

Amazon Redshift is the quickest, most generally used, totally managed, petabyte-scale cloud knowledge warehouse. Tens of 1000’s of consumers use Amazon Redshift to course of exabytes of information each day to energy their analytics workloads. Knowledge engineers, knowledge analysts, and knowledge scientists need to use this knowledge to energy analytics workloads resembling enterprise intelligence (BI), predictive analytics, machine studying (ML), and real-time streaming analytics.
Informatica Clever Knowledge Administration Cloud™ (IDMC) is an AI-powered, metadata-driven, persona-based, cloud-native platform to empower knowledge professionals with a complete and cohesive cloud knowledge administration capabilities to find, catalog, ingest, cleanse, combine, govern, safe, put together, and grasp knowledge. Informatica Knowledge Loader for Amazon Redshift, out there on the AWS Administration Console, is a zero-cost, serverless IDMC service that permits frictionless knowledge loading to Amazon Redshift.
Prospects have to convey knowledge shortly and at scale from numerous knowledge shops, together with on-premises and legacy techniques, third-party functions, and AWS providers resembling Amazon Relational Database Service (Amazon RDS), Amazon DynamoDB, and extra. You additionally want a easy, straightforward, and cloud-native resolution to shortly onboard new knowledge sources or to investigate current knowledge for actionable insights. Now, with Informatica Knowledge Loader for Amazon Redshift, you’ll be able to securely join and cargo knowledge to Amazon Redshift at scale through a easy and guided interface. You’ll be able to entry Informatica Knowledge Loader immediately from the Amazon Redshift console.
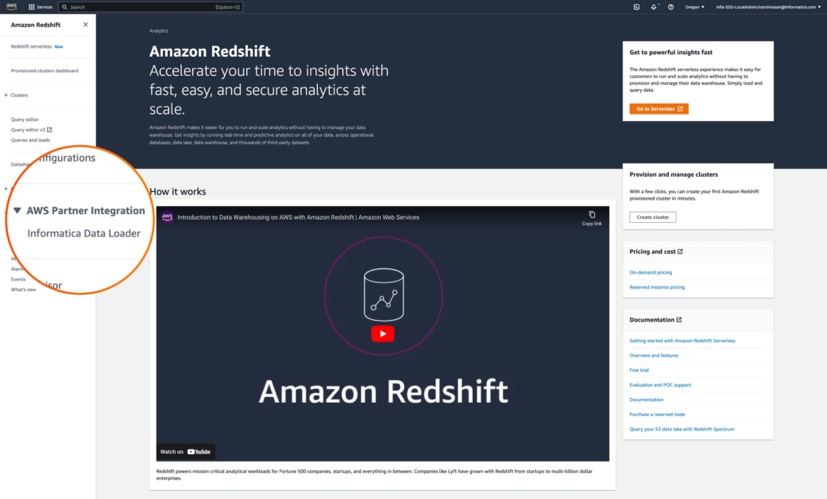
This submit gives step-by-step directions to load knowledge into Amazon Redshift utilizing Informatica Knowledge Loader.
Resolution overview
You’ll be able to entry Informatica Knowledge Loader immediately from the navigation pane on the Amazon Redshift console. The method follows the same workflow that Amazon Redshift customers already use to entry the Amazon Redshift question editor to writer and arrange SQL queries, or create datashares to share stay knowledge in read-only mode throughout clusters.
For this submit, we use a Salesforce developer account as the info supply. For directions in importing a pattern dataset, see Import Pattern Account Knowledge. You should utilize over 30 pre-built connectors supported by Informatica providers to hook up with the info supply of your selection.
We use Informatica Knowledge Loader to pick and cargo a subset of Salesforce objects to Amazon Redshift in three easy steps:
- Connect with the info supply.
- Connect with the goal knowledge supply.
- Schedule or run the info load.

Along with object-level filtering, the service additionally helps full and incremental masses, change knowledge seize (CDC), column-based and row-based filtering, and schema drifts. After the info is loaded, you’ll be able to run question and generate visualizations utilizing Amazon Redshift Question Editor v2.0.
Stipulations
Full the next stipulations:
- Create an Amazon Redshift cluster or workgroup. For extra info, discuss with Making a cluster in a VPC or Amazon Redshift Serverless.
