AWS Controllers for Kubernetes (ACK) was introduced in August, 2020, and now helps 14 AWS service controllers as typically accessible with an extra 12 in preview. The imaginative and prescient behind this initiative was easy: permit Kubernetes customers to make use of the Kubernetes API to handle the lifecycle of AWS assets akin to Amazon Easy Storage Service (Amazon S3) buckets or Amazon Relational Database Service (Amazon RDS) DB cases. For instance, you’ll be able to outline an S3 bucket as a customized useful resource, create this bucket as a part of your utility deployment, and delete it when your utility is retired.
Amazon EMR on EKS is a deployment possibility for EMR that enables organizations to run Apache Spark on Amazon Elastic Kubernetes Service (Amazon EKS) clusters. With EMR on EKS, the Spark jobs run utilizing the Amazon EMR runtime for Apache Spark. This will increase the efficiency of your Spark jobs in order that they run quicker and price lower than open supply Apache Spark. Additionally, you’ll be able to run Amazon EMR-based Apache Spark functions with different kinds of functions on the identical EKS cluster to enhance useful resource utilization and simplify infrastructure administration.
At present, we’re excited to announce the ACK controller for Amazon EMR on EKS is mostly accessible. Prospects have advised us that they just like the declarative manner of managing Apache Spark functions on EKS clusters. With the ACK controller for EMR on EKS, now you can outline and run Amazon EMR jobs instantly utilizing the Kubernetes API. This allows you to handle EMR on EKS assets instantly utilizing Kubernetes-native instruments akin to kubectl.
The controller sample has been broadly adopted by the Kubernetes neighborhood to handle the lifecycle of assets. In reality, Kubernetes has built-in controllers for built-in assets like Jobs or Deployment. These controllers constantly make sure that the noticed state of a useful resource matches the specified state of the useful resource saved in Kubernetes. For instance, should you outline a deployment that has NGINX utilizing three replicas, the deployment controller constantly watches and tries to take care of three replicas of NGINX pods. Utilizing the identical sample, the ACK controller for EMR on EKS installs two customized useful resource definitions (CRDs): VirtualCluster and JobRun. If you create EMR digital clusters, the controller tracks these as Kubernetes customized assets and calls the EMR on EKS service API (also referred to as emr-containers) to create and handle these assets. If you wish to get a deeper understanding of how ACK works with AWS service APIs, and learn the way ACK generates Kubernetes assets like CRDs, see weblog publish.
In case you want a easy getting began tutorial, seek advice from Run Spark jobs utilizing the ACK EMR on EKS controller. Usually, prospects who run Apache Spark jobs on EKS clusters use greater stage abstraction akin to Argo Workflows, Apache Airflow, or AWS Step Capabilities, and use workflow-based orchestration with the intention to run their extract, rework, and cargo (ETL) jobs. This offers you a constant expertise operating jobs whereas defining job pipelines utilizing Directed Acyclic Graphs (DAGs). DAGs permit you set up your job steps with dependencies and relationships to say how they need to run. Argo Workflows is a container-native workflow engine for orchestrating parallel jobs on Kubernetes.
On this publish, we present you the way to use Argo Workflows with the ACK controller for EMR on EKS to run Apache Spark jobs on EKS clusters.
Answer overview
Within the following diagram, we present Argo Workflows submitting a request to the Kubernetes API utilizing its orchestration mechanism.

We’re utilizing Argo to showcase the chances with workflow orchestration on this publish, however you may also submit jobs instantly utilizing kubectl (the Kubernetes command line instrument). When Argo Workflows submits these requests to the Kubernetes API, the ACK controller for EMR on EKS reconciles VirtualCluster customized assets by invoking the EMR on EKS APIs.
Let’s undergo an train of making customized assets utilizing the ACK controller for EMR on EKS and Argo Workflows.
Stipulations
Your surroundings wants the next instruments put in:
Set up the ACK controller for EMR on EKS
You possibly can both create an EKS cluster or re-use an current one. We seek advice from the directions in Run Spark jobs utilizing the ACK EMR on EKS controller to arrange the environment. Full the next steps:
- Set up the EKS cluster.
