benchmark suites, and discover that the Flan-U-PaLM mannequin outperforms PaLM fashions with simply UL2R (U-PaLM) or simply Flan (Flan-PaLM). Additional, Flan-U-PaLM achieves a brand new state-of-the-art on the MMLU benchmark with a rating of 75.4% when mixed with chain of thought and self-consistency.
 |
| Combining UL2R and Flan (Flan-U-PaLM) results in the very best efficiency in comparison with simply utilizing UL2R (U-PaLM) or simply Flan (Flan-U-PaLM). Efficiency is the normalized common over 4 analysis suites (MMLU, BBH, TyDiQA, and MGSM). |
General, UL2R and Flan are two complementary strategies for bettering pre-trained language fashions. UL2R adapts the LM to a mixture-of-denoisers goal utilizing the identical information, whereas Flan leverages coaching information from over 1.8K NLP duties to show the mannequin to observe directions. As LMs develop into even bigger, methods resembling UL2R and Flan that enhance normal efficiency with out massive quantities of compute might develop into more and more enticing.
Acknowledgements
It was a privilege to collaborate on these two papers with Hyung Received Chung, Vinh Q. Tran, David R. So, Siamak Shakeri, Xavier Garcia, Huaixiu Steven Zheng, Jinfeng Rao, Aakanksha Chowdhery, Denny Zhou, Donald Metzler, Slav Petrov, Neil Houlsby, Quoc V. Le, Mostafa Dehghani, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Ed H. Chi, Jeff Dean, Jacob Devlin, and Adam Roberts.

{kind=link}