- Be certain that the cluster could be accessed from Informatica Knowledge Loader. For a personal cluster, add an ingress rule to the safety group hooked up to your cluster to permit visitors from Informatica Knowledge Loader. Permit-list the IP tackle for the cluster to be accessed from Informatica Knowledge Loader. For extra details about including guidelines to an Amazon Elastic Compute Cloud (Amazon EC2) safety group, see Authorize inbound visitors in your Linux cases.
- Create an Amazon Easy Storage Service (Amazon S3) bucket in the identical Area because the Amazon Redshift cluster. The Informatica Knowledge Loader will stage the info into this bucket earlier than importing the info to the cluster. Seek advice from Making a bucket for extra particulars. Make a remark of the entry key ID and secret entry key for the consumer with permission to write down to the staging S3 bucket.
- In the event you don’t have a Salesforce account, you’ll be able to join a free developer account.
Now that you’ve got accomplished the stipulations, let’s get began.
Launch Informatica Knowledge Loader from the Amazon Redshift console
To launch Informatica Knowledge Loader, full the next steps:
- On the Amazon Redshift console, below AWS Companion Integration in navigation pane, select Informatica Knowledge Loader.

- Within the pop-up window Create Informatica integration, select Full Informatica integration.
 In the event you’re accessing the free Informatica Knowledge Loader for first time, you’re directed to the Informatica Knowledge Loader for Amazon Redshift to enroll for gratis. You solely want your e mail tackle to enroll.
In the event you’re accessing the free Informatica Knowledge Loader for first time, you’re directed to the Informatica Knowledge Loader for Amazon Redshift to enroll for gratis. You solely want your e mail tackle to enroll. - After you enroll, you’ll be able to register to your Informatica account.

Join to an information supply
To connect with an information supply, full the next steps:
- On the Informatica Knowledge Loader console, select New within the navigation pane.
- Select New Connection.
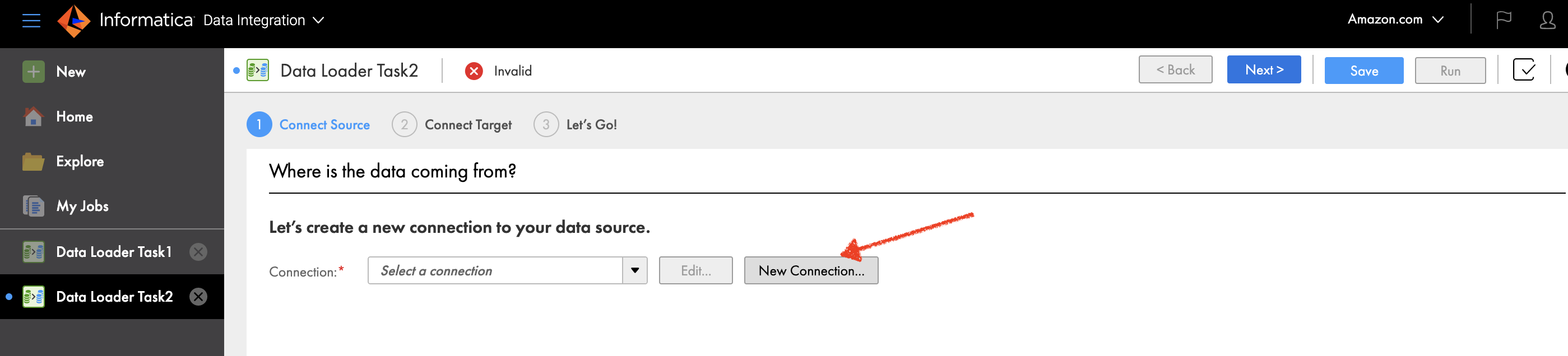
- Select Salesforce as your supply connection.
- Select Proceed.

