

GenAI is in all places you look, and organizations throughout industries are placing stress on their groups to hitch the race – 77% of enterprise leaders concern they’re already lacking out on the advantages of GenAI.
Knowledge groups are scrambling to reply the decision. However constructing a generative AI mannequin that truly drives enterprise worth is exhausting.
And in the long term, a fast integration with the OpenAI API will not lower it. It is GenAI, however the place’s the moat? Why ought to customers decide you over ChatGPT?
That fast test of the field looks like a step ahead, however for those who aren’t already serious about find out how to join LLMs along with your proprietary information and enterprise context to truly drive differentiated worth, you are behind.
That is not hyperbole. I’ve talked with half a dozen information leaders simply this week on this subject alone. It wasn’t misplaced on any of them that this can be a race. On the end line there are going to be winners and losers. The Blockbusters and the Netflixes.
In the event you really feel just like the starter’s gun has gone off, however your crew remains to be on the beginning line stretching and chatting about “bubbles” and “hype,” I’ve rounded up 5 exhausting truths to assist shake off the complacency.
Onerous fact #1: Your generative AI options should not nicely adopted and sluggish to monetize.
“Barr, if GenAI is so necessary, why are the present options we have applied so poorly adopted?”
Properly, there are a number of causes. One, your AI initiative wasn’t constructed as a response to an inflow of well-defined person issues. For many information groups, that is since you’re racing and it is early and also you need to acquire some expertise. Nevertheless, it will not be lengthy earlier than your customers have an issue that is finest solved by GenAI, and when that occurs – you’ll have a lot better adoption in comparison with your tiger crew brainstorming methods to tie GenAI to a use case.
And since it is early, the generative AI options which were built-in are simply “ChatGPT however over right here.”
Let me provide you with an instance. Take into consideration a productiveness software you would possibly use on a regular basis to share organizational information. An app like this would possibly provide a characteristic to execute instructions like “Summarize this,” “Make longer” or “Change tone” on blocks of unstructured textual content. One command equals one AI credit score.
Sure, that is useful, nevertheless it’s not differentiated.
Possibly the crew decides to purchase some AI credit, or possibly they simply merely click on over on the different tab and ask ChatGPT. I do not need to fully overlook or low cost the good thing about not exposing proprietary information to ChatGPT, nevertheless it’s additionally a smaller answer and imaginative and prescient than what’s being painted on earnings calls throughout the nation.
That pesky center step from idea to worth. Picture courtesy of Joe Reis on Substack.
So take into account: What’s your GenAI differentiator and worth add? Let me provide you with a touch: high-quality proprietary information.
That is why a RAG mannequin (or typically, a positive tuned mannequin) is so necessary for Gen AI initiatives. It offers the LLM entry to that enterprise proprietary information. (I am going to clarify why under.)
Onerous fact #2: You are scared to do extra with Gen AI.
It is true: generative AI is intimidating.
Certain, you could possibly combine your AI mannequin extra deeply into your group’s processes, however that feels dangerous. Let’s face it: ChatGPT hallucinates and it may’t be predicted. There is a information cutoff that leaves customers prone to out-of-date output. There are authorized repercussions to information mishandlings and offering customers misinformation, even when unintended.
Sounds actual sufficient, proper? Llama 2 positive thinks so. Picture courtesy of Pinecone.
Your information mishaps have penalties. And that is why it is important to know precisely what you might be feeding GenAI and that the information is correct.
In an nameless survey we despatched to information leaders asking how distant their crew is from enabling a Gen AI use case, one response was, “I do not suppose our infrastructure is the factor holding us again. We’re treading fairly cautiously right here – with the panorama transferring so quick, and the danger of reputational harm from a ‘rogue’ chatbot, we’re holding fireplace and ready for the hype to die down a bit!”
It is a broadly shared sentiment throughout many information leaders I converse to. If the information crew has abruptly surfaced customer-facing, safe information, then they’re on the hook. Knowledge governance is an enormous consideration and it is a excessive bar to clear.
These are actual dangers that want options, however you will not remedy them by sitting on the sideline. There’s additionally an actual danger of watching your online business being essentially disrupted by the crew that figured it out first.
Grounding LLMs in your proprietary information with positive tuning and RAG is an enormous piece to this puzzle, nevertheless it’s not simple…
Onerous fact #3: RAG is difficult.