- Create IAM Id mapping.
- Set up emrcontainers-controller.
- Configure IRSA for the EMR on EKS controller.
- Create an EMR job execution function and configure IRSA.
At this stage, it’s best to have an EKS cluster with correct role-based entry management (RBAC) permissions in order that Amazon EMR can run its jobs. You must also have the ACK controller for EMR on EKS put in and the EMR job execution function with IAM Roles for Service Account (IRSA) configurations in order that they’ve the proper permissions to name EMR APIs.
Please observe, we’re skipping the step to create an EMR digital cluster as a result of we need to create a customized useful resource utilizing Argo Workflows. In case you created this useful resource utilizing the getting began tutorial, you’ll be able to both delete the digital cluster or create new IAM id mapping utilizing a unique namespace.
Let’s validate the annotation for the EMR on EKS controller service account earlier than continuing:
# validate annotation
kubectl get pods -n $ACK_SYSTEM_NAMESPACE
CONTROLLER_POD_NAME=$(kubectl get pods -n $ACK_SYSTEM_NAMESPACE --selector=app.kubernetes.io/identify=emrcontainers-chart -o jsonpath="{.gadgets..metadata.identify}")
kubectl describe pod -n $ACK_SYSTEM_NAMESPACE $CONTROLLER_POD_NAME | grep "^s*AWS_"
The next code exhibits the anticipated outcomes:
AWS_REGION: us-west-2
AWS_ENDPOINT_URL:
AWS_ROLE_ARN: arn:aws:iam::012345678910:function/ack-emrcontainers-controller
AWS_WEB_IDENTITY_TOKEN_FILE: /var/run/secrets and techniques/eks.amazonaws.com/serviceaccount/token (http://eks.amazonaws.com/serviceaccount/token)
Verify the logs of the controller:
kubectl logs ${CONTROLLER_POD_NAME} -n ${ACK_SYSTEM_NAMESPACE}
The next code is the anticipated end result:
2022-11-02T18:52:33.588Z INFO controller.virtualcluster Beginning Controller {"reconciler group": "emrcontainers.companies.k8s.aws", "reconciler variety": "VirtualCluster"}
2022-11-02T18:52:33.588Z INFO controller.virtualcluster Beginning EventSource {"reconciler group": "emrcontainers.companies.k8s.aws", "reconciler variety": "VirtualCluster", "supply": "variety supply: *v1alpha1.VirtualCluster"}
2022-11-02T18:52:33.589Z INFO controller.virtualcluster Beginning Controller {"reconciler group": "emrcontainers.companies.k8s.aws", "reconciler variety": "VirtualCluster"}
2022-11-02T18:52:33.589Z INFO controller.jobrun Beginning EventSource {"reconciler group": "emrcontainers.companies.k8s.aws", "reconciler variety": "JobRun", "supply": "variety supply: *v1alpha1.JobRun"}
2022-11-02T18:52:33.589Z INFO controller.jobrun Beginning Controller {"reconciler group": "emrcontainers.companies.k8s.aws", "reconciler variety": "JobRun"}
...
2022-11-02T18:52:33.689Z INFO controller.jobrun Beginning employees {"reconciler group": "emrcontainers.companies.k8s.aws", "reconciler variety": "JobRun", "employee depend": 1}
2022-11-02T18:52:33.689Z INFO controller.virtualcluster Beginning employees {"reconciler group": "emrcontainers.companies.k8s.aws", "reconciler variety": "VirtualCluster", "employee depend": 1}
Now we’re prepared to put in Argo Workflows and use workflow orchestration to create EMR on EKS digital clusters and submit jobs.
Set up Argo Workflows
The next steps are meant for fast set up with a proof of idea in thoughts. This isn’t meant for a manufacturing set up. We advocate reviewing the Argo documentation, safety tips, and different concerns for a manufacturing set up.
We set up the argo CLI first. We’ve got supplied directions to put in the argo CLI utilizing brew, which is appropriate with the Mac working system. In case you use Linux or one other OS, seek advice from Fast Begin for set up steps.