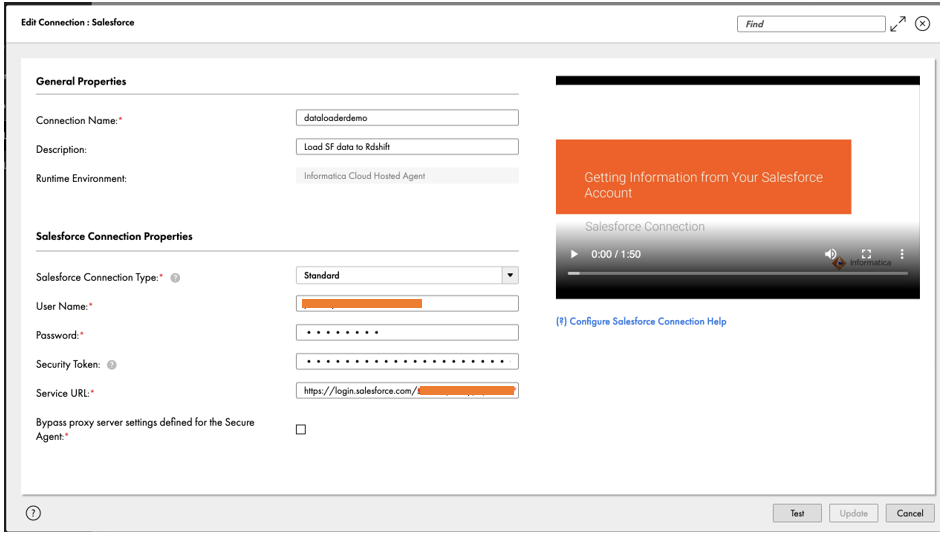
- Beneath Basic Properties, enter a reputation in your connection and an optionally available description.
- Beneath Salesforce Connection Properties¸ enter the credentials in your Salesforce account and safety token.These choices might differ relying on the supply sort, connection sort, and authentication methodology. For steering, you need to use the embedded connection configuration assist video.
- Make a remark of the connection title
Salesforce_Source_Connection. - Select Check to confirm the connection.
- Select Add to avoid wasting your connection particulars, and proceed establishing the info loader.Now that you’ve got related to the Salesforce knowledge supply, you load the pattern account info to Amazon Redshift. For this submit, we load the Account object containing info on buyer sort and billing state or province, amongst different fields.
- Be certain that
Salesforce_Source_Connectionyou simply created is chosen as Connection. - To filter the Account object in Salesforce, choose Embody some below Outline Object.
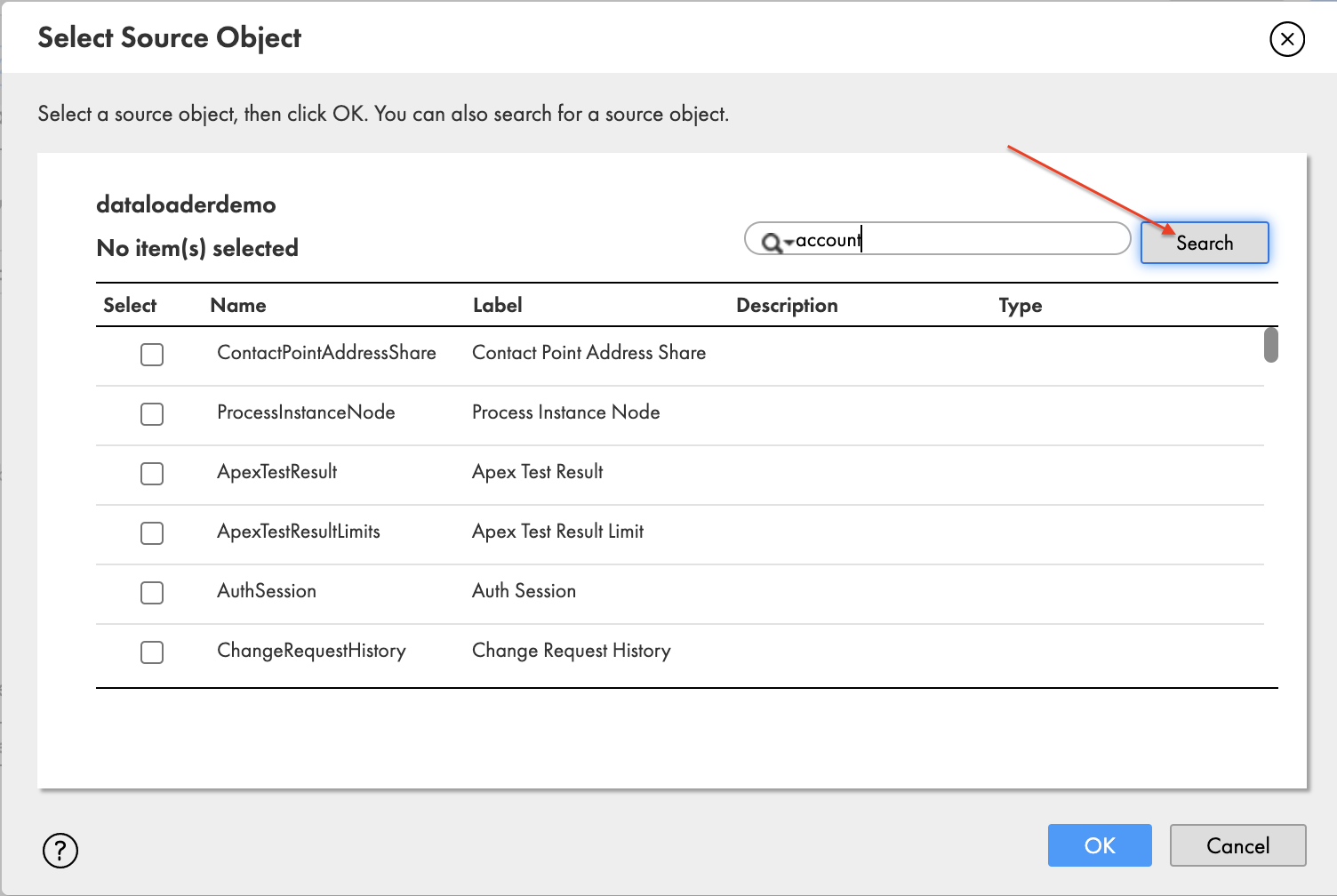
- Select the plus signal to pick the supply object Account.
