

For knowledge groups, unhealthy knowledge, damaged knowledge pipelines, stale dashboards, and 5 a.m. hearth drills are par for the course, notably as knowledge workflows ingest increasingly knowledge from disparate sources. Drawing inspiration from software program growth, we name this phenomenon knowledge downtime– however how can knowledge groups proactively forestall unhealthy knowledge from putting within the first place?
On this article, I share three key methods a few of the greatest knowledge organizations within the business are leveraging to revive belief of their knowledge.
The rise of knowledge downtime
Not too long ago, a buyer posed this query: “How do you forestall knowledge downtime?”
As an information chief for a world logistics firm, his crew was accountable for serving terabytes of knowledge to a whole bunch of stakeholders per day. Given the dimensions and pace at which they had been transferring, poor knowledge high quality was an all-too-common incidence. We name this knowledge downtime-periods of time when knowledge is absolutely or partially lacking, misguided, or in any other case inaccurate.
Again and again, somebody in advertising (or operations or gross sales or another enterprise operate that makes use of knowledge) seen the metrics of their Tableau dashboard appeared off, reached out to alert him, after which his crew stopped no matter they had been doing to troubleshoot what occurred to their knowledge pipeline. Within the course of, his stakeholder misplaced belief within the knowledge, and priceless time and assets had been diverted from truly constructing knowledge pipelines to firefight this incident.
Maybe you’ll be able to relate?
The thought of stopping unhealthy knowledge and knowledge downtime is commonplace apply throughout many industries that depend on functioning techniques to run their enterprise, from preventative upkeep in manufacturing to error monitoring in software program engineering (queue the dreaded 404 web page…).
But, lots of the similar corporations that tout their data-driven credentials aren’t investing in knowledge pipeline monitoring to detect unhealthy knowledge earlier than it strikes downstream. As an alternative of being proactive about knowledge downtime, they’re reactive, enjoying whack-a-mole with unhealthy knowledge as an alternative of specializing in stopping it within the first place.
Happily, there’s hope. Among the most forward-thinking knowledge groups have developed greatest practices for stopping knowledge downtime and stopping damaged pipelines and inaccurate dashboards of their tracks, earlier than your CEO has an opportunity to ask the dreaded query: “what occurred right here?!”
Beneath, I share 5 key methods you’ll be able to take to stopping unhealthy knowledge from corrupting your in any other case good pipelines:
Guarantee your knowledge pipeline monitoring covers unknown unknowns
Knowledge testing-whether hardcoded, dbt assessments, or different kinds of unit tests-has been the first mechanism to enhance knowledge high quality for a lot of knowledge groups.
The issue is that you simply cannot write a check anticipating each single means knowledge can break, and even should you may, that may’t scale throughout each pipeline your knowledge crew helps. I’ve seen groups with greater than 100 assessments on a single knowledge pipeline throw their fingers up in frustration as unhealthy knowledge nonetheless finds a means in.
Monitor broadly throughout your manufacturing tables and end-to-end throughout your knowledge stack
Knowledge pipeline monitoring should be powered by machine studying metamonitors that may perceive the best way your knowledge pipelines sometimes behave, after which ship alerts when anomalies within the knowledge freshness, quantity (row depend), or schema happen. This could occur mechanically and broadly throughout all your tables the minute they’re created.
It must also be paired with machine studying displays that may perceive when anomalies happen within the knowledge itself-things like NULL charges, % uniques, or worth distribution.
Complement your knowledge pipeline monitoring with knowledge testing
 For many knowledge groups, testing is the primary line of protection towards unhealthy knowledge. Courtesy of Arnold Francisca on Unsplash.
For many knowledge groups, testing is the primary line of protection towards unhealthy knowledge. Courtesy of Arnold Francisca on Unsplash.
Knowledge testing is desk stakes (no pun intendend).
In the identical means that software program engineers unit check their code, knowledge groups ought to validate their knowledge throughout each stage of the pipeline by end-to-end testing. At its core, knowledge testing helps you measure whether or not your knowledge and code are performing as you assume it ought to.
Schema assessments and custom-fixed knowledge assessments are each frequent strategies, and will help verify your knowledge pipelines are working accurately in anticipated situations. These assessments search for warning indicators like null values and referential integrity, and lets you set handbook thresholds and determine outliers which will point out an issue. When utilized programmatically throughout each stage of your pipeline, knowledge testing will help you detect and determine points earlier than they change into knowledge disasters.