Let’s create a namespace and set up Argo Workflows in your EMR on EKS cluster:
kubectl create namespace argo
kubectl apply -n argo -f https://github.com/argoproj/argo-workflows/releases/obtain/v3.4.3/set up.yaml
You possibly can entry the Argo UI domestically by port-forwarding the argo-server deployment:
kubectl -n argo port-forward deploy/argo-server 2746:2746
You possibly can entry the net UI at https://localhost:2746. You’ll get a discover that “Your connection will not be non-public” as a result of Argo is utilizing a self-signed certificates. It’s okay to decide on Superior after which Proceed to localhost.
Please observe, you get an Entry Denied error as a result of we haven’t configured permissions but. Let’s arrange RBAC in order that Argo Workflows has permissions to speak with the Kubernetes API. We give admin permissions to argo serviceaccount within the argo and emr-ns namespaces.
Open one other terminal window and run these instructions:
# setup rbac
kubectl create rolebinding default-admin --clusterrole=admin --serviceaccount=argo:default --namespace=argo
kubectl create rolebinding default-admin --clusterrole=admin --serviceaccount=argo:default --namespace=emr-ns
# extract bearer token to login into UI
SECRET=$(kubectl get sa default -n argo -o=jsonpath="{.secrets and techniques[0].identify}")
ARGO_TOKEN="Bearer $(kubectl get secret $SECRET -n argo -o=jsonpath="{.information.token}" | base64 --decode)"
echo $ARGO_TOKEN
You now have a bearer token that we have to enter for consumer authentication.
Now you can navigate to the Workflows tab and alter the namespace to emr-ns to see the workflows below this namespace.
Let’s arrange RBAC permissions and create a workflow that creates an EMR on EKS digital cluster:
cat << EOF > argo-emrcontainers-vc-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
variety: ClusterRole
metadata:
identify: argo-emrcontainers-virtualcluster
guidelines:
- apiGroups:
- emrcontainers.companies.k8s.aws
assets:
- virtualclusters
verbs:
- '*'
EOF
cat << EOF > argo-emrcontainers-jr-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
variety: ClusterRole
metadata:
identify: argo-emrcontainers-jobrun
guidelines:
- apiGroups:
- emrcontainers.companies.k8s.aws
assets:
- jobruns
verbs:
- '*'
EOF
Let’s create these roles and a job binding:
# create argo clusterrole with permissions to emrcontainers.companies.k8s.aws
kubectl apply -f argo-emrcontainers-vc-role.yaml
kubectl apply -f argo-emrcontainers-jr-role.yaml
# Give permissions for argo to make use of emr-containers clusterrole
kubectl create rolebinding argo-emrcontainers-virtualcluster --clusterrole=argo-emrcontainers-virtualcluster --serviceaccount=emr-ns:default -n emr-ns
kubectl create rolebinding argo-emrcontainers-jobrun --clusterrole=argo-emrcontainers-jobrun --serviceaccount=emr-ns:default -n emr-ns
Let’s recap what we’ve achieved up to now. We created an EMR on EKS cluster, put in the ACK controller for EMR on EKS utilizing Helm, put in the Argo CLI, put in Argo Workflows, gained entry to the Argo UI, and arrange RBAC permissions for Argo. RBAC permissions are required in order that the default service account within the Argo namespace can use VirtualCluster and JobRun customized assets through the emrcontainers.companies.k8s.aws API.
It’s time to create the EMR digital cluster. The surroundings variables used within the following code are from the getting began information, however you’ll be able to change these to fulfill your surroundings:
export EKS_CLUSTER_NAME=ack-emr-eks
export EMR_NAMESPACE=emr-ns
cat << EOF > argo-emr-virtualcluster.yaml
apiVersion: argoproj.io/v1alpha1
variety: Workflow
metadata:
identify: emr-virtualcluster
spec:
arguments: {}
entrypoint: emr-virtualcluster
templates:
- identify: emr-virtualcluster
useful resource:
motion: create
manifest: |
apiVersion: emrcontainers.companies.k8s.aws/v1alpha1
variety: VirtualCluster
metadata:
identify: my-ack-vc
spec:
identify: my-ack-vc
containerProvider:
id: ${EKS_CLUSTER_NAME}
type_: EKS
information:
eksInfo:
namespace: ${EMR_NAMESPACE}
EOF
Use the next command to create an Argo Workflow for digital cluster creation:
kubectl apply -f argo-emr-virtualcluster.yaml -n emr-ns
argo checklist -n emr-ns
The next code is the anticipated end result from the Argo CLI:
NAME STATUS AGE DURATION PRIORITY MESSAGE
emr-virtualcluster Succeeded 12m 11s 0
Verify the standing of virtualcluster:
kubectl describe virtualcluster/my-ack-vc -n emr-ns
The next code is the anticipated end result from the previous command:
Title: my-ack-vc
Namespace: default
Labels: <none>
Annotations: <none>
API Model: emrcontainers.companies.k8s.aws/v1alpha1
Type: VirtualCluster
...
