

Amazon Athena now allows information analysts and information engineers to benefit from the easy-to-use, interactive, serverless expertise of Athena with Apache Spark along with SQL. Now you can use the expressive energy of Python and construct interactive Apache Spark functions utilizing a simplified pocket book expertise on the Athena console or by way of Athena APIs. For interactive Spark functions, you may spend much less time ready and be extra productive as a result of Athena immediately begins operating functions in lower than a second. And since Athena is serverless and totally managed, analysts can run their workloads with out worrying in regards to the underlying infrastructure.
Information lakes are a standard mechanism to retailer and analyze information as a result of they permit corporations to handle a number of information sorts from all kinds of sources, and retailer this information, structured and unstructured, in a centralized repository. Apache Spark is a well-liked open-source, distributed processing system optimized for quick analytics workloads towards information of any measurement. It’s usually used to discover information lakes to derive insights. For performing interactive information explorations on the information lake, now you can use the instant-on, interactive, and totally managed Apache Spark engine in Athena. It allows you to be extra productive and get began shortly, spending virtually no time organising infrastructure and Spark configurations.
On this put up, we present how you should use Athena for Apache Spark to discover and derive insights out of your information lake hosted on Amazon Easy Storage Service (Amazon S3).
Answer overview
We showcase studying and exploring CSV and Parquet datasets to carry out interactive evaluation utilizing Athena for Apache Spark and the expressive energy of Python. We additionally carry out visible evaluation utilizing the pre-installed Python libraries. For operating this evaluation, we use the built-in pocket book editor in Athena.
For the aim of this put up, we use the NOAA International Floor Abstract of Day public dataset from the Registry of Open Information on AWS, which consists of each day climate summaries from varied NOAA climate stations. The dataset is primarily in plain textual content CSV format. We now have reworked your complete and subsets of the CSV dataset into Parquet format for our demo.
Earlier than operating the demo, we need to introduce the next ideas associated to Athena for Spark:
- Periods – If you open a pocket book in Athena, a brand new session is began for it mechanically. Periods hold observe of the variables and state of notebooks.
- Calculations – Working a cell in a pocket book means operating a calculation within the present session. So long as a session is operating, calculations use and modify the state that’s maintained for the pocket book.
For extra particulars, discuss with Session and Calculations.
Conditions
For this demo, you want the next stipulations:
- An AWS account with entry to the AWS Administration Console
- Athena permissions on the workgroup
DemoAthenaSparkWorkgroup, which you create as a part of this demo - AWS Identification and Entry Administration (IAM) permissions to create, learn, and replace the IAM function and insurance policies created as a part of the demo
- Amazon S3 permissions to create an S3 bucket and browse the bucket location
The next coverage grants these permissions. Connect it to the IAM function or consumer you employ to check in to the console. Make sure that to offer your AWS account ID and the Area by which you’re operating the demo.
Create your Athena workgroup
We create a brand new Athena workgroup with Spark because the engine. Full the next steps:
- On the Athena console, select Workgroups within the navigation pane.
- Select Create workgroup.
- For Workgroup identify, enter
DemoAthenaSparkWorkgroup.
Make sure that to enter the precise identify as a result of the previous IAM permissions are scoped down for the workgroup with this identify. - For Analytics engine, select Apache Spark.
- For Further configurations, choose Use defaults.
The defaults embody the creation of an IAM function with the required permissions to run Spark calculations on Athena and an S3 bucket to retailer calculation outcomes. It additionally units the pocket book (which we create later) encryption key administration to an AWS Key Administration Service (AWS KMS) key owned by Athena. - Optionally, add tags to your workgroup.
- Select Create workgroup.
Modify the IAM function
Creating the workgroup creates a brand new IAM function. Select the newly created workgroup, then the worth beneath Position ARN to be redirected to the IAM console.
Add the next permission as an inline coverage to the IAM function created earlier. This enables the function to learn the S3 datasets. For directions, discuss with the part To embed an inline coverage for a consumer or function (console) in Including IAM identification permissions (console).
Arrange your pocket book
To run the evaluation on Spark on Athena, we want a pocket book. Full the next steps to create one:
- On the Athena console, select Pocket book Editor.
- Select the newly created workgroup
DemoAthenaSparkWorkgroupon the drop-down menu. - Select Create Pocket book.
- Present a pocket book identify, for instance
AthenaSparkBlog. - Maintain the default session parameters.
- Select Create.
Your pocket book ought to now be loaded, which suggests you can begin operating Spark code. It’s best to see the next screenshot.

Discover the dataset
Now that we’ve workgroup and pocket book created, let’s begin exploring the NOAA International Floor Abstract of Day dataset. The datasets used on this put up are saved within the following areas:
- CSV information for 12 months 2022 –
s3://noaa-gsod-pds/2022/ - Parquet information for 12 months 2021 –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2021/ - Parquet information for 12 months 2020 –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2020/ - Total dataset in Parquet format (till October 2022) –
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/historic/
In the remainder of this put up, we present PySpark code snippets. Copy the code and enter it within the pocket book’s cell. Press Shift+Enter to run the code as a calculation. Alternatively, you may select Run. Add extra cells to run subsequent code snippets.
We begin by studying the CSV dataset for the 12 months 2022 and print its schema to grasp the columns contained within the dataset. Run the next code within the pocket book cell:

We get the next output.

We have been in a position to submit the previous code as a calculation immediately utilizing the pocket book.
Let’s proceed exploring the dataset. Wanting on the columns within the schema, we’re keen on previewing the information for the next attributes in 2022:
- TEMP – Imply temperature
- WDSP – Imply wind pace
- GUST – Most wind gust
- MAX – Most temperature
- MIN – Minimal temperature
- Title – Station identify
Run the next code:
We get the next output.