Knowledge testing dietary supplements knowledge pipeline monitoring in two key methods. The primary is by setting extra granular thresholds or knowledge SLAs. If knowledge is loaded into your knowledge warehouse a couple of minutes late which may not be anomalous, however it might be essential to the chief who accesses their dashboard at 8:00 am on daily basis.
The second is by stopping unhealthy knowledge in its tracks earlier than it ever enters the information warehouse within the first place. This may be accomplished by knowledge circuit breakers utilizing the Airflow ShortCircuitOperator, however caveat emptor, with nice energy comes nice accountability. You wish to reserve this functionality for essentially the most effectively outlined assessments on essentially the most excessive worth operations, in any other case it might add reasonably than take away your knowledge downtime.
Perceive knowledge lineage and downstream impacts
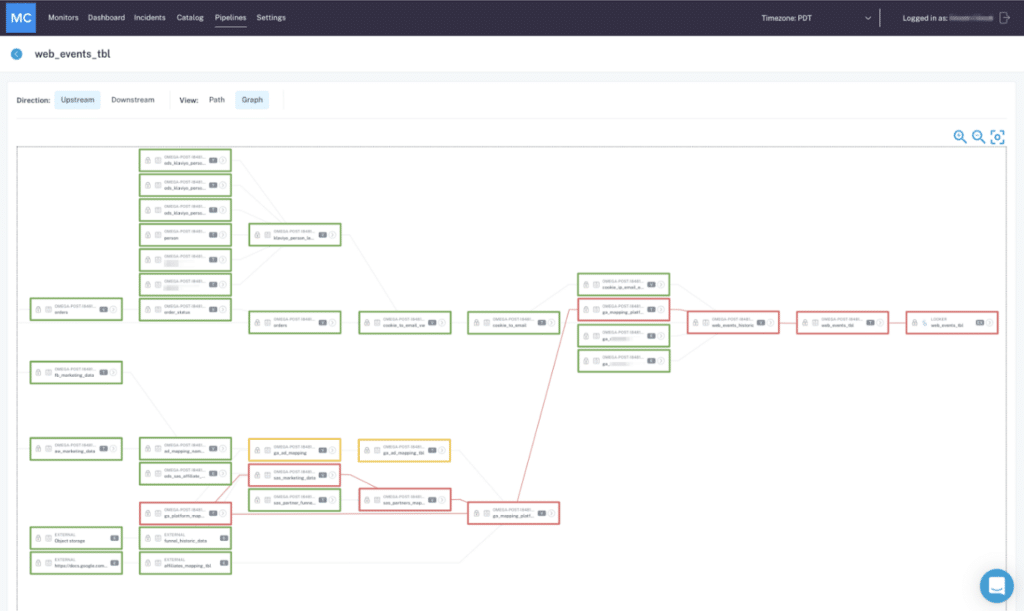
 Area and table-level lineage will help knowledge engineers and analysts perceive which groups are utilizing knowledge belongings affected by knowledge incidents upstream. Picture courtesy of Barr Moses.
Area and table-level lineage will help knowledge engineers and analysts perceive which groups are utilizing knowledge belongings affected by knowledge incidents upstream. Picture courtesy of Barr Moses.
Usually, unhealthy knowledge is the unintended consequence of an harmless change, far upstream from an finish shopper counting on an information asset that no member of the information crew was even conscious of. It is a direct results of having your knowledge pipeline monitoring resolution separated from knowledge lineage – I’ve known as it the “You are Utilizing THAT Desk?!” drawback.
Knowledge lineage, merely put, is the end-to-end mapping of upstream and downstream dependencies of your knowledge, from ingestion to analytics. Knowledge lineage empowers knowledge groups to know each dependency, together with which stories and dashboards depend on which knowledge sources, and what particular transformations and modeling happen at each stage.
When knowledge lineage is integrated into your knowledge pipeline monitoring technique, particularly on the discipline and desk stage, all potential impacts of any modifications will be forecasted and communicated to customers at each stage of the information lifecycle to offset any surprising impacts.
Whereas downstream lineage and its related enterprise use circumstances are necessary, do not neglect understanding which knowledge scientists or engineers are accessing knowledge on the warehouse and lake ranges, too. Pushing a change with out their data may disrupt time-intensive modeling initiatives or infrastructure growth.