Standing:
Ack Useful resource Metadata:
Arn: arn:aws:emr-containers:us-west-2:012345678910:/virtualclusters/dxnqujbxexzri28ph1wspbxo0
Proprietor Account ID: 012345678910
Area: us-west-2
Situations:
Final Transition Time: 2022-11-03T15:34:10Z
Message: Useful resource synced efficiently
Cause:
Standing: True
Kind: ACK.ResourceSynced
Id: dxnqujbxexzri28ph1wspbxo0
Occasions: <none>
In case you run into points, you’ll be able to test Argo logs utilizing the next command or by way of the console:
argo logs emr-virtualcluster -n emr-ns
You can even test controller logs as talked about within the troubleshooting information.
As a result of we’ve an EMR digital cluster prepared to just accept jobs, we will begin engaged on the stipulations for job submission.
Create an S3 bucket and Amazon CloudWatch Logs group which are wanted for the job (see the next code). In case you already created these assets from the getting began tutorial, you’ll be able to skip this step.
export RANDOM_ID1=$(LC_ALL=C tr -dc a-z0-9 </dev/urandom | head -c 8)
aws logs create-log-group --log-group-name=/emr-on-eks-logs/$EKS_CLUSTER_NAME
aws s3 mb s3://$EKS_CLUSTER_NAME-$RANDOM_ID1
We use the New York Citi Bike dataset, which has rider demographics and journey information info. Run the next command to repeat the dataset into your S3 bucket:
export S3BUCKET=$EKS_CLUSTER_NAME-$RANDOM_ID1
aws s3 sync s3://tripdata/ s3://${S3BUCKET}/citibike/csv/
Copy the pattern Spark utility code to your S3 bucket:
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2782/citibike-convert-csv-to-parquet.py s3://${S3BUCKET}/utility/
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2782/citibike-ridership.py s3://${S3BUCKET}/utility/
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2782/citibike-popular-stations.py s3://${S3BUCKET}/utility/
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2782/citibike-trips-by-age.py s3://${S3BUCKET}/utility/
Now, it’s time to run pattern Spark job. Run the next to generate an Argo workflow submission template:
export RANDOM_ID2=$(LC_ALL=C tr -dc a-z0-9 </dev/urandom | head -c 8)
cat << EOF > argo-citibike-steps-jobrun.yaml
apiVersion: argoproj.io/v1alpha1
variety: Workflow
metadata:
identify: emr-citibike-${RANDOM_ID2}
spec:
entrypoint: emr-citibike
templates:
- identify: emr-citibike
steps:
- - identify: emr-citibike-csv-parquet
template: emr-citibike-csv-parquet
- - identify: emr-citibike-ridership
template: emr-citibike-ridership
- identify: emr-citibike-popular-stations
template: emr-citibike-popular-stations
- identify: emr-citibike-trips-by-age
template: emr-citibike-trips-by-age
# That is guardian job that converts csv information to parquet
- identify: emr-citibike-csv-parquet
useful resource:
motion: create
successCondition: standing.state == COMPLETED