Now we’ve an thought of what the dataset seems like. Subsequent, let’s carry out some evaluation to search out the utmost recorded temperature for the Seattle-Tacoma Airport in 2022. Run the next code:
We get the next output.

Subsequent, we need to discover the utmost recorded temperature for every month of 2022. For this, we use the Spark SQL characteristic of Athena. First, we have to create a brief view on the year_22_csv information body. Run the next code:
To run our Spark SQL question, we use %%sql magic:
We get the next output.

The output of the previous question produces the month in numeric kind. To make it extra readable, let’s convert the month numbers into month names. For this, we use a user-defined operate (UDF) and register it to make use of within the Spark SQL queries for the remainder of the pocket book session. Run the next code to create and register the UDF:
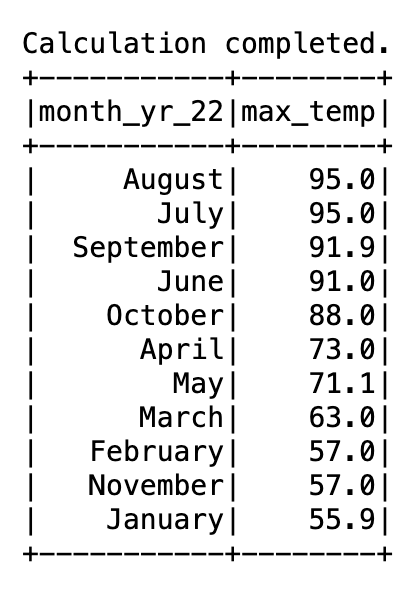
We rerun the question to search out the utmost recorded temperature for every month of 2022 however with the month_name_udf UDF we simply created. Additionally, this time we kind the outcomes primarily based on the utmost temperature worth. See the next code:
The next output exhibits the month names.
Till now, we’ve run interactive explorations for the 12 months 2022 of the NOAA International Floor Abstract of Day dataset. Let’s say we need to examine the temperature values with the earlier 2 years. We examine the utmost temperature throughout 2020, 2021, and 2022. As a reminder, the dataset for 2022 is in CSV format and for 2020 and 2021, the datasets are in Parquet format.
To proceed with the evaluation, we learn the 2020 and 2021 Parquet datasets into the information body and create short-term views on the respective information frames. Run the next code:
We get the next output.

To check the recorded most temperature for every month in 2020, 2021, and 2022, we carry out a be part of operation on the three views created so removed from their respective information frames. Additionally, we reuse the month_name_udf UDF to transform month quantity to month identify. Run the next code:
We get the next output.

To date, we’ve learn CSV and Parquet datasets, run evaluation on the person datasets, and carried out be part of and aggregation operations on them to derive insights immediately in an interactive mode. Subsequent, we present how you should use the pre-installed libraries like Seaborn, Matplotlib, and Pandas for Spark on Athena to generate a visible evaluation. For the complete checklist of preinstalled Python libraries, discuss with Checklist of preinstalled Python libraries.
We plot a visible evaluation to match the recorded most temperature values for every month in 2020, 2021, and 2022. Run the next code, which creates a Spark information body from the SQL question, converts it right into a Pandas information body, and makes use of Seaborn and Matplotlib for plotting:
The next graph exhibits our output.

Subsequent, we plot a heatmap displaying the utmost temperature development for every month throughout all of the years within the dataset. For this, we’ve transformed your complete CSV dataset (till October 2022) into Parquet format and saved it in s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/historic/.
Run the next code to plot the heatmap:
We get the next output.

From the potting, we will see the development has been virtually related throughout the years, the place the temperature rises throughout summer season months and lowers as winter approaches within the Seattle-Tacoma Airport space. You possibly can proceed exploring the datasets additional, operating extra analyses and plotting extra visuals to get the texture of the interactive and instant-on expertise Athena for Apache Spark gives.
Clear up sources
If you’re executed with the demo, be certain that to delete the S3 bucket you created to retailer the workgroup calculations to keep away from storage prices. Additionally, you may delete the workgroup, which deletes the pocket book as properly.
Conclusion
On this put up, we noticed how you should use the interactive and serverless expertise of Athena for Spark because the engine to run calculations immediately. You simply must create a workgroup and pocket book to start out operating the Spark code. We explored datasets saved in numerous codecs in an S3 information lake and ran interactive analyses to derive varied insights. Additionally, we ran visible analyses by plotting charts utilizing the preinstalled libraries. To be taught extra about Spark on Athena, discuss with Utilizing Apache Spark in Amazon Athena.
In regards to the Authors
 Pathik Shah is a Sr. Large Information Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the massive information analytics area since then, serving to clients construct scalable and strong options utilizing AWS analytics companies.
Pathik Shah is a Sr. Large Information Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the massive information analytics area since then, serving to clients construct scalable and strong options utilizing AWS analytics companies.
 Raj Devnath is a Sr. Product Supervisor at AWS engaged on Amazon Athena. He’s obsessed with constructing merchandise clients love and serving to clients extract worth from their information. His background is in delivering options for a number of finish markets, similar to finance, retail, sensible buildings, residence automation, and information communication techniques.
Raj Devnath is a Sr. Product Supervisor at AWS engaged on Amazon Athena. He’s obsessed with constructing merchandise clients love and serving to clients extract worth from their information. His background is in delivering options for a number of finish markets, similar to finance, retail, sensible buildings, residence automation, and information communication techniques.

{kind=link}