

Advert expertise suppliers extensively use machine studying (ML) fashions to foretell and current customers with probably the most related advertisements, and to measure the effectiveness of these advertisements. With rising give attention to on-line privateness, there’s a possibility to determine ML algorithms which have higher privacy-utility trade-offs. Differential privateness (DP) has emerged as a well-liked framework for growing ML algorithms responsibly with provable privateness ensures. It has been extensively studied within the privateness literature, deployed in industrial functions and employed by the U.S. Census. Intuitively, the DP framework allows ML fashions to study population-wide properties, whereas defending user-level info.
When coaching ML fashions, algorithms take a dataset as their enter and produce a skilled mannequin as their output. Stochastic gradient descent (SGD) is a generally used non-private coaching algorithm that computes the common gradient from a random subset of examples (known as a mini-batch), and makes use of it to point the path in direction of which the mannequin ought to transfer to suit that mini-batch. Essentially the most extensively used DP coaching algorithm in deep studying is an extension of SGD known as DP stochastic gradient descent (DP-SGD).
DP-SGD consists of two extra steps: 1) earlier than averaging, the gradient of every instance is norm-clipped if the L2 norm of the gradient exceeds a predefined threshold; and a couple of) Gaussian noise is added to the common gradient earlier than updating the mannequin. DP-SGD may be tailored to any current deep studying pipeline with minimal modifications by changing the optimizer, resembling SGD or Adam, with their DP variants. Nevertheless, making use of DP-SGD in apply might result in a big lack of mannequin utility (i.e., accuracy) with giant computational overheads. In consequence, numerous analysis makes an attempt to use DP-SGD coaching on extra sensible, large-scale deep studying issues. Latest research have additionally proven promising DP coaching outcomes on laptop imaginative and prescient and pure language processing issues.
In “Personal Advert Modeling with DP-SGD”, we current a scientific research of DP-SGD coaching on advertisements modeling issues, which pose distinctive challenges in comparison with imaginative and prescient and language duties. Advertisements datasets typically have a excessive imbalance between information courses, and encompass categorical options with giant numbers of distinctive values, resulting in fashions which have giant embedding layers and extremely sparse gradient updates. With this research, we display that DP-SGD permits advert prediction fashions to be skilled privately with a a lot smaller utility hole than beforehand anticipated, even within the excessive privateness regime. Furthermore, we display that with correct implementation, the computation and reminiscence overhead of DP-SGD coaching may be considerably diminished.
Analysis
We consider personal coaching utilizing three advertisements prediction duties: (1) predicting the click-through charge (pCTR) for an advert, (2) predicting the conversion charge (pCVR) for an advert after a click on, and three) predicting the anticipated variety of conversions (pConvs) after an advert click on. For pCTR, we use the Criteo dataset, which is a extensively used public benchmark for pCTR fashions. We consider pCVR and pConvs utilizing inside Google datasets. pCTR and pCVR are binary classification issues skilled with the binary cross entropy loss and we report the check AUC loss (i.e., 1 – AUC). pConvs is a regression drawback skilled with Poisson log loss (PLL) and we report the check PLL.
For every process, we consider the privacy-utility trade-off of DP-SGD by the relative enhance within the lack of privately skilled fashions beneath numerous privateness budgets (i.e., privateness loss). The privateness finances is characterised by a scalar ε, the place a decrease ε signifies increased privateness. To measure the utility hole between personal and non-private coaching, we compute the relative enhance in loss in comparison with the non-private mannequin (equal to ε = ∞). Our most important remark is that on all three widespread advert prediction duties, the relative loss enhance could possibly be made a lot smaller than beforehand anticipated, even for very excessive privateness (e.g., ε <= 1) regimes.