Make metadata a precedence, and deal with it like one
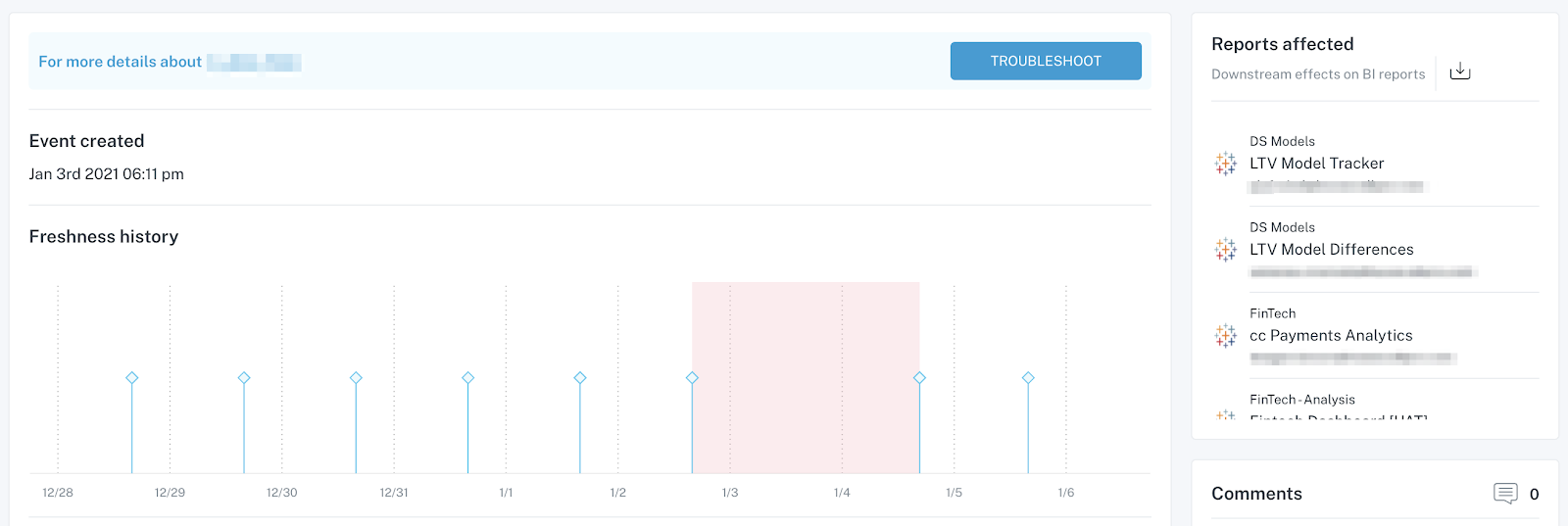
 When utilized to a selected knowledge pipeline monitoring use case, metadata generally is a highly effective software for knowledge incident decision. Picture courtesy of Barr Moses.
When utilized to a selected knowledge pipeline monitoring use case, metadata generally is a highly effective software for knowledge incident decision. Picture courtesy of Barr Moses.
Lineage and metadata go hand-in-hand on the subject of knowledge pipeline monitoring and stopping knowledge downtime. Tagging knowledge as a part of your lineage apply lets you specify how the information is getting used and by whom, decreasing the chance of misapplied or damaged knowledge.
Till all too lately, nonetheless, metadata was handled like these empty Amazon containers you SWEAR you are going to use someday – hoarded and shortly forgotten.
As corporations put money into extra knowledge options like knowledge observability, increasingly organizations are realizing that metadata serves as a seamless connection level all through your more and more advanced tech stack, making certain your knowledge is dependable and up-to-date throughout each resolution and stage of the pipeline. Metadata is particularly essential to not simply understanding which customers are affected by knowledge downtime, but in addition informing how knowledge belongings are linked so knowledge engineers can extra collaboratively and rapidly resolve incidents ought to they happen.
When metadata is utilized based on enterprise functions, you unlock a robust understanding of how your knowledge drives insights and choice making for the remainder of your organization.