failureCondition: standing.state == FAILED
manifest: |
apiVersion: emrcontainers.companies.k8s.aws/v1alpha1
variety: JobRun
metadata:
identify: my-ack-jobrun-csv-parquet-${RANDOM_ID2}
spec:
identify: my-ack-jobrun-csv-parquet-${RANDOM_ID2}
virtualClusterRef:
from:
identify: my-ack-vc
executionRoleARN: "${ACK_JOB_EXECUTION_ROLE_ARN}"
releaseLabel: "emr-6.7.0-latest"
jobDriver:
sparkSubmitJobDriver:
entryPoint: "s3://${S3BUCKET}/utility/citibike-convert-csv-to-parquet.py"
entryPointArguments: [${S3BUCKET}]
sparkSubmitParameters: "--conf spark.executor.cases=2 --conf spark.executor.reminiscence=1G --conf spark.executor.cores=1 --conf spark.driver.cores=1 --conf spark.sql.shuffle.partitions=60 --conf spark.dynamicAllocation.enabled=false"
configurationOverrides: |
ApplicationConfiguration: null
MonitoringConfiguration:
CloudWatchMonitoringConfiguration:
LogGroupName: /emr-on-eks-logs/${EKS_CLUSTER_NAME}
LogStreamNamePrefix: citibike
S3MonitoringConfiguration:
LogUri: s3://${S3BUCKET}/logs
# This can be a baby job which runs after csv-parquet jobs is full
- identify: emr-citibike-ridership
useful resource:
motion: create
manifest: |
apiVersion: emrcontainers.companies.k8s.aws/v1alpha1
variety: JobRun
metadata:
identify: my-ack-jobrun-ridership-${RANDOM_ID2}
spec:
identify: my-ack-jobrun-ridership-${RANDOM_ID2}
virtualClusterRef:
from:
identify: my-ack-vc
executionRoleARN: "${ACK_JOB_EXECUTION_ROLE_ARN}"
releaseLabel: "emr-6.7.0-latest"
jobDriver:
sparkSubmitJobDriver:
entryPoint: "s3://${S3BUCKET}/utility/citibike-ridership.py"
entryPointArguments: [${S3BUCKET}]
sparkSubmitParameters: "--conf spark.executor.cases=2 --conf spark.executor.reminiscence=1G --conf spark.executor.cores=1 --conf spark.driver.cores=1 --conf spark.sql.shuffle.partitions=60 --conf spark.dynamicAllocation.enabled=false"
configurationOverrides: |
ApplicationConfiguration: null
MonitoringConfiguration:
CloudWatchMonitoringConfiguration:
LogGroupName: /emr-on-eks-logs/${EKS_CLUSTER_NAME}
LogStreamNamePrefix: citibike
S3MonitoringConfiguration:
LogUri: s3://${S3BUCKET}/logs
# This can be a baby job which runs after csv-parquet jobs is full
- identify: emr-citibike-popular-stations
useful resource:
motion: create
manifest: |
apiVersion: emrcontainers.companies.k8s.aws/v1alpha1
variety: JobRun
metadata:
identify: my-ack-jobrun-popular-stations-${RANDOM_ID2}
spec:
identify: my-ack-jobrun-popular-stations-${RANDOM_ID2}
virtualClusterRef:
from:
identify: my-ack-vc
executionRoleARN: "${ACK_JOB_EXECUTION_ROLE_ARN}"
releaseLabel: "emr-6.7.0-latest"
jobDriver:
sparkSubmitJobDriver:
entryPoint: "s3://${S3BUCKET}/utility/citibike-popular-stations.py"
entryPointArguments: [${S3BUCKET}]
sparkSubmitParameters: "--conf spark.executor.cases=2 --conf spark.executor.reminiscence=1G --conf spark.executor.cores=1 --conf spark.driver.cores=1 --conf spark.sql.shuffle.partitions=60 --conf spark.dynamicAllocation.enabled=false"