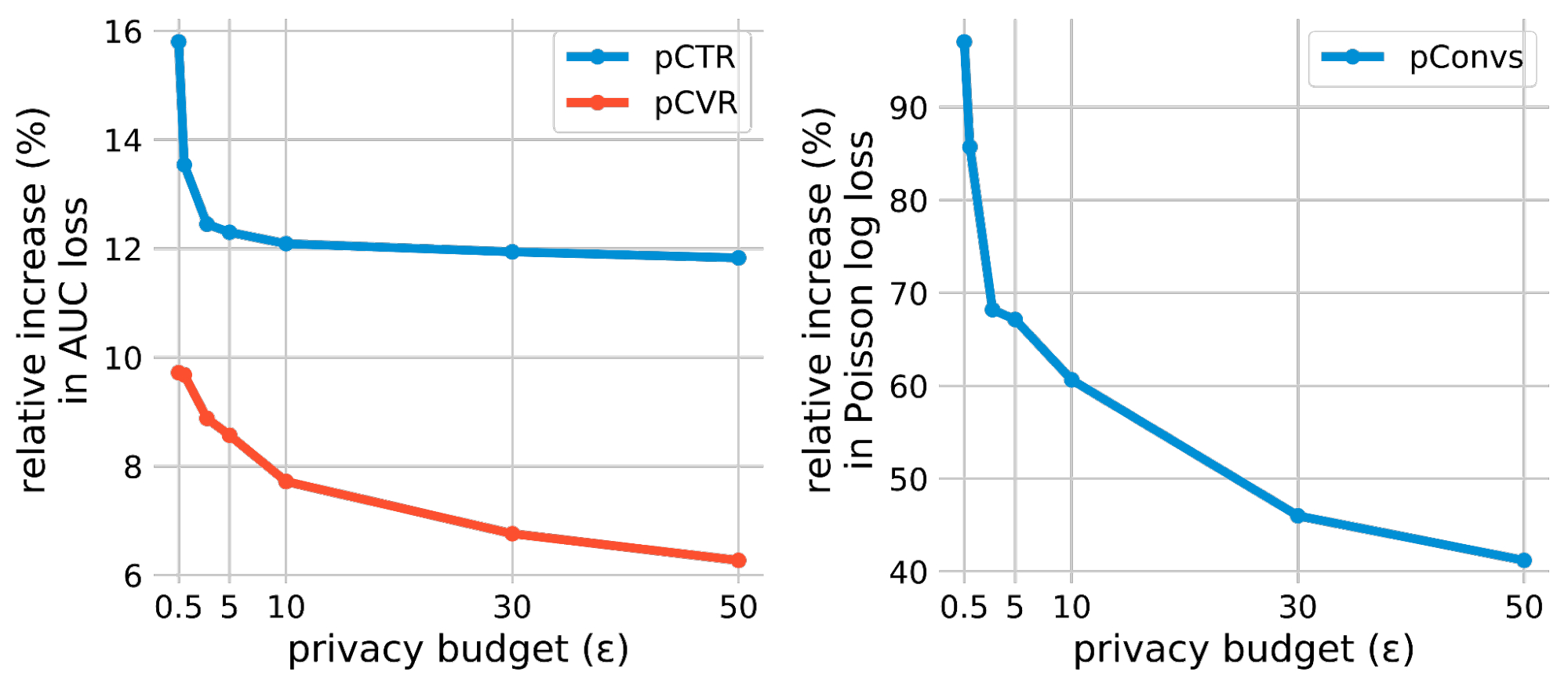 |
| DP-SGD outcomes on three advertisements prediction duties. The relative enhance in loss is computed towards the non-private baseline (i.e., ε = ∞) mannequin of every process. |
Improved Privateness Accounting
Privateness accounting estimates the privateness finances (ε) for a DP-SGD skilled mannequin, given the Gaussian noise multiplier and different coaching hyperparameters. Rényi Differential Privateness (RDP) accounting has been probably the most extensively used method in DP-SGD since the unique paper. We discover the most recent advances in accounting strategies to supply tighter estimates. Particularly, we use connect-the-dots for accounting primarily based on the privateness loss distribution (PLD). The next determine compares this improved accounting with the classical RDP accounting and demonstrates that PLD accounting improves the AUC on the pCTR dataset for all privateness budgets (ε).