I imagine that RAG (retrieval augmented technology) and positive tuning are the centerpieces of the way forward for enterprise generative AI. However though RAG is the less complicated strategy usually, creating RAG apps can nonetheless be complicated.
Cannot all of us simply begin RAGing? What is the large deal? Picture courtesy of Reddit.
RAG would possibly seem to be the plain answer for customizing your LLM. However RAG improvement comes with a studying curve, even in your most proficient information engineers. They should know immediate engineering, vector databases and embedding vectors, information modeling, information orchestration, information pipelines and all for RAG. And, as a result of it is new (launched by Meta AI in 2020), many firms simply do not but have sufficient expertise with it to ascertain finest practices.
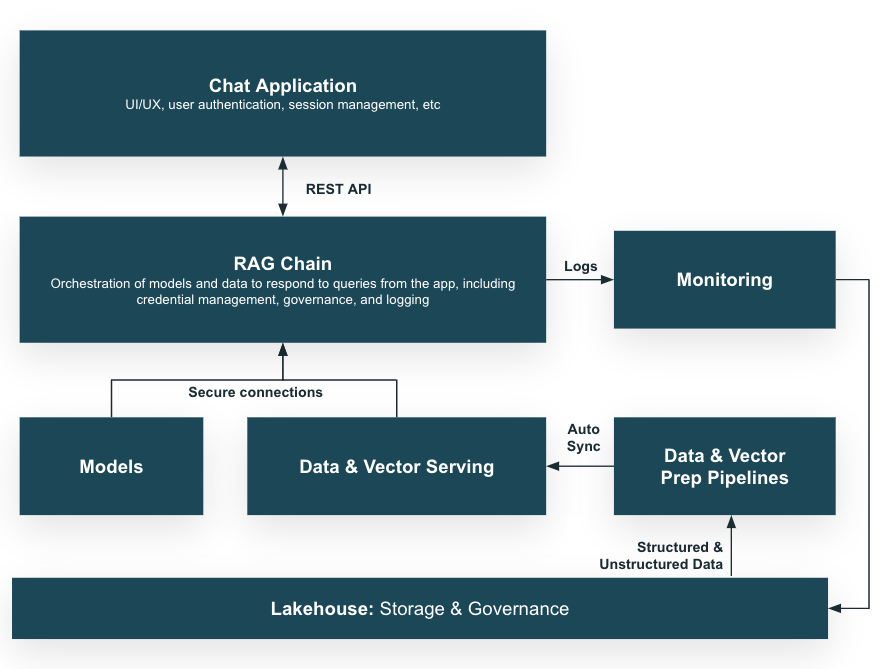
RAG software structure. Picture courtesy of Databricks.
This is an oversimplification of RAG software structure:
- RAG structure combines data retrieval with a textual content generator mannequin, so it has entry to your database whereas attempting to reply a query from the person.
- The database needs to be a trusted supply that features proprietary information, and it permits the mannequin to include up-to-date and dependable data into its responses and reasoning.
- Within the background, a information pipeline ingests numerous structured and unstructured sources into the database to maintain it correct and up-to-date.
- The RAG chain takes the person question (textual content) and retrieves related information from the database, then passes that information and the question to the LLM as a way to generate a extremely correct and personalised response.
There are plenty of complexities on this structure, nevertheless it does have necessary advantages:
- It grounds your LLM in correct proprietary information, thus making it a lot extra beneficial.
- It brings your fashions to your information somewhat than bringing your information to your fashions, which is a comparatively easy, cost-effective strategy.
We will see this turning into a actuality within the Trendy Knowledge Stack. The most important gamers are working at a breakneck velocity to make RAG simpler by serving LLMs inside their environments, the place enterprise information is saved. Snowflake Cortex now allows organizations to shortly analyze information and construct AI apps straight in Snowflake. Databricks’ new Basis Mannequin APIs present on the spot entry to LLMs straight inside Databricks. Microsoft launched Microsoft Azure OpenAI Service and Amazon just lately launched the Amazon Redshift Question Editor.