- Within the pop-up window Choose Supply Object, seek for account and select Search.
- Choose Account and select OK.
- For this submit, the remainder of the next settings are left to their default worth:
- Exclude fields – Exclude supply fields from the supply knowledge.
- Outline Filter – Filter rows from supply knowledge primarily based on a number of specified filters.
- Outline Major Keys – Configuration to specify or detect the first key column within the knowledge supply.
- Outline Watermark Fields – Configuration to specify or detect the watermark column within the knowledge supply.

Connect with the goal knowledge supply
To connect with the goal knowledge supply (Amazon Redshift), full the next steps:
- On the Informatica Knowledge Loader, select Join Goal.
- Select New Connection.
- For Connection, select Redshift (Amazon Redshift v2).
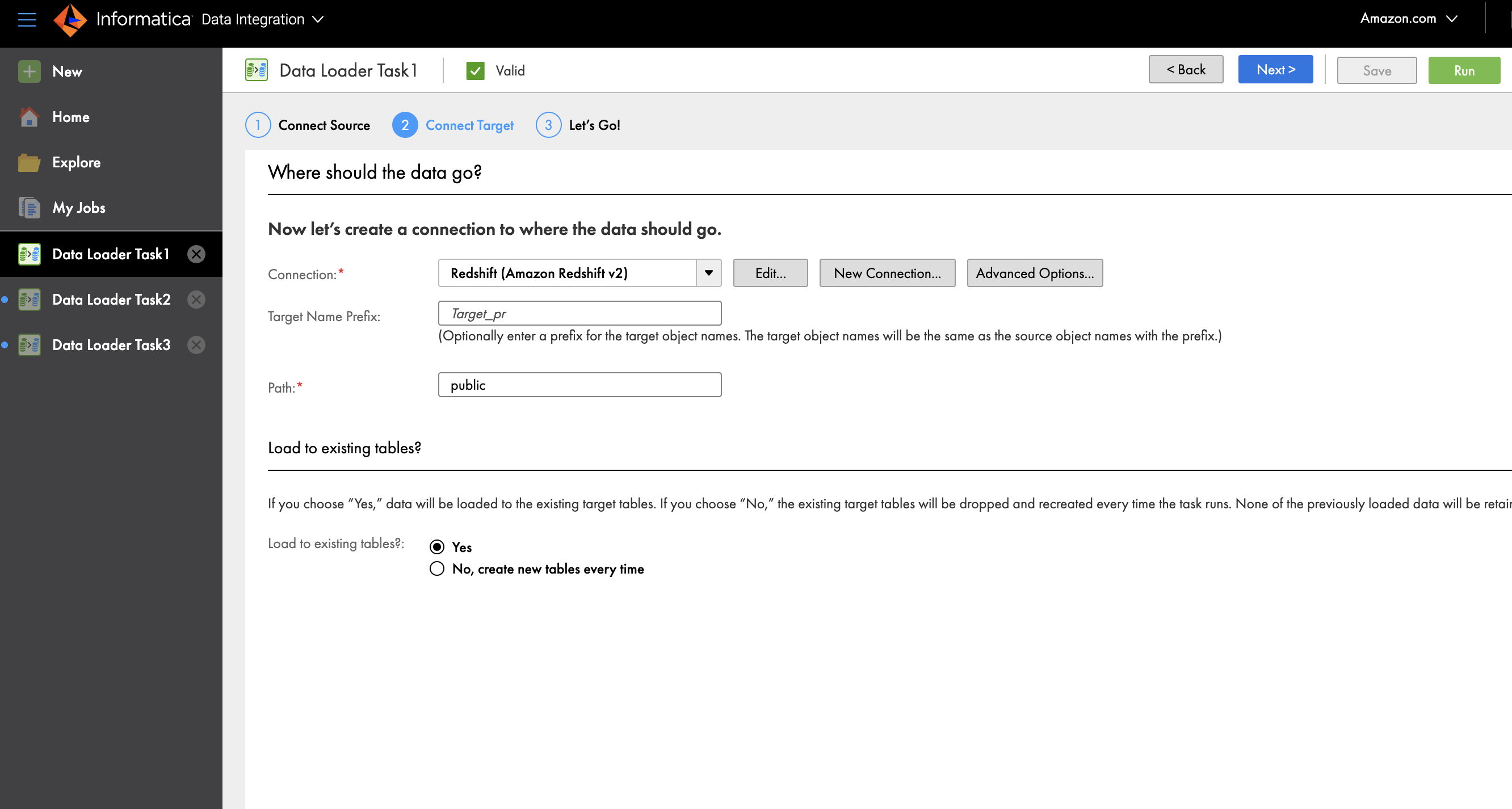