 |
Giant Batch Coaching
Batch measurement is a hyperparameter that impacts totally different facets of DP-SGD coaching. As an illustration, rising the batch measurement might cut back the quantity of noise added throughout coaching beneath the identical privateness assure, which reduces the coaching variance. The batch measurement additionally impacts the privateness assure by way of different parameters, such because the subsampling chance and coaching steps. There isn’t any easy components to quantify the influence of batch sizes. Nevertheless, the connection between batch measurement and the noise scale is quantified utilizing privateness accounting, which calculates the required noise scale (measured when it comes to the customary deviation) beneath a given privateness finances (ε) when utilizing a selected batch measurement. The determine under plots such relations in two totally different eventualities. The primary state of affairs makes use of fastened epochs, the place we repair the variety of passes over the coaching dataset. On this case, the variety of coaching steps is diminished because the batch measurement will increase, which might lead to undertraining the mannequin. The second, extra simple state of affairs makes use of fastened coaching steps (fastened steps).
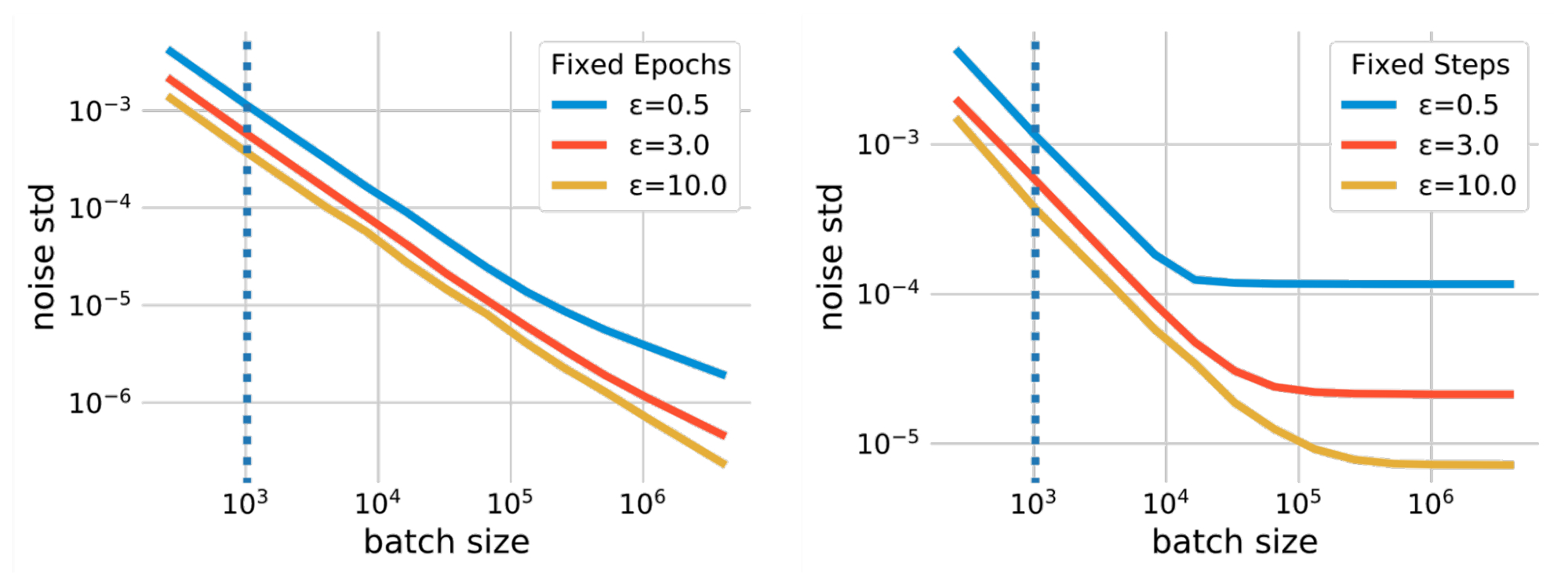 |
| The connection between batch measurement and noise scales. Privateness accounting requires a noise customary deviation, which decreases because the batch measurement will increase, to fulfill a given privateness finances. In consequence, by utilizing a lot bigger batch sizes than the non-private baseline (indicated by the vertical dotted line), the size of Gaussian noise added by DP-SGD may be considerably diminished. |
Along with permitting a smaller noise scale, bigger batch sizes additionally enable us to make use of a bigger threshold of norm clipping every per-example gradient as required by DP-SGD. For the reason that norm clipping step introduces biases within the common gradient estimation, this leisure mitigates such biases. The desk under compares the outcomes on the Criteo dataset for pCTR with a regular batch measurement (1,024 examples) and a big batch measurement (16,384 examples), mixed with giant clipping and elevated coaching epochs. We observe that enormous batch coaching considerably improves the mannequin utility. Observe that enormous clipping is barely potential with giant batch sizes. Giant batch coaching was additionally discovered to be important for DP-SGD coaching in Language and Pc Imaginative and prescient domains.