configurationOverrides: |
ApplicationConfiguration: null
MonitoringConfiguration:
CloudWatchMonitoringConfiguration:
LogGroupName: /emr-on-eks-logs/${EKS_CLUSTER_NAME}
LogStreamNamePrefix: citibike
S3MonitoringConfiguration:
LogUri: s3://${S3BUCKET}/logs
# This can be a baby job which runs after csv-parquet jobs is full
- identify: emr-citibike-trips-by-age
useful resource:
motion: create
manifest: |
apiVersion: emrcontainers.companies.k8s.aws/v1alpha1
variety: JobRun
metadata:
identify: my-ack-jobrun-trips-by-age-${RANDOM_ID2}
spec:
identify: my-ack-jobrun-trips-by-age-${RANDOM_ID2}
virtualClusterRef:
from:
identify: my-ack-vc
executionRoleARN: "${ACK_JOB_EXECUTION_ROLE_ARN}"
releaseLabel: "emr-6.7.0-latest"
jobDriver:
sparkSubmitJobDriver:
entryPoint: "s3://${S3BUCKET}/utility/citibike-trips-by-age.py"
entryPointArguments: [${S3BUCKET}]
sparkSubmitParameters: "--conf spark.executor.cases=2 --conf spark.executor.reminiscence=1G --conf spark.executor.cores=1 --conf spark.driver.cores=1 --conf spark.sql.shuffle.partitions=60 --conf spark.dynamicAllocation.enabled=false"
configurationOverrides: |
ApplicationConfiguration: null
MonitoringConfiguration:
CloudWatchMonitoringConfiguration:
LogGroupName: /emr-on-eks-logs/${EKS_CLUSTER_NAME}
LogStreamNamePrefix: citibike
S3MonitoringConfiguration:
LogUri: s3://${S3BUCKET}/logs
EOF
Let’s run this job:
argo -n emr-ns submit --watch argo-citibike-steps-jobrun.yaml
The next code is the anticipated end result:
Title: emr-citibike-tp8dlo6c
Namespace: emr-ns
ServiceAccount: unset (will run with the default ServiceAccount)
Standing: Succeeded
Situations:
PodRunning False
Accomplished True
Created: Mon Nov 07 15:29:34 -0500 (20 seconds in the past)
Began: Mon Nov 07 15:29:34 -0500 (20 seconds in the past)
Completed: Mon Nov 07 15:29:54 -0500 (now)
Length: 20 seconds
Progress: 4/4
ResourcesDuration: 4s*(1 cpu),4s*(100Mi reminiscence)
STEP TEMPLATE PODNAME DURATION MESSAGE
✔ emr-citibike-if32fvjd emr-citibike
├───✔ emr-citibike-csv-parquet emr-citibike-csv-parquet emr-citibike-if32fvjd-emr-citibike-csv-parquet-140307921 2m
└─┬─✔ emr-citibike-popular-stations emr-citibike-popular-stations emr-citibike-if32fvjd-emr-citibike-popular-stations-1670101609 4s
├─✔ emr-citibike-ridership emr-citibike-ridership emr-citibike-if32fvjd-emr-citibike-ridership-2463339702 4s
└─✔ emr-citibike-trips-by-age emr-citibike-trips-by-age emr-citibike-if32fvjd-emr-citibike-trips-by-age-3778285872 4s
You possibly can open one other terminal and run the next command to test on the job standing as effectively:
kubectl -n emr-ns get jobruns -w
You can even test the UI and have a look at the Argo logs, as proven within the following screenshot.