- Present a connection title and optionally available description.
- Beneath Amazon Redshift Connection Part, enter your entry key ID, secret entry key, and the JDBC URL or your provisioned cluster or serverless workgroup.
- Select Check to confirm connectivity.
- After the connection is profitable, select Add.

- Optionally, for Goal Identify Prefix, enter the prefix to which the article title ought to be appended.
- For Path, enter the schema title public in Amazon Redshift the place you need to load the info.
- For Load to present tables, choose No, create new tables each time.

- Select Superior Choices to enter the title of the staging S3 bucket.
- Select OK.
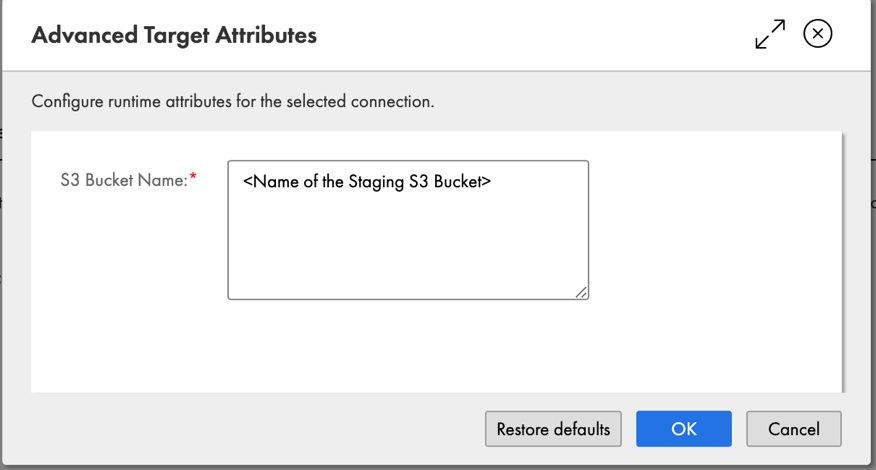
You have got now efficiently related to a goal Amazon Redshift cluster.
Schedule or run an information load
You’ll be able to run your knowledge load by selecting Run or broaden the Schedule part to schedule it.