The way forward for unhealthy knowledge and knowledge downtime
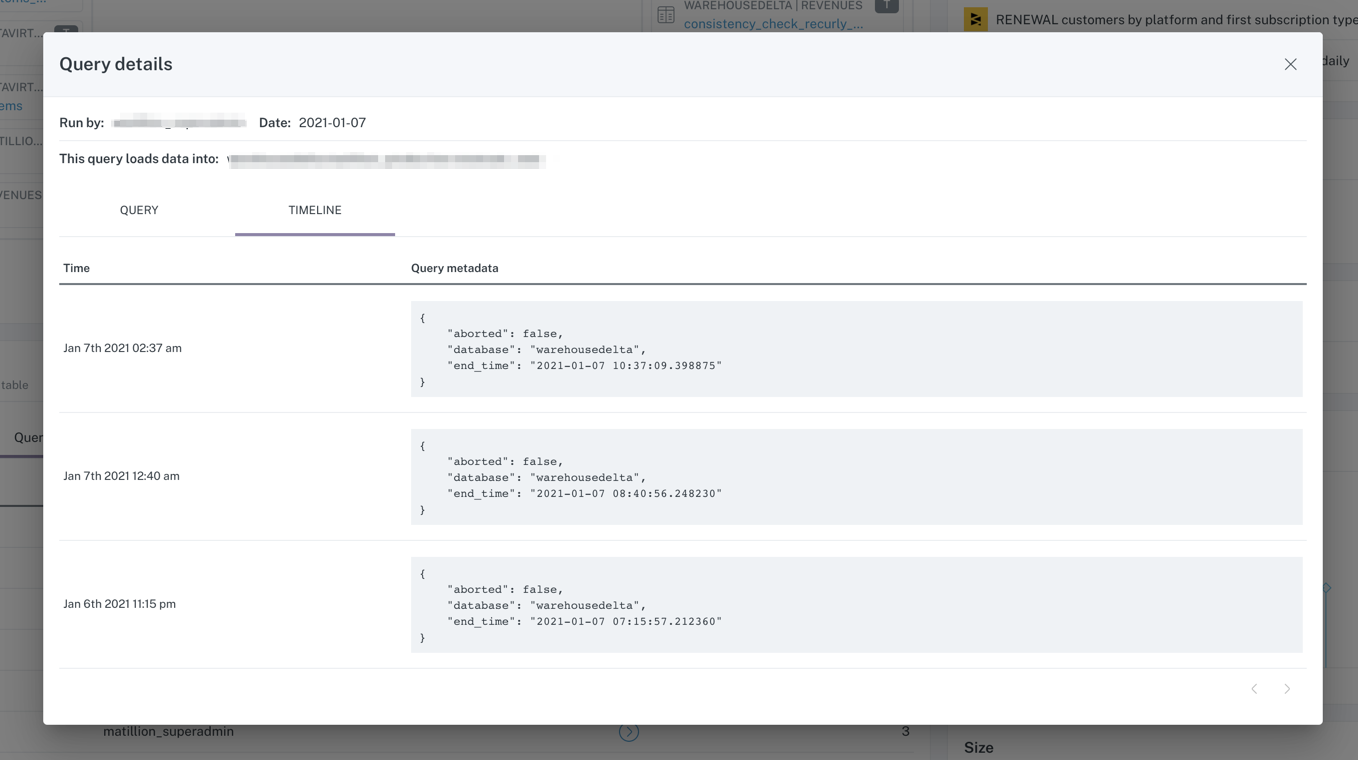
 Finish-to-end lineage powered by metadata provides you the required data to not simply troubleshoot unhealthy knowledge and damaged pipelines, but in addition perceive the enterprise functions of your knowledge at each stage in its life cycle. Picture courtesy of Barr Moses.
Finish-to-end lineage powered by metadata provides you the required data to not simply troubleshoot unhealthy knowledge and damaged pipelines, but in addition perceive the enterprise functions of your knowledge at each stage in its life cycle. Picture courtesy of Barr Moses.
So, the place does this go away us on the subject of realizing our dream of a world of knowledge pipeline monitoring that ends knowledge downtime?
Properly, like loss of life and taxes, knowledge errors are unavoidable. However when metadata is prioritized, lineage is known, and each are mapped to testing and knowledge pipeline monitoring, the detrimental impacts on your online business – the true price of unhealthy knowledge and knowledge downtime – is basically preventable.
I am predicting that the way forward for damaged knowledge pipelines and knowledge downtime is darkish. And that is a superb factor. The extra we are able to forestall knowledge downtime from inflicting complications and hearth drills, the extra our knowledge groups can deal with initiatives that drive outcomes and transfer the enterprise ahead with trusted, dependable, and highly effective knowledge.
The put up 5 Methods For Stopping Dangerous Knowledge In It’s Tracks appeared first on Datafloq.

{kind=link}