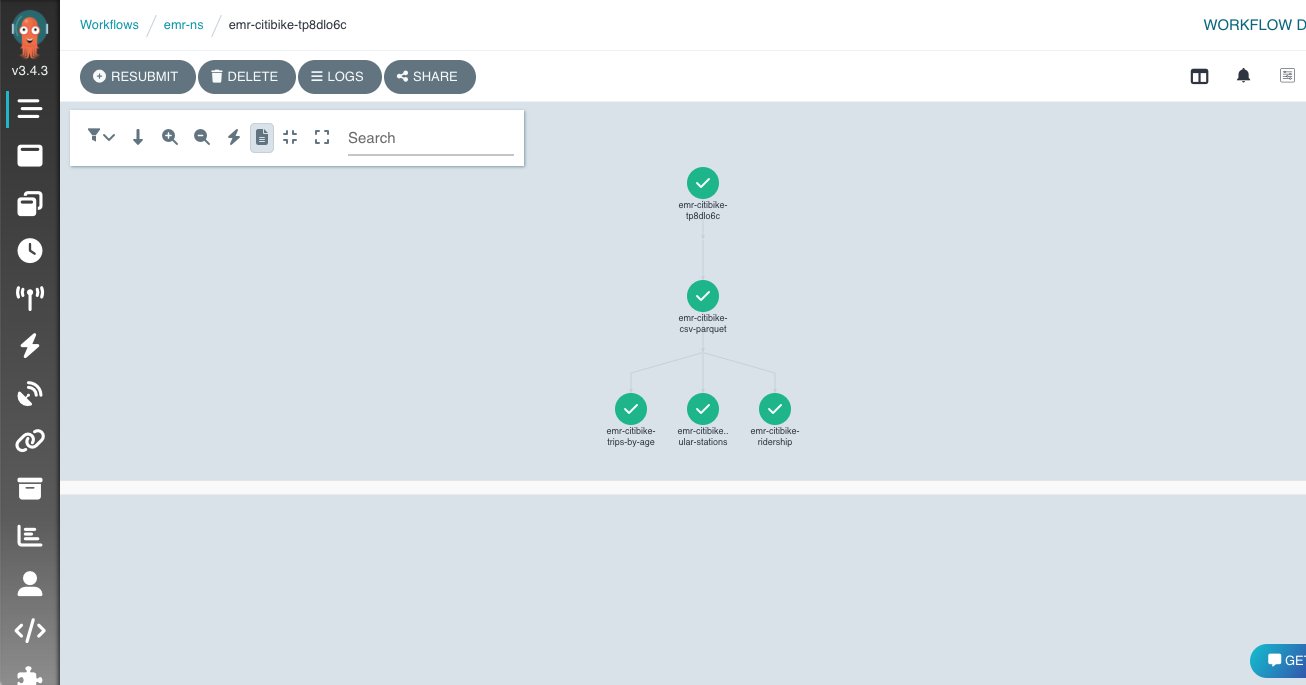
Clear up
Observe the directions from the getting began tutorial to wash up the ACK controller for EMR on EKS and its assets. To delete Argo assets, use the next code:
kubectl delete -n argo -f https://github.com/argoproj/argo-workflows/releases/obtain/v3.4.3/set up.yaml
kubectl delete -f argo-emrcontainers-vc-role.yaml
kubectl delete -f argo-emrcontainers-jr-role.yaml
kubectl delete rolebinding argo-emrcontainers-virtualcluster -n emr-ns
kubectl delete rolebinding argo-emrcontainers-jobrun -n emr-ns
kubectl delete ns argo
Conclusion
On this publish, we went by way of the way to handle your Spark jobs on EKS clusters utilizing the ACK controller for EMR on EKS. You possibly can outline Spark jobs in a declarative trend and handle these assets utilizing Kubernetes customized assets. We additionally reviewed the way to use Argo Workflows to orchestrate these jobs to get a constant job submission expertise. You possibly can make the most of the wealthy options from Argo Workflows akin to utilizing DAGs to outline multi-step workflows and specify dependencies inside job steps, utilizing the UI to visualise and handle the roles, and defining retries and timeouts on the workflow or activity stage.
You may get began at present by putting in the ACK controller for EMR on EKS and begin managing your Amazon EMR assets utilizing Kubernetes-native strategies.
Concerning the authors
 Peter Dalbhanjan is a Options Architect for AWS based mostly in Herndon, VA. Peter is obsessed with evangelizing and fixing advanced enterprise issues utilizing mixture of AWS companies and open supply options. At AWS, Peter helps with designing and architecting number of buyer workloads.
Peter Dalbhanjan is a Options Architect for AWS based mostly in Herndon, VA. Peter is obsessed with evangelizing and fixing advanced enterprise issues utilizing mixture of AWS companies and open supply options. At AWS, Peter helps with designing and architecting number of buyer workloads.
 Amine Hilaly is a Software program Growth Engineer at Amazon Internet Providers engaged on the Kubernetes and Open supply associated tasks for about two years. Amine is a Go, open-source, and Kubernetes fanatic.
Amine Hilaly is a Software program Growth Engineer at Amazon Internet Providers engaged on the Kubernetes and Open supply associated tasks for about two years. Amine is a Go, open-source, and Kubernetes fanatic.



{kind=link}