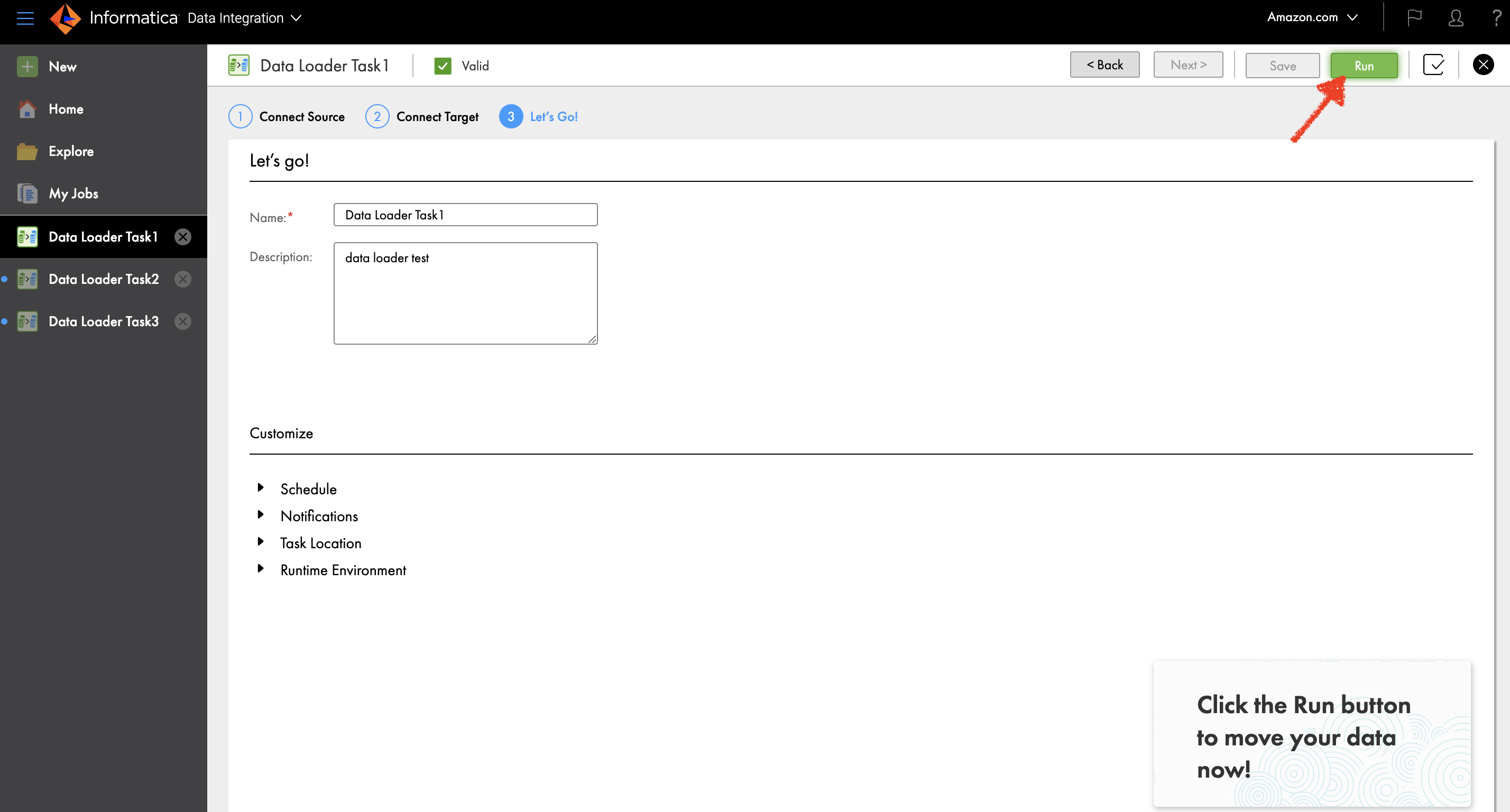
You may as well monitor job standing on the My Jobs web page.

When your job standing adjustments to Success, you’ll be able to return to the Amazon Redshift console and open Question Editor V2.