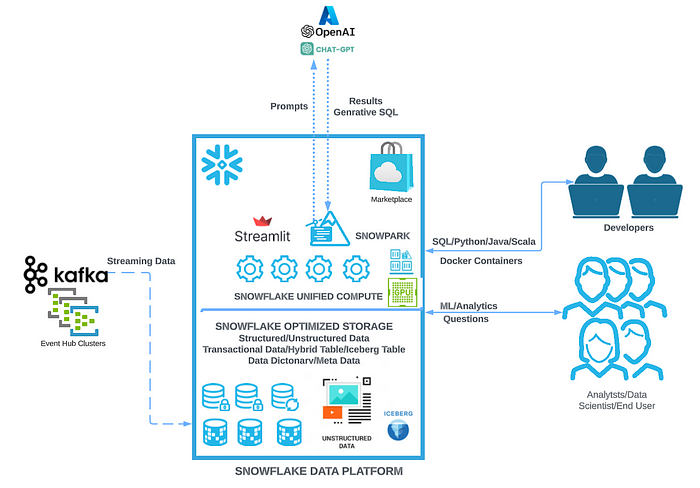
Snowflake information cloud. Picture courtesy of Medium.
I imagine all of those options have probability of driving excessive adoption. However, additionally they heighten the deal with information high quality in these information shops. If the information feeding your RAG pipeline is anomalous, outdated, or in any other case untrustworthy information, what’s the way forward for your generative AI initiative?
Onerous fact #4: Your information is not prepared but anyway.
Take , exhausting have a look at your information infrastructure. Chances are high for those who had an ideal RAG pipeline, positive tuned mannequin, and clear use case able to go tomorrow (and would not that be good?), you continue to would not have clear, well-modeled datasets to plug all of it into.
As an instance you need your chatbot to interface with a buyer. To do something helpful, it must find out about that group’s relationship with the client. In the event you’re an enterprise group right this moment, that relationship is probably going outlined throughout 150 information sources and 5 siloed databases…3 of that are nonetheless on-prem.
If that describes your group, it is potential you’re a yr (or two!) away out of your information infrastructure being GenAI prepared.
Which suggests if you need the choice to do one thing with GenAI sometime quickly, it’s essential to be creating helpful, extremely dependable, consolidated, well-documented datasets in a contemporary information platform… yesterday. Or the coach goes to name you into the sport and your pants are going to be down.
Your information engineering crew is the spine for making certain information well being. And, a trendy information stack allows the information engineering crew to repeatedly monitor information high quality into the longer term.
It is 2024 now. Launching an internet site, software, or any information product with out information observability is a danger. Your information is a product, and it requires information observability and information governance to pinpoint information discrepancies earlier than they transfer via a RAG pipeline.
Onerous fact #5: You’ve got sidelined important Gen AI gamers with out figuring out it.
Generative AI is a crew sport, particularly in terms of improvement. Many information groups make the error of excluding key gamers from their Gen AI tiger groups, and that is costing them in the long term.
Who ought to be on an AI tiger crew? Management, or a major enterprise stakeholder, to spearhead the initiative and remind the group of the enterprise worth. Software program engineers to develop the code, the person dealing with software and the API calls. Knowledge scientists to contemplate new use circumstances, positive tune your fashions, and push the crew in new instructions. Who’s lacking right here?
Knowledge engineers.
Knowledge engineers are important to Gen AI initiatives. They are going to have the ability to perceive the proprietary enterprise information that gives the aggressive benefit over a ChatGPT, and they will construct the pipelines that make that information obtainable to the LLM by way of RAG.
In case your information engineers aren’t within the room, your tiger crew just isn’t at full power. Probably the most pioneering firms in GenAI are telling me they’re already embedding information engineers in all improvement squads.
Profitable the GenAI race
If any of those exhausting truths apply to you, don’t fret. Generative AI is in such nascent levels that there is nonetheless time to begin again over, and this time, embrace the problem.
Take a step again to know the client wants an AI mannequin can remedy, convey information engineers into earlier improvement levels to safe a aggressive edge from the beginning, and take the time to construct a RAG pipeline that may provide a gentle stream of high-quality, dependable information.
And, put money into a contemporary information stack. Instruments like information observability might be a core element of information high quality finest practices – and generative AI with out high-quality information is only a entire lotta’ fluff.
The put up 5 Onerous Truths About Generative AI for Know-how Leaders appeared first on Datafloq.

{kind=link}