 |
| The results of enormous batch coaching. For 3 totally different privateness budgets (ε), we observe that when coaching the pCTR fashions with giant batch measurement (16,384), the AUC is considerably increased than with common batch measurement (1,024). |
Quick per-example Gradient Norm Computation
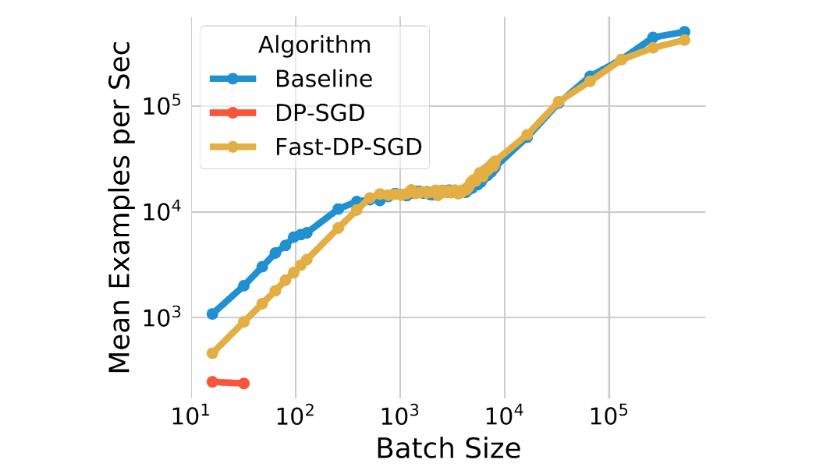
The per-example gradient norm calculation used for DP-SGD typically causes computational and reminiscence overhead. This calculation removes the effectivity of ordinary backpropagation on accelerators (like GPUs) that compute the common gradient for a batch with out materializing every per-example gradient. Nevertheless, for sure neural community layer sorts, an environment friendly gradient norm computation algorithm permits the per-example gradient norm to be computed with out the necessity to materialize the per-example gradient vector. We additionally be aware that this algorithm can effectively deal with neural community fashions that depend on embedding layers and absolutely linked layers for fixing advertisements prediction issues. Combining the 2 observations, we use this algorithm to implement a quick model of the DP-SGD algorithm. We present that Quick-DP-SGD on pCTR can deal with the same variety of coaching examples and the identical most batch measurement on a single GPU core as a non-private baseline.
 |
| The computation effectivity of our quick implementation (Quick-DP-SGD) on pCTR. |
In comparison with the non-private baseline, the coaching throughput is comparable, besides with very small batch sizes. We additionally evaluate it with an implementation using the JAX Simply-in-Time (JIT) compilation, which is already a lot quicker than vanilla DP-SGD implementations. Our implementation will not be solely quicker, however additionally it is extra reminiscence environment friendly. The JIT-based implementation can not deal with batch sizes bigger than 64, whereas our implementation can deal with batch sizes as much as 500,000. Reminiscence effectivity is vital for enabling large-batch coaching, which was proven above to be vital for enhancing utility.
Conclusion
We’ve proven that it’s potential to coach personal advertisements prediction fashions utilizing DP-SGD which have a small utility hole in comparison with non-private baselines, with minimal overhead for each computation and reminiscence consumption. We imagine there may be room for even additional discount of the utility hole via methods resembling pre-training. Please see the paper for full particulars of the experiments.
Acknowledgements
This work was carried out in collaboration with Carson Denison, Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, and Avinash Varadarajan. We thank Silvano Bonacina and Samuel Ieong for a lot of helpful discussions.

{kind=link}