In Amazon Redshift Question Editor v2.0, you’ll be able to confirm the loaded knowledge by working the next question:
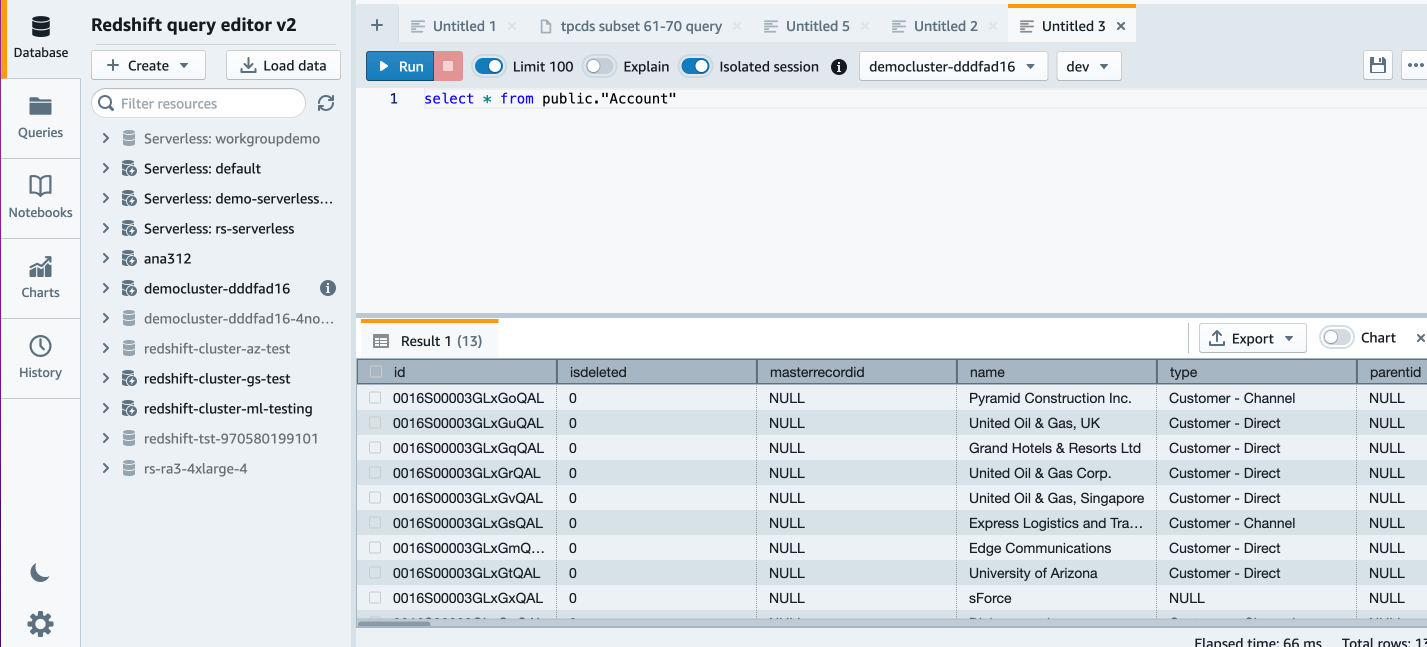
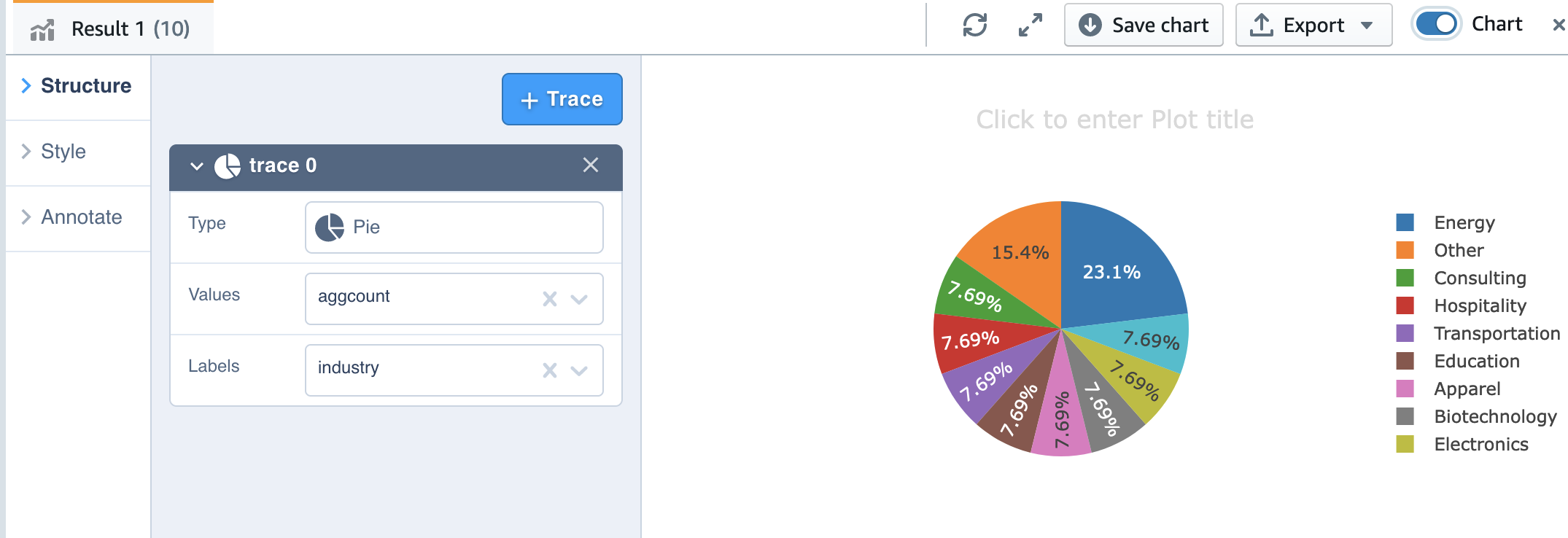
Now we will do some extra evaluation. Let’s have a look at buyer account by business:
Additionally, we will use the charting functionality of Question Editor V2 for visualization.

Merely select the chart sort and the worth and label you need to chart.
Conclusion
The submit demonstrates the built-in Amazon Redshift console expertise of loading knowledge with Informatica Knowledge Loader and querying the info with Amazon Redshift Question Editor. With Informatica Knowledge Loader, Amazon Redshift prospects can shortly onboard new knowledge sources in three easy steps and just-in-time convey knowledge at scale to drive data-driven choices.
You’ll be able to join Informatica Knowledge Loader for Amazon Redshift and begin loading knowledge to Amazon Redshift.
In regards to the authors
 Deepak Rameswarapu is a Director of Product Administration at Informatica. He’s product chief with a strategic deal with new options and product launches, strategic product highway map, AI/ML, cloud knowledge integration, and knowledge engineering and integration management. He brings 20 years of expertise constructing best-of-breed merchandise and options to deal with end-to-end knowledge administration challenges.
Deepak Rameswarapu is a Director of Product Administration at Informatica. He’s product chief with a strategic deal with new options and product launches, strategic product highway map, AI/ML, cloud knowledge integration, and knowledge engineering and integration management. He brings 20 years of expertise constructing best-of-breed merchandise and options to deal with end-to-end knowledge administration challenges.
 Rajeev Srinivasan is a Director of Technical Alliance, Ecosystem at Informatica. He leads the strategic technical partnership with AWS to convey wanted and modern options and capabilities into the arms of the purchasers. Together with buyer obsession, he has a ardour for knowledge and cloud applied sciences, and using his Harley.
Rajeev Srinivasan is a Director of Technical Alliance, Ecosystem at Informatica. He leads the strategic technical partnership with AWS to convey wanted and modern options and capabilities into the arms of the purchasers. Together with buyer obsession, he has a ardour for knowledge and cloud applied sciences, and using his Harley.
 Michael Yitayew is a Product Supervisor for Amazon Redshift primarily based out of New York. He works with prospects and engineering groups to construct new options that allow knowledge engineers and knowledge analysts to extra simply load knowledge, handle knowledge warehouse sources, and question their knowledge. He has supported AWS prospects for over 3 years in each product advertising and product administration roles.
Michael Yitayew is a Product Supervisor for Amazon Redshift primarily based out of New York. He works with prospects and engineering groups to construct new options that allow knowledge engineers and knowledge analysts to extra simply load knowledge, handle knowledge warehouse sources, and question their knowledge. He has supported AWS prospects for over 3 years in each product advertising and product administration roles.
 Phil Bates is a Senior Analytics Specialist Options Architect at AWS. He has greater than 25 years of expertise implementing large-scale knowledge warehouse options. He’s obsessed with serving to prospects by their cloud journey and utilizing the facility of ML inside their knowledge warehouse.
Phil Bates is a Senior Analytics Specialist Options Architect at AWS. He has greater than 25 years of expertise implementing large-scale knowledge warehouse options. He’s obsessed with serving to prospects by their cloud journey and utilizing the facility of ML inside their knowledge warehouse.
 Weifan Liang is a Senior Companion Options Architect at AWS. He works carefully with AWS prime strategic knowledge analytics software program companions to drive product integration, construct optimized structure, develop long-term technique, and supply thought management. Innovating along with companions, Weifan strives to assist prospects speed up enterprise outcomes with cloud-powered digital transformation.
Weifan Liang is a Senior Companion Options Architect at AWS. He works carefully with AWS prime strategic knowledge analytics software program companions to drive product integration, construct optimized structure, develop long-term technique, and supply thought management. Innovating along with companions, Weifan strives to assist prospects speed up enterprise outcomes with cloud-powered digital transformation.

{kind=link}